最近在看一本关于网络协议的书《图解HTTP》
当我们在浏览器的地址栏输入 http://www.pwstrick.com ,然后回车,回车这一瞬间到看到页面到底发生了什么呢?
1. 域名解析
2. 建立TCP连接
3. 发起HTTP请求
4. 服务器响应HTTP请求
5. 浏览器渲染页面
自己原先不是很了解,通过读了这本书后了解了些内幕。
接下来将使用工具Chrome、Fiddler、Wireshark。曾经写过一篇Fiddler的教程《移动开发中Fiddler的那些事儿》。
一、基础概念
1)TCP/IP是互联网相关的各类协议族的总称
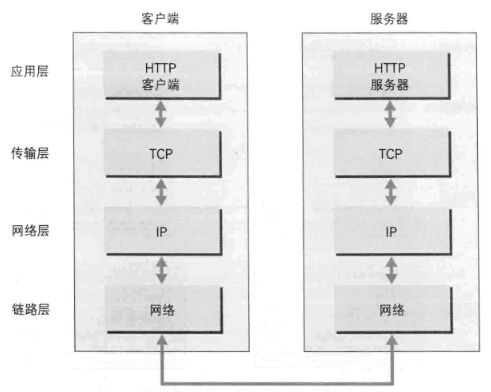
2)TCP/IP分为4层:应用层、传输层、网络层、链路层。
发送端从应用层网下走,接收端从链路层网上走。
IP(Internet Protocol):网际协议位于网络层,IP地址可以和MAC地址配对。
ARP(Address Resolution Protocol):ARP是一种用以解析地址的协议,根据通信方的IP地址反查出对应的MAC地址。
Routing:路由选择,有点像快递公司的送货过程。
TCP(Transmission Control Protocol):传输控制协议,提供可靠的字节流传输,将大数据分割成报文段(segment),TCP协议能够确认数据最终是否送达到对方。
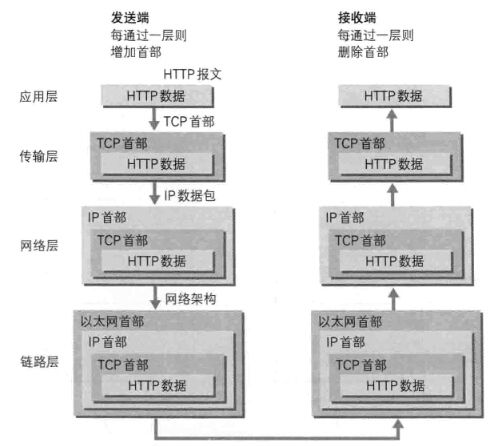
3)数据信息包装
4)域名解析DNS服务
DNS(Domain Name System)位于应用层,提供域名和IP地址之间的解析服务。
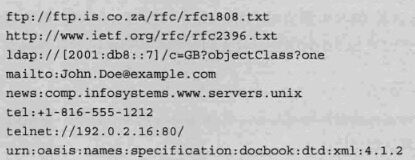
5)URI和URL
URI(Uniform Resource Identifier):统一资源标识符。
URL(Uniform Resoure Locator):统一资源定位符,通俗的说法是网址。
URI表示某一互联网资源,而URL表示资源地点,所以URL是URI的子集,下面是几个URI资源。
6)RFC
RFC(Request For Comments):征求修正意见书,RFC是互联网的设计文档。
要是不按照RFC标准执行,就有可能导致无法通信的状况。
7)HTTP
