Practical Byzantine Fault Tolerance
来自论文Practical Byzantine Fault Tolerance
本文旨在进行Byzantine faults的容错,文章开门见山提出了新算法的优势:可工作在异步环境(如Internet),响应时间可以获得比之前算法超过一个数量级的提升。当然肯定会有limitation伴随,我们试着找出它们。
一开始文章就告诉我们有一个问题还没能解决:fault-tolerant privacy。
►Normal-Case Operation
提出了Buffered requests,可以减少系统负载沉重时的message traffic和CPU overheads,不过这似乎并不是本文的重点,因此被忽略了。
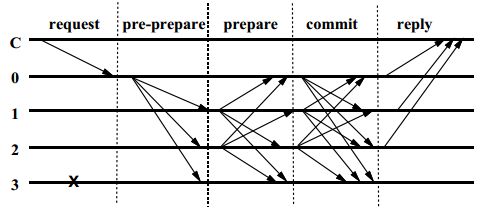
模型采取了Client -> Primary -> Backups的流程,即Client先将请求发给Primary,再由Primary通过一个三阶段协议广播给Backups。先来看一看这个三阶段:pre-prepare, prepare, commit。
在pre-prepare阶段,primary会给请求分配一个序号n,然后向所有的backups发送一个prepare message with m piggybacked,并将这个message加到它的log中。这个message的形式是
![]()
v指的是发送信息所在的view,m是client的request message,d是m的摘要。
但请求并不包含在pre-prepare信息中,避免信息过大。那Primary发送这个信息的目的何在?如果Backup i接受到这个信息后,就会进入prepare阶段,它会想其他所有的replicas发送一个信息如下,
![]()
并将此信息记录在自己的log中,如果没接收到,就什么也不做。一个replica(包括primary)接收这些prepare messages,如果它们的signatures是正确的,它们的view number等于这个replica当前的view,并且它们的序号在h和H之间,那么就将这些信息加到它的log中。之后就是commit阶段,这个replica会向其它replicas发送信息:
![]()
,同样当这个信息合理时,replicas会将它们插入到自己的log中。
Pre-prepare和prepare阶段的目的在于保证没有出错的replicas在一个view中对一个全序的请求序列达成一致。Commit阶段之后就可以确保让每个non-faulty replicas以相同的次序执行请求并给client发一个回复。下面是这个过程的流程:
►Non-Determinism
对于文件的修改时间,如果以每台机器上的local clock来定就会出现分歧,出现non-determinism,所以就需要一种机制让所有的replicas选择同一个值作为修改时间,我们又不能让client提前选择这个值,因为它并不清楚它提出的请求与其它clients提出的请求是如何被安排顺序的。最终这事就交给了primary,由它选出non-determinism值,然后经过三阶段协议让non-faulty replicas在其上达成一致。
►Reducing Communication
我们都知道,最后所有的replicas都会将各自执行的结果返回给client,如果回复很多,势必会带来较大的网络带宽消耗和CPU overhead,这里采取的优化措施是让一个replica返回完整的结果,而其它replicas返回结果的一个摘要,不过这个摘要能用来验证结果的正确与否。
►Cryptography
文章的一个改进是在发送view-change和new-view 这些不经常发送的信息时使用传统的digital signature,而对于频繁发送的其它信息时使用MACs,这会消除主要的性能瓶颈。
►Implementation
Snfsd在memory mapped file中直接执行文件系统操作,这样保持住了locality,而且它使用写时拷贝来减少与维护checkpoints有关的空间和时间overhead。
►Related Work
以前大多数的有关复制技术的工作都忽略了Byzantine故障,也都假设了一个同步系统模型,所以论文的主要工作就为这两个目的而来。传统的Viewstamped replication和大名鼎鼎的Paxos也只能容忍异步系统中的良性错误,它们对fault tolerance的支持并不是很完备。其实要容错拜占庭故障需要很复杂的使用密码鉴别技术的协议,并要有pre-prepare阶段,以及view-change来选择primary。也许是本文的一个advantage:通过view changes选择出一个新的primary,而不是选择一个不同的replicas集合来形成一个新的view。
之前也有过一些一致性协议能容错Byzantine故障,不过是在异步系统中,而且它们并没有提供一个完整的解决方案来进行状态机复制,而且并不能马上用于实践,而本文的算法既进行了正常情况下的Byzantine故障容错,也考虑了primary出错的情况。
而且通过与类似模型Rampart和SecureRing的比较,本文的模型在速度上要快一个数量级。在异步系统中,这两个模型为了检查出哪个replica出错所使用的failure detectors技术不会准确,所以它们在异步系统中会出现误判,而本文的模型可以做到。更重要的是,这两个模型会将故障的replicas排除出group,同时因为误判也会将没有故障的replicas排除出组。而本文提出的模型不会将replicas排除出group,所以就不用担心这个问题。
Phalanx也是一个可以用于异步环境的Byzantine故障容错模型,不过本文的模型要快于它,因为本文的模型由于使用MACs而不是public key cryptography在关键路径上有较少的信息延迟。
►Conclusions
作为一名读者我感觉本文提出的模型的advantages有:
(i)实现了Byzantine故障的容错
(ii)它是第一个能在一个异步环境(如Internet)正确工作的模型,并且相比于之前的算法在性能上提高了一个数量级还多
(iii)将模型用在了NFS中,实现了BFS,并且采取了一些列优化措施:用MACs代替public-key signatures,减少信息的数量和大小,还有一个incremental checkpoint-management技术
(iiii)当出现了software errors时,使用这个算法的系统仍然正常工作,当然如果所有的replicas都出现了这个software error,也是无能为力的,但对于在不同replicas中独立发生的错误,包括nondeterministic software errors这些很难检测的错误,本文的算法还是能mask掉的。
再来说一下本文算法的limitations:
减少实现算法所需要资源的数量,如减少replicas的数量,减少copies of the state的数量。