论文阅读:《Convolutional Neural Networks for Sentence Classification》
https://blog.csdn.net/u011239443/article/details/80094426
论文地址:http://xueshu.baidu.com/s?wd=paperuri%3A%287ea81182039becbb82a22aaae8099c15%29&filter=sc_long_sign&tn=SE_xueshusource_2kduw22v&sc_vurl=http%3A%2F%2Fde.arxiv.org%2Fpdf%2F1408.5882&ie=utf-8&sc_us=17214068522800736720
摘要
我们报告了一系列卷积神经网络(CNN)的实验,这些卷积神经网络是在预先训练过的词语向量的基础上进行训练以进行句子级别的分类任务。 我们展示了一个简单的CNN,带有超级参数调整和静态向量,可以在多个基准测试中取得优异的结果。 通过微调学习特定于任务的矢量可提高性能。 我们另外建议对体系结构进行简单的修改,以允许使用任务特定和静态向量。 本文讨论的CNN模型改进了7项任务中的4项任务的现有技术水平,其中包括情感分析和问题分类。
介绍
近年来,深度学习模型在计算机视觉(Krizhevsky等,2012)和语音识别(Graves等,2013)方面取得了显着成果。 在自然语言处理中,大部分深度学习方法的工作涉及通过神经语言模型学习单词向量表示(Bengio et al。,2003; Yih et al。,2011; Mikolov et al。,2013 )并在学习的单词向量上进行分类以进行分类(Collobert et al。,2011)。 其中单词从稀疏1-V编码(这里V是词汇量大小)通过隐藏层投影到较低维矢量空间上的单词向量实质上是特征提取器,它们对单词的语义特征进行维度编码。 在这样的密集表示中,语义上接近的词在低维矢量空间中同样接近欧几里得或余弦距离。
卷积神经网络(CNN)利用具有应用于局部特征的卷积滤波器的层(LeCun等,1998)。 最初发明用于计算机视觉的CNN模型随后被证明对NLP有效,并在语义分析(Yih等,2014),搜索查询检索(Shen等,2014),句子建模(Kalch - 布伦纳等人,2014年)以及其他传统的NLP任务(Collobert等,2011)。
在目前的工作中,我们训练一个简单的CNN,在从无监督的神经语言模型中得到的单词向量的顶部有一层卷积。 这些载体由Mikolov等人对1000亿字的Google新闻进行了培训,并且是公开可用的。我们最初将单词向量保持为静态,并且只学习模型的其他参数。 尽管对超参数进行了微调,但这个简单模型在多个基准测试中取得了优异的结果,表明预先训练好的向量是可用于各种分类任务的“通用”特征提取器。 通过微调学习任务特定的向量可以进一步改进。 我们最后描述了对架构的简单修改,以允许通过具有多个通道来使用预先训练的和任务特定的载体。
我们的工作在哲学上与Razavian等人的工作相似,这表明对于图像分类,从预先训练的深度学习模型获得的特征提取器在各种任务中表现良好 - 包括与原始任务非常不同的任务提取器接受了训练。
模型
图1所示的模型架构是Collobert等人CNN架构的一个细微变体。

图1:示例句子的两个通道的模型体系结构。
设 xi∈Rk x i ∈ R k 为句子中第i个单词对应的k维单词向量。 长度为n的句子(必要时填充)表示为

其中⊕是连接运算符。 一般来说,让 xi:i+j x i : i + j 参考单词 xi,xi+1,...xi+j x i , x i + 1 , . . . x i + j 的连接。 卷积运算涉及滤波器 w∈Rhk w ∈ R h k ,其被应用于 h h 个词的窗口以产生新的特征。 例如,特征 ci c i 是从单词 xi:i+h−1 x i : i + h − 1 的窗口生成的。
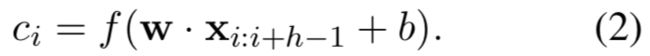
