基于麻雀搜索算法优化深度置信网络的分类方法(SSA-DBN)
结合深度置信网络(DBN)在提取特征和处理高维、非线性数据等方面的优势,提出一种基于深度置信网络的分类方法。该方法通过深度学习利用原始时域信号的傅里叶频谱(FFT)训练深度置信网络,其优势在于该方法对信号进行FFT时无需设置参数,且直接采用所有频谱分量进行建模,因此无需复杂的特征选择方法,具有较强的通用性和适应性。最后,为了进一步增强DBN的分类精度,采用麻雀搜索算法(SSA)对DBN各权重参数进行优化,实验结果表明:本文提出的方法能够有效地提高分类识别精度。
这个流程十分常见,之所以写这个博客,是因为麻雀搜索算法(SSA)是20年出来的优化算法,目前知网上还没有相关文章,因此对于有需要的人来说,可以水水文章。
1,数据处理
分类数据采用凯斯西楚的轴承数据,OHP/48KHz,数据处理程序如下:
%% 数据预处理(训练集 验证集 测试集划分)
clc;clear;close all
%% 加载原始数据
% load 0HP/48k_Drive_End_B007_0_122; a1=X122_DE_time'; %1
% load 0HP/48k_Drive_End_B014_0_189; a2=X189_DE_time'; %2
% load 0HP/48k_Drive_End_B021_0_226; a3=X226_DE_time'; %3
% load 0HP/48k_Drive_End_IR007_0_109; a4=X109_DE_time'; %4
% load 0HP/48k_Drive_End_IR014_0_174 ; a5=X173_DE_time';%5
% load 0HP/48k_Drive_End_IR021_0_213 ; a6=X213_DE_time';%6
% load 0HP/48k_Drive_End_OR007@6_0_135 ;a7=X135_DE_time';%7
% load 0HP/48k_Drive_End_OR014@6_0_201 ;a8=X201_DE_time';%8
% load 0HP/48k_Drive_End_OR021@6_0_238 ;a9=X238_DE_time';%9
% load 0HP/normal_0_97 ;a10=X097_DE_time';%10
% save original_data a1 a2 a3 a4 a5 a6 a7 a8 a9 a10 %保存下来 下次直接调用
% clear
load original_data
%%
N=100;
L=864;% 每种状态取N个样本 每个样本长度为L
data=[];label=[];
for i=1:10
if i==1;ori_data=a1;end
if i==2;ori_data=a2;end
if i==3;ori_data=a3;end
if i==4;ori_data=a4;end
if i==5;ori_data=a5;end
if i==6;ori_data=a6;end
if i==7;ori_data=a7;end
if i==8;ori_data=a8;end
if i==9;ori_data=a9;end
if i==10;ori_data=a10;end
for j=1:N
start_point=randi(length(ori_data)-L);%随机取一个起点
end_point=start_point+L+1;
data=[data ;ori_data(start_point:end_point)];
label=[label;i];
end
end
%% 标签转换 onehot编码
output=zeros(10*N,10);
for i = 1:10*N
output(i,label(i))=1;
end
%% 划分训练集 验证集与测试集 7:2:1比例
n=randperm(10*N);
