DPDK RING
DPDK RING 介绍
Ring顾名思义就是一个环形队列。有如下属性:
- 先进先出,FIFO。
- 存储结构是数组或线性表。
- 元素大小固定。
- 无锁实现。
- 多生产者或单生产者。
- 多消费者或单消费者。
- bulk模式批量入队和出队。
- Burst 模式批量入队和出队。
与链式链表相比的优势:
- cache 命中率高,无需动态分配内存。
- 生产者与消费者之间无锁。
- 多生产者/消费者之间通过32bit的CAS( Compare-And-Swap instruction)指令互斥。减少锁的消耗。
- 支持批量的入队出队。
与链式链表相比的劣势:
- 大小固定。创建Ring实例时就已决定队列的大小,有内存浪费的可能。
出队和入队的实现
针对于普通环形队列仅存在一个生产者指针和一个消费者指针。
而环形队列Ring存在两个生产者指针或索引(生产者头和生产者尾)及两个消费者指针或索引(消费者头及消费者尾)。
- 单生产者入队
初始化状态生产者头和生产者尾都指向了相同的位置。
1.入队操作第一步

首先,暂时将生产者的头索引和消费者的尾部索引交给临时变量(prod_head和prod_next);并且将prod_next指向表的下一个对象,如果在这环形缓冲区没有足够的空间,将返回一个错误。
2.入队操作的第二步
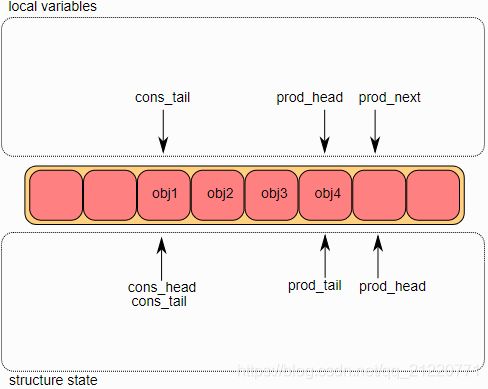
第二步是修改prod_head去指向prod_next的位置。指向新增加对象的指针被拷贝到ring(obj4)。
3.入队操作最后一步
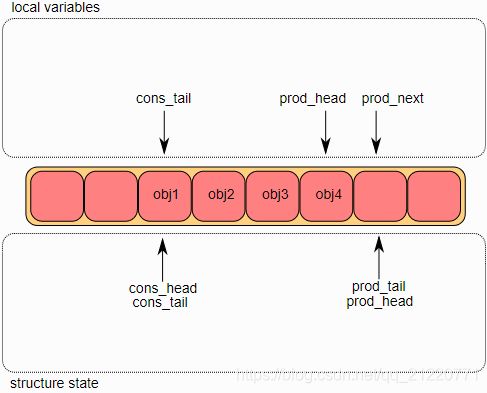
一旦这个对象被增加到环形缓冲区中,prod_tail将要被修改成prod_head指向的位置。至此,这个入队操作完成了。
- 单消费者出队
初始化状态消费者头和消费者尾都指向了相同的位置。
1.出队操作第一步
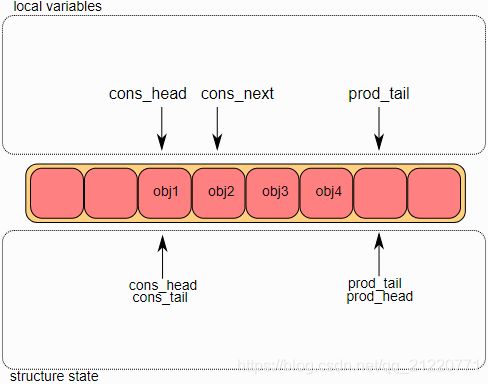
首先,暂时将消费者的头索引和生产者的尾部索引交给临时变量,并且将cons_next指向表中下一个对象,如果在这环形缓冲区没有足够的对象,将返回一个错误。
2.出队操作第二步
第二步修改cons_head去指向cons_next指向的位置,并且指向出队对象(obj1)的指针被拷贝到一个临时用户定义的指针中。
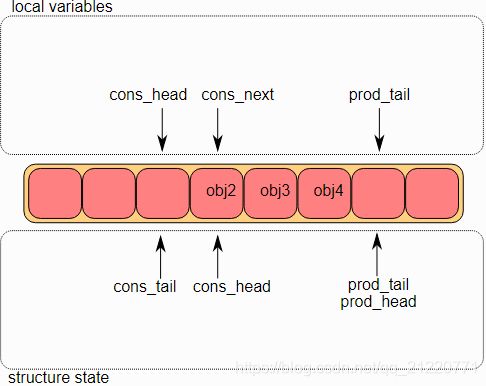
3.出队操作最后一步
最后,cons_tail被修改成执行cons_head指向的位置。至此,单消费者的出队操作完成了。
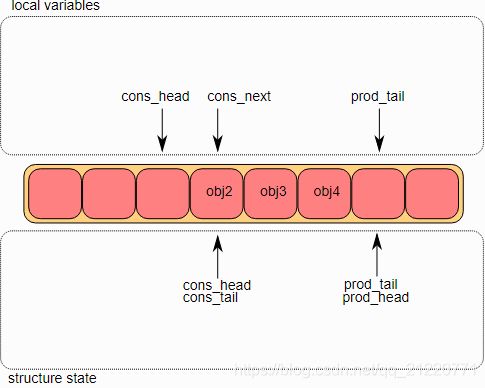
- 多生产者入队
初始状态是一个消费者的头和消费者的尾指向了相同的位置。
1.多个生产者入队第一步
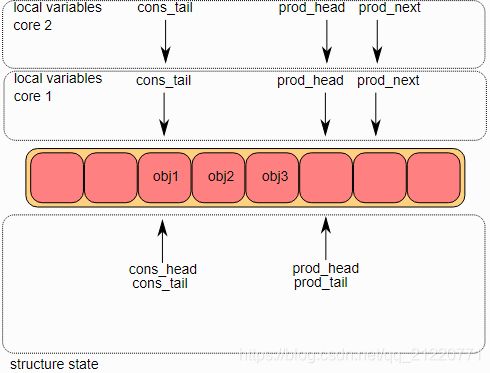
首先,在两个核上,暂时将生产者的头索引和消费者的尾索引交给临时变量,并且将prod_next指向表中下一个对象,如果在这个环形缓冲区没有足够的空间,将返回一个错误。
2.多个生产者入队第二步

第二步是修改prod_head去指向prod_next指向的位置,这个操作使用了比较交换指令(CAS)。
如果ring->prod_head和本地变量prod_head不同,则CAS操作失败,回到第一步。
如果ring->prod_head和本地变量prod_head相同,则CAS操作成功。ring->prod_head的值更新为本地变量prod_head的值。
此时core1CAS操作成功,更新head成功。core2回退第一步再次执行CAS操作,直到成功。
3.多生产者入队的第三步
这个CAS操作在core1先执行成功,并且更新了环形缓冲区的一个元素(obj4),core2后执行成功更新了另一个元素(obj5)。
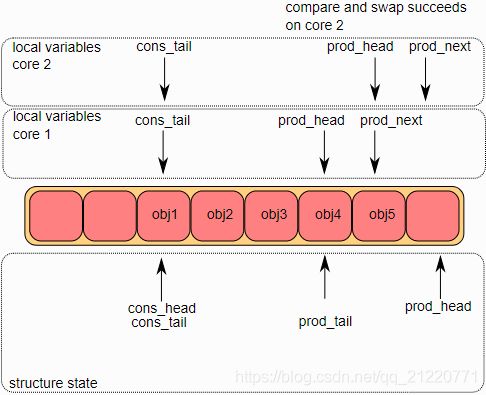
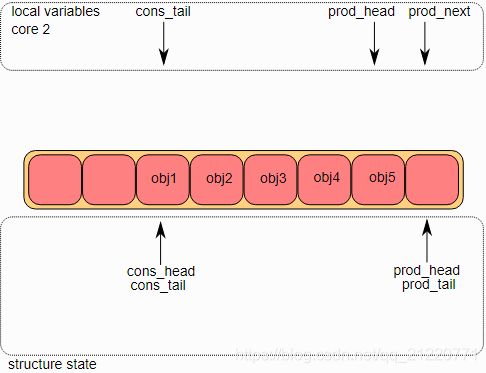
4.多生产者入队的第四步
现在每一个core要更新prod_tail。如果prod_tail等于prod_head的临时变量,那么就更新它。这个操作只是在core1进行。
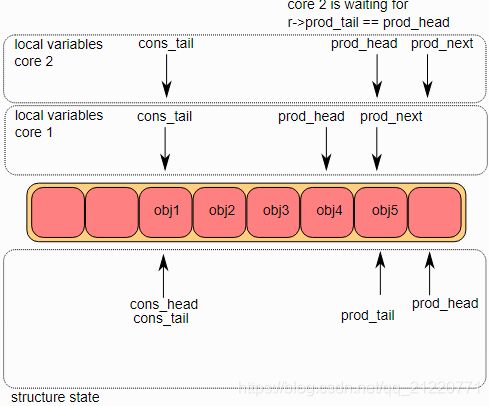
5.多生产者入队的第五步
一旦prod_tail在core1更新完成,那么也允许core2去更新它,这个操作也在core2上完成了。