这里b∈R是一个偏置项,f是一个非线性函数,如双曲正切。 该过滤器应用于句子中每个可能的单词窗口 x1:h,x2:h+1,...,xn−h+1:n x 1 : h , x 2 : h + 1 , . . . , x n − h + 1 : n 来产生特征映射。

其中 c∈Rn−h+1 c ∈ R n − h + 1 。 然后,我们在特征映射上应用最大随时间池化操作,并取最大值c = max {c}作为与此特定滤波器相对应的特征。 这个想法是为每个功能图捕获最重要的功能、具有最高价值的功能。 这种池化方案自然处理可变的句子长度。
我们已经描述了从一个过滤器中提取一个特征的过程。 该模型使用多个滤镜(具有不同的窗口大小)来获取多个特征。 这些特征形成倒数第二层并传递到完全连接的softmax层,其输出是标签上的概率分布。
在其中一个模型变体中,我们试验了两个词向量的“通道” - 一个在整个训练过程中保持静态,另一个通过反向传播进行微调(3.2节)。在多通道体系结构中,如图1所示, 将每个滤波器应用于两个通道,并将结果相加以计算方程(2)中的 ci c i 。 该模型在其他方面等同于单通道架构。
正则化
对于正则化,我们在倒数第二层上使用Dropout,并对权向量的l2范数进行约束。
数据集和实验步骤
我们在各种基准测试我们的模型。 数据集的总结统计见表1。
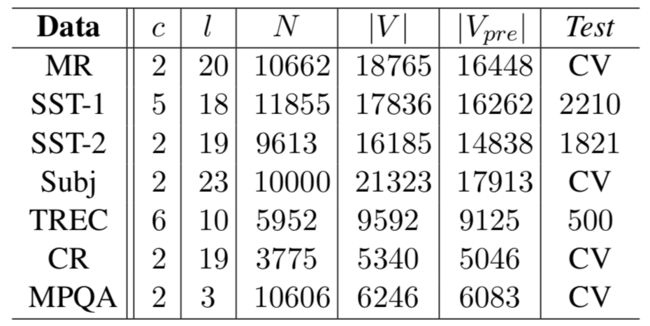
表1:标记后数据集的汇总统计。 c:目标类的数量。 l:平均句子长度。 N:数据集大小。 | V |:词汇大小。 | Vpre |:预先训练的单词向量集中存在的单词数。 Test:测试集大小(CV意味着没有标准训练/测试分割,因此使用10倍CV)。
超参数和训练
对于所有数据集我们使用:校正的线性单位;对每个100个特征图使用,大小为3,4,5的过滤窗口(h);0.5的dropout率;3的l2约束;50的批量大小 。这些值是通过SST-2验证集上的网格搜索选择的。
除了提早停止开发集之外,我们不会执行任何特定于数据集的调整。 对于没有标准验证集的数据集,我们随机选择10%的训练集数据作为验证集。 使用Adadelta更新规则,通过随机梯度下降进行混合小批量训练。
预训练词向量
使用无监督神经语言模型获得的词向量进行初始化是一种普遍的方法,可以在缺乏大型监督训练集的情况下提高性能。 我们使用公开可用的word2vec向量,这些矢量已经从Google新闻中获得了1000亿字的训练。 向量具有300维的维度,并且使用连续的词袋结构进行训练。在预训练词语集中不存在的词语是随机初始化的。
模型变体
我们试验了该模型的几个变体。
- CNN-rand:我们的基线模型,所有单词都是随机初始化的,然后在训练过程中进行修改。
- CNN-static:来自word2vec的具有预先训练好的向量的模型。 所有单词 - 包括随机初始化的未知单词 - 保持静态,只有模型的其他参数被学习。
- CNN非静态:与上面相同,但预先训练好的向量针对每项任务进行了微调。
- CNN多通道:一个有两组词向量的模型。 每组向量被视为一个“通道”,每个滤波器都应用于两个通道,但梯度仅通过其中一个通道向后传播。 因此,该模型能够微调一组向量,同时保持其他静态。 两个通道都使用word2vec进行初始化。
为了解决上述变化与其他随机因素的影响,我们删除了其他随机性来源 - CV折叠分配,未知单词向量的初始化,CNN参数的初始化 - 通过使它们保持均匀 在每个数据集内。
结果和讨论
表2列出了我们的模型与其他方法的结果。

表2:我们的CNN模型与其他方法的结果。 RAE:具有来自维基百科的预先训练的单词向量的递归自动编码器(Socher等人,2011)。 MV-RNN:具有解析树的矩阵向量递归神经网络(Socher等,2012)。 RNTN:递归神经张量网络,具有基于张量的特征函数和解析树(Socher等,2013)。 DCNN:具有k-max池的动态卷积神经网络(Kalchbrenner等,2014)。段落-Vec:在段落向量之上的逻辑回归(Le和Mikolov,2014)。 CCAE:组合类别自动编码器与组合类别语法运算符(Hermann和Blunsom,2013)。 Sent-Parser:情感分析特定的解析器(Dong et al。,2014)。 