m1=round(0.7*10*N);
m2=round(0.9*10*N);
train_X=data(n(1:m1),:);
train_Y=output(n(1:m1),:);
valid_X=data(n(m1+1:m2),:);
valid_Y=output(n(m1+1:m2),:);
test_X=data(n(m2+1:end),:);
test_Y=output(n(m2+1:end),:);
save data_process train_X train_Y valid_X valid_Y test_X test_Y
2,FFT特征提取
%% 提取FFT谱作为特征向量
clc;close all;clear
%%
load data_process
%% 2、加载数据
x1=train_X(1,:);
% 采样点
L=length(x1);
%采样频率
fs=48000;
%采样间隔
Ts=1/fs;
%采样点数
t=Ts:Ts:L*Ts;
%轴承信号
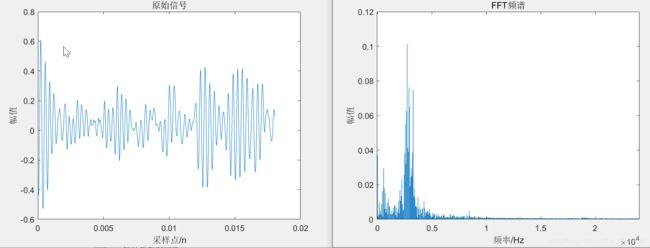
% 3、对原始信号作图
figure
plot(t,x1)
title('原始信号')
xlabel('采样点/n')
ylabel('幅值')
% 4、fft频谱
Y = fft(x1);
P2 = abs(Y/L);
P1 = P2(1:L/2+1);
P1(2:end-1) = 2*P1(2:end-1);
f = fs*(0:(L/2))/L;
figure
bar(f,P1)
title('FFT频谱')
xlabel('频率/Hz')
ylabel('幅值')
%% 训练集
TZ=[];
for IIII=1:size(train_X,1) %依次对每个样本进行处理
x1=train_X(IIII,:);%轴承信号
Y = fft(x1);
L=length(x1);
P2 = abs(Y/L);
P1 = P2(1:L/2+1);
P1(2:end-1) = 2*P1(2:end-1);
TZ(IIII,:)=P1/max(P1);
end
disp('训练集提取完毕')
train_X=TZ;
%% 验证集
TZ=[];
for IIII=1:size(valid_X,1) %依次对每个样本进行处理
x1=valid_X(IIII,:);%轴承信号
Y = fft(x1);
L=length(x1);
P2 = abs(Y/L);
P1 = P2(1:L/2+1);
P1(2:end-1) = 2*P1(2:end-1);
TZ(IIII,:)=P1/max(P1);
end
disp('验证集提取完毕')
valid_X=TZ;
%% 测试集
TZ=[];
for IIII=1:size(test_X,1) %依次对每个样本进行处理
x1=test_X(IIII,:);%轴承信号
Y = fft(x1);
L=length(x1);
P2 = abs(Y/L);
P1 = P2(1:L/2+1);
P1(2:end-1) = 2*P1(2:end-1);
TZ(IIII,:)=P1/max(P1);
end
disp('测试集提取完毕')
test_X=TZ;
%% 保存结果
save data_feature train_X valid_X test_X train_Y valid_Y test_Y
3,DBN分类
clc;clear;close all;
tic
%% 加载数据
% load('data_process.mat');
load('data_feature.mat');
trainX=double(train_X);
trainYn=double(train_Y);
testX=double(test_X);
testYn=double(test_Y);
clear train_X train_Y test_X test_Y valid_X valid_Y
