import pandas as pd %pylab
一.使用numpy创建
df = pd.DataFrame(np.arange(16).reshape((4,4)), index=list('abcd'), columns=['one','two','three','four']) df

二.由Series组成的字典
df3 = pd.DataFrame({'one':pd.Series([0,1,2,3]),
'two':pd.Series([4,5,6,7]),
'three':pd.Series([8,9,10,11]),
'four':pd.Series([12,13,14,15])},
columns=['one','two','three','four'])
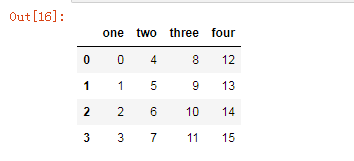
df3
自定义行索引;
df4 = pd.DataFrame({'one':pd.Series([0,1,2,3],index=list('abcd')),
'two':pd.Series([4,5,6,7],index=list('abcd')),
'three':pd.Series([8,9,10,11],index=list('abcd')),
'four':pd.Series([12,13,14,15],index=list('abcd'))},
columns=['one','two','three','four'])
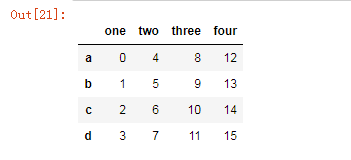
df4
总结:
由Series组成的字典,创建Dataframe, columns为字典key, index为Series的标签(如果
Series没有指定标签,则默认数字标签)
三.由字典或者series组成的列表
data = [{"one":1,"two":2},
{"one":5,"two":10,
"three":15}]
df6 = pd.DataFrame(data)
df6
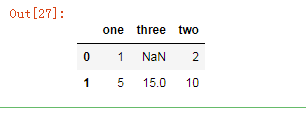
输出为:
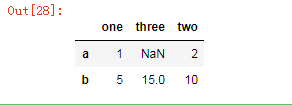
指定行索引,列名:
df7 = pd.DataFrame(data, index = ["a", "b"]) df7
df4 = pd.DataFrame(data, columns = ["one", "two", "three"],index=['a','b'])
总结:
由字典组成的列表创建Dataframe, columns为字典的key, index不做指定默认为数字标签,
pandas会自动为行,列索引排序;但是如果在pd.dataframe()的参数中指定了index和columns的值,行和列的索引就会按照指定的值排列
四.由字典组成的字典
data = { "Jack":{"math":90, "english":89, "art":78}, "Marry":{"math":82, "english":95, "art":96}, "Tom":{"math":85, "english":94} } df1 = pd.DataFrame(data) df1
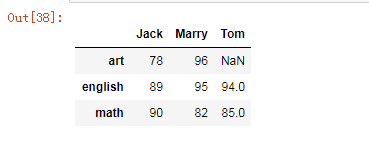
总结:
字典的健值作为dataframe的columns
如果没有指定index参数的值,行索引使用默认的数字索引
每个序列的长度必须相同
同样的,pandas会对会对列索引排序,如果显示的传入columns参数,将按照传入的值得顺序显示