- DPDK 库的代码分析:
队列头结构:
struct rte_ring {
char name[RTE_MEMZONE_NAMESIZE] __rte_cache_aligned; /**< Ring实例的名字. */
int flags; /**< 设置队列属性. */
const struct rte_memzone *memzone;/* 队列元素的内存区 */
uint32_t size; /**< 队列大小2的次幂. */
uint32_t mask; /**< 队列大小的掩码. */
uint32_t capacity; /**< 队列的容量 */
char pad0 __rte_cache_aligned; /**< empty cache line */
/** Ring 生产者. */
struct rte_ring_headtail prod __rte_cache_aligned;
char pad1 __rte_cache_aligned; /**< empty cache line */
/** Ring 消费者. */
struct rte_ring_headtail cons __rte_cache_aligned;
char pad2 __rte_cache_aligned; /**< empty cache line */
};
入队操作
static __rte_always_inline unsigned int
__rte_ring_do_enqueue(struct rte_ring *r, void * const *obj_table,
unsigned int n, enum rte_ring_queue_behavior behavior,
unsigned int is_sp, unsigned int *free_space)
{
uint32_t prod_head, prod_next;
uint32_t free_entries;
/* 移动生产者头 */
n = __rte_ring_move_prod_head(r, is_sp, n, behavior,
&prod_head, &prod_next, &free_entries);
if (n == 0)
goto end;
/* 向队列中添加元素 */
ENQUEUE_PTRS(r, &r[1], prod_head, obj_table, n, void *);
/* 更新消费者尾 */
update_tail(&r->prod, prod_head, prod_next, is_sp, 1);
end:
if (free_space != NULL)
*free_space = free_entries - n;
return n;
}
/* 更新生产者头 */
static __rte_always_inline unsigned int
__rte_ring_move_prod_head(struct rte_ring *r, unsigned int is_sp,
unsigned int n, enum rte_ring_queue_behavior behavior,
uint32_t *old_head, uint32_t *new_head,
uint32_t *free_entries)
{
const uint32_t capacity = r->capacity;
unsigned int max = n;
int success;
do {
n = max;
*old_head = r->prod.head;
rte_smp_rmb();/* 添加读屏障,确保读消费者尾之前一定能读取消费者头的值 */
*free_entries = (capacity + r->cons.tail - *old_head);/* 获取空间的元素个数 */
if (unlikely(n > *free_entries))
n = (behavior == RTE_RING_QUEUE_FIXED) ?
0 : *free_entries;
if (n == 0)
return 0;
*new_head = *old_head + n;
if (is_sp)/* 若是单生产者,直接更新生产者头 */
r->prod.head = *new_head, success = 1;
else
/* 多生产者时,根据CAS指令更新生产者头,只有一个人可以更新成功 */
