###好好好#####bert详解(实战)上
写这篇文章的时候,跳过了两个专题,因为BERT的确太火了,也比较实用吧,就拿最近的阅读理解比赛来说,几乎霸榜了,比如下面这个图:

之所以NLP这么多任务都会被刷新纪录,是因为BERT做的工作就是用来学习语言特征表达的,所以几乎只要是涉及到词向量的NLP任务都可以用到bert,而绝大部分NLP任务都会用到词向量,所以这就是BERT火的原因,对于新手来说,BERT的使用门槛无论从原理以及代码上看,的确比word2vec要高得多,所以这篇博客,我将详细记录我的使用心得。
这个系列我将分为BERT原理(上)、BERT代码使用说明(中)、BERT下游任务实战(下)三个部分讲一下我利用BERT的实战经历,其中第三个下游任务实战,我之前已经写过一篇在NER上的应用了也给出了代码,详情戳这里。下面就开始我的梳理。
BERT有那么玄乎么?
这个真没有,其实原理挺简单的,他并不是横空出世的一个东西,甚至可以说继承了好多前面的工作,接下来我就接着之前的第二篇博客语言模型与词向量后面讲。
前面讲到NNLM训练出来的词向量基本上可以代表一个词的含义了,最直观的体现就是可以拿他来做相似度匹配,找近义词,词向量火于2013年,知道现在我们依旧在使用它,即使是BERT也离不开这个东西,但是,但是,NNLM训练出来的词向量存在一个很大很大的问题:
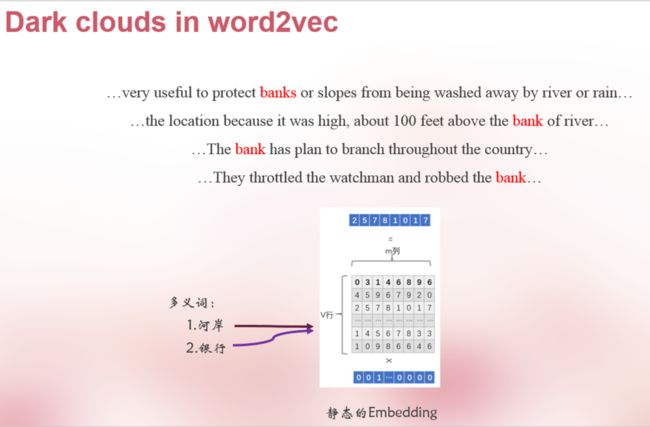
有人把word-embedding在多义词上的局限性称为是乌云真的一点都不为过,很显然多义词始终在embed矩阵中对应的同一行,这就是他的局限性。
为了打破这种局限,下面我谈一下比较重要的三个工作,ELMO,GPT,BERT。如何打破?
回想下我们是怎么用word embedding表示句子的,是把每个词通过look-up拼接成一个矩阵对吧,再往前想,就是用one-hot(id)通过一个已经训练好的线性的NNLM。我姑且把这种嵌入方式叫为static嵌入,那么,多义词无非就体现在上下文的语境上,那如果我把static embedding输入到训练好的lstm,这样出来的n-step个hidden向量是不是就动态的了,包含了上下文语境,简单来说单打独斗我刚不过,还不能叫帮手么,这就是ELMO的思想:


思路就是:embedding不再仅仅嵌入词语特征,还嵌入lstm通过大量网络学习到的参数特征,词向量和lstm学习到的权重一起嵌入到下游任务。
那它的使用方式呢?其实很Word2vec一样,加载参数么,文章在补充材料里面提到了在第一个epoch进行嵌入后的微调操作,没写在正文里,好多人拿这点说事儿,我倒觉得问题不在这里,这里举一个NER的例子:

再来,这个模型有没有问题呢?
我们来回顾下历史,看看Word2vec是怎么做的,为啥这么说NNLM的核心是DNN,而Word2vec呢?简化版的NNLM,怎么简化的,就是线性变换嘛,那ELMO呢,的确在word-embeding上加LSTM显得有点点笨拙,而且当时GOOGLE已经提出了Transformer了,所以GPT模型就是在这上下文建模上做的优化,利用了Transformer。

这里不了解Transformer的我简单提一下,实际上这个工作至关重要,我先再贴两个图:
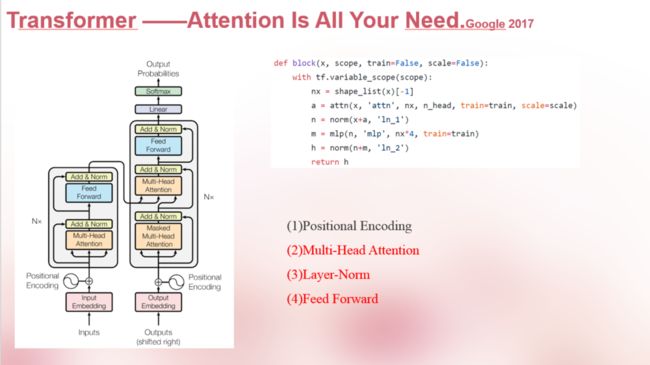
这张图是一个Encoder-Decoder框架,lstm怎么做Encoder-Decoder想必大家都清楚,这里也是一样的,我们我里面的每一个Block实际上在作用上和lstm,cnn并没区别,只是功效不同,简单来讲Transformer就是self-attention的叠加。那好,Transformer的Encoder和Decoder有没有区别,是有的,这也是GPT和BERT的区别,好多博客将GPT用的是Transformer的Decoder部分,Bert用的是Encoder部分,这没错,不过应该有人看到这还是懵的状态,区别就在masked attention上,说白了就是attention的叠加方向不一样,模型真没啥区别,再往细里说,Decoder之所以是masked attention,因为是解码嘛,自然在做attention时候不能给词语看到未来信息,比如下面这个图:
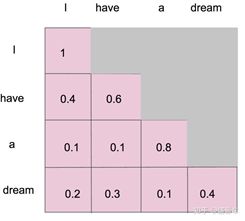
所以咯GPT用的就是Decoder部分:
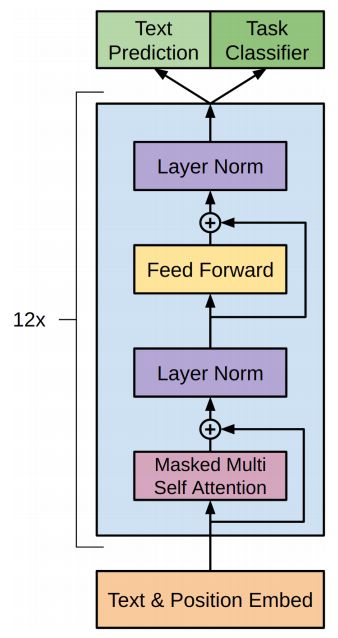
训练方式和NNLM一样,不是word2vec喔,是NNLM,利用前n-1个词预测第n个词训练词向量。
再来,Transformer在做embedding比lstm好在哪里?

这里我谈一下我的个人理解,lstm时序建模原理上可以处理无限长的句子,实际上呢,200个词撑死了吧,这样信息的确不全,所以大多数是在lstm上加Attention,那好,self-attention呢?这种叠加的Attention机制是直接算两个词之间的关系权重,然后累加到一个词上,这样每个词在计算时由于是直接计算的,距离就是1,当然这是我的个人理解,不过从现在的结果上看,在词向量的训练上(不含其它任务)Transformer要好的多。
最后来谈BERT。
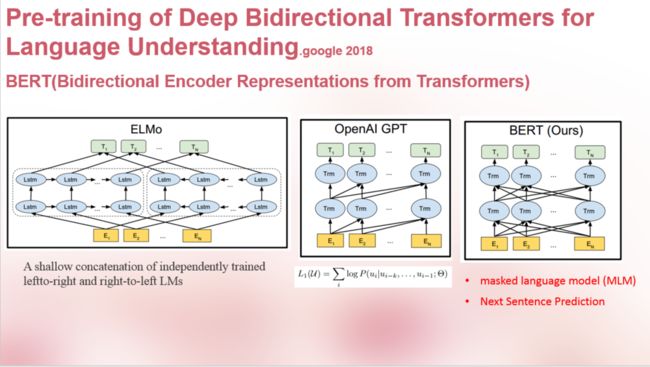
这三个图很直观了吧,既然GPT和BERT都用的Transform,为啥BERT是双向?有些博客怎么讲都不清楚,估计也是他们没理解,答案刚才就说了,就是attention的叠加方向,就是attention的叠加方向,就是attention的叠加方向。再说直白点,BERT的训练思路和word2vec的CBOW训练思路一样,利用上下文预测中间词,自然用不上masked attention 啦,GPT呢?训练思路和NNLM一样,这就是区别。
BERT怎么训练?


两个点:
1.对中间的词利用一定规则变成mask,啥规则建议看代码和论文吧。然后把这些要预测的词做成标签进行预测。
2.多任务:预测两个句子是不是有关联性(这里对语料的结构有新的要求)
最后怎么使用呢?Google这次真的很良心,论文很精品,开源也做得好,来看一下施工图:

这个图在我第一篇博客有提到,总的来说,有了施工图 ,到什么山唱什么歌,怎么用都行,我之前举例个NER的例子,给了代码,可以去看看。
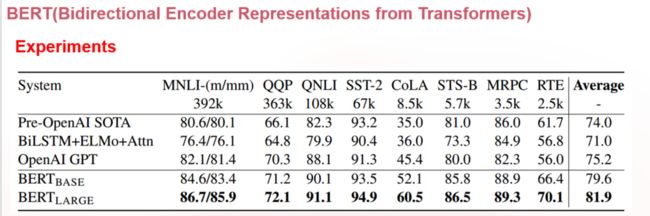
最后贴下论文的实验结果做个结束吧!
接下来我会挖掘BERT的源代码,写个教程在下篇文章中,实际上之前已经做过一部分了