如何使用腾讯智能钛机器学习平台玩转超大数据集比赛
本文原作者:林有夕。
在机器学习领域中,计算力的重要性不言而喻。不仅是某些超大数据集比赛或者图像领域的准入门槛,同时对于很多中等数据集比赛而言,计算力的大小直接影响了你的开发效率。充足的计算力,代表着你可以在同样的时间,做更多的事情。

在2019腾讯社交广告算法大赛用户指南中,建议使用的计算资源为:单机运行内存不超过128G,CPU不超过24核。
而2018腾讯社交广告算法大赛复赛阶段,则需要至少256G内存才可以跑LightGBM模型。
通常计算力的获得需要很大的成本,除了少部分有公司资源、实验室资源、或者自身拥有服务器的氪金大佬,大部分参赛选手则深受机器的困扰。
带着由衷的感激,这里向大家推荐的腾讯智能钛机器学习平台TI-ONE,陪我走过了N多比赛历程,经历了约近万个脚本的考验,接下来就将我的经验分享给大家,希望可以给大家带来帮助。
该教程旨在帮小白从注册账户开始,到运行结束生成第一个sub.csv为止。
1.智能钛机器学习简介
智能钛机器学习(TI Machine Learning,TI-ML)是基于腾讯云强大计算能力的一站式机器学习生态服务平台。它能够对各种数据源、组件、算法、模型和评估模块进行组合,使得算法工程师和数据科学家在其之上能够方便地进行模型训练、评估和预测。智能钛机器学习包括全流程一站式机器学习平台 TI-ONE 、弹性模型服务管理平台 TI-EMS(TI-Elastic Model Service)和工业 AI 平台(TI-Insight)三个子产品。同时,智能钛系列产品支持公有云访问、私有化部署以及专属云部署。
2.注册腾讯云账户
已有账户可跳过
打开TI-ONE官方页面:https://tio.cloud.tencent.com,如果未登陆,便会进入登陆页面,这里可以选择微信登陆或者QQ登陆。
登陆之后,接下来就是日常的关联手机号之类的操作了。(关联手机号即可)
注册完成后的实名认证阶段可以领取腾讯云的一系列免费套餐。
3.如何使用COS服务
完成数据存储、读取、下载的需求
对象存储(Cloud Object Storage,COS)是由腾讯云推出的无目录层次结构、无数据格式限制,可容纳海量数据且支持 HTTP/HTTPS 协议访问的分布式存储服务。腾讯云 COS 的存储桶空间无容量上限,无需分区管理,适用于 CDN 数据分发、数据万象处理或大数据计算与分析的数据湖等多种场景。COS 提供网页端管理界面、多种主流开发语言的 SDK、API 以及命令行和图形化工具,并且兼容 S3 的 API 接口,方便用户直接使用社区工具和插件。