success = rte_atomic32_cmpset(&r->prod.head,
*old_head, *new_head);
} while (unlikely(success == 0));
return n;
}
/* 向队列中填充元素 */
#define ENQUEUE_PTRS(r, ring_start, prod_head, obj_table, n, obj_type) do { \
unsigned int i; \
const uint32_t size = (r)->size; \
uint32_t idx = prod_head & (r)->mask; /* 根据prod_head获取线性表中的实际位置 */\
obj_type *ring = (obj_type *)ring_start; \
if (likely(idx + n < size)) { \
/* 向线性表中添加数据,批量4个添加 */
for (i = 0; i < (n & ((~(unsigned)0x3))); i+=4, idx+=4) { \
ring[idx] = obj_table[i]; \
ring[idx+1] = obj_table[i+1]; \
ring[idx+2] = obj_table[i+2]; \
ring[idx+3] = obj_table[i+3]; \
} \
switch (n & 0x3) { \
case 3: \
ring[idx++] = obj_table[i++]; /* fallthrough */ \
case 2: \
ring[idx++] = obj_table[i++]; /* fallthrough */ \
case 1: \
ring[idx++] = obj_table[i++]; \
} \
} else { /* 线性表的边界处理 */\
for (i = 0; idx < size; i++, idx++)\
ring[idx] = obj_table[i]; \
for (idx = 0; i < n; i++, idx++) \
ring[idx] = obj_table[i]; \
} \
} while (0)
/* 更新生产者或消费者尾 */
static __rte_always_inline void
update_tail(struct rte_ring_headtail *ht, uint32_t old_val, uint32_t new_val,
uint32_t single, uint32_t enqueue)
{
/* 对于生产者加入写屏障,对于消费者加入读屏障 */
if (enqueue)
rte_smp_wmb();
else
rte_smp_rmb();
/* 此处加入屏障的原因就是表示如果生产者或消费者尾已更新,则可说明我已完成入队或出队 */
/**
* 此处的old_val为本地生产者或消费者头 。
* 若tail != 本地head,表示其他core优先本core更新头但是没有更新tail
* 所以要等于其他core更新完tail,本core才能更新tail
*/
if (!single)/* 若是多生产者或消费者 */
while (unlikely(ht->tail != old_val))
rte_pause();
ht->tail = new_val;
}
__rte_ring_move_cons_head(更新消费者头) 原理同__rte_ring_move_prod_head
DEQUEUE_PTRS(元素出队) 原理同ENQUEUE_PTRS
- 思考
- 为什么生产者头和消费者头需要两个指针?
- 单消费者单生产者为什么可以无锁?
- prod_head 、prod_tail、cons_head、cons_tail都是4个字节。如果运用一个Ring实例,会不断出/入队,会不会溢出?若溢出了,会不会有bug?
- 为什么入队出队元素的时候4个一处理?
- struct rte_ring 中 struct rte_ring_headtail prod 和struct rte_ring_headtail cons可不可以放到一个cache行中?
- 为什么struct rte_ring_headtail prod已经独占一个cache 行,还要加一个cahce行(pad1);为什么struct rte_ring_headtail cons 已经独占一个cache 行,还要加一个cahce行(pad2)?