IDEA开发Spark应用程序
文章目录
- 创建一个Maven项目,添加依赖
- 词频统计案例开发及上传jar包到服务器并准备测试数据
- jar包提交Spark应用程序运行
- 词频统计案例迭代之输出结果到HDFS
- 词频统计案例迭代之处理多个输入文件
- 词频统计案例迭代之输入文件规则匹配
- 带排序的词频统计案例开发及运行过程深度剖析
- 求用户访问量的TopN的Hive实现以及Spark Core实现过程分析
- 求平均年龄的Spark Core实现
- 求男女人数以及最高和最低身高
spark-shell适合做测试
如果是开发的话是用IDEA+Maven+Scala来开发Spark应用程序
创建一个Maven项目,添加依赖
前面创建的过程省略。
创建了一个Scala的Maven项目后,需要添加依赖什么的。
我这边pom.xml文件添加代码如下:
2.11.8
2.6.0-cdh5.7.0
2.4.0
org.apache.spark
spark-core_2.11
${spark.version}
org.scala-lang
scala-library
${scala.version}
org.apache.hadoop
hadoop-client
${hadoop.version}
添加之后,点击Reimport,重新导入一下

但是导入之后,Hadoop的有些没有导进来,红色波浪线,报错了:

需要加一个仓库repository:
http://repository.cloudera.com/artifactory/cloudera-repos/

继续点击到如下目录:
http://repository.cloudera.com/artifactory/cloudera-repos/org/apache/hadoop/hadoop-client/2.6.0-cdh5.7.0/
这个就是上面我们添加的2.6.0-cdh5.7.0/
如果写的是2.6.0-cdh5.7.0,就要加这个仓库,如果写的是2.6.0,不说cdh的就不用加这个仓库。

然后再pom.xml里添加一下
cloudera
cloudera
http://repository.cloudera.com/artifactory/cloudera-repos/
再重新导入一下,Reimport,发现还是红色波浪线,报错
clean一下:


发现BUILD SUCCESS,没问题,说明没有影响,可能是其它的一些jar包没有导进来,不过没有影响的。
好了,有了上面的操作,看源码就很方便了,直接搜索就可以看了。
比如,想看Hadoop的入口类:FileSystem的源码

点击一下,就可以看到源码了:

词频统计案例开发及上传jar包到服务器并准备测试数据
建个包:

建个scala对象

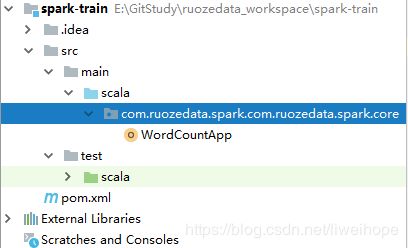
开发代码:
一开始的三步骤:首先构建一个sparkConf,再构建一个sc,然后关掉sc
package com.ruozedata.spark.com.ruozedata.spark.core
import org.apache.spark.{SparkConf, SparkContext}
object WordCountApp {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf()
val sc = new SparkContext(sparkConf)
//业务逻辑
sc.stop()
}
}
开发业务逻辑代码:wordcount代码
package com.ruozedata.spark.com.ruozedata.spark.core
import org.apache.spark.{SparkConf, SparkContext}
object WordCountApp {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf()
val sc = new SparkContext(sparkConf)
//args(0)表示传进来的第一个参数
val textFile = sc.textFile(args(0))
val wc = textFile.flatMap(line => line.split("\t")).map((_,1)).reduceByKey(_+_)
//打印出来
wc.collect().foreach(println)
sc.stop()
}
}
开发完成,代码打包
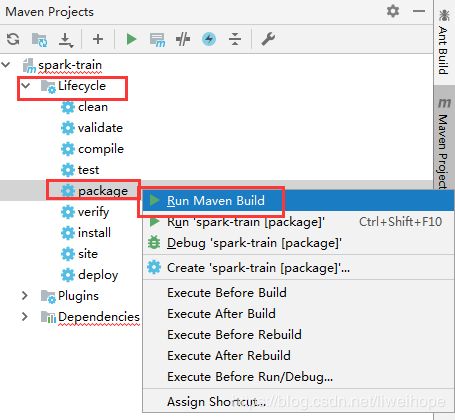
等一会,就打包成功了:

jjar包在这个目录:spark-train\target\spark-train-1.0.jar
然后把jar上传到虚拟机或者服务器上,
[hadoop@hadoop001 lib]$ pwd
/home/hadoop/lib
[hadoop@hadoop001 lib]$ ls
spark-train-1.0.jar
wordcount数据准备:
[hadoop@hadoop001 data]$ hdfs dfs -text /data/wordcount.txt
19/06/06 12:06:00 INFO lzo.GPLNativeCodeLoader: Loaded native gpl library from the embedded binaries
19/06/06 12:06:00 INFO lzo.LzoCodec: Successfully loaded & initialized native-lzo library [hadoop-lzo rev f1deea9a313f4017dd5323cb8bbb3732c1aaccc5]
world world hello
China hello
people person
love
jar包提交Spark应用程序运行
如何提交?看官网:

如何使用spark-submit,看帮助,spark-submit --help 看一下。

–class的获得,如下:

得到:–class com.ruozedata.spark.com.ruozedata.spark.core.WordCountApp
–master 为loacl[2]
application-jar的位置:/home/hadoop/lib/spark-train-1.0.jar
[application-arguments] 参数:hdfs://hadoop001:9000/data/wordcount.txt
汇总一下,如下:
./spark-submit \
--class com.ruozedata.spark.com.ruozedata.spark.core.WordCountApp \
--master local[2] \
/home/hadoop/lib/spark-train-1.0.jar \
hdfs://hadoop001:9000/data/wordcount.txt
运行结果:

词频统计案例迭代之输出结果到HDFS
加一个 wc.saveAsTextFile(args(1)):
package com.ruozedata.spark.com.ruozedata.spark.core
import org.apache.spark.{SparkConf, SparkContext}
object WordCountApp {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf()
val sc = new SparkContext(sparkConf)
val textFile = sc.textFile(args(0))
val wc = textFile.flatMap(line => line.split("\t")).map((_,1)).reduceByKey(_+_)
//wc.collect().foreach(println)
wc.saveAsTextFile(args(1))
sc.stop()
}
}
再打包上传,替换上面的jar包,再运行代码:
./spark-submit \
--class com.ruozedata.spark.com.ruozedata.spark.core.WordCountApp \
--master local[2] \
/home/hadoop/lib/spark-train-1.0.jar \
hdfs://hadoop001:9000/data/wordcount.txt \
hdfs://hadoop001:9000/data/wcoutput/
结果:

词频统计案例迭代之处理多个输入文件
多个文件如下:
[hadoop@hadoop001 lib]$ hdfs dfs -ls /data/wordcount/
Found 5 items
-rw-r--r-- 1 hadoop supergroup 49 2019-0 /data/wordcount/wordcount1.txt
-rw-r--r-- 1 hadoop supergroup 49 2019-0 /data/wordcount/wordcount2.txt
-rw-r--r-- 1 hadoop supergroup 49 2019-0 /data/wordcount/wordcount3.txt
-rw-r--r-- 1 hadoop supergroup 49 2019-0 /data/wordcount/wordcount4.txt
-rw-r--r-- 1 hadoop supergroup 49 2019-0 /data/wordcount/wordcount5.txt
执行代码:
./spark-submit \
--class com.ruozedata.spark.com.ruozedata.spark.core.WordCountApp \
--master local[2] \
/home/hadoop/lib/spark-train-1.0.jar \
hdfs://hadoop001:9000/data/wordcount/ \
hdfs://hadoop001:9000/data/wcoutput2/
执行结果如下:

词频统计案例迭代之输入文件规则匹配
文件如下:
[hadoop@hadoop001 lib]$ hdfs dfs -ls /data/wordcount/
Found 6 items
-rw-r--r-- 1 hadoop supergroup 49 2019-0 /data/wordcount/test
-rw-r--r-- 1 hadoop supergroup 49 2019-0 /data/wordcount/wordcount1.txt
-rw-r--r-- 1 hadoop supergroup 49 2019-0 /data/wordcount/wordcount2.txt
-rw-r--r-- 1 hadoop supergroup 49 2019-0 /data/wordcount/wordcount3.txt
-rw-r--r-- 1 hadoop supergroup 49 2019-0 /data/wordcount/wordcount4.txt
-rw-r--r-- 1 hadoop supergroup 49 2019-0 /data/wordcount/wordcount5.txt
执行代码
./spark-submit \
--class com.ruozedata.spark.com.ruozedata.spark.core.WordCountApp \
--master local[2] \
/home/hadoop/lib/spark-train-1.0.jar \
hdfs://hadoop001:9000/data/wordcount/*.txt \ //这里是文件规则匹配
hdfs://hadoop001:9000/data/wcoutput3/
结果如下:
还是5个,说明上面的那个test文件并没有作为输入。
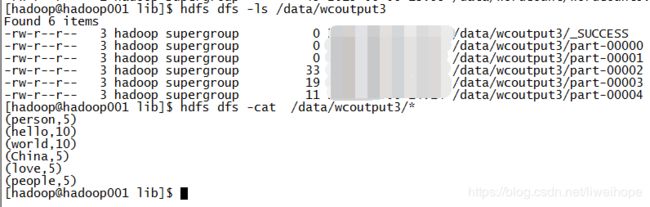
带排序的词频统计案例开发及运行过程深度剖析
代码如下:
package com.ruozedata.spark.com.ruozedata.spark.core
import org.apache.spark.{SparkConf, SparkContext}
object WordCountApp {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf()
val sc = new SparkContext(sparkConf)
val textFile = sc.textFile(args(0))
val wc = textFile.flatMap(line => line.split("\t")).map((_,1)).reduceByKey(_+_)
val sorted = wc.map(x => (x._2,x._1)).sortByKey(false).map(x => (x._2,x._1))
//这个在上一节已经有详细介绍
//wc.collect().foreach(println)
sorted.saveAsTextFile(args(1))
sc.stop()
}
}
打包上传,替换原有jar包,再执行代码:
./spark-submit \
--class com.ruozedata.spark.com.ruozedata.spark.core.WordCountApp \
--master local[2] \
/home/hadoop/lib/spark-train-1.0.jar \
hdfs://hadoop001:9000/data/wordcount/*.txt \
hdfs://hadoop001:9000/data/wcoutput4/
执行结果如下:
降序:

求用户访问量的TopN的Hive实现以及Spark Core实现过程分析
先用hive来实现:
创建一张表:
create table page_views(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
) row format delimited fields terminated by '\t';
加载数据进来:
load data local inpath '/home/hadoop/data/page_views.dat' overwrite into table page_views;
查询结果:
hive (g6)> select end_user_id,count(*) count from page_views group by end_user_id order by count desc limit 5;
.......省略....
end_user_id count
NULL 60871
123626648 40
116191447 38
122764680 34
85252419 30
Time taken: 43.963 seconds, Fetched: 5 row(s)
hive (g6)>
可以看到每个用户的id以及相应的访问数量。
再用Spark Core实现:求用户访问量的 top5 。
拿到需求,进行分析,然后功能拆解(中文描述出来,详细设计说明书),最后是代码的开发实现。
首先拿到一个文件,里面有很多行,每行好几个字段,用户的id在第六个字段,每个字段之间按照\t键进行分割。
所以需要拿到用户id,拿到了之后,后面就跟wordcount案例一样了,首先每个用户赋值为1,然后根据用户id分组求总次数,就是根据相同的key进行相加,然后反转,降序,最后再反转,取top5输出。
代码实现:
package com.ruozedata.spark.com.ruozedata.spark.core
import org.apache.spark.{SparkConf, SparkContext}
object PageViewsApp {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf()
val sc = new SparkContext(sparkConf)
val pageViews = sc.textFile(args(0))
//获取用户id
//按照tab键分割,分割之后拿到第六个字段(从0开始),
//然后每个元素赋值1,形成tuple元组
val userids = pageViews.map(x => (x.split("\t")(5),1))
//和wordcount一样
val result = userids.reduceByKey(_+_).map(x => (x._2,x._1)).sortByKey(false).map(x => (x._2,x._1)).take(5).foreach(println)
sc.stop()
}
}
然后打包上传,运行代码:
spark-submit \
--class com.ruozedata.spark.com.ruozedata.spark.core.PageViewsApp \
--master local[2] \
/home/hadoop/lib/spark-train-1.0.jar \
/home/hadoop/data/page_views.dat
运行结果,和上面hive运行的结果一样:

就像上面一样,工作中很多场景都可以看到wordcount的影子。
求平均年龄的Spark Core实现
数据格式为:ID + " " + 年龄,如下:
[hadoop@hadoop001 data]$ cat agedata.txt
1 12
2 34
3 54
4 3
5 33
6 23
7 12
8 54
9 45
10 28
分析步骤:
①取出年龄
②求出人数
③年龄相加/人数
开发代码:
package com.ruozedata.spark.com.ruozedata.spark.core
import org.apache.spark.{SparkConf, SparkContext}
object AvgAgeCalculatorApp {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf()
val sc = new SparkContext(sparkConf)
val dataFile = sc.textFile(args(0))
val ageData = dataFile.map(x => x.split(" ")(1))
val totalAge = ageData.map(x => x.toInt).reduce(_+_)
val count = ageData.count()
val avgAge = totalAge/count
println(avgAge)
sc.stop()
}
}
打包上传,执行命令:
spark-submit \
--class com.ruozedata.spark.com.ruozedata.spark.core.AvgAgeCalculatorApp \
--master local[2] \
/home/hadoop/lib/spark-train-1.0.jar \
/home/hadoop/data/agedata.txt
即可得到结果。
求男女人数以及最高和最低身高
需求:
1)统计男女人数
2)男性中最高身高和最低身高
3)女性中最高身高和最低身高
数据格式为:ID + " " + 性别 + " " + 身高
如下:
[hadoop@hadoop001 data]$ cat people_info.txt
1 M 178
2 M 156
3 F 165
4 M 178
5 F 154
6 M 167
7 M 189
8 F 210
9 F 209
10 F 190
11 M 176
12 M 165
13 F 159
14 M 155
15 M 164
代码如下:
package com.ruozedata.spark.com.ruozedata.spark.core
import org.apache.spark.{SparkConf, SparkContext}
object peopleApp {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf()
val sc = new SparkContext(sparkConf)
val peopleData = sc.textFile(args(0))
//第一步分别取出 男性+身高 以及 女性+身高
val mRdd = peopleData.map(x =>x.split(" ")).map(line => (line(1),line(2))).filter(_._1 == "M")
val fRdd = peopleData.map(x =>x.split(" ")).map(line => (line(1),line(2))).filter(_._1 == "F")
//求男女人数
val mCount = mRdd.count()
val fCount = fRdd.count()
//求男性中最高身高和最低身高
val mMaxHeight =mRdd.map(x => (x._2).toInt)max()
//也可以这样求:peopleData.map(line =>line.split(" ")).filter(line => line(1)=="M").sortBy(x => x(2),false).take(1)
//peopleData.map(line =>line.split(" ")).filter(line => line(1)=="M").map(x =>x(2).toInt).max
val mMinHeight = mRdd.map(x => (x._2).toInt).min()
//求女性中最高身高和最低身高
val fMaxHeight = fRdd.map(x => (x._2).toInt).max()
//也可以这样求:peopleData.map(line =>line.split(" ")).filter(line => line(1)=="F").sortBy(x => x(2),false).take(1)
//peopleData.map(line =>line.split(" ")).filter(line => line(1)=="F").map(x =>x(2).toInt).max
val fMinHeight = fRdd.map(x => (x._2).toInt).min()
println("男性人数:" + mCount + "" + "女性人数:" + fCount)
println("男性中最高身高为:" + mMaxHeight + "男性中最低身高为:" + mMinHeight)
println("女性中最高身高为:" + fMaxHeight + "女性中最低身高为:" + fMinHeight)
sc.stop()
}
}
下图只是部分测试结果,可参考:
