生成式文本摘要
文本摘要
- 0.Abstract
- 1.任务介绍
- 数据集
- 评估方法
- 测试集
- 2. 词表构建
- 3. Baseline模型
- 基线模型结果
- 4. 解码部分
- 5. 最终模型
- 双层结构
- Multi-Head Attention机制
- Mask机制
- 先验知识
- 最终效果
- 6. 另外一些还没有实现的想法/可能的方向
0.Abstract
本文实现了一个简单的中文文本摘要, 摘要方法使用生成式. 评估方法使用Rouge-N.
项目代码github地址: https://github.com/neesetifa/Summarization
1.任务介绍
文本摘要通常有两种, 它们分别是抽取式摘要(Extractive summarization)和生成式摘要(Abstractive summarization). 压缩式摘要暂不讨论.
抽取式摘要主要从源文档中提取出现成的词/句.
生成式摘要是基于NLG(Natural Language Generation).由模型自己生成句子. 生成式摘要较抽取式摘要具有更高的灵活性, 允许模型有一定概率生成新的词语/短语. 通常基于sequence to sequence结构实现. 此类型是本文实现的摘要生成方式.
数据集
数据集比较工整, 一共50K条数据, 分为摘要(summarization)和原文(text)两部分.
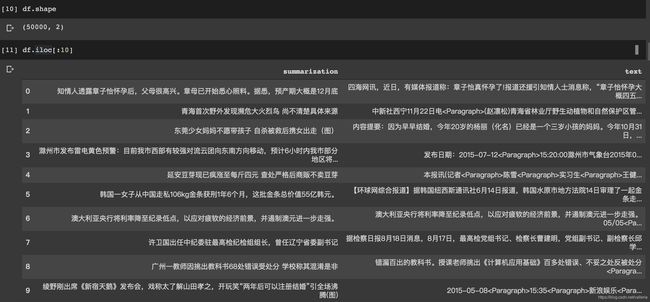
评估方法
本项目使用的评估方法是ROUGE-N
ROUGE-N的最大值是1. 即"参考摘要"里的所有字都在"模型自动生成的摘要"里出现过.
测试集
由于自行构造数据集比较困难, 此项目中直接取了数据集里一小部分作为测试集.
2. 词表构建
词表构建比较简单, 没有使用分词工具, 直接分字.
PS: 可以使用分词工具进行分词. 此处使用分字没有特殊含义.
chars = {}
for summarization,text in df.values:
for w in summarization:
chars[w] = chars.get(w, 0) + 1
for w in text: #
chars[w] = chars.get(w, 0) + 1
词表里额外加入了4个特殊词, 分别是:
4个特殊词放在词表的 0-3这4个index里, 正式词从编号4开始. 整个词表保存在一个json文件里.
json.dump([chars, id2char, char2id], open('vocab.json', 'w'))
3. Baseline模型
Baseline模型使用了sequence to sequence结构+attention机制.
encoder部分用了双向LSTM结构(即BiLSTM), decoder里面用了单向LSTM.
由于单向结构只考虑了上下文中的"上文"信息, 并没有考虑后面的内容. 双向结构同时拥有从后往前的信息, 即考虑了"下文"的信息.
decoder部分没有加入双向是因为显然解码只能从左往右. 如果decoder部分也能做双向还请留言指教.