NBSVM,MNB:Naive Bayes支持向量机和Multinomial朴素贝叶斯,来自Wang和Manning(2012)的单边结构。 G-Dropout,F-Dropout:来自Wang和Manning的高斯Dropout和快速Dropout(2013)。 Tree-CRF:带有条件随机场的依赖树(Nakagawa等,2010)。 CRF-PR:带后验正则化的条件随机场(Yang and Cardie,2014)。 SVMS:来自Silva等人的具有单双卦,wh词,头词,POS,解析器,上位词和60个手编码规则的SVM作为特征。 (2011年)。
我们的所有随机初始化单词(CNN-rand)的基线模型不能很好地表现出来。虽然我们期望通过使用预先训练的向量来获得性能收益,但我们对收益的巨大程度感到惊讶。即使是一个带有静态向量(CNN静态)的简单模型,其表现也非常好,可以针对更复杂的深度学习模型提供有竞争力的结果,这些模型使用复杂的池化方案或需要事先计算分析树。这些结果表明,预训练好的向量是好的,“通用”的特征提取器,可以跨数据集使用。为每个任务微调预先训练好的向量,可以进一步改进(CNN-非静态)。
多通道与单通道模型
我们最初希望多通道架构能够防止过拟合(通过确保学习矢量不会偏离原始值太远),因此比单通道模型效果更好,特别是在较小的数据集上。 结果则不然,所以需要进一步规范微调过程的工作。 例如,不为非静态部分使用附加信道,而是可以维护单个信道,但是使用在训练期间允许修改的额外维度。
静态与非静态表示
与单通道非静态模型一样,多通道模型能够微调非静态通道,使其更加专用于手头任务。 例如,’good’在word2vec中与’bad’类似,大概是因为它们(几乎)在语法上是等价的。 但对于在SST-2数据集中进行微调的非静态通道中的向量,情况不再如此(表3)。
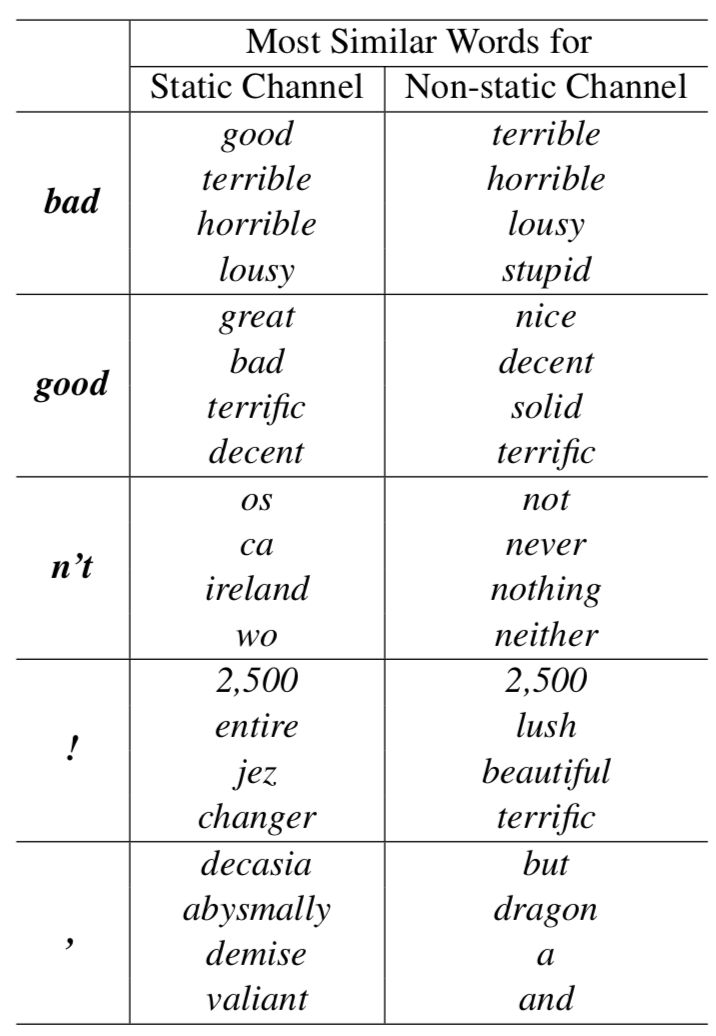
表3:训练后SST-2数据集多通道模型中静态通道中向量(左)和非静态通道(右侧)中的前四个相邻词 - 基于余弦相似度的向量。
同样地,“good”可以说更接近“nice”,而不是“great”,而这确实反映在学习的媒介中。
对于不在预先训练好的向量集中的(随机初始化的)单词,微调允许它们学习更有意义的表示法:网络得知感叹号与情感表达相关联,并且逗号是句子连接相关联(表3)。
进一步观察
我们报告一些进一步的实验和观察:
- Kalchbrenner等人 (2014)报告的CNN结果与我们的单通道模型基本相同,结果更差。 例如,具有随机初始化单词的Max-TDNN(时延神经网络)在SST-1数据集上获得37.4%,而我们的模型为45.0%。 我们将这种差异归因于具有更多容量的CNN(多个滤波器宽度和特征映射)。
- Dropout证明是一个很好的正规化,使用大于必要的网络并让Dropout正规化它是可行的。 Dropout增加了2%-4%的相对表现。
- 当随机初始化不在word2vec中的单词时,我们通过从 U[−a,a] U [ − a , a ] 中抽取每个维度来获得轻微的改进,其中a被选择为使得随机初始化的向量具有与预先训练的向量相同的方差。 如果采用更复杂的方法来反映初始化过程中预先训练好的向量的分布情况,可以进一步改进,这将是有趣的。
- 我们简单地尝试了另一套由Collobert et al.on维基百科训练的公开可用的单词向量,并发现word2vec提供了非常优越的性能。 目前还不清楚这是由于Mikolov等人的架构还是千亿字的Google新闻数据集。
- Adadelta带来了类似Adagrad的结果,但需要较少的时期。
总结
在目前的工作中,我们描述了一系列基于word2vec构建的卷积神经网络的实验。 尽管对超参数进行了少量调整,但具有一层卷积的简单CNN表现非常出色。 我们的结果增加了已有的证据,即未监督的词向量预训练是NLP深度学习的重要组成部分。
TextCnn 调参
参考论文:《A Sensitivity Analysis of (and Practitioners’ Guide to) Convolutional Neural Networks for Sentence Classification》