官方文档地址:https://cloud.tencent.com/document/product/436/6231
COS控制台地址:https://console.cloud.tencent.com/cos5
3.1开通COS服务
第一次打开控制台网址时会弹出如下弹框,点击不再提醒,并关闭弹框。
接下来,实名认证:实名认证完成之后可领取套餐。至此,已经成功开通COS服务。

3.2创建存储桶
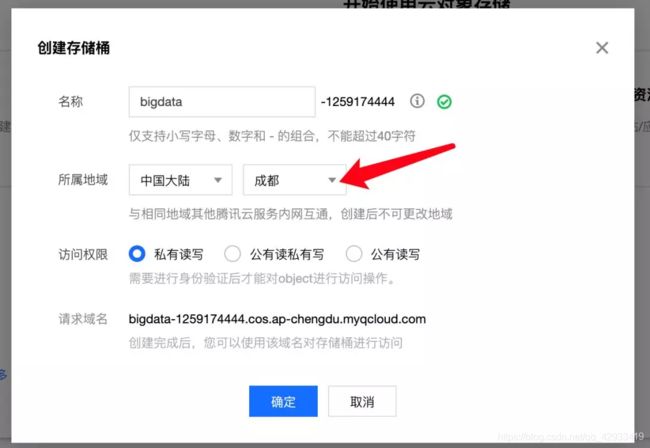
3.3创建文件夹
创建存储桶完成后,进入存储桶管理页面。我们可以看到:可以通过这里来上传文件(上传文件支持多选,支持上传文件夹)以及创建文件夹。
这里创建了 algo_tencent_2019 文件夹,用来存放2019腾讯广告算法大赛的数据以及结果产出。

3.4配置COS访问密钥
点击这个链接配置COS访问密钥:https://console.cloud.tencent.com/cam/capi
点击新建密钥即可以创建密钥。
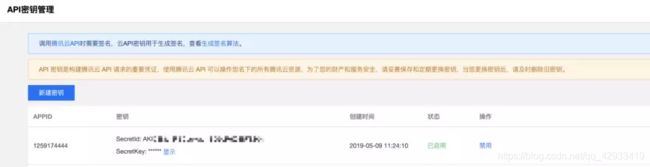
注意:不要让其他人知道哦,因为你的数据以及工作流中的代码,均可通过该密钥访问。如不慎泄漏,可以点击禁用。
注意:COS的交互可以通过网页以及客户端等多种方式。
关于COS的计费规则,请参考官方文档。合理使用的情况下,资费忽略不计。
4.使用TI-ONE服务
4.1获取体验资格
产品入口:https://cloud.tencent.com/product/tio
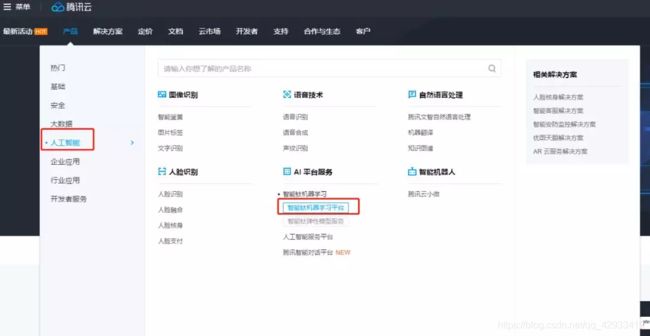
点击立即体验即可获得体验资格,更多细节与贴心的文档,产品小姐姐和技术小哥哥已为你准备好。
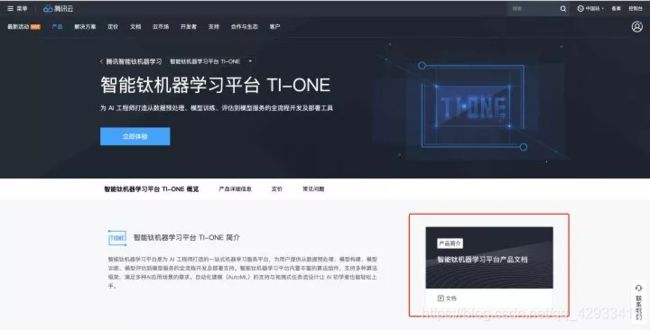
下面我们直奔主题,开始配置执行我们的code。
4.2新建工程
点击立即体验,进入工作台界面,新建一个工程。(PS:一般一个比赛一个工程,或者一个阶段)
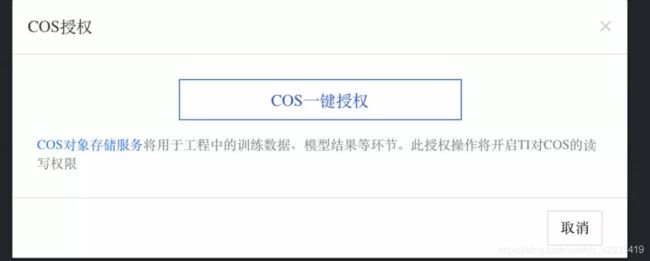
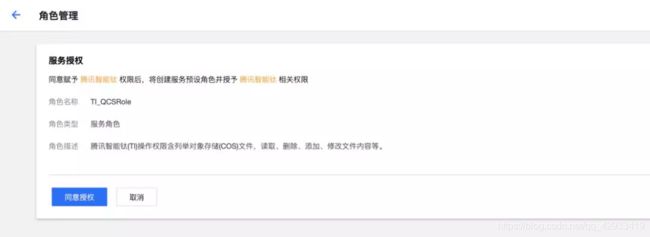
授权成功之后返回重新点击创建。
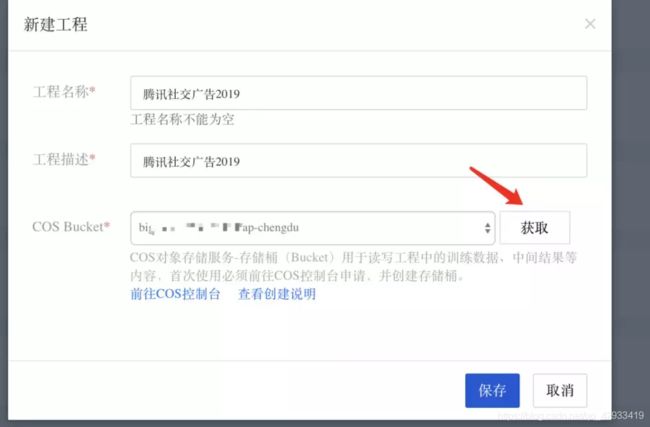
保存之后便成功创建了一个与我们的COS打通的工程。
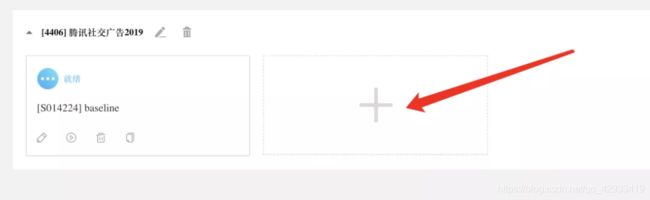
4.3创建工作流
点击+,创建一个工作流。创建之后会默认跳转至工作流页面。
依旧直奔主题,从左侧组件列表,直接拖动TensorFlow组件至右边画布中。
