Selenium模拟浏览器入门实战(+PhantomJS):漫画爬虫
虽然自2018年开始,PhantomJS暂停开发,而且新版本Selenium不再支持PhantomJS,而是推荐使用谷歌或者火狐无界面浏览器,但是现在仍然可以使用Selenium+PhantomJS,只是warning而已。
这里有篇博客以供参考:https://blog.csdn.net/u010358168/article/details/79749149
Selenium模拟浏览器
Python网络爬虫中最麻烦的就是那些通过JavaScript获取数据的站点。Python对JS的支持不太好,想用Python获取网站中JavaScript返回的数据,唯一的方法就是模拟浏览器了。
安装Selenium模块
Selenium是一套完整的Web应用程序测试系统,其核心Selenium Core基于JsUnit,完全由JavaScript编写,因此可运行于任何支持JavaScript的浏览器上。
Windows下安装Selenium模块:
python -m pip install -U selenium在编写Python网络爬虫的时候,主要用到Selenium的Webdriver。Selenium.Webdriver不可能支持所有浏览器,查看Webdriver支持列表,打开cmd执行命令:
python
from selenium import webdriver
help(webdriver)执行结果:
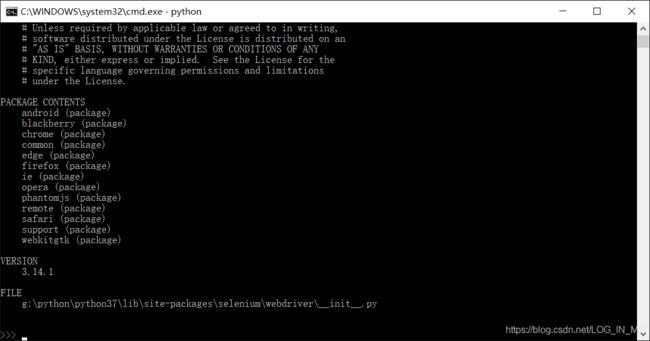
可以看出所支持的浏览器,其中PhantomJS是一个基于WebKit的服务端JavaScript API。它全面支持 Web而不需浏览器支持,其快速原生支持各种Web标准:DOM处理、CSS选择器、JSON、Canvas和SVG。PhantomJS可用于页面自动化、网络监测、页面截屏以及无界面测试等。
无界面意味着开销小速度快,以前网上有牛人测试过,使用Selenium调用上面的浏览器,速度前三分别是PhantomJS、Chrome、IE,现在呢Chrome和Firefox推出了无界面浏览器,所以Selenium开始推荐使用Chrome和Firefox的无界面浏览器了。(但本文还是使用PhantomJS)
Windows下安装PhantomJS
进入PhantomJS官网下载页:https://phantomjs.org/download.html,Download V2.1(这是官方认定的暂停开发前最稳定的版本),下载完成后解压,将.exe文件复制到Python的目录中就行了。(需要将.exe文件加入到系统路径中,由于Python已经加入到系统路径中且是配合Python使用的,所以干脆将其放到Python目录中就可以了。)
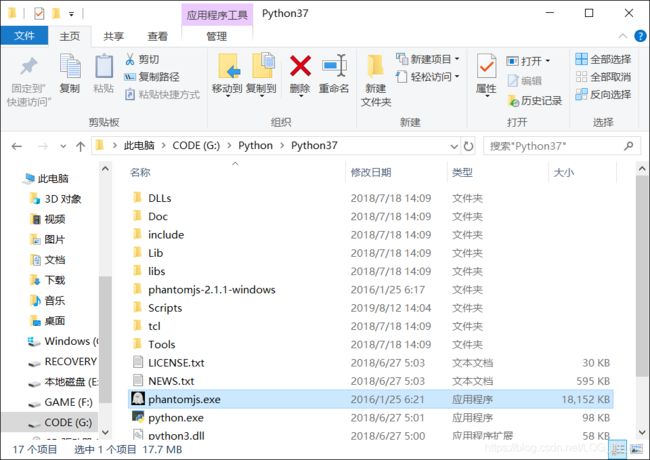
Selenium+PhantomJS抓取数据
首先要引入Selenium.Webdriver,连接PhantomJS:
from selenium import webdriver
browser = webdriver.PhantomJS()然后三步走:
1、获取页面响应内容。
browser.get(url) #get方法请求网页
browser.implicitly_wait(10)
# PhantomJS解释浏览器是需要时间的,给implicity_wait()一个时间参数,
# implicitly_wait()会智能等待,只要解释完成了就进行下一步操作。
# 当然可以使用time.sleep()强行休眠一段时间,但是时间不好掌握。
html = browser.page_source #获取返回的数据可以使用page_source方法
2、定位要爬取的数据。
定位html标签元素selenium含有以下18个函数:

可以对定位的元素进行操作,即模拟浏览器操作:
#定位到百度首页的输入框
textElement=browser.find_element_by_id('kw')
#向输入框装填数据
textElement.send_keys('Python selenium')
#定位到提交按钮
submitElement=browser.find_element_by_id('su')
#对该元素执行点击操作
submitElement.click()selenium常用函数:https://blog.csdn.net/poppy3163/article/details/78044122
3、获取要爬取的数据。
element.text #获取element标签里的文字
element.get_attribute(name) #获取element中某个属性值爬取极速漫画实战:
极速漫画网址:http://www.1kkk.com/
随便找一篇漫画《我的男友风净尘》,进入第一章第一页:http://www.1kkk.com/ch1-866831/#ipg1
想要爬取第一章的漫画保存在自定义的文件夹里。
from selenium import webdriver
import logging
import os
import time
import requests
import codecs
class getCartoon(object):
#可以理解为构造函数
def __init__(self):
self.startUrl='http://www.1kkk.com/ch1-866831/#ipg1'
self.browser=self.getBrowser() #获取网页
self.saveCartoon(self.browser) #定位内容,保存漫画
#获取网页
def getBrowser(self):
browser=webdriver.PhantomJS()
try:
browser.get(self.startUrl)
browser.implicitly_wait(10)
except:
logging.error('open the url failed')
return browser
#保存漫画
def saveCartoon(self, browser):
