组复制安装部署 | 全方位认识 MySQL 8.0 Group Replication
作者 罗小波 · 数据库技术专家
出品 沃趣科技

组复制以插件的形式提供给MySQL Server使用,组中的每个Server都需要配置和安装MGR插件。本节将以三节点的组复制为例,详细介绍组复制的搭建步骤。
PS:部署多个MySQL Server的另一种方法是使用InnoDB Cluster 集群,它基于组复制实现,并将一些搭建步骤封装在程序中,使您能够轻松地使用MySQL Shell 8.0 (MySQL 8.0的一部分)来搭建组复制。此外,InnoDB Cluster 集群与MySQL Router无缝衔接,简化了部署MySQL的高可用集群的步骤。
2.1 部署单主模式的组复制
组复制中的组成员(MySQL Server)可以都部署在同一台主机上(通常用于测试目的),也可以将每个组成员分别部署在单独的主机中(这也是推荐的部署方式)。本节将以在3台不同的主机上分别部署3个节点为例介绍组复制的搭建步骤(有关在同一主机上部署多个组复制节点的步骤,请参阅“本地部署组复制”部分)。
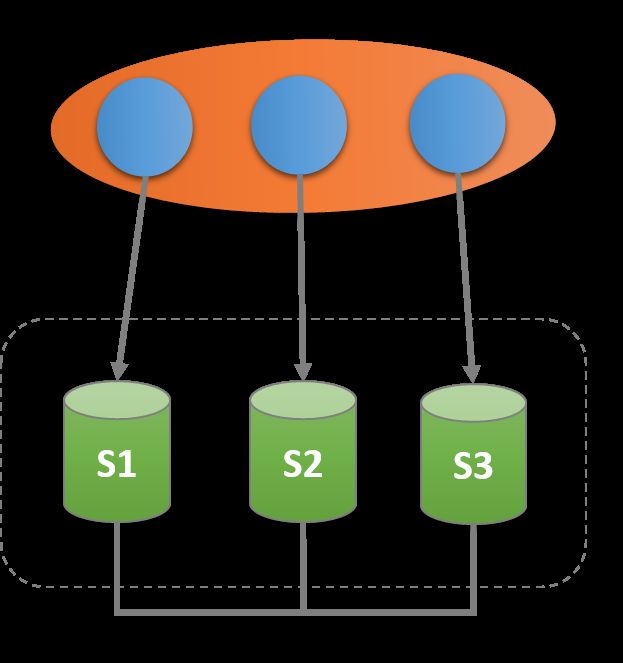
一个三节点的组复制架构图如下,三个节点分别以S1、S2、S3表示,3个客户端分别与三个节点进行通信。
2.1.1. 组复制的实例初始化安装
第一步是部署至少三个MySQL Server(这里与组复制无关,只是先对三个数据库实例进行初始化安装),在3台主机中,分别部署名为为s1、s2、s3的数据库实例(数据库实例的初始化安装步骤省略)。
MGR 是MySQL Server 8.0提供的内置MySQL插件,因此不需要额外安装(注意,虽然不需要额外的安装操作,但是需要额外的加载操作)。
2.1.2. 组复制的实例配置
本节将对配置组复制所要求的系统变量进行介绍,更多有关组复制的要求和限制,详情可参考"9、组复制要求和限制"。
2.1.2.1. 组复制实例配置的基本要求
存储引擎配置
对于组复制,数据必须存储在InnoDB事务引擎中(更多原因,可参考"9.1. 组复制要求")。使用其他存储引擎(例如:临时的MEMORY存储引擎)在组复制中可能会导致出错。因此,我们可以使用disabled_storage_engines系统变量将可能导致组复制出错的一些存储引擎在实例级别关闭掉,如下:
# 注意:在禁用MyISAM存储引擎之后,如果你使用的是MySQL 8.0.16之前的版本,那么,在使用mysql_upgrade命令进行版本升级时,可能会出现错误。要处理这个问题,可以在运行mysql_upgrade命令之前启用MyISAM引擎,在版本升级完成之后再禁用该引擎
disabled_storage_engines="MyISAM,BLACKHOLE,FEDERATED,ARCHIVE,MEMORY"主从复制框架配置
在上文中,我们提到过,组复制是基于主从复制的基础架构实现的,因此,关于启用主从复制的一些基本参数,在组复制中也要求启用,但是,由于组复制本身实现了一些高可用、一致性等特性,所以,在主从复制中,一些关于这些特性的参数就可以适当放宽要求,综合这些因素,在组复制中,有如下一些系统变量配置要求:
# Server 实例级别的唯一标志
server_id=1
# 启用GTID
gtid_mode=ON
# 只允许执行GTID模式下被认为安全的语句
enforce_gtid_consistency=ON
# 禁用二进制日志中的事件数据校验
binlog_checksum=NONE
# 启用二进制日志记录功能
log_bin=binlog
# 启用SQL线程回放之后将二进制写入自身的binlog中,在组复制中,依赖于每个成员持久化的binlog来实现一些数据自动平衡的特性
log_slave_updates=ON
# 启用ROW格式复制,增强数据一致性
binlog_format=ROW
# 启用双TABLE,使用InnoDB引擎表来保存IO和SQL线程的位置信息(复制元数据),以增强复制状态的安全性
master_info_repository=TABLE
relay_log_info_repository=TABLE2.1.2.2. 组复制参数配置
以下仅列出一些组复制最基本的系统变量的配置,需要注意的是,在配置这些系统变量之前,需要确保组中所有的成员数据库实例都已经初始化安装完成,且组复制所要求的主从复制框架的配置已经在my.cnf配置文件中已设置好。
plugin_load_add='group_replication.so'
group_replication_group_name="aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa"
group_replication_start_on_boot=off
group_replication_local_address= "s1:33061"
group_replication_group_seeds= "s1:33061,s2:33061,s3:33061"
group_replication_bootstrap_group=off
组复制参数简介
plugin_load_add='group_replication.so':用于在MySQL Server启动时加载相应的插件(这里使用plugin_load_add插件在启动MySQL Server时,自动加载MGR插件,配合后续的一些组复制系统变量,可以省去繁琐的手工配置组复制的步骤)。
group_replication_group_name="aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa":给定一个组的组名称(必须是有效的UUID格式,因为在组复制中,binlog中记录的GTID是使用这个UUID来进行构造的,如果不知道如何制定,可以使用select uuid();语句来生成)。
group_replication_start_on_boot=off:是否需要随着MySQL Server一并启动MGR插件,在你想手工配置组复制时,就将该系统变量的值设置为off即可。但要注意,一旦将组成功初始化安装完成之后,就需要将该系统变量设置为on(默认为on),以便让MGR插件每次都可以随着MySQL Server自动启动。
group_replication_local_address= "s1:33061":组复制中该成员用于与其他成员之间通讯的地址和端口(s1可以使用IP代替),组会将此地址用于与组内其他成员之间为组通讯引擎(XCom,Paxos变体)建立远程连接,要注意,该系统变量中涉及的端口不能与MySQL Server的运行端口冲突,也不能将此端口它用,它只能用于组成员之间的内部通信。另外,如果不使用IP而是使用的主机名,该主机名需要让组内的所有成员都能够正常解析,以便找到有效的IP地址(可以通过DNS或者所有成员上配置相同的hosts解析记录),从MySQL 8.0.14开始,可以使用IPV6地址,一个组中可以包含使用IPv6和IPv4的成员的组合,更多有关对IPv6网络和混合IPv4和IPv6的信息,请参见"4.5. 配置支持IPv6和混合IPv6与IPv4地址的组"。
group_replication_group_seeds= "s1:33061,s2:33061,s3:33061":
* 指定组复制中有效组成员的地址集合,多个成员地址之间使用逗号分隔。这些成员称为种子成员,其作用只是让joiner节点能够使用这些地址和端口与组建立连接,因此,不需要把所有的成员地址都列出,但要求至少有一个地址有效(可以将组中所有成员的地址和端口都列出,但这不是必须的,如果要列出组中所有成员的地址和端口信息,则建议按照组中成员的启动顺序列出)。一旦joiner节点与组成功建立了连接,则在组内所有成员的performance_schema.replication_group_members表中都会列出组成员的信息。
* 组内第一个启动的成员,需要负责引导组启动,由于是第一个组成员,所以,在引导组启动时会忽略该系统变量的值。引导组的成员中的任何现有数据都将作用于下一个加入组的成员。即,第二个加入组的成员中任何缺失的数据都将以第一个成员作为数据的提供者(donor节点)执行数据复制(因为此时第一个启动的组成员是唯一一个可以提供差异数据的节点)。后续第三个加入组的成员中任何缺失的数据可以选择第一个成员或者第二个成员作为数据的提供者,以此类推,后续joiner节点都可以在之前已经成功加入组内的成员中任意选择一个作为数据的提供者。
* 注:通常,组成员之间内部通讯的端口建议设置为33061,但是,如果所有的组成员都部署在同一台主机中,则为了避免端口冲突,需要配置为其他端口。
group_replication_bootstrap_group=off:
* 设置是否使用这个Server来引导组,对于该系统变量的设置,建议在所有Server中都设置为off(默认为off),然后,根据需要人工选择一个Server来引导组,以便确保始终只有一个Server来引导组启动。
* 在任何时候,该系统变量都只能在一个Server上启用,通常是在第一个启动的Server上启用,且是在第一次引导组时启用(或者在整个组被关闭,然后需要重新引导组时启用,就算是第一个启动的Server,在第一次引导组完成之后,也需要及时关闭该参数),如果多个Server同时启用了这个系统变量,将会造成人为的脑裂场景。
在本示例中对于主机名的解析,我们使用本地hosts文件做解析。
# 需要在即将配置组复制的三台主机中都进行配置
[root@node3 ~]# cat /etc/hosts
......
10.10.30.162 s1 mysql1
10.10.30.163 s2 mysql2
10.10.30.164 s3 mysql3PS:
尽管组复制的组成员之间相互通信使用的本地地址和端口与MySQL Server用于SQL访问的地址和端口不同,但是如果MySQL Server不能够正确识别其他组成员的SQL访问地址和端口,则组复制中有Server加入组时的分布式恢复过程可能会失败。因此,建议运行MySQL的主机操作系统配置正确的且唯一的主机名(可以为组复制的所有成员统一配置DNS或统一配置本地hosts解析记录)。主机名信息可以通过performance_schema.replication_group_members表的Member_host列查看。如果组中存在多个成员的操作系统都使用了默认的主机名,则成员有可能因为无法解析到正确的成员地址而无法成功加入组。在这种情况下,建议在每个成员的数据库my.cnf配置文件中使用report_host系统变量各自配置一个惟一的主机名。
group_replication_group_seeds系统变量中列出的是组内种子成员的内部网络通讯地址和端口,该地址和端口由每个组成员的系统变量group_replication_local_address指定,而不是客户端用于MySQL Server的SQL访问的地址和端口,另外,要注意,在performance_schema.replication_group_members表中MEMBER_PORT列的值,是SQL访问的端口(而不是组成员之间内部通讯的端口),它来自于组成员的port系统变量。
启动组复制,需要先使用一个Server引导组启动完成,然后将第一个组成员作为种子成员,其余Server依次串行申请加入组(一个组复制集群中,不支持在没有任何活跃节点的情况下,将第一个引导组启动的Server和其他申请加入组的Server同时启动,这可能导致所有申请加入组的Server都失败),如果有特殊需求需要在同一时刻申请加入组,则group_replication_group_seeds系统变量中不要列出还未成功加入组的Server作为种子成员,否则可能导致某些Server申请加入组失败。
joiner节点在其group_replication_group_seeds系统变量中指定的种子成员的地址(IPV6或IPV4),必须与该变量所指向的种子成员中的group_replication_local_address系统变量指定的地址相匹配(IPV6或IPV4),即种子成员中group_replication_local_address指定的是IPV4地址,那么,在joiner节点中的group_replication_group_seeds系统变量中也要指定IPV4地址,不能使用IPV6地址,否则地址协议不匹配会导致joiner节点申请加入组失败。另外,所有成员(包括已加入组的成员和待加入组的成员)中的白名单必须允许相互之间的访问,否则将会拒绝白名单之外的网络地址的连接尝试。有关更多白名单的信息,请参见"5.1. 组复制的IP地址白名单"。
如果使用的数据库版本低于MySQL 8.0.2,则还需要将transaction_write_set_extraction变量配置为XXHASH64。该系统变量指示MySQL Server对每个事务,在收集写集数据(WRITESET)时使用XXHASH64散列算法进行计算。从MySQL 8.0.2开始,该系统变量默认值被设置为了XXHASH64,如果低于该版本,那么,在配置组复制时需要将该系统变量添加到my.cnf配置文件中,如下:
transaction_write_set_extraction = XXHASH64组中所有成员的配置非常相似。因此,在配置其他成员时只需要对少量的系统变量稍作修改即可(例如:server_id、datadir、group_replication_local_address)。在下文中将对这些每个成员必须修改的系统变量进行说明。
2.1.3. 用户凭证
组复制在将组成员加入组时,使用分布式恢复过程来同步joiner节点的数据。分布式恢复会涉及到使用名为group_replication_recovery的组复制通道将事务从donor节点(捐赠者)的二进制日志传输到joiner节点中。因此,必须设置具有正确权限的复制用户,以便组复制可以在成员与成员之间建立复制通道。如果组成员已设置了使用远程克隆的操作进行分布式恢复(从MySQL 8.0.17版本开始支持),则此复制用户还将在donor节点上当做克隆用户角色使用,因此也需要克隆用户角色的正确权限。有关分布式恢复的完整描述,请参见"4.3. 分布式恢复"。
在组复制中,用于分布式恢复的复制用户可以通过二进制日志在成员之间相互同步,即,可以只在第一个组成员上创建复制用户,然后,后续joiner节点依靠分布式恢复机制通过二进制日志中的创建用户语句将该用户进行同步。也可以在组复制的每个成员中分别创建复制用户(但是,为了避免组复制中的Server各自创建用户的二进制日志在后续相互同步数据时发生冲突,每个Server在创建用户之前需要在会话级别临时关闭二进制日志,创建用户完成之后再重新启用二进制日志)。
如果设置了克隆功能,则被克隆的joiner节点在克隆操作完成之后,在创建组复制通道group_replication_recovery时使用的复制用户和密码是来自于donor节点的。即,整个组复制中所有的成员都会使用相同的复制用户,需要确保复制用户在任意组成员都可以正常与组中其他成员进行分布式恢复与数据同步,因此,除非特殊原因,否则建议在整个组复制拓扑中,使用相同的复制用户和密码以及授权。
注意:如果在组复制中为分布式恢复配置且启用了SSL,则,必须在joiner节点连接到donor节点之前为每个成员创建好启用SSL的复制用户(即,需要在每个组成员上单独创建启用SSL的复制用户),以便joiner节点能够成功连接到donor节点。有关为分布式恢复连接设置SSL的说明,请参见"5.2. 组复制安全套接字层(SSL)支持"。
如果要为组复制创建用于分布式恢复的复制用户,则请按照如下步骤进行操作。
1)启动MySQL Server,然后使用客户端连接到该实例。
2)如果要为组复制中的每个成员分别创建复制用户,则需要先在客户端会话级别关闭二进制日志记录,如下:
mysql> SET SQL_LOG_BIN=1;
3)创建一个MySQL用户,并为该用户授予REPLICATION SLAVE权限,如果Server设置为支持克隆,则还需要为该用户授予BACKUP_ADMIN权限。这里以创建名为rpl_user、密码为password的用户为例,列出创建复制用户的语句,如下:
mysql> CREATE USER rpl_user@'%' IDENTIFIED BY 'password';
mysql> GRANT REPLICATION SLAVE ON *.* TO rpl_user@'%';
mysql> GRANT BACKUP_ADMIN ON *.* TO rpl_user@'%';
mysql> FLUSH PRIVILEGES;
# 注意,如果想要使用mysql_native_password密码认证插件,则在创建用户时,改用如下语句
mysql> CREATE USER rpl_user@'%' IDENTIFIED WITH mysql_native_password BY 'password';
4)如果执行了第2步骤禁用了二进制日志记录,则在创建完成复制用户之后需要立即启用它,语句如下:
mysql> SET SQL_LOG_BIN=1;
5)配置好用户后,使用CHANGE MASTER TO语句进行配置复制,使用上述步骤中创建的复制用户作为用户凭证,复制通道指定为group_replication_recovery,这样,就可以通过分布式恢复或远程克隆操作进行状态传输。语句如下(注意,根据你创建的实际用户名和密码替换rpl_user和password字符串):
# 需要正确配置复制用户的用户名和密码,否则,会因为用户凭证不正确而无法连接到donor节点来执行状态传输,因为会造成该节点无法加入组
mysql> CHANGE MASTER TO MASTER_USER='rpl_user', MASTER_PASSWORD='password' FOR CHANNEL 'group_replication_recovery';
在组复制中使用SHA-2用户凭证插件。
默认情况下,MySQL 8.0中创建的用户都启用了SHA-2用户凭证插件(在MySQL 8.0中,创建用户时默认使用了caching_sha2_password插件,如果需要临时使用mysql_native_password身份认证插件,则可以使用创建用户语句中的auth_option部分指定,例如:IDENTIFIED WITH mysql_native_password BY 'password',如果需要修改全局的身份认证插件,可以设置系统变量default_authentication_plugin=mysql_native_password),如果用于分布式恢复使用的rpl_user用户使用了SHA-2身份验证插件,且也没有为组复制通道group_replication_recovery启用SSL支持(需要使用group_replication_ssl_mode系统变量以及ssl_*开头的一些系统变量进行配置),则,RSA 密钥对将取代密码作为用户凭证。你可以手工将密钥对中的公钥拷贝到joiner节点中提供给rpl_user用户使用,也可以在donor节点中配置为joiner节点请求加入组时为其提供公钥。如果RSA秘钥对也未进行配置,则将会导致成员加入组失败,报错"[ERROR] [MY-010584] [Repl] Slave I/O for channel 'group_replication_recovery': error connecting to master 'rpl_user@node1:3306' - retry-time: 60 retries: 1 message: Authentication plugin 'caching_sha2_password' reported error: Authentication requires secure connection. Error_code: MY-002061"。
更安全的方法是将rpl_user用户所需的公钥文件复制到joiner节点的Server所在主机中。然后,在joiner节点的Server中配置group_replication_recovery_public_key_path系统变量,指定rpl_user用户所需的公钥文件路径。
另一种不太安全的方法是,在donor节点中,将group_replication_recovery_get_public_key系统变量设置为ON,以便在joiner节点请求加入组时,由其向joiner节点提供rpl_user用户所需的公钥文件。由于这种方法没有办法使用秘钥对来验证Server本身的身份,因此,只有当您能够确定不存在Server本身的身份风险时,才能使用这种方法。
PS:为组复制通道group_replication_recovery启用SSL支持的配置示例如下:
# 在所有joiner节点和活跃组成员的my.cnf中设置如下参数
[mysqld]
ssl_ca = "cacert.pem"
ssl_capath = "/.../ca_directory"
ssl_cert = "server-cert.pem"
ssl_cipher = "DHE-RSA-AEs256-SHA"
ssl_crl = "crl-server-revoked.crl"
ssl_crlpath = "/.../crl_directory"
ssl_key = "server-key.pem"
# 在donor节点中创建复制用户
donor> SET SQL_LOG_BIN=0;
donor> CREATE USER 'rec_ssl_user'@'%' REQUIRE SSL;
donor> GRANT replication slave ON *.* TO 'rec_ssl_user'@'%';
donor> GRANT BACKUP_ADMIN ON *.* TO 'rec_ssl_user'@'%';
donor> SET SQL_LOG_BIN=1;
# 在joiner节点中,执行如下CHANGE MASTER语句
new_member> CHANGE MASTER TO MASTER_USER="rec_ssl_user" FOR CHANNEL "group_replication_recovery";
# 在joiner节点中,可以动态配置如下系统变量(动态配置完成之后需要将其持久化到my.cnf中)
new_member> SET GLOBAL group_replication_recovery_use_ssl=1;
new_member> SET GLOBAL group_replication_recovery_ssl_ca= '.../cacert.pem';
new_member> SET GLOBAL group_replication_recovery_ssl_cert= '.../client-cert.pem';
new_member> SET GLOBAL group_replication_recovery_ssl_key= '.../client-key.pem';
关于加密连接配置的参考链接:
https://dev.mysql.com/doc/refman/8.0/en/caching-sha2-pluggable-authentication.html
https://dev.mysql.com/doc/refman/8.0/en/group-replication-secure-socket-layer-support-ssl.html
https://dev.mysql.com/doc/refman/8.0/en/creating-ssl-rsa-files.html
2.1.4. 启动组复制
配置并启动名为s1的MySQL Server之后(注:这里指的是启动数据库实例),如果启动MySQL Server之前在my.cnf配置文件中配置系统变量plugin_load_add='group_replication.so',则MySQL Server启动时会自动加载MGR插件,如果未在配置文件中指定过加载插件,则,此时你需要手工执行插件加载,语句如下:
INSTALL PLUGIN group_replication SONAME 'group_replication.so';
注意:mysql.session用户是用于加载MGR插件使用的,在加载MGR插件之前,该用户必须存在,所以,如果你使用的版本是比较老旧的版本,则可能不存在这个用户,此时,你需要先使用mysql_upgrade命令升级到新版本,然后再操作加载MGR插件,否则,在加载MGR插件时会报错:"There was an error when trying to access the server with user: mysql.session@localhost. Make sure the user is present in the server and that mysql_upgrade was ran after a server update.."。另外,有数据库安全加固需求的场景,在做加固时需要注意,不要将该用户误删除了。
当MGR插件加载成功之后,可以通过如下语句进行简单查看。
mysql> SHOW PLUGINS;
+----------------------------+----------+--------------------+----------------------+-------------+
| Name | Status | Type | Library | License |
+----------------------------+----------+--------------------+----------------------+-------------+
......
| group_replication | ACTIVE | GROUP REPLICATION | group_replication.so | GPL |
+------------------------------------------+----------+--------------------+-----------------------+---------+
47 rows in set (0.01 sec)
2.1.5. 引导组
第一次启动组的过程称为引导。使用group_replication_bootstrap_group系统变量来引导一个组。引导程序只能由单个MySQL Server(这里指的是引导组的MySQL Server)执行一次。这就是为什么group_replication_bootstrap_group系统变量不在my.cnf配置文件中持久化的原因。如果将其保存在配置文件中(group_replication_bootstrap_group=ON),则在重新启动组成员时,组中的所有成员都将会尝试引导组,而这些组的名称都是相同的,这将导致组产生脑裂。因此,为了安全地引导组,需要在第一个MySQL Server启动完成之后,登录到数据库中,手工执行如下语句完成组的引导(该参数也可用于重新引导组,先设置为OFF,再设置为ON)。
# 设置由该MySQL Server来引导组
mysql> SET GLOBAL group_replication_bootstrap_group=ON;
# 启动组复制
mysql> START GROUP_REPLICATION;
# 在该MySQL Server中,组复制启动完成之后,引导组的工作也一起完成了,为避免后续一系列意外原因可能发生脑裂,需要将引导组的开关参数及时关闭
mysql> SET GLOBAL group_replication_bootstrap_group=OFF;
一旦START GROUP_REPLICATION语句执行完成,代表着组就已经启动完成了。可以通过performance_schema.replication_group_members表中记录的组成员信息来查看组成员的状态:
# 从下面的内容中,我们可以看到,当前只有1个成员s1(每个成员有一行单独的记录),处于ONLINE状态,成员唯一标识符为ce9be252-2b71-11e6-b8f4-00212844f856(成员的server_uuid系统变量中获取的值),正在端口3306上监听客户端连接(注意这里是SQL访问端口,不是组成员之间的通讯端口)
mysql> SELECT * FROM performance_schema.replication_group_members;
+---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+
| CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE | MEMBER_ROLE | MEMBER_VERSION |
+---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+
| group_replication_applier | 395409e1-6dfa-11e6-970b-00212844f856 | s1 | 3306 | ONLINE | PRIMARY | 8.0.17 |
+---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+
1 row in set (0.01 sec)
为了演示MySQL Server确实处在一个组中,并且能够处理负载(指业务访问流量),下面制造一些测试数据,语句如下:
# 登录数据库中,执行建库,建表,并插入测试数据
mysql> CREATE DATABASE test;
mysql> USE test;
mysql> CREATE TABLE t1 (c1 INT PRIMARY KEY, c2 TEXT NOT NULL);
mysql> INSERT INTO t1 VALUES (1, 'Luis');
# 检查表t1中的数据
mysql> SELECT * FROM t1;
+----+------+
| c1 | c2 |
+----+------+
| 1 | Luis |
+----+------+
# 检查二进制日志的内容(注:使用SHOW BINLOG EVENTS语句只能看到statement格式的语句文本和event结构信息,无法看到row格式的BINLOG编码文本)
mysql> SHOW BINLOG EVENTS;
+---------------+-----+----------------+-----------+-------------+--------------------------------------------------------------------+
| Log_name | Pos | Event_type | Server_id | End_log_pos | Info |
+---------------+-----+----------------+-----------+-------------+--------------------------------------------------------------------+
| binlog.000001 | 4 | Format_desc | 1 | 123 | Server ver: 8.0.19-log, Binlog ver: 4 |
| binlog.000001 | 123 | Previous_gtids | 1 | 150 | |
| binlog.000001 | 150 | Gtid | 1 | 211 | SET @@SESSION.GTID_NEXT= 'aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa:1' |
| binlog.000001 | 211 | Query | 1 | 270 | BEGIN |
| binlog.000001 | 270 | View_change | 1 | 369 | view_id=14724817264259180:1 |
| binlog.000001 | 369 | Query | 1 | 434 | COMMIT |
| binlog.000001 | 434 | Gtid | 1 | 495 | SET @@SESSION.GTID_NEXT= 'aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa:2' |
| binlog.000001 | 495 | Query | 1 | 585 | CREATE DATABASE test |
| binlog.000001 | 585 | Gtid | 1 | 646 | SET @@SESSION.GTID_NEXT= 'aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa:3' |
| binlog.000001 | 646 | Query | 1 | 770 | use `test`; CREATE TABLE t1 (c1 INT PRIMARY KEY, c2 TEXT NOT NULL) |
| binlog.000001 | 770 | Gtid | 1 | 831 | SET @@SESSION.GTID_NEXT= 'aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa:4' |
| binlog.000001 | 831 | Query | 1 | 899 | BEGIN |
| binlog.000001 | 899 | Table_map | 1 | 942 | table_id: 108 (test.t1) |
| binlog.000001 | 942 | Write_rows | 1 | 984 | table_id: 108 flags: STMT_END_F |
| binlog.000001 | 984 | Xid | 1 | 1011 | COMMIT /* xid=38 */ |
+---------------+-----+----------------+-----------+-------------+--------------------------------------------------------------------+
如上所述,我们创建了测试库、表、数据,这些数据变更被写入了二进制日志中,这样,其他joiner节点将写入数据的组成员选做donor节点时,就可以通过这些二进制日志记录来做分布式恢复,从而实现数据同步。
2.1.6. 向组中添加实例
此时,组中已有一个成员s1,且其中包含一些数据。现在,假设我们需要扩展s2和s3两个MySQL Server到组中。
2.1.6.1. 添加第二个实例
首先,为名为s2的MySQL Server创建配置文件。与配置名为s1的MySQL Server的系统变量相比,除了server_id和group_replication_local_address之外,其余配置与s1中使用的配置类似。如下:
[mysqld]
#
# Disable other storage engines
#
disabled_storage_engines="MyISAM,BLACKHOLE,FEDERATED,ARCHIVE,MEMORY"
#
# Replication configuration parameters
#
server_id=2
gtid_mode=ON
enforce_gtid_consistency=ON
binlog_checksum=NONE
#
# Group Replication configuration
#
transaction_write_set_extraction=XXHASH64
group_replication_group_name="aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa"
group_replication_start_on_boot=off
group_replication_local_address= "s2:33061"
group_replication_group_seeds= "s1:33061,s2:33061,s3:33061"
group_replication_bootstrap_group= off
与s1的配置过程类似,在s2的进程启动完成之后,按照以下方式配置分布式恢复所需的用户凭证,建议使用与s1 配置过程中完全一致的语句进行操作。
SET SQL_LOG_BIN=0;
CREATE USER rpl_user@'%' IDENTIFIED BY 'password';
GRANT REPLICATION SLAVE ON *.* TO rpl_user@'%';
GRANT BACKUP_ADMIN ON *.* TO rpl_user@'%';
SET SQL_LOG_BIN=1;
CHANGE MASTER TO MASTER_USER='rpl_user', MASTER_PASSWORD='password' FOR CHANNEL 'group_replication_recovery';
如果用户使用了SHA-2身份验证插件(MySQL 8中的默认插件),则启用加密连接相关的步骤参考"2.1.3. 用户凭证"。
如果需要动态加载MGR插件,可参考"2.1.4. 启动组复制"。
登录s2数据库中,使用如下语句启动组复制,此时,s2开始执行加入组的过程。
# 对于启动组复制的操作步骤,与s1相比,少了使用系统变量group_replication_bootstrap_group来引导组的步骤,因为s1启动时,已经引导过组了,即,组已存在,后续加入组的其他Server不需要也不允许做引导组的操作,否则会导致脑裂。s2要做的只是启动复制组,加入组即可
mysql> START GROUP_REPLICATION;
注意:当s2的组复制成功启动并成功加入组时,它将检查s2的系统变量super_read_only的值。并动态将s2的系统变量super_read_only设置为ON,同时同步到配置文件中进行持久化,以确保任何情况下只读节点都不能够接受写事务。但是,如果Server应该以读写模式加入组,例如:作为单主模式中的主要节点,或者作为多主模式中的组成员(多主模式下,所有组成员都是主要节点),就算系统变量super_read_only被设置为ON,在该Server加入组成功时,会自动将其设置为OFF,以便允许写事务访问。
查看performance_schema.replication_group_members表中的数据,可以发现组中已经存在2个处于ONLINE状态的成员了。
mysql> SELECT * FROM performance_schema.replication_group_members;
+---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+
| CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE | MEMBER_ROLE | MEMBER_VERSION |
+---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+
| group_replication_applier | 395409e1-6dfa-11e6-970b-00212844f856 | s1 | 3306 | ONLINE | PRIMARY | 8.0.17 |
| group_replication_applier | ac39f1e6-6dfa-11e6-a69d-00212844f856 | s2 | 3306 | ONLINE | SECONDARY | 8.0.17 |
+---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+
2 rows in set (0.00 sec)
当s2尝试加入组时,“分布式恢复”的机制能够确保s2能够利用s1中的binlog来进行数据同步。一旦分布式恢复过程执行完成,s2就可以在该组中转变为活跃成员,此时它会被标记为ONLINE状态。换句话说,在s2被标记为ONLINE状态之后,要求它必须已经完全同步了s1中的数据,因为,该状态下,它会基于s1中的数据开始处理新的事务。下面,我们验证一下s2是否已经完全同步了s1中的数据,如下:
# 查看测试数据是否存在
mysql> SHOW DATABASES LIKE 'test';
+-----------------+
| Database (test) |
+-----------------+
| test |
+-----------------+
# 查看测试表中的数据是否存在
mysql> SELECT * FROM test.t1;
+----+------+
| c1 | c2 |
+----+------+
| 1 | Luis |
+----+------+
# 查看s2中的binlog记录情况(组复制拓扑中所有的成员都要求记录远端事务的binlog,以便能够在任意组成员发生意外时,任意组成员都可以提供一致的数据访问以及将其他成员的数据同步到一致状态的能力)
mysql> SHOW BINLOG EVENTS;
+---------------+------+----------------+-----------+-------------+--------------------------------------------------------------------+
| Log_name | Pos | Event_type | Server_id | End_log_pos | Info |
+---------------+------+----------------+-----------+-------------+--------------------------------------------------------------------+
| binlog.000001 | 4 | Format_desc | 2 | 123 | Server ver: 8.0.19-log, Binlog ver: 4 |
| binlog.000001 | 123 | Previous_gtids | 2 | 150 | |
| binlog.000001 | 150 | Gtid | 1 | 211 | SET @@SESSION.GTID_NEXT= 'aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa:1' |
| binlog.000001 | 211 | Query | 1 | 270 | BEGIN |
| binlog.000001 | 270 | View_change | 1 | 369 | view_id=14724832985483517:1 |
| binlog.000001 | 369 | Query | 1 | 434 | COMMIT |
| binlog.000001 | 434 | Gtid | 1 | 495 | SET @@SESSION.GTID_NEXT= 'aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa:2' |
| binlog.000001 | 495 | Query | 1 | 585 | CREATE DATABASE test |
| binlog.000001 | 585 | Gtid | 1 | 646 | SET @@SESSION.GTID_NEXT= 'aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa:3' |
| binlog.000001 | 646 | Query | 1 | 770 | use `test`; CREATE TABLE t1 (c1 INT PRIMARY KEY, c2 TEXT NOT NULL) |
| binlog.000001 | 770 | Gtid | 1 | 831 | SET @@SESSION.GTID_NEXT= 'aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa:4' |
| binlog.000001 | 831 | Query | 1 | 890 | BEGIN |
| binlog.000001 | 890 | Table_map | 1 | 933 | table_id: 108 (test.t1) |
| binlog.000001 | 933 | Write_rows | 1 | 975 | table_id: 108 flags: STMT_END_F |
| binlog.000001 | 975 | Xid | 1 | 1002 | COMMIT /* xid=30 */ |
| binlog.000001 | 1002 | Gtid | 1 | 1063 | SET @@SESSION.GTID_NEXT= 'aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa:5' |
| binlog.000001 | 1063 | Query | 1 | 1122 | BEGIN |
| binlog.000001 | 1122 | View_change | 1 | 1261 | view_id=14724832985483517:2 |
| binlog.000001 | 1261 | Query | 1 | 1326 | COMMIT |
+---------------+------+----------------+-----------+-------------+--------------------------------------------------------------------+
此时,已确认s2已经成功加入到组中,且可以对外提供只读访问了(为什么s2只能提供只读访问呢?因为我们在配置s1时并没有配置系统变量group_replication_single_primary_mode,而该变量默认值为ON,即,默认为单主模式,单主模式下,只有一个主要节点(只有一个可读写的成员,其他成员都为只读)。
2.1.6.2. 添加更多实例
向组中添加其他Server时,操作步骤与s2基本相同,只需要对一些需要针对不同Server自身修改的系统变量做调整即可,这里我们就简要列出操作步骤,如下:
1)创建配置文件(修改系统变量server_id和group_replication_local_address为s3对应的值)。
mysqld]
#
# Disable other storage engines
#
disabled_storage_engines="MyISAM,BLACKHOLE,FEDERATED,ARCHIVE,MEMORY"
#
# Replication configuration parameters
#
server_id=3
gtid_mode=ON
enforce_gtid_consistency=ON
binlog_checksum=NONE
#
# Group Replication configuration
#
group_replication_group_name="aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa"
group_replication_start_on_boot=off
group_replication_local_address= "s3:33061"
group_replication_group_seeds= "s1:33061,s2:33061,s3:33061"
group_replication_bootstrap_group= off
2)启动s3数据库进程,并使用客户端登录到数据库中,为组复制通道group_replication_recovery配置以及分布式恢复的用户凭证。
SET SQL_LOG_BIN=0;
CREATE USER rpl_user@'%' IDENTIFIED BY 'password';
GRANT REPLICATION SLAVE ON *.* TO rpl_user@'%';
GRANT BACKUP_ADMIN ON *.* TO rpl_user@'%';
FLUSH PRIVILEGES;
SET SQL_LOG_BIN=1;
CHANGE MASTER TO MASTER_USER='rpl_user', MASTER_PASSWORD='password' FOR CHANNEL 'group_replication_recovery';
3)加载MGR插件并启动组复制
INSTALL PLUGIN group_replication SONAME 'group_replication.so';
START GROUP_REPLICATION;
此时,名为s3的MySQL Server已经启动并运行,且已经加入了组,并赶上了组中的其他成员中的数据。通过查询performance_schema.replication_group_members表我们可以看到s3已经成功加入组且为ONLINE状态,如下:
mysql> SELECT * FROM performance_schema.replication_group_members;
+---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+
| CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE | MEMBER_ROLE | MEMBER_VERSION |
+---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+
| group_replication_applier | ac39f1e6-6dfa-11e6-a69d-00212844f856 | s2 | 3306 | ONLINE | SECONDARY | 8.0.17 |
| group_replication_applier | 7eb217ff-6df3-11e6-966c-00212844f856 | s3 | 3306 | ONLINE | SECONDARY | 8.0.17 |
| group_replication_applier | 95409e1-6dfa-11e6-970b-00212844f856 | s1 | 3306 | ONLINE | PRIMARY | 8.0.17 |
+---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+
3 rows in set (0.00 sec)
接下来,在s3中简单验证下数据是否同步完成,我们可以看到,在s3上的数据与在s1和s2中查询到的数据结果集相同。
mysql> SHOW DATABASES LIKE 'test';
+-----------------+
| Database (test) |
+-----------------+
| test |
+-----------------+
mysql> SELECT * FROM test.t1;
+----+------+
| c1 | c2 |
+----+------+
| 1 | Luis |
+----+------+
mysql> SHOW BINLOG EVENTS;
+---------------+------+----------------+-----------+-------------+--------------------------------------------------------------------+
| Log_name | Pos | Event_type | Server_id | End_log_pos | Info |
+---------------+------+----------------+-----------+-------------+--------------------------------------------------------------------+
| binlog.000001 | 4 | Format_desc | 3 | 123 | Server ver: 8.0.19-log, Binlog ver: 4 |
| binlog.000001 | 123 | Previous_gtids | 3 | 150 | |
| binlog.000001 | 150 | Gtid | 1 | 211 | SET @@SESSION.GTID_NEXT= 'aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa:1' |
| binlog.000001 | 211 | Query | 1 | 270 | BEGIN |
| binlog.000001 | 270 | View_change | 1 | 369 | view_id=14724832985483517:1 |
| binlog.000001 | 369 | Query | 1 | 434 | COMMIT |
| binlog.000001 | 434 | Gtid | 1 | 495 | SET @@SESSION.GTID_NEXT= 'aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa:2' |
| binlog.000001 | 495 | Query | 1 | 585 | CREATE DATABASE test |
| binlog.000001 | 585 | Gtid | 1 | 646 | SET @@SESSION.GTID_NEXT= 'aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa:3' |
| binlog.000001 | 646 | Query | 1 | 770 | use `test`; CREATE TABLE t1 (c1 INT PRIMARY KEY, c2 TEXT NOT NULL) |
| binlog.000001 | 770 | Gtid | 1 | 831 | SET @@SESSION.GTID_NEXT= 'aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa:4' |
| binlog.000001 | 831 | Query | 1 | 890 | BEGIN |
| binlog.000001 | 890 | Table_map | 1 | 933 | table_id: 108 (test.t1) |
| binlog.000001 | 933 | Write_rows | 1 | 975 | table_id: 108 flags: STMT_END_F |
| binlog.000001 | 975 | Xid | 1 | 1002 | COMMIT /* xid=29 */ |
| binlog.000001 | 1002 | Gtid | 1 | 1063 | SET @@SESSION.GTID_NEXT= 'aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa:5' |
| binlog.000001 | 1063 | Query | 1 | 1122 | BEGIN |
| binlog.000001 | 1122 | View_change | 1 | 1261 | view_id=14724832985483517:2 |
| binlog.000001 | 1261 | Query | 1 | 1326 | COMMIT |
| binlog.000001 | 1326 | Gtid | 1 | 1387 | SET @@SESSION.GTID_NEXT= 'aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa:6' |
| binlog.000001 | 1387 | Query | 1 | 1446 | BEGIN |
| binlog.000001 | 1446 | View_change | 1 | 1585 | view_id=14724832985483517:3 |
| binlog.000001 | 1585 | Query | 1 | 1650 | COMMIT |
+---------------+------+----------------+-----------+-------------+--------------------------------------------------------------------+
2.2 本地部署组复制
部署组复制常见的方法是使用多个MySQL Server且每个Server单独占用一台主机,以提供更好的高可用性。但,组复制也支持在本地部署(所有Server部署在同一台主机中),这样,可以大大节省用于测试目的的成本。
注意:本地部署不适用于生产环境,因为所有MySQL Server都运行在同一台主机上。如果此主机发生任何故障,将可能导致整个组不可用、甚至发生数据丢失。因此,本地部署仅限于测试目的,而不应该为了节省成本而在生产环境中使用。
下面以3个MySQL Server的组复制为例,简要介绍本地部署的操作步骤。要在一台主机上创建一个包含三个MySQL Server的组复制。这意味着需要三个不同的目录来分别存放3个MySQL Server的数据和配置文件。
1)初始化安装MySQL Server
# 这里,我们仍然沿用上文中的Server名称s1、s2、s3,分别代表组复制中的第一个Server、第二个Server、第三个Server,各自创建好对应的数据和配置文件存放目录,然后,使用如下命令对3个MySQL Server进行初始化安装
## 初始化安装第一个Server(s1)
mysql-8.0/bin/mysqld --initialize-insecure --basedir=$PWD/mysql-8.0 --datadir=$PWD/data/s1
## 初始化安装第二个Server(s2)
mysql-8.0/bin/mysqld --initialize-insecure --basedir=$PWD/mysql-8.0 --datadir=$PWD/data/s2
## 初始化安装第三个Server(s3)
mysql-8.0/bin/mysqld --initialize-insecure --basedir=$PWD/mysql-8.0 --datadir=$PWD/data/s3
上述步骤中的data/s1、data/s2、data/s3目录中,是每个MySQL Server的初始化数据目录,其中包含着各自的mysql系统数据库和相关表等。
注意:不要在生产环境中使用--initialize-insecure选项对数据库进行初始化安装,因为使用该选项对数据库初始化安装之后,数据库的超级管理员root账号为一个空密码账号,任何人都可以使用该账号登录数据库,存在一定的安全风险。有关安全设置的更多信息,请参见“5、组复制安全性"。
2)本地组复制成员的配置。基于"2.1.2. 组复制的实例配置"中的my.cnf配置参数模板,修改对应每个MySQL Server的路径和端口相关的系统变量,如下:
[mysqld]
# server configuration
datadir=/data/s1
basedir=/mysql-8.0/
port=24801
socket=/s1.sock
组复制需要成员之间的网络连接互通,这意味着每个成员必须能够解析所有其他成员的网络地址。由于这里我们是采用本地部署,所有的MySQL Server都安装在了同一台主机中,因此,可以在my.cnf配置文件中添加一行配置,例如:report_host=127.0.0.1,这样,所有的组成员都可以通过本地回环地址进行通讯,可以确保每个组成员之间能够互相通讯,然后,在每个成员的my.cnf中,按照如下示例配置组复制相关的系统变量。
# s1的组复制相关的系统变量配置
group_replication_local_address= "127.0.0.1:24901"
group_replication_group_seeds= "127.0.0.1:24901,127.0.0.1:24902,127.0.0.1:24903"
# s2的组复制相关的系统变量配置
group_replication_local_address= "127.0.0.1:24902"
group_replication_group_seeds= "127.0.0.1:24901,127.0.0.1:24902,127.0.0.1:24903"
# s3的组复制相关的系统变量配置
group_replication_local_address= "127.0.0.1:24903"
group_replication_group_seeds= "127.0.0.1:24901,127.0.0.1:24902,127.0.0.1:24903"
本地部署方式,由于所有MySQL Server都部署在同一台主机中,所以,你可以在系统变量group_replication_local_address上为3个组成员指定相同的地址,但是,端口一定要确保唯一(如果组成员处在不同的主机中,则需要指定不同的地址,但端口不需要保证唯一,总之,该系统变量值中,"地址+端口"需要保证唯一),这样组成员之间才能正确地相互找到彼此。另外,对于系统变量group_replication_group_seeds,为了配置简便,你可能希望将所有的组成员地址与端口信息都一并指定,这样所有成员都可以充当种子成员,但是要注意,整个地址串中需要保证有活跃成员能够为joiner节点提供分布式恢复相关的服务。
| 作者简介
罗小波·数据库技术专家
《千金良方——MySQL性能优化金字塔法则》作者之一。熟悉MySQL体系结构,擅长数据库的整体调优,喜好专研开源技术,并热衷于开源技术的推广,在线上线下做过多次公开的数据库专题分享,发表过近100篇数据库相关的研究文章。
全文完。
Enjoy MySQL 8.0 :)
叶老师的「MySQL核心优化」大课已升级到MySQL 8.0,扫码开启MySQL 8.0修行之旅吧
