车道线检测Learning Lightweight Lane Detection CNNs by Self Attention Distillation
Learning Lightweight Lane Detection CNNs by Self Attention Distillation
2019 ICCV
摘要
由于车道标注中固有的非常稀疏的监控信号,训练车道检测的深度模型是一个挑战。没有从更丰富的环境中学习,这些模型往往在具有挑战性的场景中失败,例如,严重的遮挡、模糊的车道和糟糕的照明条件。本文提出了一种新的知识蒸馏方法,即自我注意力蒸馏(self attention distillation)(SAD),它允许一个模型从自身学习并获得实质性的改进,而不需要任何额外的监督或标签。具体来说,我们观察到,从训练到合理水平的模型中提取的注意力地图将编码丰富的上下文信息。有价值的上下文信息可以作为一种自由监督的形式,通过在网络自身执行自上而下和分层的注意力蒸馏网络进行进一步表征学习。SAD可以很容易地整合到任何前馈卷积神经网络(CNN)中,并且不会增加推理时间。我们使用ENet、ResNet- 18和ResNet-34等轻量级模型,在三个流行的车道检测基准(TuSimple、CULane和BDD100K)上验证了SAD。最轻的模型ENet-SAD的性能相对较好,甚至超过了现有的算法。值得注意的是,与最先进的SCNN[16]相比,ENet-SAD的参数减少了20倍,运行速度提高了10倍,同时在所有基准测试中仍然实现了令人瞩目的性能。
Github: https://github.com/cardwing/Codes-for-Lane-Detection
1. 介绍
把车道线检测视为语义分割任务,将图像中的每个像素赋值为一个二进制标签,以指示它是否属于某个车道
主要挑战:车道又长又细,带注释的车道像素的数量远远少于背景像素,从这样细微而稀疏的注释中学习成为为任务训练深度模型的主要挑战。
方案: 为了减轻深度模型对稀疏标注的依赖,提出了几种方案,例如多任务学习(MTL)和消息传递(MP)。
MTL可以提供额外的监控信号,但它需要额外的工作来准备注释,例如,场景分割地图、消失点或可驾驶区域。(VPP)
MP可以帮助在神经元之间传播信息,抵消稀疏监督的效果,更好地捕捉场景上下文。但是,由于MP的开销,极大地增加了推理时间。(SCNN)
在这项工作中,我们提出了一个方法,允许车道检测网络在不需要额外的标签和外部监督的情况下,加强其自身的表征学习。此外,它不会增加基本模型的推理时间。我们的方法被称为自我注意力蒸馏(Self-Attention Distillation)(SAD)。顾名思义,SAD允许网络利用来自身层的注意力地图作为其低层的精馏目标。这种注意力提取机制被用来补充通常基于分段的监督学习。
当一个车道检测网络被训练到一个合理的水平时,来自不同层次的注意力地图会捕捉到多样化和丰富的上下文信息,提示车道的位置和场景的大致轮廓,如图1所示。

使用SAD后
(1)低层的注意力地图被细化,视觉注意力捕获了更丰富的场景上下文
(2)较低层次中学习到的更好的表示反过来又有利于更深层次
2. 相关工作
2.1车道线检测
基于特征
深度学习
(1)DVCNN: 以前视图和俯视图作为输入
(2)Toward end to end : 将车道检测分为两个阶段,背景/目标 + 实例分割
(3)同时实现车道边界分割和道路面积分割的框架(几何约束,车道边界和车道区域构成)
(4)ELGAN:将lane标签作为额外的输入,将GAN整合到原始框架中,使分割图更接近标签。
(5)SCNN: 每层内的信息传递
2.2 知识蒸馏和注意力蒸馏
目的:将知识从大网络转移到小网络。
通常在知识提取过程中,一个小型的学生网络会模仿大型教师网络和标签的中间输出。
最近的研究将知识蒸馏拓展为注意力蒸馏,学生网络通过学习来自教师网络的注意力图来训练。
作者的SAD方法不需要教师网络。蒸馏是按层次和自上而下的方式进行的,在这种方式中**,注意力知识是逐层传播的**。作者的重点是研究提取分层的注意力进行自我学习的可能性。
3. 方法
3.1 自我注意力蒸馏
除了使用上述的语义分割和车道存在预测损失来训练我们的车道检测网络外,我们的目标是进行分层和自顶向下的注意力提取来增强表征学习过程。
提出的SAD不需要任何外部监督或额外的标签,因为注意力地图来自网络本身。
注意力地图分为两类:基于激活的注意力地图和基于梯度的注意力地图
基于激活的注意力地图:通过处理特定层的激活输出得到
基于梯度的注意力地图:利用层的梯度输出得到
在实验中,我们根据经验发现,基于激活的注意力蒸馏可以获得可观的性能收益
Activation-based注意蒸馏
![]()
(C:通道 H:高 W:宽)
映射中每个元素的绝对值表示此元素对最终输出的重要性。因此,可以通过计算这些值在通道维度上的统计信息来构造映射函数。有三种:
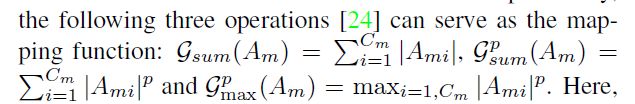
三种映射效果如图2

可得,使用![]() 作为映射函数可以获得最大的性能收益。
作为映射函数可以获得最大的性能收益。
在训练中加入SAD
SAD中,前一层的注意力图可以从后续层中提取有用的上下文信息。如果原始注意图的大小与目标的大小不同,则在softmax操作之前添加双线性上采样B(?。
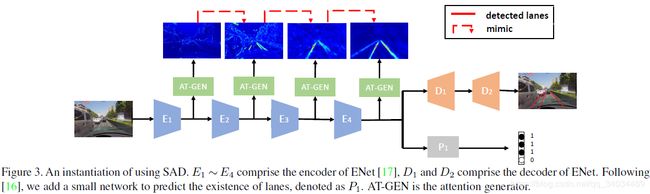
实验中,在不同时间点引入SAD。在ENet训练40K次后加入。结构如图3所示,分别在E2、E3、E4解码器后加入注意力生成器(AT-GEN)
逐层蒸馏损失的表达式:


总的损失函数:
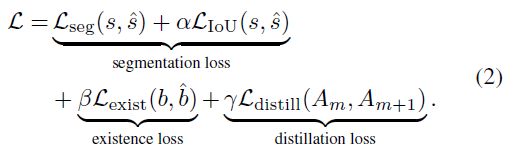
第一项为分割损失,由语义图的标准交叉熵损失和IOU损失构成
第二项为二值化图的二元交叉熵损失,用于预测车道线是否存在
3.2 车道线处理
除CULane外,TuSimple和BDD100K没有对模型的输出进行后处理。
在CUlane数据集下,通过ENet模型,得到多通道概率图和车道存在向量。
Follow SCNN:
(1)使用一个9*9核来平滑概率图;
(2)对于每条存在概率大于0.5的车道,每隔20行搜索对应的概率图,寻找概率值最高的位置。
(3)拟合曲线
3.3 结构设计
原有的ENet模型由四个编码器和2个解码器构成。
改进:
(1)Follow SCNN:在编码器后加入一个小的网络P1来预测lane的存在
(2)在预测分支采用扩张卷积核以增大感受视野
(3)使用特性连接来将E4的输出与E3的输出融合在一起
4. 实验
4.1 结果
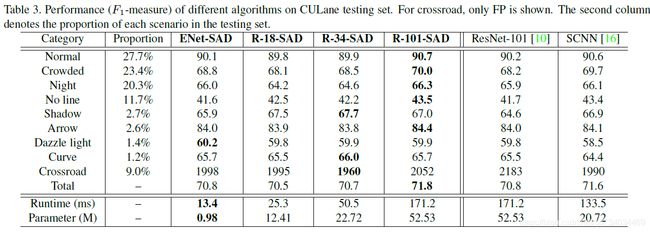
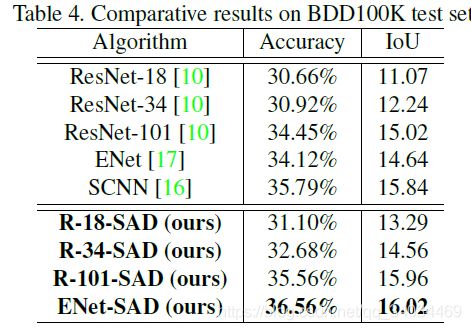

4.2 Ablation Study
我们研究了不同因素对最终性能的影响,如模仿路径。此外,我们还进行了大量的实验来调查在训练过程中引入SAD的时间点。
SAD蒸馏路径
表现:
(1) SAD在中层和高层工作良好。
(2)在低层添加SAD会降低性能。
(3)与模仿非相邻层的注意力图相比,模仿相邻层的注意力图会带来更多的性能提升
原因:在低层加入影响全局信息
反向蒸馏
测试了另一种蒸馏方案,使较高的层模拟较低的层。它将ENet的性能从93.02%降低到91.26%。因为低水平的注意力地图包含更多的细节和更多的噪音。使用高层来模拟低层将不可避免地干扰高层捕获的全局信息,从而妨碍车道检测任务的关键线索。
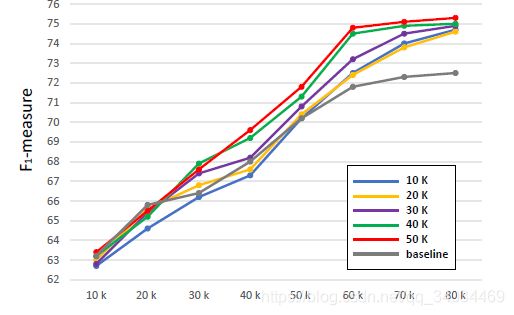
加入SAD的时机
从图8可以看出,虽然引入SAD的不同时间点最终获得的性能几乎相同,但是加入SAD的时间对网络的收敛速度有影响。我们将这一现象归因于后期图层生成的目标注意力图的质量。在早期的训练阶段,由于深层没有得到良好的训练,因此这些层产生的精馏目标质量较低。在这些早期阶段引入SAD并没有那么成功。反之,在后期训练阶段加入SAD有利于前一层的表示学习。