MobileNet网络系列论文及模型V1-V2-V3
文章目录
- MobileNet V1
- 结构
- 深度可分离卷积Depthwise Separable Convolution
- 计算参数量
- 网络结构与训练
- 宽度参数Width Multiplier: Thinner更小的模型
- 分辨率因子Resolution Multiplier:减少表示Reduced Representation
- 实验
- MobileNet V2
- 深度分离卷积(Depthwise Separable Convolutions)
- Linear Bottlenecks
- Inverted residuals
- Model Architecture模型结构
- Trade-off hyper parameters超参平衡
- Implementation Notes
- 5.1 Memory efficient inference有效的内存推理
- 结论
- MobileNetV3
- NetAdapt
- h-swish
- 微调
- 后记
- 为何要点赞?
MobileNet V1
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision
Applications 2017.4
基于一种使用深度可分割卷积去建立轻量型网络结构的流线型结构。
引进了两个简单的超参数,这两个超参数在延迟和准确率方面达到了平衡,宽度因子和分辨率因子。
之前的网络要么大模型压缩为小模型;要么训练小模型。我们可以通过超参可调网络大小(有些论文只考虑模型规模,没直接考虑模型速度)
结构
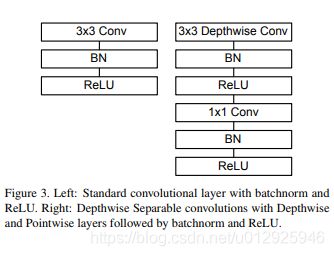
深度可分离卷积Depthwise Separable Convolution
将标准卷积分解为深度卷积和称为点向卷积的1×1卷积pointwise convolution。
标准卷积同时过滤且将输入合并为一组新的输出;深度可分离卷积一个用于过滤,另一层用于合并。
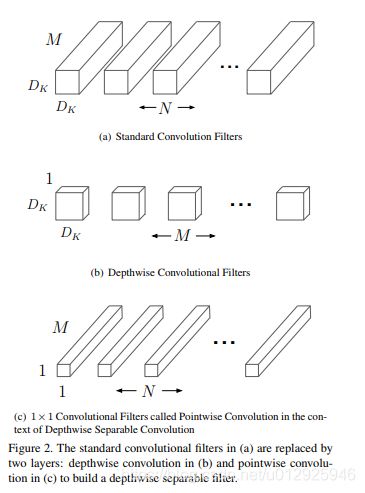
计算参数量
如图2
输入Df x Df x M 的Feature map F时(M是输入channel)
标准卷积产生Df x Ff x N个feature map G(N是本层channel数量)
stride为1,使用padding时,输出图G为
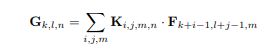
标准卷积cost为
![]()
Dk是滤波器大小如3x3,
深度卷积和点卷积都用了BN层和ReLU层
简单来说,每个输入通道(输入深度)带有一个滤波器的深度卷积可以写成下面:
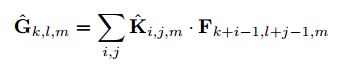
其中Khat表示深度卷积,卷积核为(Dk, Dk, l, M),其中 mth 个卷积核应用在F中第 mth 个通道上,产生 Ghat 上mth个通道输出。
深度卷积计算量为:DkDkMDfDf
但是,它仅过滤输入通道,不会将他们组合以创建新功能。因此,需要额外的一层来计算通过 1*1 卷积的深度卷积输出的线性组合,以便生出这些新特征。
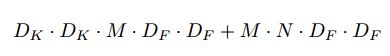
通过将卷积表示为过滤和组合的两步过程,我们减少了以下计算:
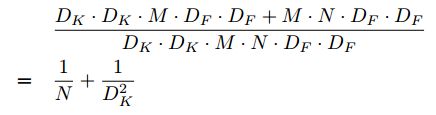