双向LSTM的结构可以参考下图, hi是LSTM单元. (把LSTM换成最基本的RNN或者GRU, 从结构上来说都是可以的)
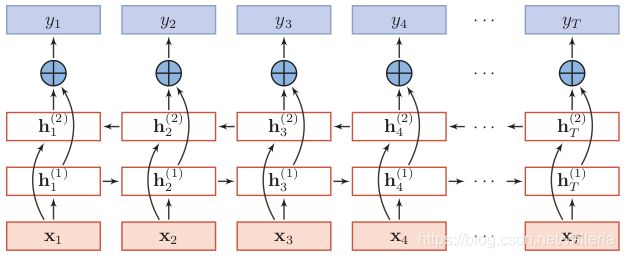
h1是正向结构:
h t ( 1 ) = f ( U 1 h t − 1 ( 1 ) + W 1 x t + b 1 ) h_t^{(1)}=f(U_{1}h_{t-1}^{(1)}+W_{1}x_{t}+b_{1}) ht(1)=f(U1ht−1(1)+W1xt+b1)
h2是逆向结构:
h t ( 2 ) = f ( U 2 h t + 1 ( 2 ) + W 2 x t + b 2 ) h_t^{(2)}=f(U_{2}h_{t+1}^{(2)}+W_{2}x_{t}+b_{2}) ht(2)=f(U2ht+1(2)+W2xt+b2)
最终输出:
h t = c o n c a t ( h t ( 1 ) ; h t ( 2 ) ) h_{t}=concat(h_t^{(1)} ; h_t^{(2)}) ht=concat(ht(1);ht(2))
由于BiLSTM里使用两套参数, 最后的输出是两套的结果进行拼接(concatenate)操作.
下面是实际操作过程中BiLSTM的实现方式. 通常是初始化两个LSTM单元, 然后分别送入原始的x以及逆序的x. 模型结构图可以参考最终模型里的图, 只是没有双层结构.
x_forward = LSTM(embedding_size, return_sequences=True)(x) #把原始数据送入LSTM. return_sequences需要置为True,因为需要每个时间片(time step)的输出, 为attention做准备.
x_backward = reverse_sequence(x) #把原始数据反转过来
x_backward = LSTM(embedding_size, return_sequences=True)(x_backward) #反转的数据送入另一个LSTM中
x_backward = reverse_sequence(x_backward) #把结果再反转
x = concatenate([x_forward, x_backward], 2) #拼接
损失函数(loss function)使用cross entropy.
基线模型结果
在Tesla K80的GPU上训练, 每一个epoch的时间约为60s.
![]()
![]()
基线模型分数:
Rouge-1分数: 0.298
Rouge-2分数: 0.137
Rouge-L分数: 0.633
实际效果:

我随机挑选了一句话, 可以看到摘要部分质量并不是很好, 并且有相当多的重复词语.
4. 解码部分
解码部分采用beam search算法, 我的代码里k值设定为3. 循环停止条件是碰到
算法:
- 在开始运算前, y初始化为
标识符. - 如果是第一次运算, 则直接保存top k个值.
如果不是,则遍历top k * top k种组合找出新的top k. 比如当前有三个候选字 [A,B,C], A,B,C分别送入模型预测, 可以各获得三个结果: A->[A1,A2,A3], B->[B1,B2,B3], C->[C1,C2,C3], 那么一共有 3*3 = 9个组合, 即[A,A1],[A,A2],[A,A3], [B,B1], [B,B2],[B,B3], [C,C1],[C,C2],[C,C3], 从这9个里选取top 3作为下一轮y的输入.
假设分数最高的组合是[A,A3],[C,C1],[C,C3], 那么这个组合就送入下一次循环, 他们又可以各产生3个候选字, [A,A3]->[S1,S2,S3], [C,C1]->[T1,T2,T3],[C,C3]->[R1,R2,R3], 如此往复. - 如果碰到至少有一个y里已经含有
, 则在含有 里的y里选择分数最高的一个返回. 如果没有一个句子有 , 并且循环次数已经达到了max_len, 则返回分数最高的一个句子.
