C1W1-09_logistic-regression-overview
视频链接
You will now get an overview of logistic regression. Previously, you learned to extract features, and now you will use those extracted features to predict whether a tweet has a positive sentiment or a negative sentiment. Logistic regression makes use of a sigmoid function which outputs a probabilily between zero and one. Let’s take a look at the overview of logistic regression. Just a quick recap. In supervised machine learning, you have input features and a set of labels. To make predictions based on your data, you use a function with some parameters to map your features to output labels. To get an optimum mapping from your features to labels, you minimize the cost function which works be comparing how closely your output Y hat is to the true labels Y from your data. After which the parameters are updated and you repeat the process until your cost is minimized. For logistic regression, this function F is equal to the sigmoid function.
现在回顾下逻辑回归。先前你学习了提取特征,现在你将使用这些已提取的特征来预测是否一个推文有一个正向情绪或是一个负向情绪。逻辑回归使用了一个sigmoid函数,输出一个在0到1之间的概率。让我们回顾下逻辑回归。简单回归下。在监督机器学习中,你输入特征和一组标签。为了基于你的数据做预测,你使用一个带有一些参数来映射你的特征的函数来输出标签。为了得到一个从你的特征到标签的最佳映射,你将成本函数最小化,这个函数用来比较你的输出值 Y ^ \hat{Y} Y^和数据中真实标签 Y Y Y有多接近。在参数被更新后,你重复这个过程直到你的成本最小化。对于逻辑回归,这个函数F等同于sigmoid函数。

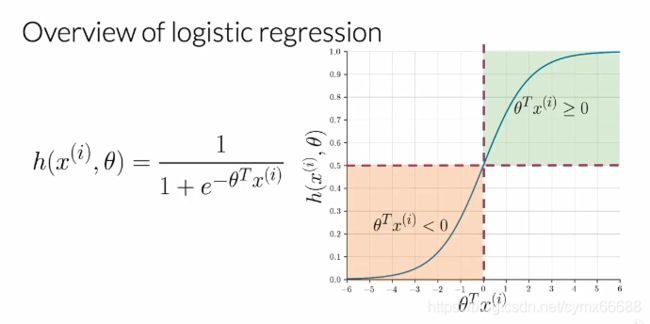
The function used to classify in logistic regression H is the sigmoid function and it depends on the parameters Theta and then the features vector X superscripts i, where i is used to denote the ith observation or data points. In the context of tweets, that’s the ith tweets. Visually, the sigmoid function has this form and it approaches zero as the dot product of Theta transpose X, over here, approaches minus infinity and one as it approaches infinity.
For classification, a threshold is needed. Usually, it is set to be 0.5 and this value corresponds to a dot product between Theta transpose and X equal to zero. So whenever the dot product is greater or equal than zero, the prediction is positive, and whenever the dot product is less than zero, the prediction is negative.
逻辑回归中用于分类的函数H是个sigmoid函数,它取决于参数 θ \theta θ,然后特征向量 x i x^i xi, i i i用来表示第 i i i个观察值或数据点。在推文中,是第 i i i个推文。从视觉上看,sigmoid函数有这样的形式,它趋近于0,是 θ \theta θ转置与X的点乘,在这里,X趋近于负无穷,趋近于正无穷是1。对于分类,需要给定一个阈值。通常被设置为0.5,这个值相当于 θ \theta θ转置与X的点乘等于0。因此无论何时点乘是越来越大或大于等于0,预测是正的,无论何时点乘小于0,预测是负的。
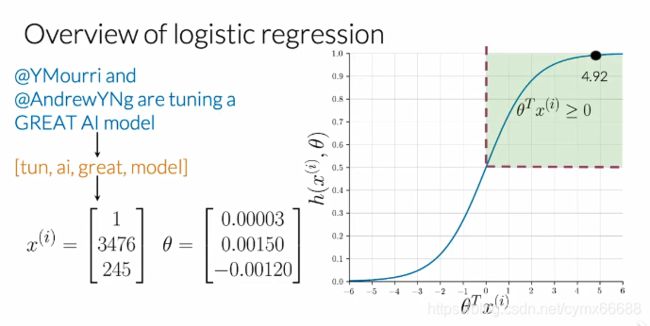
So let’s look at an example in the now familiar context of tweets and sentiment analysis. Look at the following tweet. After a preprocessing, you should end up with a list like this. Note that handles are deleted, everything is in lowercase and the word tuning is reduced to its stem, tun. Then you woluld be able to extract feature given a frequencies dictionary and arrive at a vector similiar to the following. With a bias units over here and two features that are the sum of positive and negative frequencies of all the words in your processed tweets. Now assuming that you already have an optimum sets of parameters Theta, you would be able to get the value of the sigmoid function, in this case, equal to 4.92, and finally, predict a positive sentiment.
让我们来看一个现在熟悉的推文和情感分析示例。看下面的推文。在预处理之后,你应该得到一个像这样的列表。请注意要把@的删除,所有都是小写,单词tuning减少到它的词干tun。然后你能够提取特征得到一个频率字典,得到一个与下面相似的向量。这里有一个偏置单位,还有两个特征是你已处理的推文中所有单词的正向频率和负向频率。现在假设你已经有一组最优参数 θ \theta θ,你能够得到sigmoid函数值,在这种情况下,等于4.92,最后,预测为一个正向情绪。
Now that you know the notation for logistic regression, you can use it to train a weight factor Theta.
现在你知道了逻辑回归的符号,你能使用它来训练一个权重因子 θ \theta θ。