MobileNet使用 3*3 深度可分离卷积,使用的计算量比标准卷积少8到9倍,而准确率仅略有降低,如第四节所述。因式分解只花费了较小的计算。
网络结构与训练
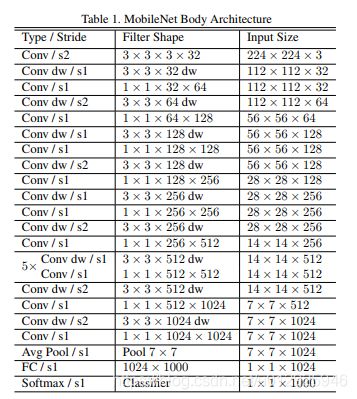
所有层后面都带有一个batchnorm 和ReLU非线性,通过某些层stride=2实现pooling
MobileNet将95%的计算量放在了1x1卷积中(可以通过高度优化的通用矩阵乘法(GEMM)函数来实现),这其中也包含了75%的参数,其他参数集中于全连接层。
使用RMSProp训练,较少的使用了正则化和数据增强,因为小模型不易过拟合。对深度滤波器几乎不进行权重衰减(L2正则化)很重要,因为他们参数太少。
宽度参数Width Multiplier: Thinner更小的模型
引入了一个非常简单的参数 alpha,称为 width乘数。宽度乘数 alpha 的作用是使每一层的网络均匀变薄。
其中α∈(0,1],典型设置为1、0.75、0.5和0.25
输入通道的数量变为 alpha x M,而输出通道的数量N变为 alpha x N。具有宽度乘数 alpha 的深度可分离卷积的计算成本为:
![]()
分辨率因子Resolution Multiplier:减少表示Reduced Representation
分辨率乘数ρ,将其应用于输入图像,然后通过相同的乘数来减少每一层的内部表示.我们通过设置输入分辨率来隐式设置ρ
计算出成本
![]()
其中ρ∈(0,1]通常是隐式设置的,因此网络的输入分辨率为224、192、160或128
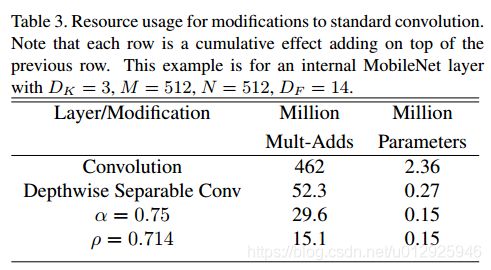
表3显示了将体系结构收缩方法依次应用于该层时该层的参数的计算和数量。
。第一行显示了完整卷积层的Mult-Adds和参数,输入特征图的大小为14×14×512,内核K的大小为3×3×512×512。
实验
MobileNet的深度可分离卷积比完全卷积在ImageNet上只少1%
在类似的计算和参数数量下,使MobileNets变薄比使他们变浅好 3%
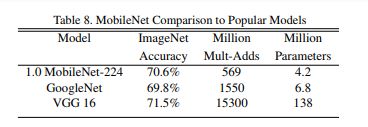
表8将完整的MobileNet与原始的GoogleNet [30]和VGG16 [27]进行了比较。 MobileNet的准确度几乎与VGG16一样,但要小32倍,而计算复杂度却要低27倍。它比GoogleNet更准确,但体积更小,计算量减少了2.5倍以上
减少后的MobileNet(宽度因子α= 0.5和降低后的分辨率160×160)。减少后的MobileNet比AlexNet [19]好4%,而计算量却比AlexNet小45倍,少9.4 倍。在大约相同的大小和22倍以下的计算量下,它也比Squeezenet [12] 好4%。
细粒度分类,大规模地利定位,人脸属性,人脸识别,目标检测等领域都有效
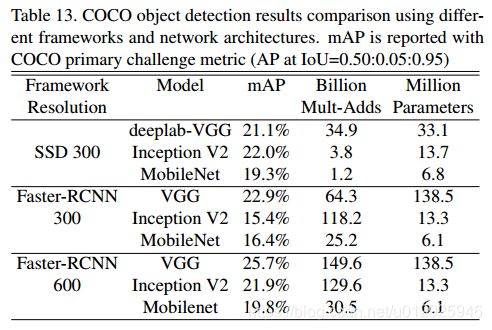
Faster-RCNN模型每个图像评估300个RPN建议框,COCO中去掉了8K个最小的图像。
MobileNet V2
MobileNetV2: Inverted Residuals and Linear Bottlenecks 2018.1
改善效果,退出面向目标检测的SSDLite ,介绍了简化移动语义分割模型DeepLabv3构建新的Mobile DeepLabv3.
