Go语言(Golang)高并发处理思路
Go语言作为新兴的语言,最近发展势头很是迅猛,其最大的特点就是原生支持并发。它使用的是“协程(goroutine)模型”,和传统基于 OS 线程和进程实现不同,Go语言的并发是基于用户态的并发,这种并发方式就变得非常轻量,能够轻松运行几万并发逻辑。Go 的并发属于 CSP 并发模型的一种实现,CSP 并发模型的核心概念是:“不要通过共享内存来通信,而应该通
过通信来共享内存”。这在 Go 语言中的实现就是 Goroutine 和 Channel。
1、场景描述
在一些场景下,有大规模请求(十万或百万级qps),我们处理的请求可能不需要立马知道结果,例如数据的打点,文件的上传等等。这时候我们需要异步化处理。常用的方法有使用resque、MQ、RabbitMQ等。这里我们在Golang语言里进行设计实践。
2、方案演进
2.1、直接使用goroutine
在Go语言原生并发的支持下,我们可以直接使用一个goroutine(如下方式)去并行处理这个请求。但是,这种方法明显有些不好的地方,我们没法控制goroutine产生数量,如果处理程序稍微耗时,在单机万级十万级qps请求下,goroutine大规模爆发,内存暴涨,处理效率会很快下降甚至引发程序崩溃。
2.2、缓冲队列
缓冲队列一定程度上了提高了并发,但也是治标不治本,大规模并发只是推迟了问题的发生时间。当请求速度远大于队列的处理速度时,缓冲区很快被打满,后面的请求一样被堵塞了。
2.3 队列+工作池
只用缓冲队列不能解决根本问题,这时候我们可以参考一下线程池的概念,定一个工作池(协程池),来限定最大goroutine数目。每次来新的job时,从工作池里取出一个可用的worker来执行job。这样一来即保障了goroutine的可控性,也尽可能大的提高了并发处理能力。
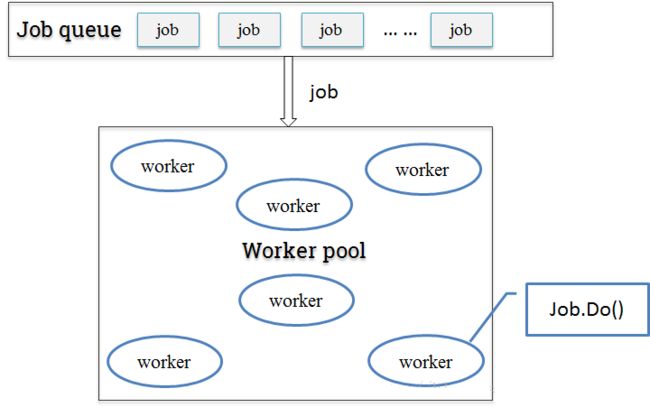
3、代码实现思路:
首先,我们定义一个job的接口, 具体内容由具体job实现;
// --------------------------- Job ---------------------
type Job interface {
Do()
}然后定义一下job队列和work池类型,这里我们work池也用golang的channel实现。
type JobQueue chan Job
// --------------------------- Worker ---------------------
type Worker struct {
JobChan JobQueue //每一个worker对象具有JobQueue(队列)属性。
}// --------------------------- WorkerPool ---------------------
type WorkerPool struct { //线程池:
Workerlen int //线程池的大小
JobQueue JobQueue //Job队列,接收外部的数据
WorkerQueue chan JobQueue //worker队列:处理任务的Go程队列
}4、完整代码
package main
import (
"fmt"
"runtime"
"time"
)
//定义一个实现Job接口的数据
type Score struct {
Num int
}
//定义对数据的处理
func (s *Score) Do() {
fmt.Println("num:", s.Num)
time.Sleep(500*time.Millisecond) //模拟执行的耗时任务
}
func main() {
num := 100 * 100 * 2 //开启 2万个线程
// debug.SetMaxThreads(num + 1000) //设置最大线程数
// 注册工作池,传入任务
// 参数1 worker并发个数
p := NewWorkerPool(num)
p.Run()
//写入一千万条数据
dataNum := 100 * 100* 100* 10
go func() {
for i := 1; i <= dataNum; i++ {
sc := &Score{Num: i}
p.JobQueue <- sc //数据传进去会被自动执行Do()方法,具体对数据的处理自己在Do()方法中定义
}
}()
//循环打印输出当前进程的Goroutine 个数
for {
fmt.Println("runtime.NumGoroutine() :", runtime.NumGoroutine())
time.Sleep(5 * time.Second)
}
}
// --------------------------- Job ---------------------
type Job interface {
Do()
}
type JobQueue chan Job
// --------------------------- Worker ---------------------
type Worker struct {
JobChan JobQueue //每一个worker对象具有JobQueue(队列)属性。
}
func NewWorker() Worker {
return Worker{JobChan: make(chan Job)}
}
//启动参与程序运行的Go程数量
func (w Worker) Run(wq chan JobQueue) {
go func() {
for {
wq <- w.JobChan //处理任务的Go程队列数量有限,每运行1个,向队列中添加1个,队列剩余数量少1个 (JobChain入队列)
select {
case job := <-w.JobChan:
//fmt.Println("xxx2:",w.JobChan)
job.Do() //执行操作
}
}
}()
}
// --------------------------- WorkerPool ---------------------
type WorkerPool struct { //线程池:
Workerlen int //线程池的大小
JobQueue JobQueue //Job队列,接收外部的数据
WorkerQueue chan JobQueue //worker队列:处理任务的Go程队列
}
func NewWorkerPool(workerlen int) *WorkerPool {
return &WorkerPool{
Workerlen: workerlen,
JobQueue: make(JobQueue),
WorkerQueue: make(chan JobQueue, workerlen),
}
}
func (wp *WorkerPool) Run() {
fmt.Println("初始化worker")
//初始化worker(多个Go程)
for i := 0; i < wp.Workerlen; i++ {
worker := NewWorker()
worker.Run(wp.WorkerQueue) //开启每一个Go程
}
// 循环获取可用的worker,往worker中写job
go func() {
for {
select {
//将JobQueue中的数据存入WorkerQueue
case job := <-wp.JobQueue: //线程池中有需要待处理的任务(数据来自于请求的任务) :读取JobQueue中的内容
worker := <-wp.WorkerQueue //队列中有空闲的Go程 :读取WorkerQueue中的内容,类型为:JobQueue
worker <- job //空闲的Go程执行任务 :整个job入队列(channel) 类型为:传递的参数(Score结构体)
//fmt.Println("xxx1:",worker)
//fmt.Printf("====%T ; %T======\n",job,worker,)
}
}
}()
}运行效果:
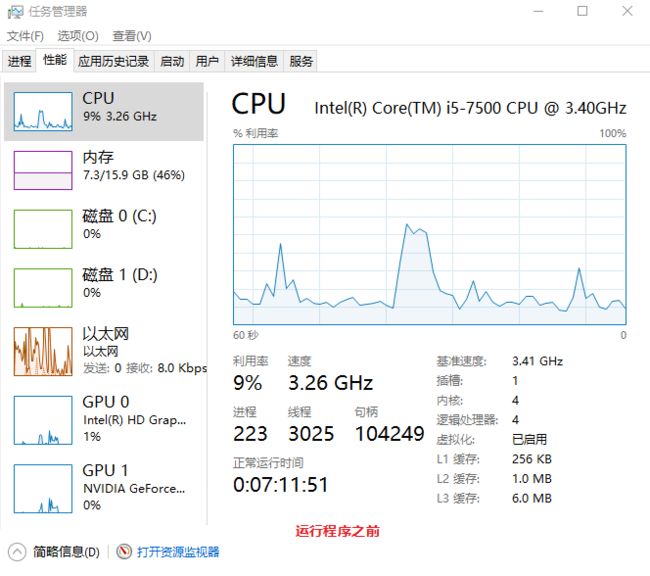
5、资源消耗
5.1 CPU消耗对比

5.2 内存消耗对比
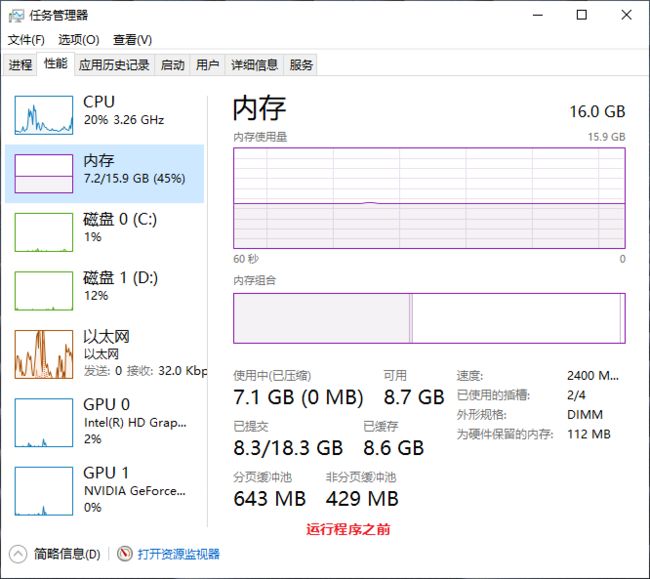
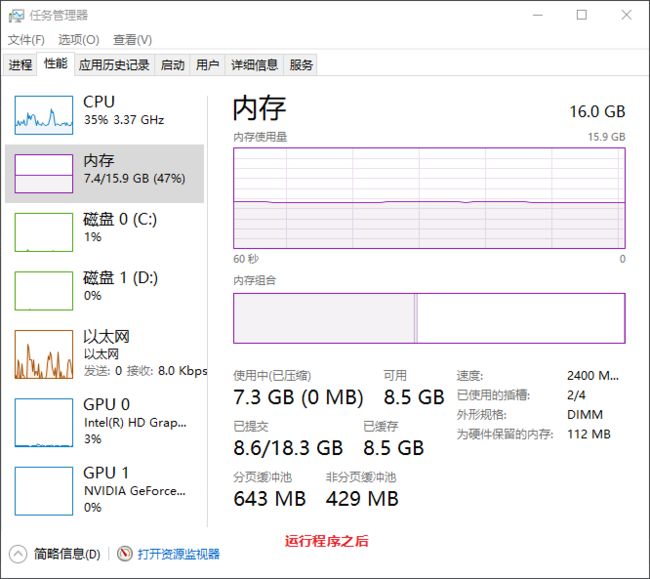
6、代码分析
核心代码:
思考:临时变量 worker是channel,没有读操作,只有写操作。为什么没有发生死锁现象?
select {
case job := <-wp.JobQueue:
worker := <-wp.WorkerQueue
worker <- job
}分别输出临时变量worker、w.JobChan,代码如下:
// 循环获取可用的worker,往worker中写job
go func() {
for {
select {
//将JobQueue中的数据存入WorkerQueue
case job := <-wp.JobQueue: //线程池中有需要待处理的任务(数据来自于请求的任务) :读取JobQueue中的内容
worker := <-wp.WorkerQueue //队列中有空闲的Go程 :读取WorkerQueue中的内容,类型为:JobQueue
worker <- job //空闲的Go程执行任务 :整个job入队列(channel) 类型为:传递的参数(Score结构体)
fmt.Println("临时变量worker:",worker) //todo: 地址是什么
fmt.Printf("====job类型:%T ; worker类型%T======\n",job,worker,)
}
}
}()//启动参与程序运行的Go程数量
func (w Worker) Run(wq chan JobQueue) {
go func() {
for {
wq <- w.JobChan //处理任务的Go程队列数量有限,每运行1个,向队列中添加1个,队列剩余数量少1个 (JobChain入队列)
select {
case job := <-w.JobChan:
fmt.Println("执行处理任务的worker:",w.JobChan) //todo: 地址是什么
job.Do() //执行操作
}
}
}()
}
输出效果为:
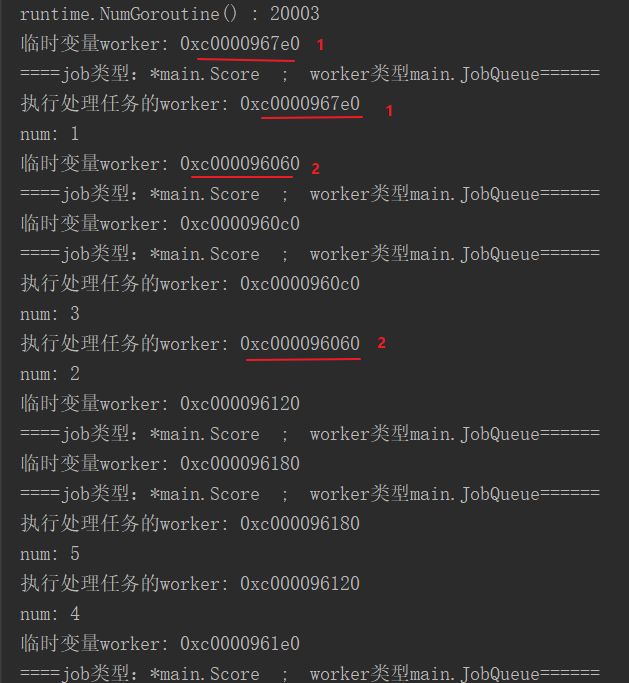
结果发现worker、w.JobChan是同一地址(指向的地址一样)。所以 在
worker <- job :向worker中写数据;job := <-w.JobChan: 从w.JobChan中读数据。由于worker、w.JobChan是对同一数据进行操作,所以临时变量worker不会发生死锁现象。
说明:也可以将核心内容封装成一个库,以后直接调用即可。
知识点说明:
1、 地址引用参考:https://blog.csdn.net/weixin_42117918/article/details/107564157
2、对应channel读写的操作(ch为chan 的类型):
-
ch<-数据类型 //数据写入ch -
数据类型:=<-ch //ch通道中的数据取出,存入数据类型对应的变量。 -
ch1<-ch2 //其中ch1,ch2都是 chan类型(channel类型);执行顺序是从左至右,将ch2存入ch1(ch2入队列ch1),即将ch2看做数据添加到通道ch1中。