HTTP是无状态协议,协议对于发送过的请求或响应都不做持久化处理。
HTTP/1.1为了实现保持状态的功能,引入了Cookie。
二、域名解析
在《What really happens when you navigate to a URL》中曾提到DNS会先在缓存中查找记录。
浏览器缓存、系统缓存、路由器缓存、ISP DNS 缓存、递归搜索。
![]()
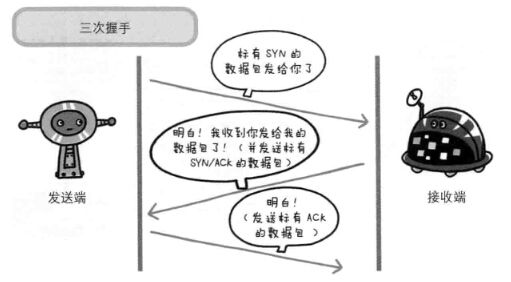
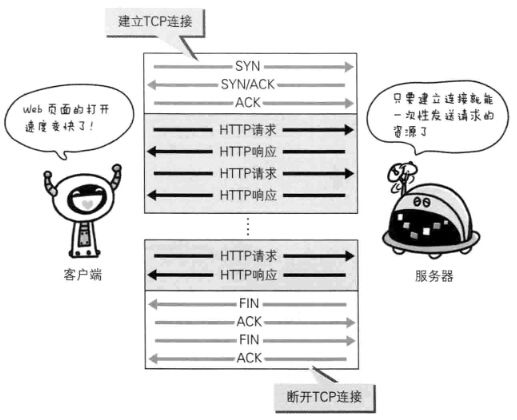
三、建立TCP连接
![]()
1)发送端发送一个带SYN标志的数据包给对方
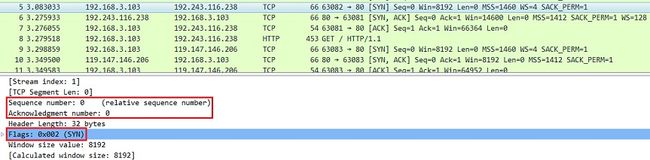
Sequence Number:序号;
Acknowledgment Number:确认号。
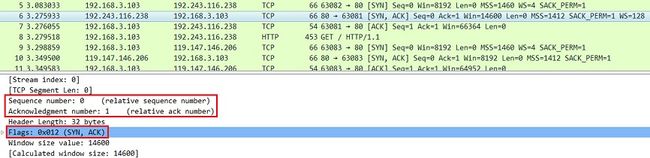
2)接收端回传一个带有SYN和ACK标志的数据包以示传达确认信息
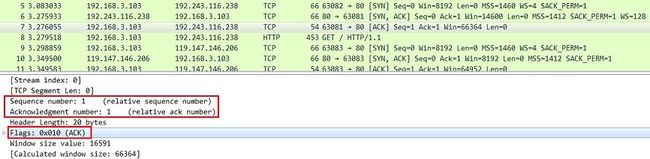
3)发送端再回传一个带ACK标志的数据包,代表“握手结束”
四、发起HTTP请求
HTTP(Hyper Text Transfer Protocol),超文本传输协议,由请求和响应构成。
在书本的第3章介绍了HTTP信息。
1)请求报文
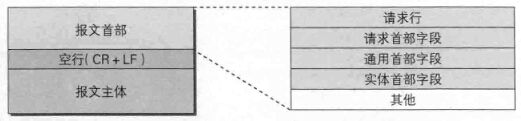
报文首部内容如下:
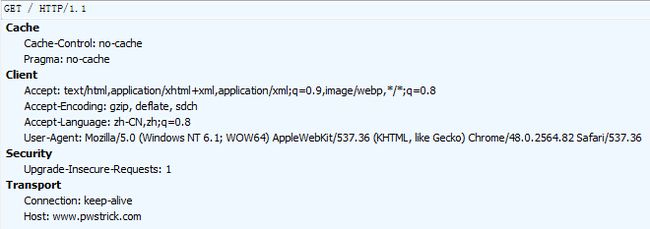
在书本的第6章中有详细的HTTP首部说明。
“Connection:keep-alive”:持久连接,只要任意一端没有明确提出断开,就保持TCP连接状态。
2)响应报文
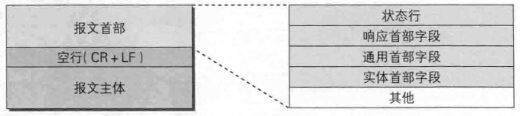
报文首部内容如下:
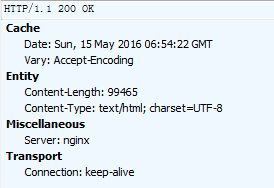
上图中的200是HTTP状态码,在书中的第4章详细介绍了状态码。
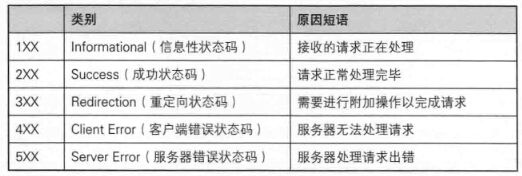
五、服务器响应HTTP请求
