计算机视觉技术self-attention最新进展
其它机器学习、深度学习算法的全面系统讲解可以阅读《机器学习-原理、算法与应用》,清华大学出版社,雷明著,由SIGAI公众号作者倾力打造。
- 书的购买链接
- 书的勘误,优化,源代码资源
Attention注意力,起源于Human visual system(HVS),个人定义的话,应该类似于 外界给一个刺激Stimuli,然后HVS会第一时间产生对应的 saliency map,注意力对应的应该就是这个显著性区域。
这其中就涉及很多 bottom-up 及 top-down 的 physiological 原理~总的来说,就是 区域权值学习 问题:
1、Hard-attention,就是0/1问题,哪些区域是被 attentioned,哪些区域不关注
2. Soft-attention,[0,1]间连续分布问题,每个区域被关注的程度高低,用0~1的score表示
Self-attention自注意力,就是 feature map 间的自主学习,分配权重(可以是 spatial,可以是 temporal,也可以是 channel间)
[1] Non-local NN, CVPR2018
FAIR的杰作,主要 inspired by 传统方法用non-local similarity来做图像 denoise
主要思想也很简单,CNN中的 convolution单元每次只关注邻域 kernel size 的区域,就算后期感受野越来越大,终究还是局部区域的运算,这样就忽略了全局其他片区(比如很远的像素)对当前区域的贡献。
所以 non-local blocks 要做的是,捕获这种 long-range 关系:对于2D图像,就是图像中任何像素对当前像素的关系权值;对于3D视频,就是所有帧中的所有像素,对当前帧的像素的关系权值。
网络框架图也是简单粗暴:
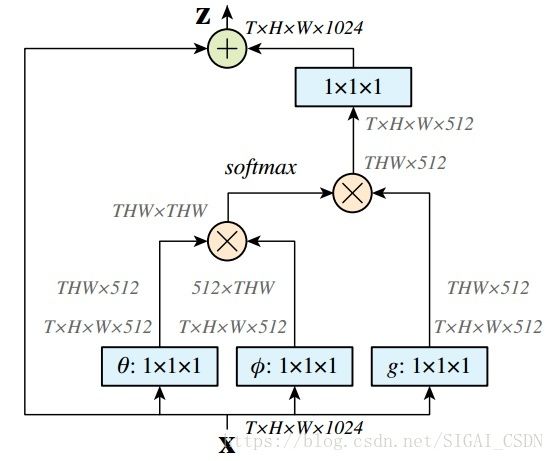
Non-local block[1]
文中有谈及多种实现方式,在这里简单说说在DL框架中最好实现的 Matmul 方式:
- 首先对输入的 feature map X 进行线性映射(说白了就是 1*1*1 卷积,来压缩通道数),然后得到
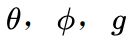 特征
特征 - 通过reshape操作,强行合并上述的三个特征除通道数外的维度,然后对
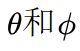 进行矩阵点乘操作,得到类似协方差矩阵的东西(这个过程很重要,计算出特征中的自相关性,即得到每帧中每个像素对其他所有帧所有像素的关系)
进行矩阵点乘操作,得到类似协方差矩阵的东西(这个过程很重要,计算出特征中的自相关性,即得到每帧中每个像素对其他所有帧所有像素的关系) - 然后对自相关特征 以列or以行(具体看矩阵 g 的形式而定) 进行 Softmax 操作,得到0~1的weights,这里就是我们需要的 Self-attention 系数
- 最后将 attention系数,对应乘回特征矩阵 g 中,然后再上扩 channel 数,与原输入 feature map X 残差一下,完整的 bottleneck
嵌入在 action recognition 框架中的attention map 可视化效果:

注意力可视化[1]
图中的箭头表示,previous 若干帧中的某些像素 对最后图(当前帧)的脚关节像素的贡献关系。由于是soft-attention,其实每帧每个像素对对其有贡献关系,图中黄色箭头是把响应最大的关系描述出来。
总结
Pros:non-local blocks很通用的,容易嵌入在任何现有的 2D 和 3D 卷积网络里,来改善或者可视化理解相关的CV任务。比如前不久已有文章把 non-local 用在 Video ReID [2] 的任务里。
Cons:文中的结果建议把non-local 尽量放在靠前的层里,但是实际上做 3D 任务,靠前的层由于 temporal T 相对较大,构造![]() 及点乘操作那步,超多的参数,需要耗费很大的GPU Memory~ 可后续改善
及点乘操作那步,超多的参数,需要耗费很大的GPU Memory~ 可后续改善
[2] Interaction-aware Attention, ECCV2018
美图联合中科院的文章
这文章扯了很多 Multi-scale 特征融合,讲了一堆 story,然并卵;直接说重点贡献,就是在 non-local block 的协方差矩阵基础上,设计了基于 PCA 的新loss,更好地进行特征交互。作者认为,这个过程,特征会在channel维度进行更好的 non-local interact,故称为 Interaction-aware attention
那么问题来了,怎么实现 通过PCA来获得 Attention weights呢?
