如何优化MySQL查询?
个人学习MySQL的总结学习笔记,参考资料都在文末给出,建议阅读
⭐️内容较多,点赞收藏不迷路 ⭐️
文章目录
- 概念
- 使用Explain进行分析
- 优化数据访问
- 1. 减少请求的数据量
- 2. 减少服务器端扫描的行数
- 重构查询方式
- 1. 切分大查询
- 2. 分解大连接查询
- 拓展阅读
概念
衡量指标:
- 响应时间
- 返回的行数
- 扫描的行数
这三个指标都会记录到MySQL的慢日志中。
响应时间包括
- 服务时间:数据库处理这个查询花费的时间。
- 排队时间:被阻塞时间,比如等待I/O操作、等待行锁等待。
主要是优化服务时间。
评估响应时间是否合理(是否真实反应服务时间)
知道一个查询所需要哪些索引以及它的执行计划是什么,然后计算大概需要多少个顺序和随机I/O,再用其乘以在具体硬件下一次I/O的消耗时间,最后把消耗相加。
一个任务由多个子任务组成,优化一个查询任务,可以通过消除一些子任务、减少子任务的执行次数或者让子任务运行得更快来达到目的。
MySQL执行一个查询的过程
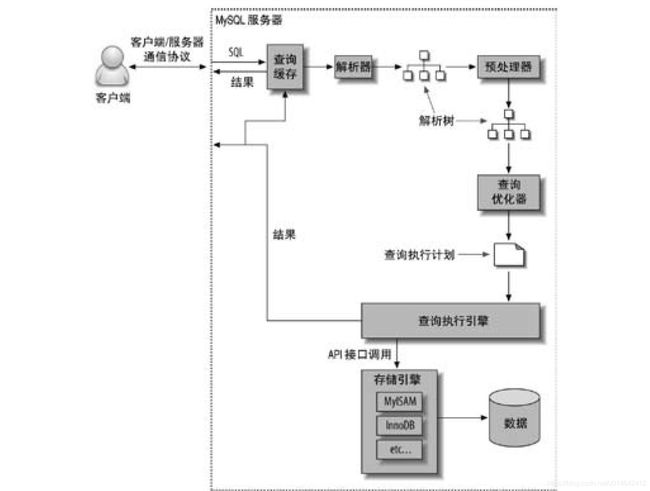
- 客户端发送一条查询给服务器。
- 服务器先检查查询缓存,如果命中了缓存,则立即返回存储在缓存中命中的结果,否则进入下一阶段。
- 服务器进行SQL解析、预处理,再由优化器生成对应的执行计划。
- MySQL根据优化器生成的执行计划,调用存储引擎的API来执行查询。
- 将结果返回给客户端。
第四步是最重要的一步,其中包含了大量的调用和数据处理,包括排序、分组。
在整个过程中,网络、CPU计算,生成信息和执行计划、互斥等操作都需要花费时间。向存储引擎检索数据的调用操作所需要的时间,包括内存操作、CPU操作和I/O操作等时间。
优化查询主要是减少和消除一些额外操作、重复操作、慢操作的时间。
使用Explain进行分析
Explain 用来分析 SELECT 查询语句,开发人员可以通过分析 Explain 结果来优化查询语句。
比较重要的字段有:
- select_type : 查询类型,有简单查询、联合查询、子查询等
- key : 使用的索引
- rows : 扫描的行数
优化数据访问
查询性能低下的最基本愿意是访问的数据太多。
通过以下分析可以优化查询
- 确认应用程序是否在检索大量超过需要的数据,可能是因为访问了太多的行或者列。
- 确认MySQL服务器层是否存在扫描大量超过需要的数据行。
1. 减少请求的数据量
- 只返回必要的行:MySQL会先返回全部结果集再进行筛选。比如取出一百条数据但只显示前十条,可以通过再查询后面加LIMIT解决。
- 只返回必要的列:最好不要使用SELECT *语句。取出全部列会让优化器无法完成索引覆盖扫描这类优化,还会为服务器带来额外的I/O、内存和CPU的消耗。
- 缓存重复查询的数据:使用缓存可以避免在数据库中进行查询,特别在要查询的数据经常被重复查询时,缓存带来的查询性能提升将会是非常明显的。
2. 减少服务器端扫描的行数
理想情况下扫描的行数和返回的行数是相同的。使之实现的最有效的方式是使用索引来覆盖查询。
如果没有找到合适的访问类型,最有效的办法是增加一个合适的索引,索引让MySQL以最高效、扫描行数最少的方式找到需要的记录。
扫描类型
- 全索引扫描:全索引扫描,查询时,遍历索引树来获取数据行。如果数据不是密集的会产生随机IO。在执行计划中是Type列,index。
- 全表扫描:通过读物理表获取数据,顺序读磁盘上的文件。这种情况会顺序读磁盘上的文件。在执行计划中是Type列,all。
- 覆盖索引:覆盖索引,如果where条件的列和返回的数据在一个索引中,那么不需要回查表,那么就叫覆盖索引。在执行计划中是extra那一列,using index。
对比
全索引扫描并不一定就比全表扫描好,取决于数据存储位置。
如果数据在内存,那么这两种没有太大区别。
如果数据在磁盘,全表扫描比全索引扫描要好,这是因为,全表扫描是顺序读数据,sequential read,是顺序IO。全索引扫描可能会产生随机读(reandom read),随机IO,显然,顺序读要比随机读快很多。
WHRER的使用
从好到坏
- 在存储引擎层,利用索引中使用来过滤不匹配的记录。
- 使用覆盖扫描来返回记录,直接从索引中过滤不需要的记录并返回命中的结果。这是在服务器层完成的,无须再回表查询记录。
- 从数据表中返回数据,然后过滤不满足条件的记录。在服务器层完成,需要先从数据表中读出记录然后过滤。
扫描大量数据但只需返回少数的行
- 使用索引覆盖查询,把所有需要的列都放在索引中。
- 该表库表结构,比如使用单独的汇总表。
- 重写复杂查询,让优化器能跟以更优化的方式执行查询。
重构查询方式
- 将查询转换一种写法让其返回一样的结果,但性能更好。
- 通过修改代码用另一种方式完成查询最终达到一样的目的。
1. 切分大查询
将大查询切分成小查询,每个查询功能完全一样,只完成一小部分,每次只返回一小部分查询结果。
一个大查询如果一次性执行的话,可能一次锁住很多数据、占满整个事务日志、耗尽系统资源、阻塞很多小的但重要的查询。
DELETE FROM messages WHERE create < DATE_SUB(NOW(), INTERVAL 3 MONTH);
rows_affected = 0
一次删除一万行
do {
rows_affected = do_query(
"DELETE FROM messages WHERE create < DATE_SUB(NOW(), INTERVAL 3 MONTH) LIMIT 10000")
} while rows_affected > 0
进一步优化
删除任务之间设置时间间隔,可以将服务器的一次性压力分散,降低对服务器的影响,减少删除时锁的持有时间。
2. 分解大连接查询
很多高性能的应用都会对关联查询进行分解。
将一个大连接查询分解成对每一个表进行一次单表查询,然后在应用程序中进行关联,这样做的好处有:
- 让缓存更高效。对于连接查询,如果其中一个表发生变化,那么整个查询缓存就无法使用。而分解后的多个查询,即使其中一个表发生变化,对其它表的查询缓存依然可以使用。
- 分解成多个单表查询,这些单表查询的缓存结果更可能被其它查询使用到,从而减少冗余记录的查询。
- 减少锁竞争;
- 在应用层进行连接,可以更容易对数据库进行拆分,从而更容易做到高性能和可伸缩。
- 查询本身效率也可能会有所提升。例如下面的例子中,使用 IN() 代替连接查询,可以让 MySQL 按照 ID 顺序进行查询,这可能比随机的连接要更高效。
SELECT * FROM tag
JOIN tag_post ON tag_post.tag_id=tag.id
SELECT * FROM tag WHERE tag='mysql';
SELECT * FROM tag_post WHERE tag_id=1234;
SELECT * FROM post WHERE post.id IN (123,456,567,9098,8904);
拓展阅读
一个好的索引结构,是好的查询的必备基础,或者说,了解了如何创建一个良好的索引结构,那么写出良好的查询也就不成什么问题了。
如何构建一个良好索引?
面试MySQL必备知识点
⭐️
如果对你有帮助,请点个赞,加个收藏噢!
参考资料
《高性能MySQL》
cyc2018