机器学习之如何评价分类算法(混淆矩阵(confusion Matrix),精准率,召回率,F1 score,PR曲线,ROC曲线,评价多分类算法)
我们一般在sklearn中使用score值来看我们的预测结果,也就是我们的分类准确度
使用准确度这个指标在通常情况下是可以的,但是对我们的一些极度偏斜的数据,却会产生问题:
比如说 我们有一个癌症预测系统,预测准确度达到了99.9%,如果我们只是用score来看,这个系统算是非常好的系统了
但是考虑到,如果是我们的癌症率只有0.1%呢?我们只要不管是否得癌症,我就让这个系统预测没有得癌症,最后也能得到99.9%的准确率,这个结果显然不是我们想到的。所以我们需要引入其他的指标来衡量我们的分类算法。
在说其他指标前,我们先来看下什么叫 混淆矩阵(confusion Matrix):
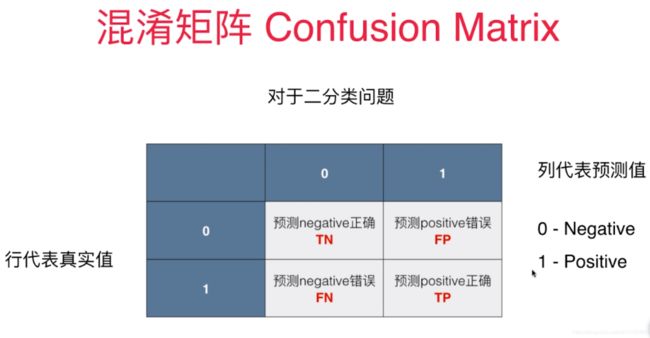
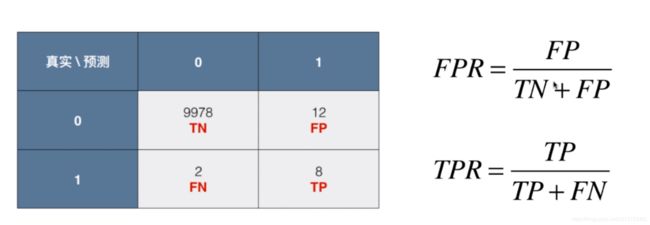
如图显示,对我们的一个二分类问题来说,我们画出一个3*3的矩阵,
我们的行表示我们的真实值,列表示我们的预测分类结果
0和1分别代表两个分类。我们使用negetive代表0,positive代表1
所以对于TN这个框,表示true negetive ,就是说我们的真实值为0,我们的预测结果也为0,所以预测 0这个类别正确
其他的3个框也同理,F代表false。
我们代入具体的数据
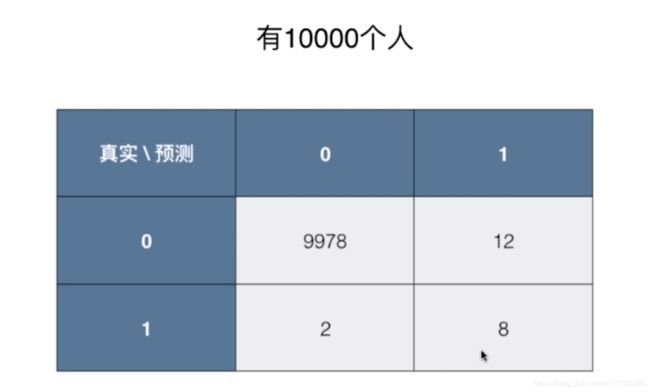
我们有10000个人,1代表得癌症的人数,0代表没有得癌症的概率
所以图中这个矩阵的意思就是10000个人中,真实数据表示有9978+12人没有癌症,但是我们将其中的12人预测为得了癌症。
有2+8人得了癌症,我们预测正确了8人得了癌症,预测了其中2人没有得癌症。
我们了解了混淆矩阵的含义,有混淆矩阵,我们引出我们的精准率(precision)和召回率(recall)这两个指标,
给出这两个指标的计算公式。我们来看下什么意思
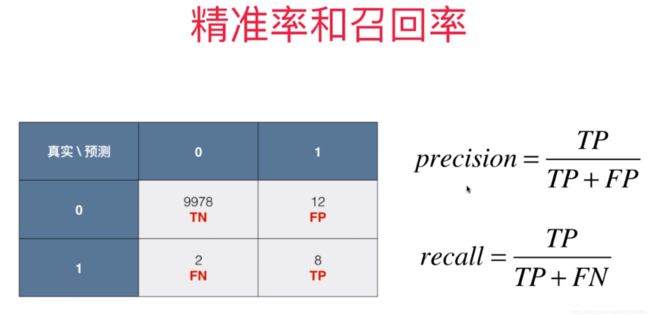
对我们的精准率来说,我们预测出了其中有20(8+12)人得了癌症,但是,这个20人当中,只有8个人得了癌症。 所以我们的精准率为8/(12+8) =0.4 换句话说:如果有100个人预测,我们通过精准率说明我们预测癌症成功的概率为40%。
对我们的召回率来说,我们实际有10(2+8)人得了癌症,但是,我们只预测对了其中的8人,所以我们的召回率为8/(2+8)=0.8.