文中不直接使用 协方差矩阵的特征值分解 来实现,而是使用下述等价形式:
![]()
![]() 根据上面公式约束,设计了Interaction-aware loss 来增强channel间的non-local交互:
根据上面公式约束,设计了Interaction-aware loss 来增强channel间的non-local交互:
![]()
其中 A 为需要学习的 attention weights,X 为输入的 feature map
整体的Attention Block框架图和 non-local 基本一致:
~ 有点小区别是,在 X 和 Watten 点乘后,还加了个 b 项,文中说这里可看作 data central processing (subtracting mean) of PCA
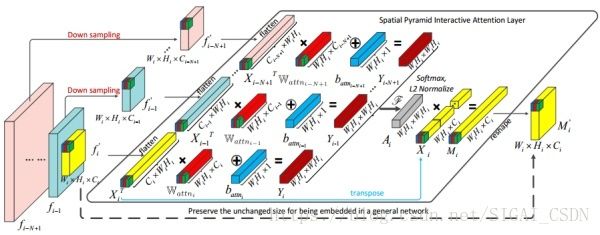
spatial pyramid interactive attention layer[3]
动作识别的主网络就与non-local中直接使用 I3D 不同,这里是使用类似 TSN 的采样Segment形式输入,然后使用2D网络提特征,再统一在Attention block进行时空聚合
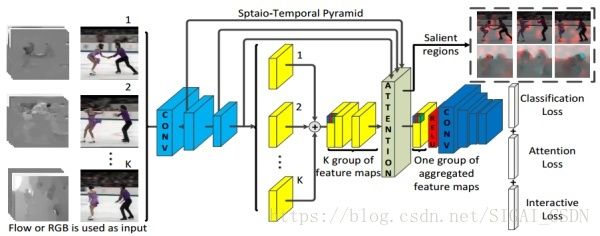
动作识别网络框架[3]
[4] CBAM: Convolutional Block Attention Module, ECCV2018
这货就是基于 SE-Net [5]中的 Squeeze-and-Excitation module 来进行进一步拓展,
具体来说,文中把 channel-wise attention 看成是教网络 Look 'what’;而spatial attention 看成是教网络 Look 'where',所以它比 SE Module 的主要优势就多了后者
我们先看看 SE-module:
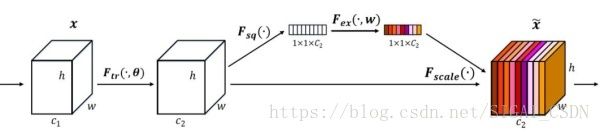
SE-module[5]
流程:
- 将输入特征进行 Global AVE pooling,得到 1*1* Channel
- 然后bottleneck特征交互一下,先压缩 channel数,再重构回channel数
- 最后接个 sigmoid,生成channel 间0~1的 attention weights,最后 scale 乘回原输入特征
再看看 CBAM :
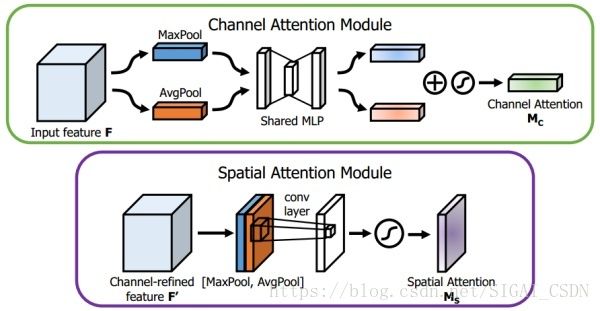
CBAM[4]
Channel Attention Module,基本和 SE-module 是一致的,就额外加入了 Maxpool 的 branch。在 Sigmoid 前,两个 branch 进行 element-wise summation 融合。
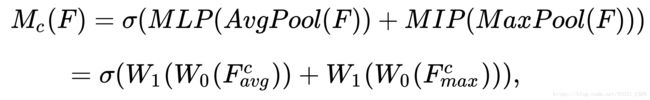
Spatial Attention Module, 对输入特征进行 channel 间的 AVE 和 Max pooling,然后 concatenation,再来个7*7大卷积,最后 Sigmoid