%% DBN参数设置
rng(0)
% 网络各层节点
input_num=size(trainX,2);%输入层
hidden_num=[50 20];%隐含层,两个数就是两个隐含层 3个数就是3个隐含层
class=size(trainYn,2);%输出层
nodes = [input_num hidden_num class]; %节点数
% 初始化网络权值
dbn = randDBN(nodes);%调用randDBN
nrbm=numel(dbn.rbm);
opts.MaxIter =100; % 迭代次数
% opts.BatchSize = round(length(trainYn)/4); % batch规模为四分之一的训练集trainY的长度进行四舍五入取整
opts.BatchSize = 32; % batch规模
opts.Verbose = 0; % 是否展示中间过程
opts.StepRatio = 0.1; % 学习速率
% opts.InitialMomentum = 0.9;%opts.InitialMomentum为0.7
% opts.FinalMomentum = 0.1;%opts.FinalMomentum为0.8
% opts.WeightCost = 0.005;%opts.WeightCost为0
%opts.InitialMomentumIter = 10;
%% RBM逐层预训练
dbn = pretrainDBN(dbn, trainX, opts);%进行dbn的预训练
%% 线性映射-将训练好的各RBM 堆栈初始化DBN网络
dbn= SetLinearMapping(dbn, trainX, trainYn);%调用SetLinearMapping函数
%% 训练DBN-微调整个DBN
opts.MaxIter =100; % 迭代次数
% opts.BatchSize = round(length(trainYn)/4); % batch规模为四分之一的训练集trainY的长度进行四舍五入取整
opts.BatchSize =32;
opts.Verbose = 0; % 是否展示中间过程
opts.StepRatio = 0.1; % 学习速率
opts.Object = 'CrossEntropy'; % 目标函数: Square CrossEntropy
%opts.Layer = 1;
dbn = trainDBN(dbn, trainX, trainYn, opts);%dbn调用trainDBN函数
%% 测试
% 对训练集进行预测
trainYn_out = v2h( dbn, trainX );%trainYn_out调用v2h函数
[~,trainY] = max(compet(trainYn'));
[~,trainY_out] = max(compet(trainYn_out'));
%compet是神经网络的竞争传递函数,用于指出矩阵中每列的最大值。对应最大值的行的值为1,其他行的值都为0。
%分类
% 计算准确率
accTrain = sum(trainY==trainY_out)/length(trainY);%accTrain为TrainY==trainY_out'的总和除以length(trainY)
% 画训练集预测结果
figure%图形
plot(trainY,'r o')%画一个名为trainY,红色的圆圈
hold on%hold on 是当前轴及图形保持而不被刷新,准备接受此后将绘制
plot(trainY_out,'g +')%画一个名为trainY_out,绿色的加号
legend('真实值','预测值')%legend(图例1,图例2,)
grid on%画网格
xlabel('样本','fontsize',13)%xlabel(x轴说明)
ylabel('类别','fontsize',13)%ylabel(y轴说明)