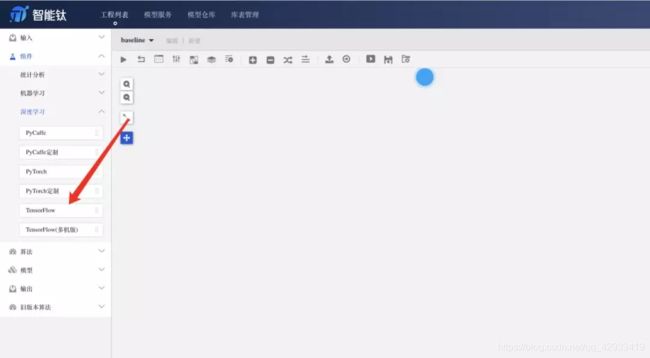
点击Tensorflow组件,重点关注右侧组件参数配置:
程序脚本:程序调起的.py文件,代码写在这里。
Python版本:3.5和2.7,这里我选择的是3.5。
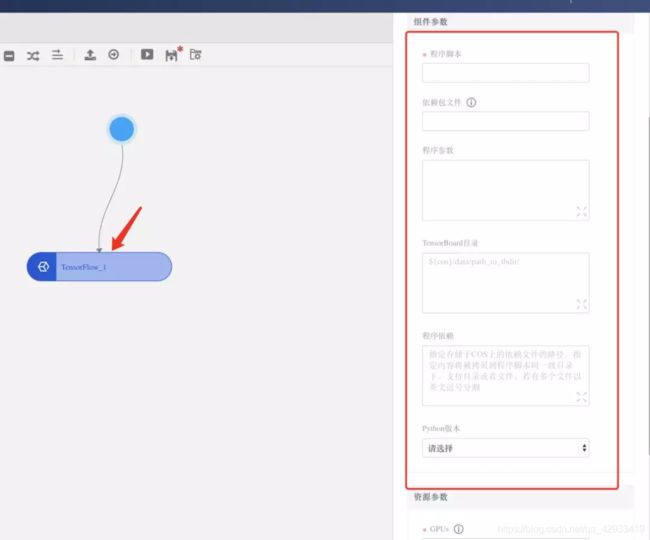
点击程序脚本输入框会弹出脚本资源列表。
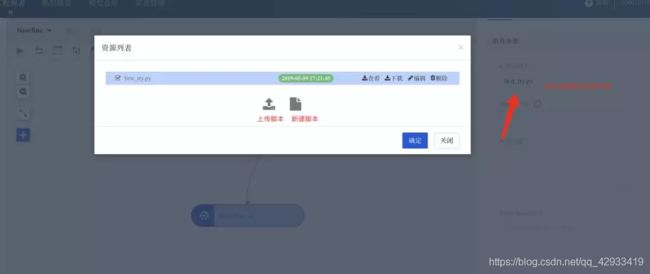
这里我写了一个简单的语句,输出数字666点击保存。


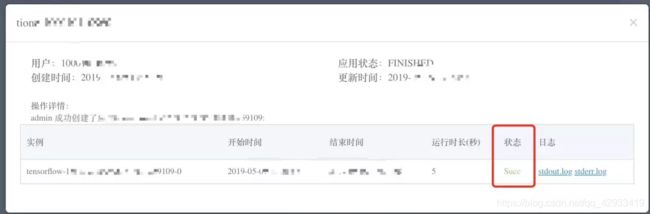
4.4查看运行状态
鼠标右键任务->TensorFlow控制台->App详情,正常情况下会有pending(等待资源)、succ(运行完成)、fail(失败)等状态。
4.5查看运行日志
鼠标右键任务->TensorFlow控制台->App详情->stdout.log(运行日志)/ stderr. Log(错误日志)
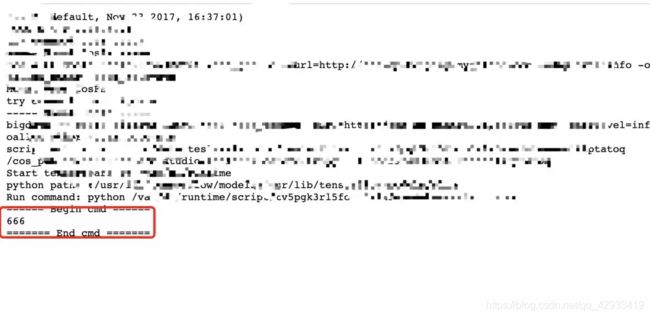
大家都知道脚本运行的过程中,最重要的就是运行包安装、数据读取、建模、运算、输出。这里分别来实现一下。主要还是在于灵活运用os提供的shell功能。
1.运行包安装:
os.system(‘pip install lightgbm’)
2.查看系统状态:
os.system(‘free -g’) 一般是512G内存,偶尔存在128G的机器,所以如果要跑需要大量内存的程序,需要先检查一下是不是分配到了512G的。
os.system(‘cat /proc/cpuinfo| grep “processor”| wc -l’)
CPU数是虚拟CPU数目,一般是56核,但是实际测试应该是10核左右。所以,对于大部分默认使用全部CPU的多线程程序需要留意,例如lgb的n_jobs 或者 n_thread等参数,需要设置为实际的CPU数目为10(可以自己尝试尝试),否则速度会很慢。
3. 日志更新:
系统的日志更新存在缓存的延迟,这里对于调试有点不太友好,这里提供一个设置函数,可以解决缓存延迟问题,在每个脚本开头加上这一句就可以了。
class Unbuffered(object):
def init(self, stream):
self.stream = stream
def write(self, data):
self.stream.write(data)
self.stream.flush()
def getattr(self, attr):
return getattr(self.stream, attr)
