ElasticSearch笔记01
安装部署过程网上有很多教程,在此不累赘
目录
- 1. 什么是ES?
- 2. 基本概念
- 2.1 Index
- 2.2 Type
- 2.3 Document
- 2.4 Filed
- 2.5 倒排索引
- 3. RestFul操作风格(通过kibana测试)
- 3.1 POST方式创建Document
- 3.2 PUT创建Document
- 3.3 PUT更新文档
- 3.4 PUT创建索引
- 3.5 POST更新文档
- 3.5 DELETE删除文档
- 3.6 GET获取文档
- 3.7 POST查询所有数据
- 4. ES查询
- 4.1 普通查询
- 4.1.1 查询类型
- 4.2 排序
- 4.3 分页
- 4.4 条件查询
- 4.4.1 与操作
- 4.4.2 或操作
- 4.4.3 非操作
- 4.4.4 大于、小于、等于...
- 4.5 term精确匹配
- 4.6 高亮显示
1. 什么是ES?
Elasticsearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎。Elasticsearch用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。官方客户端在Java、.NET(C#)、PHP、Python、Apache Groovy、Ruby和许多其他语言中都是可用的。根据DB-Engines的排名显示,Elasticsearch是最受欢迎的企业搜索引擎,其次是Apache Solr,也是基于Lucene。(百度百科)
2. 基本概念
2.1 Index
ES的顶层的单位,相当于关系型数据库中的Database
2.2 Type
注:在7.X版本中将Type类型进行了移除,不再推荐使用
在ES中,可以针对Document进行分组,而这个分组讲的就是Type,它是虚拟的逻辑分组,用来过滤 Document,类似关系型数据库中的数据表(仅仅是类似,性质不同,后边有讲到)。
不同的 Type 应该有相似的结构(Schema),性质完全不同的数据(比如 products 和 logs)应该存成两个 Index,而不是一个 Index 里面的两个 Type(虽然可以做到)。
ES是基于Lucene开发的搜索引擎,最终在Lucene中不同Type下的Filed的处理是一样的,即不同Type下相同名称的Filed是同一个的。不同Type中的相同字段名称就会在处理中出现冲突的情况,导致Lucene处理效率下降。但是在很多情况下,不同Type下难免会出现不同映射关系的Filed,在ES是不允许出现的,
2.3 Document
Index(索引)中的单条数据称为Document(文档),相当于关系型数据库中表的单条数据,Document使用JSON进行表示。
2.4 Filed
Document(文档)中的字段,每个Document包含了很多个Filed(字段),每个字段都有对应的值,多个字段组合成为了Document,相当于关系型数据库表的字段。
2.5 倒排索引
在平常的使用中最多的可能是正向索引,即通过key去查找value,而倒排索引则是通过value查找key。假如有以下的数据。
| ID | 名称 | 描述 |
|---|---|---|
| 1 | 华为 | 硬件、强国、通信、手机、中国 |
| 2 | 三星 | 硬件,手机、通信、韩国 |
| 3 | 苹果 | 手机、美国 |
正向索引就是我们通过ID为1的key我们可查到名称为华为,描述为硬件、强国、通信、手机、中国的一条信息。
倒排索引则另外维护了一个表,如下
| 描述 | ID |
|---|---|
| 硬件 | 1、2 |
| 强国 | 1 |
| 通信 | 1、2 |
| 手机 | 1、2、3 |
| 中国 | 1 |
| 韩国 | 2 |
| 美国 | 3 |
当我们需要查询中国这个关键字的时候,就会锁定到上表的一条记录上,发现只有ID为1的数据存在中国这个关键字,我们只需要通过ID = 1进行查询就可以了,避免了直接通过模糊匹配在表1描述属性进行全文遍历,大大提升了索引的效率。
3. RestFul操作风格(通过kibana测试)
个人感觉ES的restful操作风格不是很规范[狗头]
| method | 地址 | 描述 |
|---|---|---|
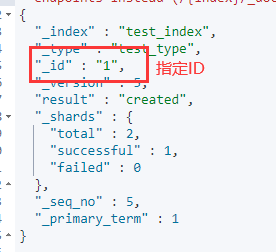
| PUT | host:9200/索引名称/类型名称/文档ID | 创建文档(指定文档ID) |
| POST | host:9200/索引名称/类型名称/ | 创建文档(随机文档ID) |
| POST | host:9200/索引名称/类型名称/文档ID/_update | 修改文档 |
| DELETE | host:9200/索引名称/类型名称/文档ID/ | 删除文档 |
| GET | host:9200/索引名称/类型名称/文档ID/ | 查找文档(指定ID) |
| POST | host:9200/索引名称/类型名称/_search/ | 查找所有文档 |
3.1 POST方式创建Document
POST /test_index_2/_doc/
{
"name": "zhangsan",
"age": 18
}
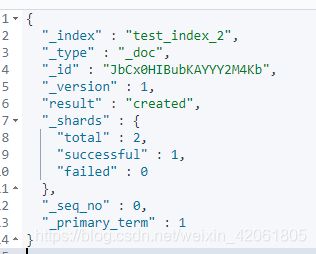

3.2 PUT创建Document
PUT /test_index/test_type/1
{
"name": "zhangsan",
"age": 11
}
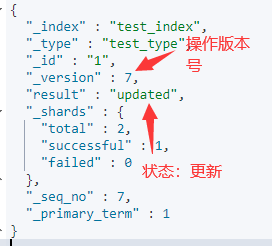
3.3 PUT更新文档
注意:更新时必须指定所有字段,否则其他非更新字段也会被更新
PUT /test_index/test_type/1
{
"name": "zhangsan",
"age": 111
}
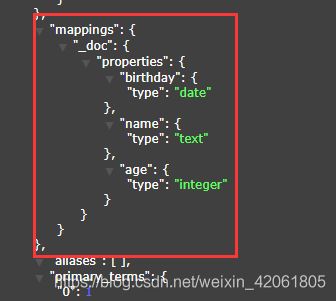
3.4 PUT创建索引
注意:不插入数据,只建立索引结构,如指定字段类型(mapping)
PUT /test_index_3
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"age": {
"type": "integer"
},
"birthday": {
"type": "date"
}
}
}
}
3.5 POST更新文档
注意:此方式不需要指定所有字段,只需要指定修改的字段即可,推荐使用
POST /test_index/test_type/1/_update
{
"doc": {
"name": "zhangsan_update"
}
}
3.5 DELETE删除文档
DELETE /test_index/test_type/1
3.6 GET获取文档
GET /test_index/test_type/1
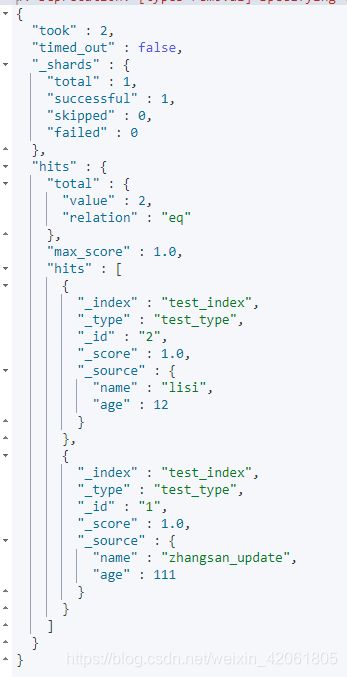
3.7 POST查询所有数据
POST /test_index/test_type/_search
4. ES查询
4.1 普通查询
GET /student/_search
{
"query": {
"match": {
"name": "王子"
}
}
}
4.1.1 查询类型
- match:根据规则匹配,查询包含分词器分词后关键字的所有内容
例如:现在存在两个数据,”王五“ 和 ”王五麻子“(ES目前没安装中文分词器,但是不影响结果)
上边的这两数据默认分词器分为”王“, ”五“, ”麻“, ”子“
通过match匹配内容王子,则会把王五, 王五麻子都会查出来,因为分词器将王子分为了王,子两个关键字,而这两个数据都进行了匹配,所以将结果查询了出来 - match_all:查询所有
GET /student/_search { "query": { "match_all": {} } } - match_phrase:根据规则匹配,同时判断关键词索引是否连续
还是1的数据,我们继续查询,只不过采用match_phrase进行查询,那么查询出来的则是空的,因为没有进行全部的匹配并且索引不连续,如数据王五麻子匹配到了王,子,但是王和子的索引不是连续的,所以查询为空。GET /student/_search { "query": { "match_phrase": { "name": "王子" } } } - match_phrase_prefix:用到再补充
- multi_match:多字段查询
GET /student/_search { "query": { "multi_match": { "query": "王", "fields": ["name"] } } }
4.2 排序
GET /student/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"age": {
"order": "desc"
}
}
]
}
4.3 分页
GET /student/_search
{
"query": {
"match_all": {}
},
"from": 0,
"size": 2
}
4.4 条件查询
4.4.1 与操作
GET /student/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"age": 15
}
},
{
"match": {
"name": "张三"
}
}
]
}
}
}
4.4.2 或操作
GET /student/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"age": 15
}
},
{
"match": {
"name": "李四"
}
}
]
}
}
}
4.4.3 非操作
GET /student/_search
{
"query": {
"bool": {
"must_not": [
{
"match": {
"age": 15
}
}
]
}
}
}
4.4.4 大于、小于、等于…
GET /student/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "张三"
}
}
],
"filter": {
"range": {
"age": {
"gt": 10
}
}
}
}
}
}
4.5 term精确匹配
不知道分词器的存在,不会对filed进行分词操作,直接使用倒排索引精确匹配
# 分词器首先会将张三分为 “张” 和 “三” ,然后查询包含张和三的
GET student/_search
{
"query": {
"match": {
"name": "张三"
}
}
}
# 不会对张三进行分词,直接采用倒排索引查询“张三”, 虽然存在张三这个数据,但是在存储的过程中并没有张三这个最终分词,所以查询为空
GET student/_search
{
"query": {
"term": {
"name": "张三"
}
}
}
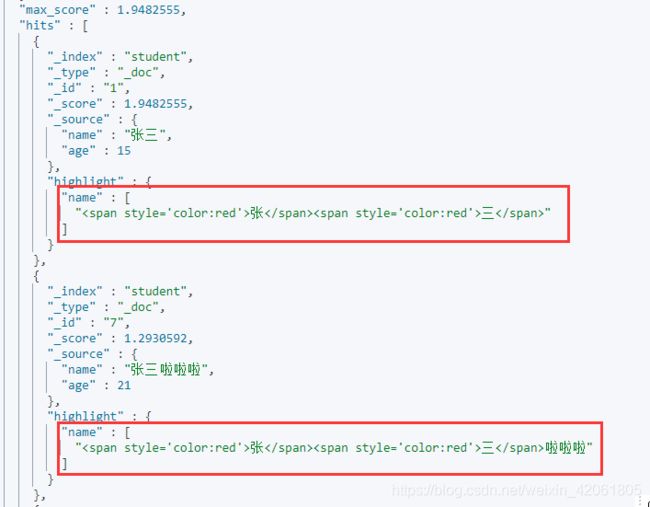
4.6 高亮显示
GET student/_search
{
"query": {
"match": {
"name": "张三"
}
},
"highlight": {
"pre_tags": "",
"post_tags": "",
"fields": {
"name": {}
}
}
}