cartoonTitle=browser.title.split('_')[0] #获取网页title以_分割,取出分割后数组第一个赋给cartoonTitle变量
self.createDir(cartoonTitle) #新建文件夹,以cartoonTitle为名
os.chdir(cartoonTitle) #将输入流切换到当前路径
sumPage=int(browser.find_element_by_xpath('//*[@id="chapterpager"]/a[8]').text) #获取该章节的页数
i=1
#循环一页一页地爬
while i<=sumPage:
imgName=str(i)+'.png'
imgElement=browser.find_element_by_xpath('//*[@id="cp_image"]') #匹配到漫画图片的![]() 元素
imgUrl=imgElement.get_attribute('src') #获取
元素
imgUrl=imgElement.get_attribute('src') #获取![]() 标签里的src属性值,即图片链接
print(imgUrl)
#使用requests请求imgUrl
response=requests.get(imgUrl)
with codecs.open(imgName,'ab') as fp:
fp.write(response.content)
logging.info('save img %s' %imgName)
i+=1
#模拟点击下一页
nextTag=browser.find_element_by_xpath('/html/body/div[7]/div/a[2]')
nextTag.click() #模拟点击操作
browser.implicitly_wait(20) #等待加载页面
time.sleep(5)
logging.info('save img successs')
exit()
#创建新路径,新建文件夹
def createDir(self, dirName):
if os.path.exists(dirName):
logging.error('create directory %s failed, have a same name file or directory' %dirName)
else:
try:
os.makedirs(dirName)#新建文件夹
except:
logging.error('create directory %s failed' %dirName)
else:
logging.info('create directory %s success' %dirName)
if __name__=='__main__':
getCartoon()
标签里的src属性值,即图片链接
print(imgUrl)
#使用requests请求imgUrl
response=requests.get(imgUrl)
with codecs.open(imgName,'ab') as fp:
fp.write(response.content)
logging.info('save img %s' %imgName)
i+=1
#模拟点击下一页
nextTag=browser.find_element_by_xpath('/html/body/div[7]/div/a[2]')
nextTag.click() #模拟点击操作
browser.implicitly_wait(20) #等待加载页面
time.sleep(5)
logging.info('save img successs')
exit()
#创建新路径,新建文件夹
def createDir(self, dirName):
if os.path.exists(dirName):
logging.error('create directory %s failed, have a same name file or directory' %dirName)
else:
try:
os.makedirs(dirName)#新建文件夹
except:
logging.error('create directory %s failed' %dirName)
else:
logging.info('create directory %s success' %dirName)
if __name__=='__main__':
getCartoon()查看爬取结果:
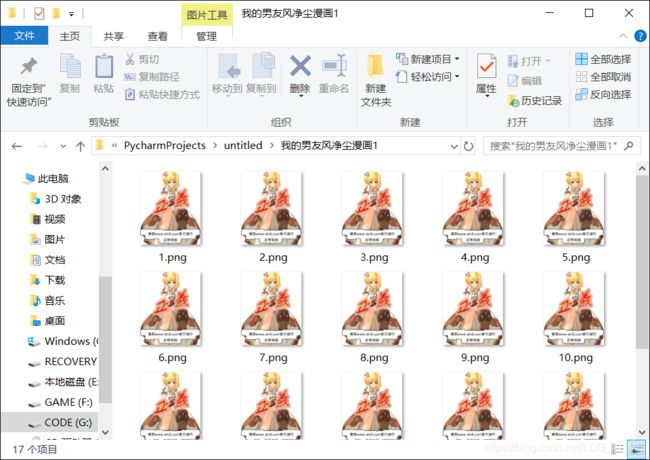
发现,这个网站在防盗链上做的很到位,只要在页面上执行一次刷新操作,网站就判为盗链,显示出防止盗链的图片,并且得到的图片链接地址也无法下载。
所以干脆我就截图保存下来,不下载了:
将下载图片文件的操作:
imgElement=browser.find_element_by_xpath('//*[@id="cp_image"]') #匹配到漫画图片的![]() 元素
imgUrl=imgElement.get_attribute('src') #获取
元素
imgUrl=imgElement.get_attribute('src') #获取![]() 标签里的src属性值,即图片链接
print(imgUrl)
#使用requests请求imgUrl
response=requests.get(imgUrl)
with codecs.open(imgName,'ab') as fp:
fp.write(response.content)
logging.info('save img %s' %imgName)
标签里的src属性值,即图片链接
print(imgUrl)
#使用requests请求imgUrl
response=requests.get(imgUrl)
with codecs.open(imgName,'ab') as fp:
fp.write(response.content)
logging.info('save img %s' %imgName)换成对整个页面截屏的操作:
browser.get_screenshot_as_file(imgName) #对整个页面进行截图存为图片再次运行:

成功。