换句话说就是10个人都得了癌症让系统去预测,系统只预测了出其中的8人,击中了其中的8人,还2个人没有get到他们点上
我们在这种极度偏差的数据中,通常使用我们比较关心的数据和预测结果来对我们精准率做计算。比如图中我们会比较关心多少人得了癌症。
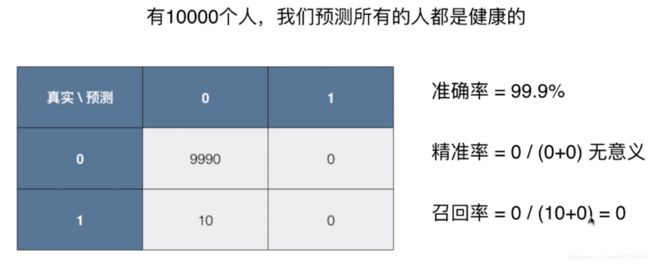
我们再回到一开始提的那个直接全部预测没有的癌症的例子代入混淆矩阵
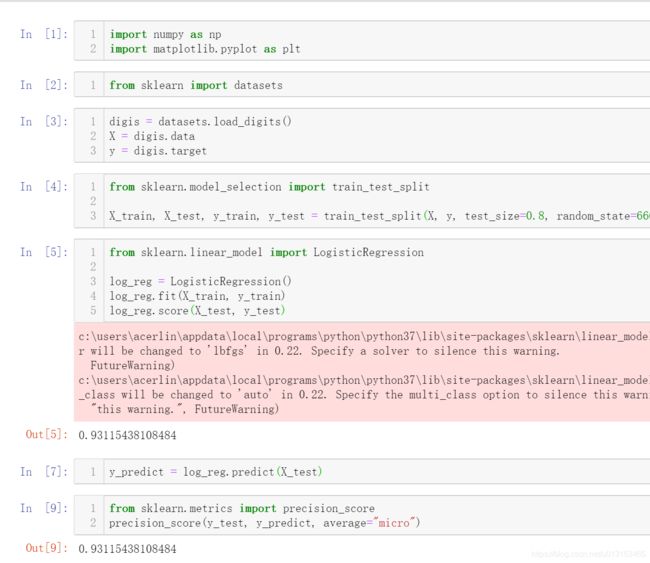
看下sklearn中的实现

对于我们精准率和召回率,我们要如何取舍?主要还是取决于我们模型关心的结果怎么区分。
比如我们一个股票预测的系统,如果我们去预测股票的涨跌,那我们就更关心股票的精准率,10次股票上升,我们只击中了其中8次,2次没击中,我们并没有投钱进去,显然结果是可控的,也就是召回率是80%。如果10次预测,实际4次上涨,6次下跌,我们全预测上涨,精准率为40%,就亏钱。显然 这时候我们更关心精准率是否够高、
又比如病人预测系统,我们这时候显然是更关心召回率,我们希望的是每个得病的人都能预测出来。假设将没有病的人预测成有病,等下次进行复查的时候可以再次检查出来是否生病,显然这时候召回率就显得更重要。
当然我们有时候2个指标都需要。这时候结合两个指标,最简单的办法就是取2个指标的平均值。我们这里就引入F1 score的概念
我们先来看下F1 score的公式: 1/F = 0.5*(1/precision + 1/recall)
所以得出
F = 2* precision*recall / (precision + recall)
这里我们使用的调和平均值,
使用调和平均值,不使用算数平均值的原因是因为 当我们两个值相差比较大的时候,例如0.1和0.9 算数平均值得出值会取中间0.5,而调和平均值只有在两个数都很大的时候,才能取到较大的值。而相对于0.1和0.9得出的F1 score就会很小。
