新手学python(1):解析XML与系统调用
最近需要做一个项目,完成一批音乐的格式转换。由于之前并未学习过python,所以想借此机会学一下。在介绍自己的学习过程之前,先把项目简要描述一下。目前在一台服务器a上有几十万首原始的MP3音乐文件,现在需要将其转换成wav文件进行后续的指纹提取,提取过程可以在a上完成。不过指纹匹配的过程需要耗费几十G的内存,服务器a上没有这么多内存,所以匹配过程需要在服务器b上完成。此外,为了方便今后对几十万首歌的检索,需要将歌曲信息存入数据库,数据库架设在服务器b上。现在比较麻烦的一点是,原始MP3音乐的信息目前存在与一系列的xml文件中,我们需要解析xml文件获取音乐信息然后存入数据库。整个运行流程如图一。
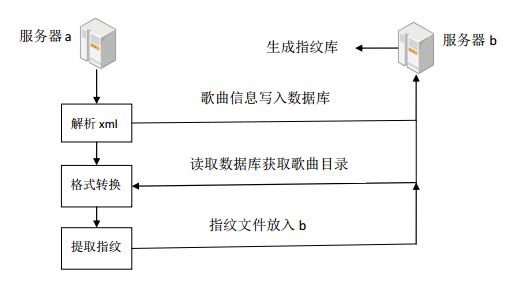
图1 项目的运行流程
之前见很多人用python,说它的各种好处,几行代码就可以构造一个爬虫,我很怀疑。为了跟上时代潮流,我也还是学习一下,看看python到底多牛。
首先从同事那里借了本《Python核心编程》,看了两天,大体熟悉了一下python。如果从现在的角度来看此书,我感觉这本书真是烂透了,内容虽然很全,但都是浅尝辄止。如果说适合于初学者,但是很多概念又没解释清楚,内容介绍比较混乱。肯定不适合高级程序员,建议大家搜索新的python书籍。不过烂归烂,我初学python就是靠它了。
其实一门语言的学习,了解基本语法只需要一天;能尝试应用只需要两天;但是想熟练使用,尤其是各个库的使用,得需要常年累月的积累。所以大家不要对新语言有抵触心理,上手都比较容易,写个hello world程序真是分分钟的事。好了,下面开始介绍自己学习python时用到的几个应用。
1解析XML文件
我面临的第一个任务是如何解析xml文件获得歌曲信息。存有歌曲信息的xml文件非常复杂,简化版的xml内容如下:
……
Mozart: Le Nozze di Figaro - The Sony Opera House
20072009
……
……
……
Le nozze di Figaro, K. 492: Sinfonia
……
Classical
true
Artist
Orchestra del Maggio Musicale Fiorentino
true
……
Music
00000000000020961825_01_001_25003.mp3
……
……
……
其简化版的层次结构如图二。
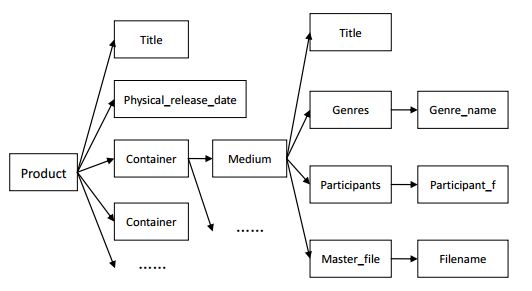
图2 xml的层次结构图
我需要通过解析xml文件获得音乐的专辑,发行时间,歌曲名,作者,类型,原始文件名,目录,大小等信息。看似复杂,但是解析用到的函数就几个:
- getElementsByTagName:获得父标签下所有指定的标签,结果是一个nodeList;
- childNodes:获得一个标签的所有子标签,结果是一个nodeList;
- nodeValue:获得标签的值。
具体的解析过程就是反复利用上面这三个函数逐层进行解析。解析代码如下:
from xml.dom import minidom
class ParseXML(object):
@staticmethod
def parse(file):
results=list();
results.append(os.path.dirname(file));
doc=minidom.parse(file);
doc.toxml('utf-8');
root=doc.documentElement;
product=root.getElementsByTagName('Product');
children=product[0].childNodes;#the result is a list,even though only one element, we must use index to visit the function
for child in children:#parse an album
if child.nodeName=='Title':
results.append(child.childNodes[0].nodeValue.encode('utf-8','ignore').strip());
elif child.nodeName=='Physical_release_date':
results.append(child.childNodes[0].nodeValue.encode('utf-8','ignore').strip());
elif child.nodeName=='Container':
medias=child.getElementsByTagName('Media');
for media in medias:#parse every music
medium=media.getElementsByTagName('Medium');
for m in medium:
result=list();
attributes=m.childNodes;
for attribute in attributes:
if attribute.nodeName=='Title':
result.append(attribute.childNodes[0].nodeValue.encode('utf-8','ignore').strip());
elif attribute.nodeName=='Genres':
genre=attribute.getElementsByTagName('Genre');
genre_name=genre[0].getElementsByTagName('Genre_name');
result.append(genre_name[0].childNodes[0].nodeValue.encode('utf-8','ignore').strip());
elif attribute.nodeName=='Participants':
participant=attribute.getElementsByTagName('Participant');
full_name=participant[0].getElementsByTagName('Participant_full_name');
result.append(full_name[0].childNodes[0].nodeValue.encode('utf-8','ignore').strip());
elif attribute.nodeName=='Master_file':
audio_file=attribute.getElementsByTagName('Audio_file');
filename=audio_file[0].getElementsByTagName('Filename');
result.append(filename[0].childNodes[0].nodeValue.encode('utf-8','ignore'));
full_name=os.path.join(os.path.dirname(file),filename[0].childNodes[0].nodeValue.encode('utf-8','ignore'));
result.append(os.path.getsize(full_name));
results.append(result);
results.append(len(results)-3);
return results;
代码比较长,但是逻辑比较简单。首先加载root,然后获得root的Product标签。需要注意的一点是getElementsByTagName返回的是一个列表,即使只有一个子标签,我们也要用下标的形式访问。获得Product标签之后,就利用childNodes函数解析获得所有的子标签。从子标签中我们可以直接解析获得音乐的专辑和发行时间。为了获得其他信息,我们需要进一步解析Container标签,解析方法和Product标签的解析类似。
还有两点需要解释。第一,Product标签的子节点不只有字面上的Title等标签,还有换行也是标签。如果我们将Product的子节点都打印出来,结果类似于:
[
可以看到,列表的第一个元素是Textnode,第二个元素才是Title标签。这表明minidom将换行解析为一个独立的元素。所以在解析如:
Value
的标签时,它实际上有三个子标签。第二,在获取一个标签的内容时,也必须通过childNodes函数来获取。例如,我们要获得Title的内容,如果我们直接访问title的内容,则会返回None。所以我们首先返回Title标签的所有子标签,然后获得子标签的内容。
代码为了后续应用,将解析的结果存入一个列表中。此外,由于歌曲名等可能有非ascii码,代码还用utf-8对结果进行了编码。
2 系统调用
Python作为一种脚本语言,肯定少不了调用系统命令执行一些任务。Python中主要有两个函数system和popen,都在os库中。当然也可以通过subprocess模块执行系统调用,它们方式都一样。
格式转换需要调用ffmpeg将MP3文件转换为wav文件,由于不需要返回值,所以采用system函数,代码如下:
@staticmethod
def transform(file,save_to,name):
new_name=name+'.wav';
saved_file=os.path.join(save_to,new_name);
os.system('./ffmpeg -i '+file+' -y -ar 8000 -ac 1 -vn '+saved_file);
@staticmethod
def wavCount(dir):
f=os.popen(‘ls ’+dir+’/*.wav |wc -l’);
count=f.readline();
f.close();
return count;