title(['原始数据迭代100次训练集准确率:' num2str(accTrain*100) '%'],'fontsize',13)%title(图形名称)
% 对测试集进行预测
testYn_out = v2h( dbn, testX );%testYn_out为调用v2h函数
[~,testY] = max(compet(testYn'));
[~,testY_out] = max(compet(testYn_out'));%compet是神经网络的竞争传递函数,用于指出矩阵中每列的最大值。对应最大值的行的值为1,其他行的值都为0。
% 计算准确率
accTest = sum(testY==testY_out)/length(testY);%accTest为testY==testY_out'的总和除以length(testY)
% 画测试集预测结果
figure%图形
plot(testY,'r o')%画一个名为testY,红色的圆圈
hold on%hold on 是当前轴及图形保持而不被刷新,准备接受此后将绘制
plot(testY_out,'g *')%画一个名为testY_out,绿色的加号
legend('真实值','预测值')%legend(图例1,图例2,)
grid on%画网格
xlabel('样本','fontsize',13)%xlabel(x轴说明)
ylabel('类别','fontsize',13)%ylabel(y轴说明)
title(['原始数据迭代100次测试集准确率:' num2str(accTest*100) '%'],'fontsize',13)%title(图形名称)
toc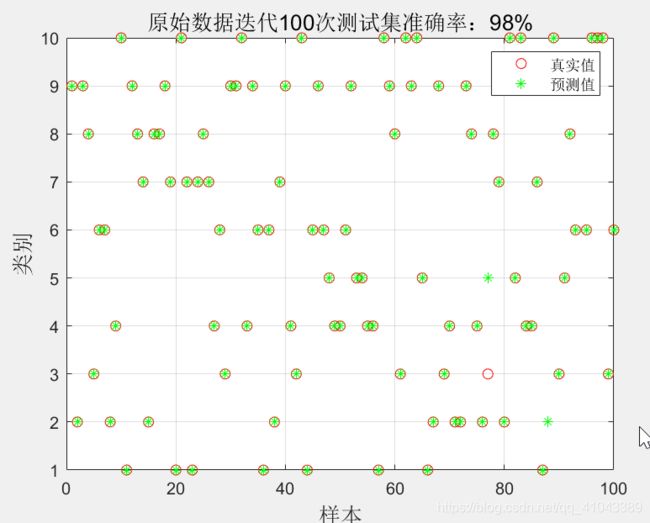
4.SSA-DBN分类
clc;clear;close all;format compact
tic
%% 加载数据
% load('data_process.mat');
load('data_feature.mat');
trainX=double(train_X);
trainYn=double(train_Y);
validX=double(valid_X);
validYn=double(valid_Y);
testX=double(test_X);
testYn=double(test_Y);
clear train_X train_Y test_X test_Y valid_X valid_Y
%% 麻雀算法优化DBN
% 网络各层节点设置
input_num=size(trainX,2);%输入层
hidden_num=[50 30];%隐含层,两个数就是两个隐含层 3个数就是3个隐含层
class=size(trainYn,2);%输出层
nodes = [input_num hidden_num class]; %节点数
% [x,trace]=ssafordbn(trainX,validX,trainYn,validYn,nodes); %ssa优化隐含层节点数
% save best_para x trace
%%
load best_para
%将优化结果放到h中
figure
plot(trace)
title('适应度进化曲线')
xlabel('迭代次数')
ylabel('目标函数值/错误率')
采用训练集进行DBN训练,优化时,SSA以验证集的错误率为适应度函数,进行优化,目标函数如图,SSA的目的就是找到一组权重参数,使得训练出来的DBN在验证集上拥有最低的错误率。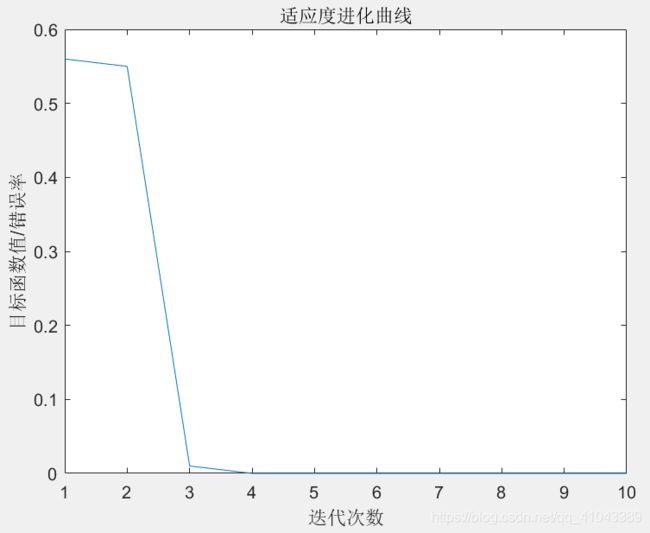
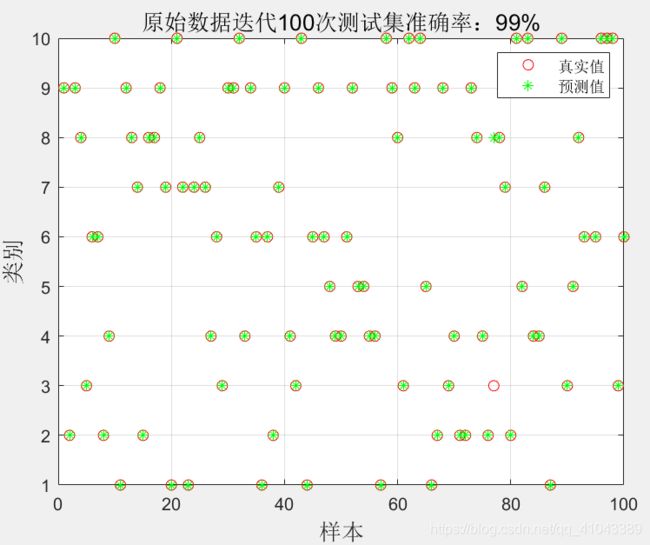
采用优化得到的这组超参数,重新训练模型,并对测试集分类,结果如图:
更多见我github:https://github.com/fish-kong/SSA-DBN-classification