其实,我们通过上面的说明,我们可以看出,我们的精准率和召回率是相互制约的。精准率变大,召回率就会相应的变小,反之也成立。
在我们的逻辑回归中,我们默认取一个决策边界为0,来作为我们的分类依据,所以我们的精准率和召回率的计算过程如下图

如果我们需要对精准率和召回率做平衡的话,我们需要我们改变我们的决策边界来平衡我们的精准率和召回率。
我们只需要改变score的array集合中的决策边界来改变预测值就行了。
代码如下

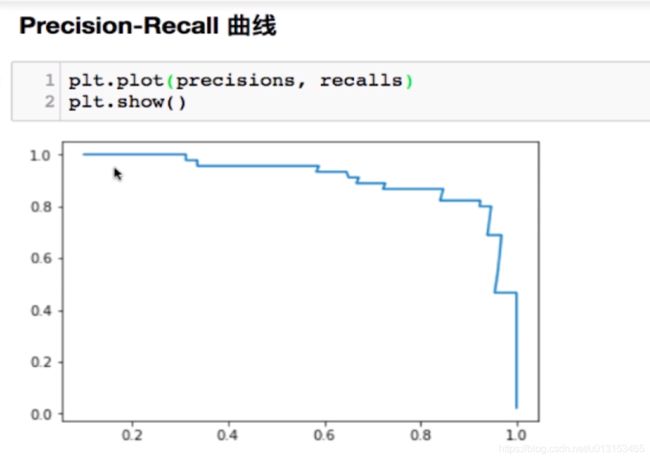
评价我们PR的好坏,首先我们使用我们的PR曲线来看
还有一种ROC曲线,通过面积大小来评价我们的模型的好坏

什么是TPR和FPR呢?我们先看图
TPR很简单,就是我们的recall
表示我们预测正确的真实值占全部真实值的百分比(这里我们还是用关心的类别来考虑,我们在癌症系统中显然更关心得癌症的人的个数)
FPR有公式就可得知。就是我们将多少的没有得癌症的人预测成了得癌症的百分比
不管是TPR还是FPR,都是使用预测值为1(也就是得癌症的人作为我们的分子)
结合上面的原点和星星图
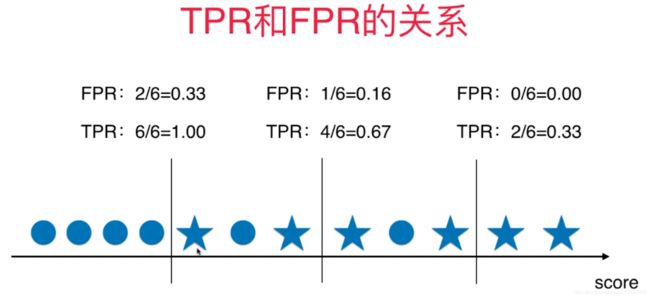
可以看出来,TPR和FPR是成正比的,TPR越大,FPR越大。反之TPR越小,FPR也越小
我们接下去绘制ROC曲线。
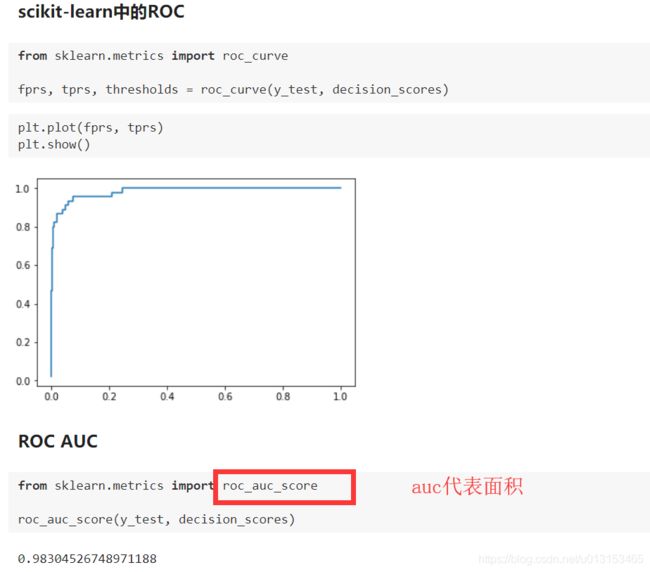
面积越大,代表我们的模型越好。
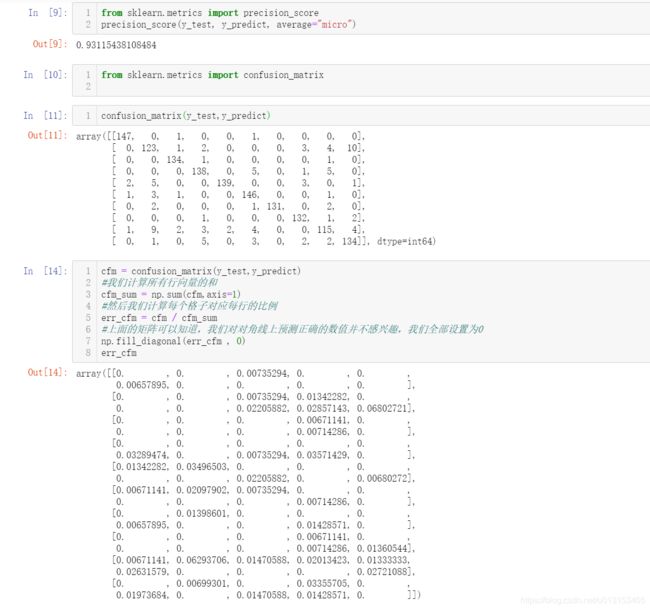
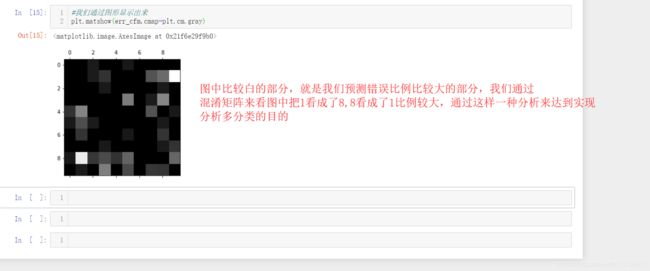
最后我们来看看,如何用混淆矩阵评价多分类的问题
直接上代码吧: