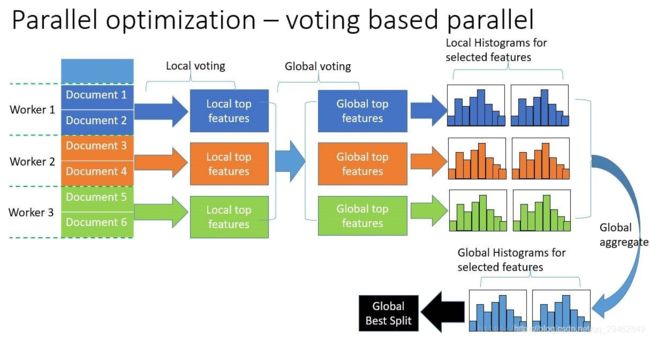
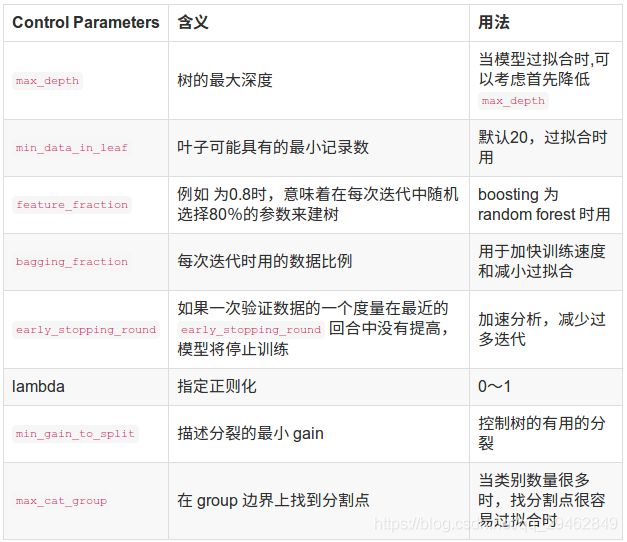
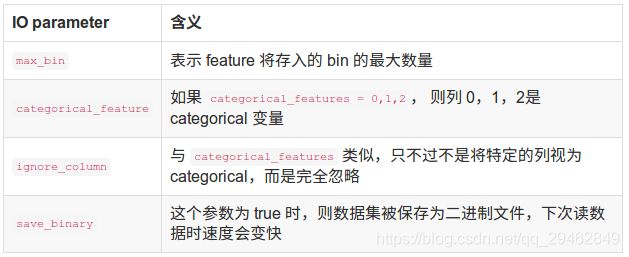
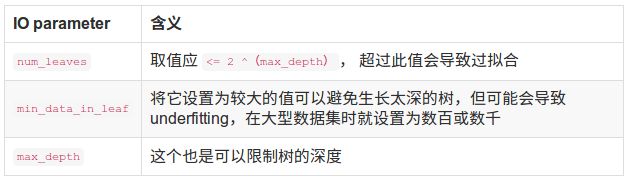
- LangChain中的向量数据库接口-Weaviate
洪城叮当
langchain数据库经验分享笔记交互人工智能知识图谱
文章目录前言一、原型定义二、代码解析1、add_texts方法1.1、应用样例2、from_texts方法2.1、应用样例3、similarity_search方法3.1、应用样例三、项目应用1、安装依赖2、引入依赖3、创建对象4、添加数据5、查询数据总结前言 Weaviate是一个开源的向量数据库,支持存储来自各类机器学习模型的数据对象和向量嵌入,并能无缝扩展至数十亿数据对象。它提供存储文档嵌
- Python的科学计算库NumPy(一)
linlin_1998
pythonnumpy开发语言
NumPy(NumericalPython)是Python中最基础、最重要的科学计算库之一,提供了高性能的多维数组(ndarray)对象和大量数学函数,是许多数据科学、机器学习库(如Pandas、SciPy、TensorFlow等)的基础依赖。1.创建一个numpy里面的一维数组importnumpyasnp###通过array方法创建一个ndarrayarray1=np.array([1,2,3
- 微算法科技的前沿探索:量子机器学习算法在视觉任务中的革新应用
MicroTech2025
量子计算算法
在信息技术飞速发展的今天,计算机视觉作为人工智能领域的重要分支,正逐步渗透到我们生活的方方面面。从自动驾驶到人脸识别,从医疗影像分析到安防监控,计算机视觉技术展现了巨大的应用潜力。然而,随着视觉任务复杂度的不断提升,传统机器学习算法在处理大规模、高维度数据时遇到了计算瓶颈。在此背景下,量子计算作为一种颠覆性的计算模式,以其独特的并行处理能力和指数级增长的计算空间,为解决这一难题提供了新的思路。微算
- 在mac m1基于llama.cpp运行deepseek
lama.cpp是一个高效的机器学习推理库,目标是在各种硬件上实现LLM推断,保持最小设置和最先进性能。llama.cpp支持1.5位、2位、3位、4位、5位、6位和8位整数量化,通过ARMNEON、Accelerate和Metal支持Apple芯片,使得在MACM1处理器上运行Deepseek大模型成为可能。1下载llama.cppgitclonehttps://github.com/ggerg
- 【机器学习笔记Ⅰ】9 特征缩放
巴伦是只猫
机器学习机器学习笔记人工智能
特征缩放(FeatureScaling)详解特征缩放是机器学习数据预处理的关键步骤,旨在将不同特征的数值范围统一到相近的尺度,从而加速模型训练、提升性能并避免某些特征主导模型。1.为什么需要特征缩放?(1)问题背景量纲不一致:例如:特征1:年龄(范围0-100)特征2:收入(范围0-1,000,000)梯度下降的困境:量纲大的特征(如收入)会导致梯度更新方向偏离最优路径,收敛缓慢。量纲小的特征(如
- 深度学习实战-使用TensorFlow与Keras构建智能模型
程序员Gloria
Python超入门TensorFlowpython
深度学习实战-使用TensorFlow与Keras构建智能模型深度学习已经成为现代人工智能的重要组成部分,而Python则是实现深度学习的主要编程语言之一。本文将探讨如何使用TensorFlow和Keras构建深度学习模型,包括必要的代码实例和详细的解析。1.深度学习简介深度学习是机器学习的一个分支,使用多层神经网络来学习和表示数据中的复杂模式。其广泛应用于图像识别、自然语言处理、推荐系统等领域。
- 【大模型与机器学习解惑】什么是A/B测试,为何进行A/B测试?
以下内容将围绕机器学习中的A/B测试展开,从概念与背景到实施细节、示例代码、优化思路和未来建议,并在最后给出一个整体的“输出目录”供参考。目录什么是机器学习的A/B测试为何要进行A/B测试A/B测试的实施流程示例代码与详细解释优化方向与未来建议结语1.什么是机器学习的A/B测试A/B测试(也常被称作对照试验、SplitTest)最早多用于互联网产品的功能或界面迭代中,指的是将用户或样本随机分为两组
- 详解LLMOps,将DevOps用于大语言模型开发
大家好,在机器学习领域,随着技术的不断发展,将大型语言模型(LLMs)集成到商业产品中已成为一种趋势,同时也带来了许多挑战。为了有效应对这些挑战,数据科学家们转向了一种新型的DevOps实践LLM-OPS,专为大型语言模型的开发和维护而设计。本文将介绍LLM-OPS的核心思想,并分析这一策略如何帮助数据科学家更高效地运用DevOps的优秀实践,从而在语言模型的开发和部署过程中,提升工作效率和成果的
- 搜广推校招面经九十一
美团机器学习/数据挖掘算法工程师_二面一、介绍一下ESMM模型,是否有进行过函数推导传统的转化率建模方式:只用发生点击(click=1)的样本来训练CVR模型。CVR定义如下:CVR=P(y=1∣x,z=1)CVR=P(y=1|x,z=1)CVR=P(y=1∣x,z=1)y=1表示用户发生了转化(如购买)z=1表示用户点击了广告这样做的问题:样本选择偏差(SampleSelectionBias,S
- python 计算生态概览的概述
文章目录前言python计算生态库的介绍1.网络爬虫2.数据分析3.文本处理4.数据可视化5.机器学习6.图形用户界面7.游戏开发8.网络应用开发前言python计算生态概览的解释Python计算生态概览是对Python作为一门强大而广泛使用的编程语言所拥有的庞大软件集合的整体描述和概述。这个生态体系不仅包含了Python的标准库(stdlib),即随Python解释器安装的基本模块,还涵盖了极其
- Google机器学习实践指南(模型预测偏差)
AI_Auto
人工智能机器学习人工智能
Google机器学习(31)-模型预测偏差预测偏差:模型为何总是"猜不准"的真相揭秘你的模型预测准确率高达95%,却总是与实际情况差那么一点点?这可能是预测偏差在作祟!本文将带你深入探索这个被忽视的模型"隐形杀手"。一、什么是预测偏差?一个生活化案例想象一下,你网购了一个智能体重秤,连续一周称重显示都是60kg。但你去健身房用专业设备测量,实际是62kg。这种系统性的测量偏差,就是预测偏差在现实中
- 【机器学习|学习笔记】用 Python 结合 graphviz 生成 ID3、C4.5、CART 三种决策树的结构示意图。
【机器学习|学习笔记】用Python结合graphviz生成ID3、C4.5、CART三种决策树的结构示意图【机器学习|学习笔记】用Python结合graphviz生成ID3、C4.5、CART三种决策树的结构示意图文章目录【机器学习|学习笔记】用Python结合graphviz生成ID3、C4.5、CART三种决策树的结构示意图用Python结合graphviz生成ID3、C4.5、CART三种
- 智能产品经理的核心能力
AI天才研究院
AgenticAI实战AI人工智能与大数据AI大模型企业级应用开发实战计算科学神经计算深度学习神经网络大数据人工智能大型语言模型AIAGILLMJavaPython架构设计AgentRPA
智能产品经理的核心能力1.背景介绍在当今快节奏的数字时代,产品经理扮演着至关重要的角色,他们负责确保产品满足用户需求,实现商业目标,并保持竞争优势。随着人工智能(AI)和机器学习(ML)技术的不断发展,智能产品经理的概念应运而生。智能产品经理需要将传统的产品管理技能与新兴技术相结合,以创建具有创新性和智能化的产品体验。智能产品不仅需要满足功能需求,还需要提供个性化、智能化和无缝的用户体验。这对产品
- 使用Python进行机器学习入门指南
软考和人工智能学堂
Python开发经验python机器学习开发语言
使用Python进行机器学习入门指南机器学习(MachineLearning)是人工智能(ArtificialIntelligence,AI)的一个重要分支,旨在通过算法和统计模型,使计算机系统能够自动从数据中学习和改进。Python作为机器学习领域的主流编程语言,提供了丰富的库和工具来实现各种机器学习任务。本文将介绍如何使用Python进行机器学习,包括基本概念、常用库以及一个实战项目示例。目录
- 【亲测免费】 CatBoost 教程项目使用指南
CatBoost教程项目使用指南tutorials项目地址:https://gitcode.com/gh_mirrors/tutorials1/tutorials1.项目介绍CatBoost是一个高效、灵活且易于使用的梯度提升库,特别适用于处理分类特征。它由Yandex开发,广泛应用于机器学习和数据科学领域。CatBoost提供了丰富的功能,包括自动处理分类特征、支持GPU训练、内置的交叉验证和模
- Python自动化机器学习平台库之mindsdb使用详解
概要MindsDB是一个开源的自动化机器学习平台,它通过SQL接口简化了机器学习模型的创建、训练和预测过程。该库的核心理念是将机器学习功能直接集成到数据库中,让开发者无需深入了解复杂的机器学习算法,就能够快速构建和部署预测模型。MindsDB支持多种数据源连接,包括MySQL、PostgreSQL、MongoDB等主流数据库,同时提供了丰富的PythonAPI接口,使得数据科学家和开发者能够在熟悉
- 堡垒机操作行为异常检测的机器学习算法应用
一、传统检测模式的困境与机器学习的破局价值在数字化转型浪潮中,堡垒机作为运维安全的核心防线,面临着操作行为复杂度激增与检测能力滞后的双重挑战。传统检测手段主要依赖静态规则库与统计模型,存在三大致命缺陷:规则固化与误报泛滥:某金融机构曾因规则库未及时更新,导致运维人员正常批量操作被误判为“暴力破解”,单日误报量超2000次,消耗安全团队60%的精力。动态行为适应性弱:微服务架构下,运维人员访问路径呈
- 最全 自动驾驶数据集 (11/4号已更新)
数据猎手小k
自动驾驶人工智能机器学习
自动驾驶是一个快速发展的行业,它融合了人工智能、机器学习、传感器技术、高精度地图和先进的计算平台等多种技术。技术方面,自动驾驶汽车依赖于先进的传感器、如激光雷达、摄像头、毫米波雷达等,以及强大的计算平台来处理大量数据,自动驾驶数据集是训练和验证自动驾驶系统的关键资源,它提供了丰富的场景和条件,使算法能够学习和适应复杂的真实世界驾驶环境。一、研究背景自动驾驶技术的发展需要大量的数据来训练和优化算法,
- 机器学习深度学习驱动在光子学设计中的应用与未来【专题培训会议邀您共探科技前沿】
软研科技
信息与通信信号处理量子计算人工智能
一、背景介绍在智能科技飞速发展的今天,光子学设计与智能算法的结合正成为科研创新的热点。深度学习、机器学习等算法在光子器件的逆向设计、超构表面材料设计、光学神经网络构建等方面展现出巨大潜力。二、会议亮点由北京软研国际信息技术研究院主办的“智能算法驱动的光子学设计与应用”专题培训会议,将深入探讨以下核心内容:光子器件的逆向设计:利用深度学习优化多参数光子器件设计。超构表面与超材料设计:智能算法在新型光
- 机器学习与光子学的融合正重塑光学器件设计范式
m0_75133639
光电智能电视二维材料电子半导体人工智能顶刊nature
Nature/Science最新研究表明,该交叉领域聚焦六大前沿方向:光子器件逆向设计、超构材料智能优化、光子神经网络加速器、非线性光学芯片开发、多任务协同优化及光谱智能预测。系统掌握该领域需构建四维知识体系:1、基础融合——从空间/集成光学系统切入,解析机器学习赋能光学的理论必然性,涵盖光学神经网络构建原理2、逆向设计革命——通过AnsysOptics实战,掌握FDTD算法与粒子群/拓扑优化技术
- AI模型训练新范式:基于同态加密的隐私保护方案
AIGC应用创新大全
人工智能同态加密区块链ai
AI模型训练新范式:基于同态加密的隐私保护方案技术解析关键词同态加密(HomomorphicEncryption)、隐私保护机器学习(PPML)、全同态加密(FHE)、安全多方计算(MPC)、加密数据训练摘要本报告系统解析基于同态加密的AI模型训练新范式,覆盖从理论基础到工程实践的全生命周期。首先通过第一性原理推导同态加密的数学本质,对比传统隐私保护技术的局限性;其次构建“加密-训练-解密”全流程
- 量子机器学习入门:从理论到实践
量子机器学习入门:从理论基石到实践路径元数据框架标题量子机器学习入门:从理论基石到实践路径——连接量子计算与人工智能的未来桥梁关键词量子计算;机器学习;量子算法;量子神经网络;Qiskit;PennyLane;量子变分算法摘要量子机器学习(QuantumMachineLearning,QML)是量子计算与机器学习的交叉领域,通过量子计算的叠加态、纠缠和并行性解决传统机器学习的计算瓶颈(如高维数据处
- 全球人工智能与机器学习大会PPT
a flying bird
论文解读和大咖技术号记录人工智能
大会演讲PPT合集https://ppt.infoq.cn/list/93PPT分享|ppt|人工智能|aicon|infoq|机器学习PPT分享,前段时间的AICon北京站2021全球人工智能与机器学习大会(https://aicon.infoq.cn/2021/beijing),汇集了很多业界大佬,工业界多个方向的从业人员分享了他们在实际业……https://xw.qq.com/cmsid/2
- 人工智能基础知识PPT课件
智慧化智能化数字化方案
方案解读馆人工智能入门人工智能学习人工智能课件人工智能PPT
人工智能基础知识定义与概念:人工智能是研究、开发用于模拟、延伸和扩展人类智能行为的综合性科学,其目的是让计算机系统具备执行人类智能任务的能力。涉及计算机科学、数学等多学科,研究对象是让系统具备智能,智能包括认知、适应和自主能力等维度。学派与方法学派:有符号主义、联结主义、行为主义等学派,分别从不同角度研究人工智能。方法:包括基于知识、学习和仿生的方法,如专家系统、机器学习、深度学习等。分类与发展分
- 数据挖掘:从理论到实践的深度探索
代码老y
数据挖掘人工智能
在当今数字化时代,数据已经成为企业决策的重要依据。数据挖掘作为一门从大量数据中提取有价值信息的技术,已经广泛应用于各个领域,如金融、医疗、零售、互联网等。本文将深入探讨数据挖掘的基本概念、主要技术和实际应用案例,帮助读者更好地理解数据挖掘的价值和应用。一、数据挖掘的基本概念(一)数据挖掘的定义数据挖掘(DataMining)是从大量数据中提取有用信息的过程。它结合了统计学、机器学习、数据库技术和人
- 开发智能化的企业并购风险评估模型
开发智能化的企业并购风险评估模型关键词:企业并购、风险评估、人工智能、机器学习、深度学习、数学建模摘要:本文详细探讨了开发智能化企业并购风险评估模型的背景、核心概念、算法原理、系统架构设计以及项目实战。通过结合机器学习和深度学习技术,提出了一种基于数据驱动的智能化风险评估方法,旨在帮助企业更准确地识别和预测并购过程中的潜在风险,提升决策的科学性和有效性。第1章:企业并购风险评估模型的背景与问题描述
- 机器学习手写字体识别系统:技术演进与应用实践
万能小贤哥
机器学习人工智能
引言:手写字体识别的技术定位与价值在信息处理领域,人工录入手写文本的低效性与机器识别的高效性形成鲜明对比。例如,医疗处方的人工处理需约5分钟/张,而采用手写字体识别技术可将时间缩短至10秒/张,显著提升处理效率。作为计算机视觉与人工智能的重要分支,手写字体识别技术通过将手写文本转换为可编辑电子文本,不仅大幅减少人工输入时间和错误,降低人工处理成本,还能在大量数据处理时保持高于人工录入的准确性,是人
- 机器学习算法:核心原理与前沿发展综述
fmvrj34202
机器学习算法人工智能
机器学习算法作为人工智能的核心驱动力,正在重塑我们解决问题的范式。本文将系统性地探讨机器学习算法的分类体系、数学基础、优化方法以及最新发展趋势,为从业者提供技术参考。一、算法分类体系根据学习范式,机器学习算法可分为三大类:监督学习:基于标注数据的建模方法线性回归:最小化平方误差的闭式解θ=(XᵀX)⁻¹Xᵀy支持向量机:通过核技巧实现非线性分类,优化目标为max(0,1-yᵢ(w·xᵢ+b))决策
- 「日拱一码」020 机器学习——数据处理
胖达不服输
「日拱一码」机器学习人工智能数据处理python
目录数据清洗缺失值处理删除缺失值:填充缺失值:重复值处理检测重复值处理重复值异常值处理Z-score方法IQR方法(四分位距)数据一致性检查数据转换规范化(归一化)Min-Max归一化MaxAbsScaler标准化离散化等宽离散化等频离散化数据清洗数据清洗是数据处理的第一步,目的是去除噪声数据、处理缺失值和异常值,使数据更加干净、可用缺失值处理删除缺失值:如果数据集中缺失值较少,可以直接删除包含缺
- 机器学习每周挑战——二手车车辆信息&交易售价数据
梦想成为一名机器学习高手
机器学习python人工智能
这是数据集的截图目录背景描述数据说明车型对照:燃料类型对照:老规矩,第一步先导入用到的库第二步,读入数据:第三步,数据预处理第四步:对数据的分析第五步:模型建立前的准备工作第六步:多元线性回归模型的建立第七步:随机森林模型的建立问题:背景描述本数据爬取自印度最大的二手车交易平台CARS24,包含8000+该平台上交易车辆的关键评估信息。CARS24成立于2015年,总部位于印度古尔冈,是一个在印度
- LeetCode[位运算] - #137 Single Number II
Cwind
javaAlgorithmLeetCode题解位运算
原题链接:#137 Single Number II
要求:
给定一个整型数组,其中除了一个元素之外,每个元素都出现三次。找出这个元素
注意:算法的时间复杂度应为O(n),最好不使用额外的内存空间
难度:中等
分析:
与#136类似,都是考察位运算。不过出现两次的可以使用异或运算的特性 n XOR n = 0, n XOR 0 = n,即某一
- 《JavaScript语言精粹》笔记
aijuans
JavaScript
0、JavaScript的简单数据类型包括数字、字符创、布尔值(true/false)、null和undefined值,其它值都是对象。
1、JavaScript只有一个数字类型,它在内部被表示为64位的浮点数。没有分离出整数,所以1和1.0的值相同。
2、NaN是一个数值,表示一个不能产生正常结果的运算结果。NaN不等于任何值,包括它本身。可以用函数isNaN(number)检测NaN,但是
- 你应该更新的Java知识之常用程序库
Kai_Ge
java
在很多人眼中,Java 已经是一门垂垂老矣的语言,但并不妨碍 Java 世界依然在前进。如果你曾离开 Java,云游于其它世界,或是每日只在遗留代码中挣扎,或许是时候抬起头,看看老 Java 中的新东西。
Guava
Guava[gwɑ:və],一句话,只要你做Java项目,就应该用Guava(Github)。
guava 是 Google 出品的一套 Java 核心库,在我看来,它甚至应该
- HttpClient
120153216
httpclient
/**
* 可以传对象的请求转发,对象已流形式放入HTTP中
*/
public static Object doPost(Map<String,Object> parmMap,String url)
{
Object object = null;
HttpClient hc = new HttpClient();
String fullURL
- Django model字段类型清单
2002wmj
django
Django 通过 models 实现数据库的创建、修改、删除等操作,本文为模型中一般常用的类型的清单,便于查询和使用: AutoField:一个自动递增的整型字段,添加记录时它会自动增长。你通常不需要直接使用这个字段;如果你不指定主键的话,系统会自动添加一个主键字段到你的model。(参阅自动主键字段) BooleanField:布尔字段,管理工具里会自动将其描述为checkbox。 Cha
- 在SQLSERVER中查找消耗CPU最多的SQL
357029540
SQL Server
返回消耗CPU数目最多的10条语句
SELECT TOP 10
total_worker_time/execution_count AS avg_cpu_cost, plan_handle,
execution_count,
(SELECT SUBSTRING(text, statement_start_of
- Myeclipse项目无法部署,Undefined exploded archive location
7454103
eclipseMyEclipse
做个备忘!
错误信息为:
Undefined exploded archive location
原因:
在工程转移过程中,导致工程的配置文件出错;
解决方法:
- GMT时间格式转换
adminjun
GMT时间转换
普通的时间转换问题我这里就不再罗嗦了,我想大家应该都会那种低级的转换问题吧,现在我向大家总结一下如何转换GMT时间格式,这种格式的转换方法网上还不是很多,所以有必要总结一下,也算给有需要的朋友一个小小的帮助啦。
1、可以使用
SimpleDateFormat SimpleDateFormat
EEE-三位星期
d-天
MMM-月
yyyy-四位年
- Oracle数据库新装连接串问题
aijuans
oracle数据库
割接新装了数据库,客户端登陆无问题,apache/cgi-bin程序有问题,sqlnet.log日志如下:
Fatal NI connect error 12170.
VERSION INFORMATION: TNS for Linux: Version 10.2.0.4.0 - Product
- 回顾java数组复制
ayaoxinchao
java数组
在写这篇文章之前,也看了一些别人写的,基本上都是大同小异。文章是对java数组复制基础知识的回顾,算是作为学习笔记,供以后自己翻阅。首先,简单想一下这个问题:为什么要复制数组?我的个人理解:在我们在利用一个数组时,在每一次使用,我们都希望它的值是初始值。这时我们就要对数组进行复制,以达到原始数组值的安全性。java数组复制大致分为3种方式:①for循环方式 ②clone方式 ③arrayCopy方
- java web会话监听并使用spring注入
bewithme
Java Web
在java web应用中,当你想在建立会话或移除会话时,让系统做某些事情,比如说,统计在线用户,每当有用户登录时,或退出时,那么可以用下面这个监听器来监听。
import java.util.ArrayList;
import java.ut
- NoSQL数据库之Redis数据库管理(Redis的常用命令及高级应用)
bijian1013
redis数据库NoSQL
一 .Redis常用命令
Redis提供了丰富的命令对数据库和各种数据库类型进行操作,这些命令可以在Linux终端使用。
a.键值相关命令
b.服务器相关命令
1.键值相关命令
&
- java枚举序列化问题
bingyingao
java枚举序列化
对象在网络中传输离不开序列化和反序列化。而如果序列化的对象中有枚举值就要特别注意一些发布兼容问题:
1.加一个枚举值
新机器代码读分布式缓存中老对象,没有问题,不会抛异常。
老机器代码读分布式缓存中新对像,反序列化会中断,所以在所有机器发布完成之前要避免出现新对象,或者提前让老机器拥有新增枚举的jar。
2.删一个枚举值
新机器代码读分布式缓存中老对象,反序列
- 【Spark七十八】Spark Kyro序列化
bit1129
spark
当使用SparkContext的saveAsObjectFile方法将对象序列化到文件,以及通过objectFile方法将对象从文件反序列出来的时候,Spark默认使用Java的序列化以及反序列化机制,通常情况下,这种序列化机制是很低效的,Spark支持使用Kyro作为对象的序列化和反序列化机制,序列化的速度比java更快,但是使用Kyro时要注意,Kyro目前还是有些bug。
Spark
- Hybridizing OO and Functional Design
bookjovi
erlanghaskell
推荐博文:
Tell Above, and Ask Below - Hybridizing OO and Functional Design
文章中把OO和FP讲的深入透彻,里面把smalltalk和haskell作为典型的两种编程范式代表语言,此点本人极为同意,smalltalk可以说是最能体现OO设计的面向对象语言,smalltalk的作者Alan kay也是OO的最早先驱,
- Java-Collections Framework学习与总结-HashMap
BrokenDreams
Collections
开发中常常会用到这样一种数据结构,根据一个关键字,找到所需的信息。这个过程有点像查字典,拿到一个key,去字典表中查找对应的value。Java1.0版本提供了这样的类java.util.Dictionary(抽象类),基本上支持字典表的操作。后来引入了Map接口,更好的描述的这种数据结构。
&nb
- 读《研磨设计模式》-代码笔记-职责链模式-Chain Of Responsibility
bylijinnan
java设计模式
声明: 本文只为方便我个人查阅和理解,详细的分析以及源代码请移步 原作者的博客http://chjavach.iteye.com/
/**
* 业务逻辑:项目经理只能处理500以下的费用申请,部门经理是1000,总经理不设限。简单起见,只同意“Tom”的申请
* bylijinnan
*/
abstract class Handler {
/*
- Android中启动外部程序
cherishLC
android
1、启动外部程序
引用自:
http://blog.csdn.net/linxcool/article/details/7692374
//方法一
Intent intent=new Intent();
//包名 包名+类名(全路径)
intent.setClassName("com.linxcool", "com.linxcool.PlaneActi
- summary_keep_rate
coollyj
SUM
BEGIN
/*DECLARE minDate varchar(20) ;
DECLARE maxDate varchar(20) ;*/
DECLARE stkDate varchar(20) ;
DECLARE done int default -1;
/* 游标中 注册服务器地址 */
DE
- hadoop hdfs 添加数据目录出错
daizj
hadoophdfs扩容
由于原来配置的hadoop data目录快要用满了,故准备修改配置文件增加数据目录,以便扩容,但由于疏忽,把core-site.xml, hdfs-site.xml配置文件dfs.datanode.data.dir 配置项增加了配置目录,但未创建实际目录,重启datanode服务时,报如下错误:
2014-11-18 08:51:39,128 WARN org.apache.hadoop.h
- grep 目录级联查找
dongwei_6688
grep
在Mac或者Linux下使用grep进行文件内容查找时,如果给定的目标搜索路径是当前目录,那么它默认只搜索当前目录下的文件,而不会搜索其下面子目录中的文件内容,如果想级联搜索下级目录,需要使用一个“-r”参数:
grep -n -r "GET" .
上面的命令将会找出当前目录“.”及当前目录中所有下级目录
- yii 修改模块使用的布局文件
dcj3sjt126com
yiilayouts
方法一:yii模块默认使用系统当前的主题布局文件,如果在主配置文件中配置了主题比如: 'theme'=>'mythm', 那么yii的模块就使用 protected/themes/mythm/views/layouts 下的布局文件; 如果未配置主题,那么 yii的模块就使用 protected/views/layouts 下的布局文件, 总之默认不是使用自身目录 pr
- 设计模式之单例模式
come_for_dream
设计模式单例模式懒汉式饿汉式双重检验锁失败无序写入
今天该来的面试还没来,这个店估计不会来电话了,安静下来写写博客也不错,没事翻了翻小易哥的博客甚至与大牛们之间的差距,基础知识不扎实建起来的楼再高也只能是危楼罢了,陈下心回归基础把以前学过的东西总结一下。
*********************************
- 8、数组
豆豆咖啡
二维数组数组一维数组
一、概念
数组是同一种类型数据的集合。其实数组就是一个容器。
二、好处
可以自动给数组中的元素从0开始编号,方便操作这些元素
三、格式
//一维数组
1,元素类型[] 变量名 = new 元素类型[元素的个数]
int[] arr =
- Decode Ways
hcx2013
decode
A message containing letters from A-Z is being encoded to numbers using the following mapping:
'A' -> 1
'B' -> 2
...
'Z' -> 26
Given an encoded message containing digits, det
- Spring4.1新特性——异步调度和事件机制的异常处理
jinnianshilongnian
spring 4.1
目录
Spring4.1新特性——综述
Spring4.1新特性——Spring核心部分及其他
Spring4.1新特性——Spring缓存框架增强
Spring4.1新特性——异步调用和事件机制的异常处理
Spring4.1新特性——数据库集成测试脚本初始化
Spring4.1新特性——Spring MVC增强
Spring4.1新特性——页面自动化测试框架Spring MVC T
- squid3(高命中率)缓存服务器配置
liyonghui160com
系统:centos 5.x
需要的软件:squid-3.0.STABLE25.tar.gz
1.下载squid
wget http://www.squid-cache.org/Versions/v3/3.0/squid-3.0.STABLE25.tar.gz
tar zxf squid-3.0.STABLE25.tar.gz &&
- 避免Java应用中NullPointerException的技巧和最佳实践
pda158
java
1) 从已知的String对象中调用equals()和equalsIgnoreCase()方法,而非未知对象。 总是从已知的非空String对象中调用equals()方法。因为equals()方法是对称的,调用a.equals(b)和调用b.equals(a)是完全相同的,这也是为什么程序员对于对象a和b这么不上心。如果调用者是空指针,这种调用可能导致一个空指针异常
Object unk
- 如何在Swift语言中创建http请求
shoothao
httpswift
概述:本文通过实例从同步和异步两种方式上回答了”如何在Swift语言中创建http请求“的问题。
如果你对Objective-C比较了解的话,对于如何创建http请求你一定驾轻就熟了,而新语言Swift与其相比只有语法上的区别。但是,对才接触到这个崭新平台的初学者来说,他们仍然想知道“如何在Swift语言中创建http请求?”。
在这里,我将作出一些建议来回答上述问题。常见的
- Spring事务的传播方式
uule
spring事务
传播方式:
新建事务
required
required_new - 挂起当前
非事务方式运行
supports
&nbs