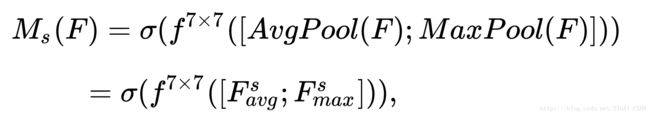
[4] CDANet, 2018
最近才在arXiv挂出来的,把Self-attention的思想用在图像分割,可通过long-range上下文关系更好地做到精准分割。
主要思想也是上述文章 CBAM 和 non-local 的融合变形:
把deep feature map进行spatial-wise self-attention,同时也进行channel-wise self-attetnion,最后将两个结果进行 element-wise sum 融合。
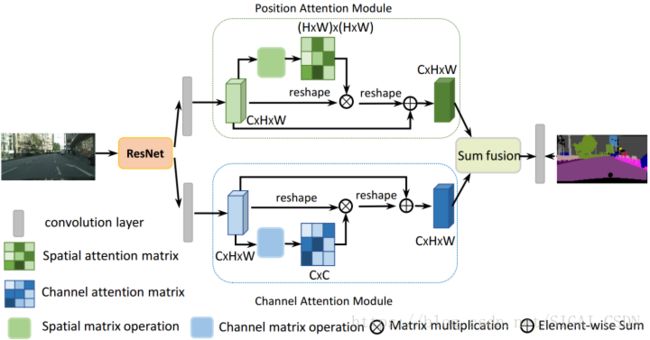
Dual Attention Network[6]
这样做的好处是:
在 CBAM 分别进行空间和通道 self-attention的思想上,直接使用了 non-local 的自相关矩阵 Matmul 的形式进行运算,避免了 CBAM 手工设计 pooling,多层感知器 等复杂操作。
总的来说,上述几个Attention module很容易嵌入到现有的网络框架中,而 CBAM 特别轻量级,也方便在端部署,也可再cascade一下temporal attention,放进 video 任务里用~~
估计后续学术界会有很多基于它们的变形和应用,哈哈~
Reference:
[1] Xiaolong Wang, Ross Girshick, Abhinav Gupta, Kaiming He, Non-local Neural Networks, CVPR2018
[2]Xingyu Liao, Lingxiao He, Zhouwang Yang, Video-based Person Re-identification via 3D Convolutional Networks and Non-local Attention,2018
[3]Yang Du, Chunfeng Yuan, Bing Li, Lili Zhao, Yangxi Li, Weiming Hu,Interaction-aware Spatio-temporal Pyramid Attention Networks for Action Classification, ECCV2018
[4] CSanghyun Woo, Jongchan Park, Joon-Young Lee, In So Kweon, BAM: Convolutional Block Attention Module, ECCV2018
[5]Jie Hu, Li Shen, Gang Sun,Squeeze-and-Excitation Networks, ILSVRC 2017 image classification winner; CVPR 2018 Oral
[6]Jun Fu et al., Dual Attention Network for Scene Segmentation, 2018