从上面的响应报文中可以看到服务器软件是Nginx,并且请求的是一张PHP页面。
以前曾经写过一篇《PHP代码的执行》,不过软件用的是Apache。这里就假设是Apache+PHP(fastcgi)架构提供服务。
1)Apache
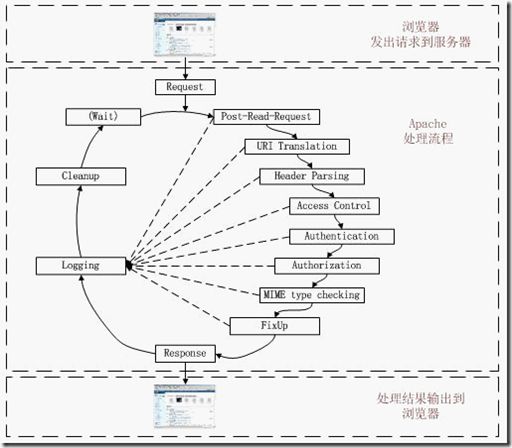
Apache对HTTP的请求可以分为连接、处理和断开连接3个大的阶段。同时也可以分为上图所示的11个小的阶段。
2)FastCGI
FastCGI可以让一个客户端,从网页浏览器向执行在Web服务器上的程序请求数据。
比如现在请求的是“index.php”,根据配置文件,Apache知道这个不是静态文 件,需要去找PHP解析器来处理,那么它会把这个请求简单处理后交给PHP解析器。
Apache会传url、查询字符串、POST数据、HTTP header等,而CGI就是规定要传哪些数据、以什么样的格式传递给后方处理这个请求的协议。
3)PHP脚本执行
PHP程序完成基本的准备工作后启动PHP及Zend引擎, 加载注册的扩展模块。
初始化完成后读取脚本文件,Zend引擎对脚本文件进行词法分析,语法分析。
编译成opcode执行。
服务器最终将生成的HTML代码返回给浏览器。
六、浏览器渲染页面
从Chrome的网络工具中可以看到,浏览器会先下载HTML代码,再去下载CSS或JS外部资源。
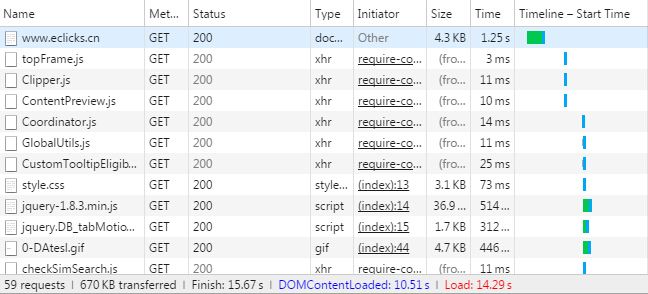
网上的很多资料显示,浏览器是边下载HTML,边解析HTML的。
有篇文章叫《How browsers work》介绍浏览器内部工作原理的,文中提到了浏览器的渲染引擎——Webkit。
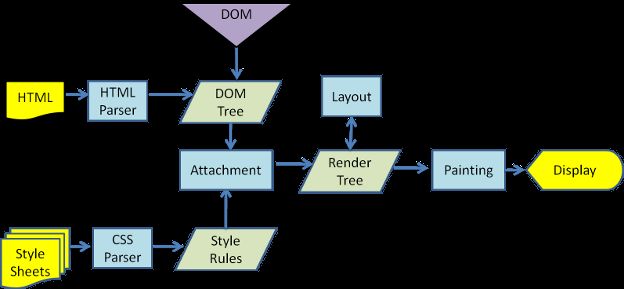
渲染引擎首先通过网络获得所请求文档的内容,通常以8K分块的方式完成,下面是渲染引擎基本流程:
解析HTML以构建DOM树 -> 构建Render(渲染)树 -> 布局Render树 -> 绘制Render树

下图是Webkit的主流程:
参考资料:
Wireshark基本用法
当你输入一个网址,实际会发生什么?
一次完整的HTTP事务是怎样一个过程
从输入url到页面加载完的过程中都发生了什么事情
当在浏览器地址栏输入一个URL后回车,将会发生的事情?