基于倒置残差结构(inverted residual structure)
此外,我们发现去除主分支中的非线性变换是有效的,这可以保持模型表现力。
该模块首先将输入的低维压缩表示(low-dimensional compressed representation)扩展到高维,使用轻量级深度卷积做过滤;随后用linear bottleneck将特征投影回低维压缩表示。 这个模块可以使用任何现代框架中。
该模块特别适用于移动设备设计,它在推理过程不实现大的张量,这减少了需要嵌入式硬件设计对主存储器访问的需求。
近几年的网络提高工作大致在几个方向:
1超参调优,网络剪枝方法和连通性学习
2 改变内容捐几块的连通结构,,例如ShuffleNet引入稀疏性等。
3 将遗传算法、强化学习等优化算法引入
深度分离卷积(Depthwise Separable Convolutions)
同V1 略
Linear Bottlenecks
连串的卷积和激活层形成一个兴趣流形(manifold of interest ,这就是我们感兴趣的数据内容)
长期以来我们认为:在神经网络中兴趣流行可以嵌入到低维子空间,
MobileNetv1是通过宽度因子(width factor)在计算量和精度之间取折中。用上面的理论来说,宽度因子控制激活空间的维度,直到兴趣流行横跨整个空间。
- 如果当前激活空间内兴趣流行完整度较高,经过ReLU,可能会让激活空间坍塌,不可避免的会丢失信息。(如下Figure 1的示意图)
- 如果经过ReLU变换输出是非零的,那输入和输出之间是做了一个线性变换的,即将输入空间中的一部分映射到全维输出,换句话来说,ReLU的作用是线性分类器。

使用矩阵 T 将数据嵌入到 n 维空间中,后接ReLU,再使用T−1 将其投影回2D平面。可看到n=15-30时信息丢失较少
总结一下两个性质
- 如果兴趣流行经过ReLU变换后得到非零的结果,这时ReLU对应着是一个线性变换
- 只有当输入流行可包含在输入空间的低维子空间中,ReLU才能完整的保持输入流行的信息。
既然在低维空间中使用ReLU做激活变换会丢失很多信息,论文针对这个问题使用linear bottleneck(即不使用ReLU激活,做了线性变换)的来代替原本的非线性激活变换。
linear bottleneck可以防止非线性破坏太多信息。
从linear bottleneck到深度卷积之间的的维度比称为Expansion factor(扩展系数),该系数控制了整个block的通道数。 linear bottleneck的使用操作的流程演化图如下:
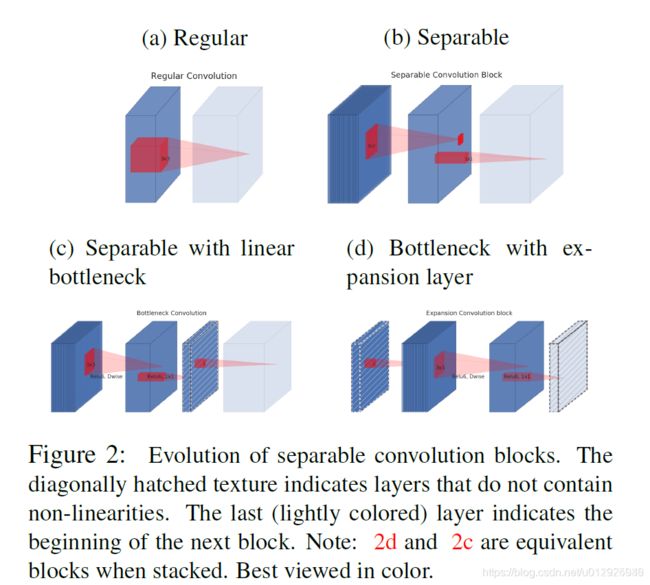
图C和图D 是MobileNetv2的结构(d是c的下一个连接状态),同样是将标准卷积拆分为深度卷积和逐点卷积,在逐点卷积后使用了接1×1 卷积,该卷积使用线性变换,总称为一层低维linear bottleneck,其作用是将输入映射回低维空间
Inverted residuals
由上面的分析,直觉上我们认为linear bottleneck中包含了所有的必要信息,对于Expansion layer(即linear到深度卷积部分)仅是伴随张量非线性变换的部分实现细节,我们可将shortcuts放在linear bottleneck之间连接。示意图如下:
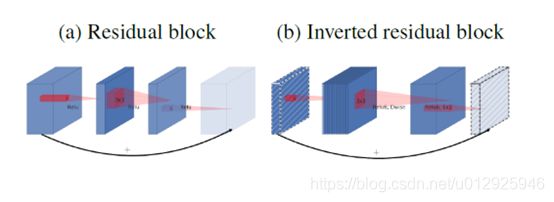
选择这样的结构,可以提升梯度在乘积层之间的传播能力,有着更好的内存使用效率。
下表是bottleneck convolution的基本实现:

1首先是1×1 conv2d变换通道,后接ReLU6激活
2中间是深度卷积,后接ReLU
3最后的1×1 conv2d后面不接ReLU了,而是论文提出的linear bottleneck
膨胀率:输入维度大小和内部维度大小。
linear bottleneck层中使用线性层至关重要,试验发现如果使用非线性层,会下降几个点的精度
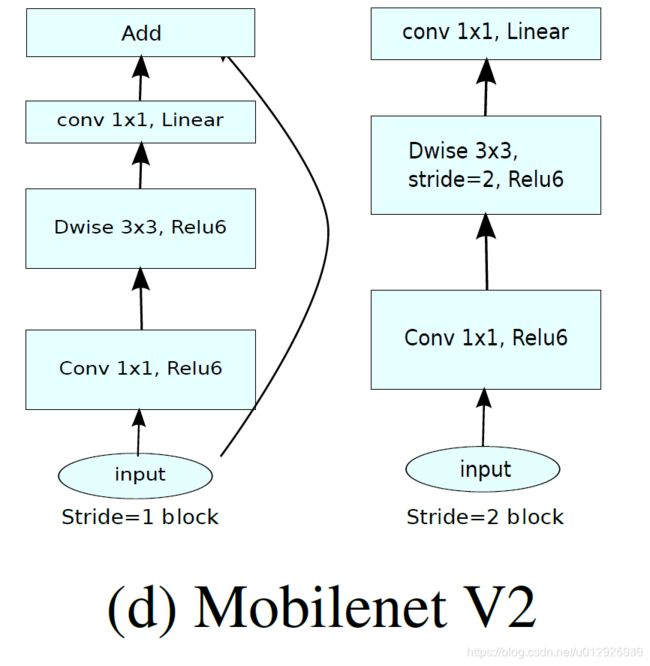
MobileNetV2 两种结构都是中间部分channe较大,因而是倒残差结构,
Model Architecture模型结构
基本单元是bottleneck depth-separable convolution

使用ReLU6(即f(x)=min{max(0,x),6} f(x)=min{max(0,x),6}f(x)=min{max(0,x),6})作为非线性激活函数,这样在低精度计算下具有更强的鲁棒性。
我们所有的实验,选择扩展因子(expansion factor)等于6,例如采用64的通道的输入张量产生128通道的输出,则中间的深度卷积的通道数为6×64=384 6×64=3846×64=384。
试验中发现,nearly identical performance curves, 扩展因子5-10比较合适。小网络用小些的扩展因子,大网络用大些的。
Trade-off hyper parameters超参平衡
控制输入分辨率和width multiplier宽度因子,可以在 accuracy/performance 上平衡。
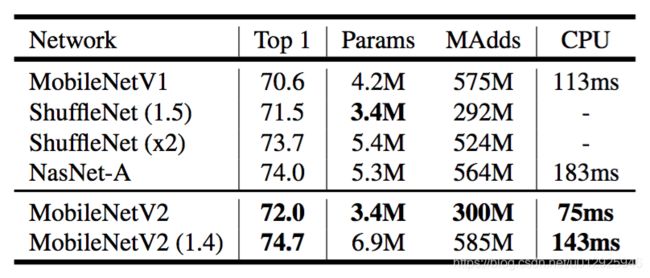
Our primary network (width multiplier 1, 224 × 224)有f 300 million multiply-adds 和 3.4 million parameters.实验了从96-224不同的而输入,从0.35到1.4不同的宽度因子,7 multiply adds to 585M MAdds, while the 模型大小在 1.7M and 6.9M parameters.之间
小于1的宽度因子在非最后一层都使用,来减小模型规模
Implementation Notes
5.1 Memory efficient inference有效的内存推理
该算法基于以下事实:内部张量I可以表示为t张量的连接,每个大小为n/t,则通过累加和,我们只需要将一个大小为n/t的中间块始终保留在内存中。使用n=t,我们最终只需要保留中间表示的单个通道。使我们能够使用这一技巧的两个约束是(a)内部变换(包括非线性和深度)是每个通道的事实,以及(b)连续的非按通道运算符具有显著的输入输出大小比。对于大多数传统的神经网络,这种技巧不会产生显著的改善。
线性瓶颈的重要性。线性瓶颈模型的严格来说比非线性模型要弱一些,因为激活总是可以在线性状态下进行,并对偏差和缩放进行适当的修改。然而,我们在图6a中展示的实验表明,线性瓶颈改善了性能,为非线性破坏低维空间中的信息提供了支持。
ImageNet分类任务
检测任务
SSDLite 也是把卷积部分分成两部分 MNet+SSDlite效果最好
语义分割
DeepLabv3简化,
在MobileNetV2的倒数第二个特征映射的顶部构建DeepLabv3头部比在原始的最后一个特征映射上更高效,因为倒数第二个特征映射包含320个通道而不是1280个通道,这样我们就可以达到类似的性能,但是要比MobileNetV1的通道少2.5倍,