import sys
sys.stdout = Unbuffered(sys.stdout)
4. 数据读取:
首先将要处理的数据存放在COS对象存储里,而平台启动的时候,会默认使用远程挂载的功能(COSFS 工具支持将 COS 存储桶挂载到本地,像使用本地文件系统一样直接操作腾讯云对象存储) 。
而COS的根目录对应挂载到了/cos_person目录下,如果我们要访问该train.csv,只需要pd.read_csv(’/cos_person/algo_tencent_2019/data/train.csv’)
5. 数据存储:
把/cos_person目录当作实际的目录就可以了。你对该目录做的所有的操作,读和写,都会同步到COS中,从而通过COS即可以将数据下载。
df.to_csv(’/cos_person/algo_tencent_2019/data/sub.csv’)
6.使用GPU:
目前CPUs 和Memory 的配置并不能代表实际机型的效果。(不影响结果)
GPUs,非0的时候,就会给你挂载一个P40,对于神经网络脚本而言,效率会高很多(只能同时跑一个GPU任务,因为GPU默认配额是一个账户一个)
下面是一个完整的示例:
#-- coding: utf-8 -
import os
import sys
import pip
#设置日志实时刷新
class Unbuffered(object):
def init(self, stream):
self.stream = stream
def write(self, data):
self.stream.write(data)
self.stream.flush()
def getattr(self, attr):
return getattr(self.stream, attr)
sys.stdout = Unbuffered(sys.stdout)
os.system(‘free -h’) # 查看内存分配情况
pip.main([‘install’, ‘lightgbm’]) # 安装包
#主代码
import pandas as pd
import lightgbm as lgb
path = ‘/cos_person/algo_tencent_2019/data/’
train = pd.read_csv(path + ‘/train.csv’) # 读取数据
print(‘train…’) # 训练过程
sub = train.copy() # 假设训练完成
sub.to_csv(path + ‘sub.csv’) # 保存结果
print(‘Done!’)