def beam_search(s, model, topk=3, max_len=64):
x = str2id(s) # 别忘了输入的句子是字符, 要转为id
x = x * topk # 复制三份, 因为我们的top k是3
y = [[2]] # 我设置的的index是2, 所以y初始化为2
y = y * topk # 同样复制三份
y_, score = [],[]
#两种停止情况, 碰到或者最长maxlen
for i in range(maxlen):
probability = model.predict([x, y])
arg_topk = probability.argsort()[:, -topk:]
if i == 0:
# 如果是第一次, 直接保存结果
y_.append(top_k_index)
score.append(top_k_score)
else:
# 不然, 两个for遍历 top k * top k 次
for j in range(topk):
for k in range(topk):
y_.append(top_k_index)
score.append(top_k_score)
... # 此时y_里应该有9个候选值,从中选出新的top k个
y = y_ # y赋予新值
if found <end>:
... # 如果发现y里有, 则在含有\里的y里选择分数最高的一个返回
return id2str(y_)
# 如果maxlen后依旧没有,直接返回
return id2str(y_)
5. 最终模型
最终模型结构:
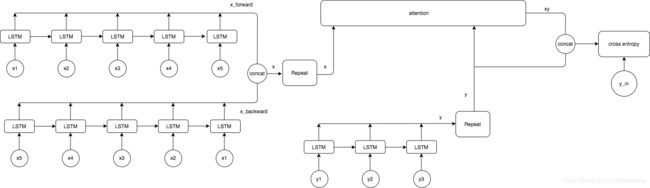
先谈一下这个最终模型结构. 这个结构算是半原创, 结合了一部分ELMo和Transformer的思想. 结构上并没有太多道理, 只是尝试把所学的知识结合在了一起.
准确来说Encoder部分是来源于我之前对ELMo结构细节上的错误理解, 结果弄巧成拙, 并且实际效果居然还不错.
在最终模型里,一共加入了以下几个优化点:
- 使用了双层结构
- 加入了Multi-Head Attention机制
- 加入了Mask机制
- 加入了先验知识
双层结构
encoder部分和decoder部分都加入双层结构, 即encoder部分为两层的BiLSTM, decoder部分为两层LSTM.
双层结构即为图里repeat部分, 第一层输出之后的向量会再经过同样的一个结构.
多层的好处很简单, 将模型特征进行多次重组, 可以学习到更高级的特征, 增强模型表现力.
Multi-Head Attention机制
这个做法来源于Transformer里的Multi-Head Self-Attention机制. 对于这个机制的详解可以参考我的另一篇博客–> 传送门
首先,加入attention的好处是把decoder的每个部分都和encoder的每个部分联系了起来, 使decoder每个部分都能获得encoder所有部分的信息.
其次, Multi-Head机制使模型能够学到不同的表达和关注的点. 增强了模型的表示能力. Multi-Head做法其实就相当于把输入的Q,K,V再过多个线性层.
在我的模型里, x的最终输出和y的最终输出会做一个Multi-Head Attention操作. 之所以不是self-attention是因为本模型里是y查询x的键值(即Q=y, K和V=x). 我这一步就相当于Transformer的Decoder结构里的第二个Multi-head Attention.
class Attention(Layer):
"""multi-head+attention 多头注意力机制
下面代码为伪代码, 不能运行
"""
def __init__(self,num_of_heads,size_per_head):
self.num_of_heads = num_of_heads #头的数量
self.size_per_head = size_per_head #每个头的size
def build(self):
self.wq = Dense() #定义 wq,wk,wv 三个线性层/线性矩阵
self.wk = Dense()
self.wv = Dense()
def call(self, inputs):
q, k, v= inputs # 下图三个输入都为x,因为是self-attention. 在本模型里, q是y, k和v是x
q = self.wq(q) # Multi-head机制, 输入经过线性层
k = self.wk(k)
v = self.wv(v)
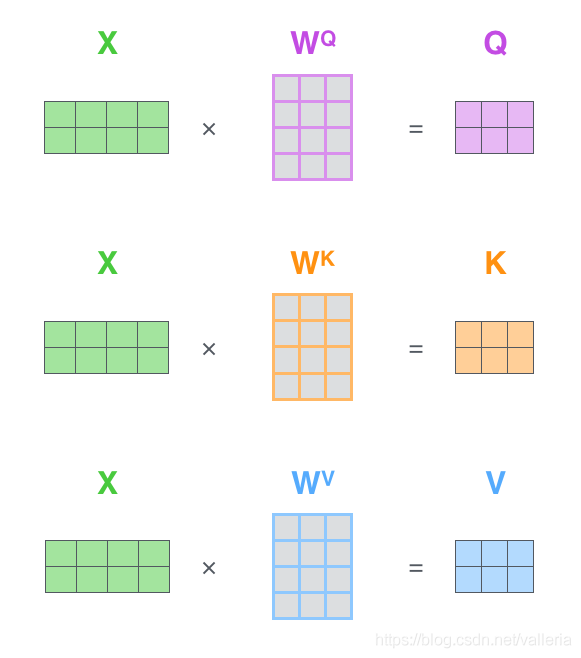
a = batch_dot(q, k) # Q和K先做点乘
a = a / self.size_per_head ** 0.5 # 缩放,即根号dk
a = softmax(a) # 做softmax
z = batch_dot(a, v) # 再和V做点乘
return z
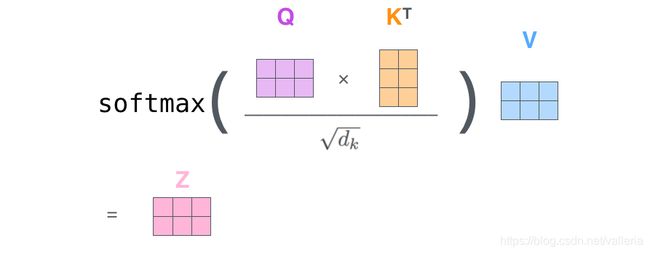
Mask机制
Mask机制是什么?
简单讲, 如果句子是这样[2,4,3,6,0,0,0], 后面三个位置没有值, 那么这个句子的mask就是[1,1,1,1,0,0,0]. 即有值的地方设置为1,没值的设置为0.
为什么要Mask?
由于实际运算都是矩阵相乘. 我们做这类模型, 都会设置一个max_len, 太短的句子补足max_len的部分, 即padding. padding部分初始化的时候都是0, 但实际经过计算后, 它们或多或少都会产生值. 然而我们并不希望 padding部分也有值, 于是加入Mask机制. 每次点乘运算过后都要过一次mask. 让没有值得地方始终保持0.
mask机制分成两种:
1.普通状态下把padding部分设置成0.
2.需要经过softmax时设置成-inf. 因为如果直接把0送入softmax,这一部分在经过softmax计算后,也会享有一部分权重,然而我们不想0值的部分拥有权重,所以设置成-inf,这样softmax在计算时他们的权重都会变成0.
Mask机制主要在上节的Attention里应用.
def mask(x, mask, mode='mul'):
if mode == 'mul': #这里x在做点乘操作,把不应该有值的位置变成0
return x * mask
else: #这里把0的位置设置成一个非常大的负数
return x - (1 - mask) * 1e10
先验知识
工业级落地场景中通常都会加入很多规则与先验.
先验知识的好处: 让模型有目的的往某些地方偏. 比如白发,老年斑. 先验知识是老人. 让模型更倾向于判断是老人.
而在文本摘要里, 摘要的词通常都会在原文中出现过. 所以这里加入的先验知识就是文章中已经出现过的词, 把他们作为最后分类时的一个先验知识. 使得模型倾向于选择文章中已经出现过的词.
做法就是在x输入时, 统计每句句子里, 某个字是否出现过. 出现过标注1, 没有出现过标注0. 该向量的长度应为单词表的长度. 最后和attention部分的输出做平均. 然后再送入cross entropy.
def get_prior(x)
...
return x_prior
x_prior = get_prior(x) # 获得先验知识
xy = Attention()([y, x, x]) # 这是attention这步
xy = concate(xy, y) # 图里最后一部分的concat
xy = (xy + x_prior) / 2 # 将这个结果和先验知识做平均
cross_entropy = crossentropy(y_in, xy)
最终效果
在Tesla K80的GPU上训练, 每一个epoch的时间约为231s.
![]()
![]()
最终模型分数:
Rouge-1分数: 0.309
Rouge-2分数: 0.219
Rouge-L分数: 0.523
实例效果:

可以看到, Rouge-1分数和基线模型比起来有所提升, Rouge-2分数相差较大, 而Rouge-L分数则比基线模型低了很多.
我认为主要原因就是训练目标(即loss function)和评测指标并不相关. 模型在减少loss时并不会增加Rouge分数. 这也是目前生成式任务(包括机器翻译)的一些问题: 训练目的和评测不一致.
其次, 由于Rouge-1是一个字一个字比对, 并没有考虑顺序. 而在Rouge-2里组成了词之后, 会附带一些顺序信息, 能够看出baseline模型生成的句子里一些不通顺的问题.
Rouge-L比基线模型低这么多的原因我目前尚未分析出原因, 可能只是当前模型下的巧合. 在训练时只是保证了loss最低, 实际训练时Rouge分数上下浮动非常大.
但是可以看到实际效果中, 句子质量比起基线模型已经有了显著提升.
6. 另外一些还没有实现的想法/可能的方向
1.对模型结构进行调整, encoder部分舍弃sequence to sequence结构, 直接使用self-attention机制. 由于self-attention可以并行计算, 理论上可以提高训练速度. 当然也需要加上positional encoding. 这个做法其实就是一个超级简化版的Transformer的encoder部分的结构.
2.至于生成句子里有单词不断重复的问题, 虽然在最终模型里这个问题发生的现象有减少,但只是由于模型变复杂了, 文中提出的几个优化点并没有实际解决这个问题.
这篇论文
我的模型采用了Multi-head attention, x的所有hidden layer的输出和y的所有hidden layer的输出过attention. 论文里的基线模型部分采用如下机制:
我们知道在生成句子时,decoder部分是从左往右一个个词生成的,对于每个时间片t(或者说每一步t) , 论文里的decoder的hidden state进行了如下计算
e i t = v T t a n h ( W h h i + W s s t + b a t t n ) e_{i}^{t}=v^{T} tanh(W_{h}h_{i}+W_{s}s_{t}+b_{attn}) eit=vTtanh(Whhi+Wsst+battn)
其中v, Wh, Ws, battn 都是训练参数, 没什么特别. st是当前时刻decoder输出的hidden state, hi则是encoder部分每次输出的hidden state,即 [h1, h2, h3, …]其实就是我上面基线模型代码里的这个x.
x = concatenate([x_forward, x_backward], 2)
然后再过softmax层输出每个单词的概率.
a t = s o f t m a x ( e t ) a^{t}=softmax(e^{t}) at=softmax(et)
论文的优化点是在此基础上的. 作者加入了一个覆盖机制(Coverage mechanism). 具体实现如下:
设定一个新的覆盖向量 ct. ct怎么获得呢? 公式如下:
c t = ∑ i = 0 t − 1 a i c^{t}= \sum_{i=0}^{t-1} a^{i} ct=i=0∑t−1ai
说白了就是: 每个ct是前面(t-1)个at的和. 于是et的计算变成如下:
e i t = v T t a n h ( W h h i + W s s t + b a t t n + W c c i t ) e_{i}^{t}=v^{T} tanh(W_{h}h_{i}+W_{s}s_{t}+b_{attn}+W_{c}c^{t}_{i}) eit=vTtanh(Whhi+Wsst+battn+Wccit)
Wc和其他一样, 都是训练参数. 这么做其实就等于加了一个先验知识, 即当前的attention的分布结果都受前一次attention结果的影响. 或者说, 前一次attention的结果都会告知当前attention:“上一步的单词概率分布是长这样的, 这步计算时你尽量避免产生相同的分布, aka, 避免产生重复单词”
当然我们需要在损失函数后面加入一个惩罚项:
c o v l o s s t = λ ∑ i m i n ( a i t , c i t ) covloss_{t}= \lambda \sum_{i} min(a^{t}_{i}, c^{t}_{i}) covlosst=λi∑min(ait,cit)
这样在训练时, 模型可以知道我每次产生了相同的at时是会有惩罚的.
把它加入原有loss function里, 就变成了:
l o s s n e w = c r o s s _ e n t r o p y + λ ∑ i m i n ( a i t , c i t ) loss_{new}=cross\_entropy+\lambda \sum_{i} min(a^{t}_{i}, c^{t}_{i}) lossnew=cross_entropy+λi∑min(ait,cit)
=======
目前由于这个结构和我的multi-head attention结构稍有冲突, 暂时没有很好地想好该怎么将两者结合. 未来将持续进行尝试.