DeepLabv3头部的计算成本很高,移除ASPP模块会显著减少MAdd并且只会稍微降低性能。
结论
理论上:所提出的卷积块具有独特的属性,允许将网络表现力(由扩展层编码)与其容量(由瓶颈输入编码)分开。探索这个是未来研究的重要方向。
MobileNetV3
MobileNetV3通过结合硬件感知网络架构搜索(NAS)和NetAdapt算法对移动电话cpu进行调优,然后通过新的架构改进对其进行改进。比v2又快又好。
V3应用于分割任务时提出了一种新的高效分割解码器Lite reduce Atrous Spatial Pyramid Pooling (LR-ASPP)(即R-ASPP的改进)
结合了自动搜索块内参数+搜索新的网络结构
借鉴SqueezeNet,大量1x1conv的squeeze减少参数,更减少mAdds加法乘法数量,且量化后精度减小比其他模型小。
V3-large借鉴MnasNet网络结构,改进swish为hard-swish,然后用NetAdapt搜.V3-small从头直接搜
NAS:强化学习方法,搜索空间指数增长,因而早期只搜结构,使用相同块构建。我们可以使用不同的块。
1. 平台感知NAS搜结构
2. 用NetAdapt搜每层filters数量
NetAdapt
可以顺序方式微调单层.
三个步骤
- 给proposals,要求给出方案必须是减小延迟方向.
- 基于上一般fine-tune训练T步(比如1000)
- 评价acc,重复三步
其中不用acc评价,而用acc/延迟 的最优.考虑延迟情况. 我们允许减小膨胀层,为保持链接,允许减小bottleneck瓶颈块.
h-swish
与原版激活函数更匹配,由于各种硬件针对ReLU都有优化加速,所以这个激活也有加速,量化后精度变化比其他小。计算量比swish小,比ReLU大,但是精度高。
更深的网络使用H-swish成本更低,(由于激活内存在深层不断减半),因而网络后半段再使用h-swish,前面ReLU
非线性部分借鉴squeeze-excite压缩激活模块, 该模块定位四分之一膨胀通道
微调
搜完网络,头尾部分计算量较大.头部减少一些层,32个变16个(因为发现32个filters有互为镜像的情况);使用不同的非线性减少冗余; 使用h-swish.省3ms
尾部1x1贵,但是有效.但是可以降低前一层投影,滤波的层,减少10ms
其他:
针对检测\分割时,最后一层channel减半,(因为本来针对1000分类设计的)
分割效果比 ESPNetV2好,
后记
看完这些,希望你已经没有想看源码的冲动了。
如果是这样的话,不妨点个赞吧。
为何要点赞?
如果本文解决了你的困惑,不妨点个赞鼓励一下。
不管你信不信,也不管你同不同意,实际上,你的每一次点赞都标志着你自身的进步。而打赏乃是点赞的高级形式
曾经有无数个点赞的机会,但是我都没有好好珍惜,假如时光可以倒流,我一定为他们也为自己点赞。
To do ing 2020.4.8 4.16 4.19V2论文结束
http://noahsnail.com/2018/06/06/2018-06-06-MobileNetV2-%20Inverted%20Residuals%20and%20Linear%20Bottlenecks%E8%AE%BA%E6%96%87%E7%BF%BB%E8%AF%91%E2%80%94%E2%80%94%E4%B8%AD%E6%96%87%E7%89%88/
https://blog.csdn.net/u011974639/article/details/79199588