SQL的分组查询——group by、with rollup、having、聚合函数、group_concat等
文章目录
- 1. 分组查询介绍
- 2. group by的使用
- 根据gender字段来分组
- 根据age字段分组、with rollup的初步使用
- 根据name和gender多个字段进行分组
- 3. group by + group_concat()的使用
- 4. group by + 聚合函数的使用
- 5. group by + having的使用
- 6. group by + with rollup的使用
- 7. 小结
1. 分组查询介绍
分组查询就是将查询结果按照指定字段进行分组,字段中数据相等的分为一组。
分组查询基本的语法格式如下:
GROUP BY 列名 [HAVING 条件表达式] [WITH ROLLUP]
说明:
列名: 是指按照指定字段的值进行分组。
HAVING 条件表达式: 用来过滤分组后的数据。
WITH ROLLUP:在所有记录的最后加上一条记录,显示select查询时聚合函数的统计和计算结果
2. group by的使用
group by可用于单个字段分组,也可用于多个字段分组
根据gender字段来分组
select gender from students group by gender;

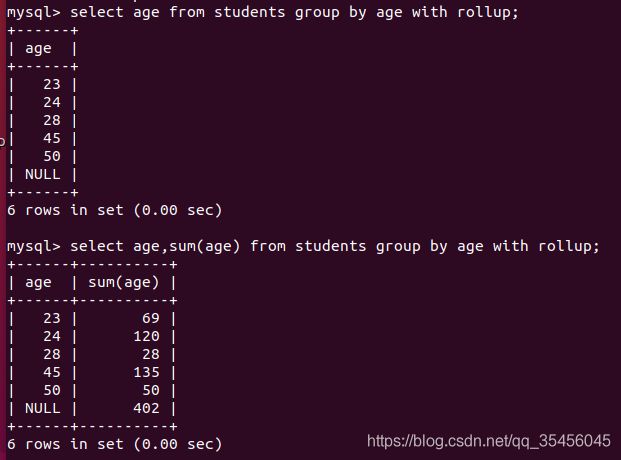
根据age字段分组、with rollup的初步使用
select age,sum(age) from students group by age with rollup;
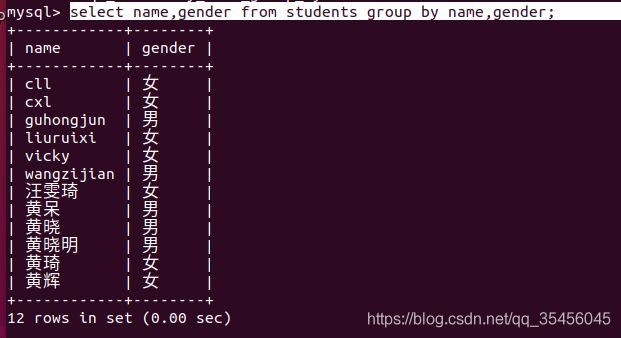
根据name和gender多个字段进行分组
select name,gender from students group by name,gender;
3. group by + group_concat()的使用
group_concat(字段名): 统计每个分组指定字段的信息集合,每个信息之间使用逗号进行分割
-- 根据gender字段进行分组, 查询gender字段和分组的name字段信息
select gender,group_concat(name) from students group by gender;

4. group by + 聚合函数的使用
– 统计不同性别的人的平均年龄
select gender,avg(age) from students group by gender;

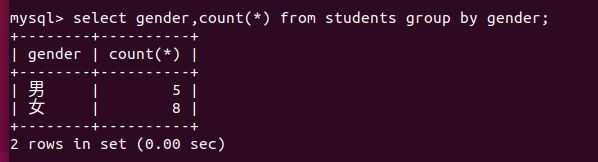
– 统计不同性别的人的个数
select gender,count(*) from students group by gender;
5. group by + having的使用
having作用和where类似都是过滤数据的,但having是过滤分组数据的,只能用于group by
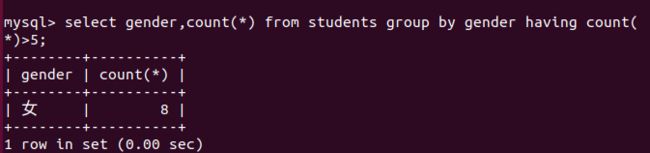
– 根据gender字段进行分组,统计分组条数大于2的
select gender,count(*) from students group by gender having count(*)>5;
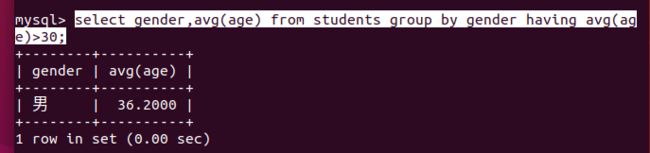
不同性别人的平均年龄,平均年龄大于30的
select gender,avg(age) from students group by gender having avg(age)>30;
6. group by + with rollup的使用
with rollup的作用是:在最后记录后面新增一行,显示select查询时聚合函数的统计和计算结果
– 根据gender字段进行分组,汇总总人数
select gender,count(*) from students group by gender with rollup;

– 根据gender字段进行分组,汇总所有人的年龄
select gender,group_concat(age) from students group by gender with rollup;

7. 小结
group by 根据指定的一个或者多个字段对数据进行分组
group_concat(字段名)函数是统计每个分组指定字段的信息集合
聚合函数在和 group by 结合使用时, 聚合函数统计和计算的是每个分组的数据
having 是对分组数据进行条件过滤
with rollup在最后记录后面新增一行,显示select查询时聚合函数的统计和计算结果