Mycat(三)——几种分片规则 分库 一致性hash的原理及使用
文章目录
- Mycat分片规则
- 取模
- 分库
- schema.xml
- 分片枚举
- schema.xml
- 测试
- 问题:
- 固定hash分片
- 优点
- 范围约定分片
- 按日期分区
- 按天分
- 一致性HASH
- 解决什么问题?
- 原理
- 增加节点
- 某个节点宕机
- 数据倾斜
- 总结
- Mycat使用一致性Hash
- 跳增一致性哈希分片
Mycat分片规则
取模
在前面演示分表的时候,使用了取模的方式实现。
取模的话是根据节点个数进行,会有一些弊端,如:
- hash不均匀,生成的分布式id未必是连续的id,因此大概率可能会有很多id被hash到同一个节点;
- 扩容需要rehash。假如有3个节点,一个id被id%3 hash到了第一个节点,如果进行扩容,增加一个实例,那么再对这个id进行hash,id%4,可能就到了另外一个节点,这样的话就无法查询到这个id的数据信息。
分库
这里使用两组主从实例。
master-01——slave01
master02——slave02
【搭建主从见文尾巴】
在两个master中创建一个mycat库,和如下表:
CREATE TABLE `t_order` (
`orderId` bigint(20) NOT NULL,
`orderName` varchar(255) NOT NULL,
`orderType` varchar(255) CHARACTER SET utf8 NOT NULL,
`createTime` datetime DEFAULT NULL,
PRIMARY KEY (`orderId`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf-8 ROW_FORMAT=DYNAMIC;
schema.xml
<schema name="mycatDB" checkSQLschema="true" dataNode="ali3307">
<table name="t_order" dataNode="ali3307,tx3306" primaryKey="orderId" rule="mod-long">
table>
schema>
<dataNode name="ali3307" dataHost="HOSTali3307" database="mycat" />
<dataNode name="tx3306" dataHost="HOSTtx3306" database="consult" />
<dataHost name="HOSTali3307" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()heartbeat>
<connectionInitSql>connectionInitSql>
<writeHost host="aliWrite" url="xxxx:3307" user="root"
password="root">
<readHost host="aliRead" url="xxxx:3316" password="root" user="root"/>
writeHost>
dataHost>
<dataHost name="HOSTtx3306" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()heartbeat>
<connectionInitSql>connectionInitSql>
<writeHost host="txWrite" url="xxxx:3306" user="root"
password="123456">
<readHost host="txRead" url="xxx:3307" password="123456" user="root"/>
writeHost>
dataHost>
说明:
-
在虚拟表table中指定两个master实例的dataNode。
-
两个dataNode分别指定自己的dataHost,在dataHost中,writeHost指定为master,用于写,readHost用于指定slave,用于读。
-
mycat会自动检测到主从关系。
-
规则rule这里还是使用取模 mod-long,在rule.xml中配置的:
<tableRule name="mod-long"> <rule> <columns>orderIdcolumns> <algorithm>mod-longalgorithm> rule> tableRule> <function name="mod-long" class="io.mycat.route.function.PartitionByMod"> <property name="count">2property> function>
测试添加两条数据:
insert into t_order(orderId,orderName,orderType,createTime) values(741624363904667648,'na','DD','2020-02-02')
insert into t_order(orderId,orderName,orderType,createTime) values(741624363904667649,'na','DD','2020-02-02')

分别插入到了两个库中的t_order表。
分片枚举
假如我们要根据某个字段进行分区,如根据不同的省份分到不同的库中。
准备一张表:
CREATE TABLE `t_order_province` (
`orderId` bigint(20) NOT NULL,
`orderName` varchar(255) NOT NULL,
`createTime` datetime DEFAULT NULL,
`province` varchar(255) NOT NULL,
PRIMARY KEY (`orderId`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=latin1 ROW_FORMAT=DYNAMIC;
第4个字段为所属省份信息,我们就根据该字段进行分区。
schema.xml
<schema name="mycatDB" checkSQLschema="true" dataNode="ali3307">
<table name="t_order_province" dataNode="ali3307,tx3306" primaryKey="orderId" rule="sharding-by-intfile">
table>
schema>
在这里表名换成上面的表,然后指定分区规则。其他的和之前的一样。
在rule.xml中配置规则:
<tableRule name="sharding-by-intfile">
<rule>
<columns>provincecolumns>
<algorithm>hash-intalgorithm>
rule>
tableRule>
<function name="hash-int"
class="io.mycat.route.function.PartitionByFileMap">
<property name="mapFile">partition-hash-int.txtproperty>
<property name="type">1property>
<property name="defaultNode">0property>
function>
columns指定分区的列。
在该function中,mapFile指定分区的配置文件。
如下:
BJ=0
SJ=0
GZ=0
HZ=0
JS=1
SX=1
假设将这几个省份分别分到两个区中(注意有几个mysql实例,就只能分几个区,我们有两个master实例,因此最多只能分俩区)
因此,这种方式只能针对这种知道固定值的场景,对范围内可能出现的值做固定分区。
defaultNode:
表示默认节点:小于0表示不设置默认节点,大于等于0表示设置默认节点。
对于不能找到分区的值就存到默认节点中。
测试
连接mycat的逻辑库插入数据:
INSERT INTO t_order_province(orderId,orderName,createTime,province) values(2133,'嘻哈哈','2020-08-03','BJ');
INSERT INTO t_order_province(orderId,orderName,createTime,province) values(2134,'噜噜噜','2020-08-03','HZ');
INSERT INTO t_order_province(orderId,orderName,createTime,province) values(2133,'滴滴','2020-08-03','JS');
INSERT INTO t_order_province(orderId,orderName,createTime,province) values(2134,'啦啦','2020-08-03','SX');
结果:

可以看到,4组数据根据省份名,按照配置的分区进入到了两个库中。
这样就可以根据各个省份实际的业务量,对其数据进行分区到不同的库中。
问题:
对于这样一种分片方式,像上海北京这样的地区的数据量非常大,这样的话,时间久了数据量就会倾斜到此类地区的分区中,而像新疆、西藏的分区就会很少,当数据量饱和时,就需要再增加节点,如使用三台机器保存北京上海的数据。这时可以在中间再加一层mycat,通过一致性hash进行分片:

一致性hash我们后面再讲。
固定hash分片
该分片规则,就取id的二进制低10位,然后和1111111111相与得到一个结果。
优点
相对于十进制取模,当连续插入1-10时,可能会被分到10根分片,而基于二进制,可能会分到连续的分片,能够减少插入事务,避免使用XA带来的性能问题。
配置:
其他都一样,分片规则改成固定hash。
rule.xml中配置如下:
<tableRule name="gd-hash">
<rule>
<columns>orderIdcolumns>
<algorithm>gd-hash-funcalgorithm>
rule>
tableRule>
<function name="gd-hash-func" class="io.mycat.route.function.PartitionByLong">
<property name="partitionCount">1,1property>
<property name="partitionLength">300,724property>
function>
这里有两个参数:
-
partitionCount
分区的数量,值为逗号隔开的相加。上面就是2个分区,如果为2,1那就是3个分区。
-
partitionLength
每个分区的长度。总长为1024。如上面的,第一个分区就是0-299,第二个分区就是300-1023;
如果是如下配置:
<function name="gd-hash-func" class="io.mycat.route.function.PartitionByLong"> <property name="partitionCount">2,1property> <property name="partitionLength">300,424property> function>则共3个分区。第一个分区范围为:0-299;第二个分区为:300-599;第三个分区为600-1023;
配置完成后插入两条数据:
INSERT INTO t_order_province(orderId,orderName,createTime,province) values(1111,'aa','2020-02-02','BJ');
INSERT INTO t_order_province(orderId,orderName,createTime,province) values(8888,'aa','2020-02-02','BJ');
-
1111
转为二进制为10001010111
低10位为:0001010111。
和1111111111相与后为:1010111=87,因此进入第一个分区 -
8888
二进制:10001010111000
低10位:1010111000
相与后:1010111000=696进入第二个分区。
结果:
![]()
范围约定分片
用处不大,就是指定固定的范围进行分片。
rule.xml:
<tableRule name="range-sharding">
<rule>
<columns>orderIdcolumns>
<algorithm>rang-shardingalgorithm>
rule>
tableRule>
<function name="rang-sharding"
class="io.mycat.route.function.AutoPartitionByLong">
<property name="mapFile">autopartition-long.txtproperty>
function>
指定在autopartition-long.txt文件中配置范围规则:
0-1000=0
1001-2000=1
0-1000的id在0分区,1001-2000的分区在1分区。
如果不在范围内,则不可插入。
很简单,就不演示了。
按日期分区
按天分
其他都一样,指定分区规则即可:
<tableRule name="sharding-by-date">
<rule>
<columns>createTimecolumns>
<algorithm>partbydayalgorithm>
rule>
tableRule>
columns指定日期列。
<function name="partbyday"
class="io.mycat.route.function.PartitionByDate">
<property name="dateFormat">yyyy-MM-ddproperty>
<property name="sNaturalDay">0property>
<property name="sBeginDate">2020-08-01property>
<property name="sEndDate">2020-08-08property>
<property name="sPartionDay">4property>
function>
-
sPartionDay
分区大小。指定分区的天数。即从开始日期开始,每n天分在一个节点中。
因为当前只有两个数据库实例,因此调成每4天一个分区,范围从08-01开始,到08-08,正好可以分2个区。
如果范围内可分的分区数大于配置的dataNode个数,启动就会报错。
如果想启动不报错,就不指定结束日期,这样就可以启动了。但是肯定也会按从开始日期开始指定天数进行分区的,所以如果插入的数据的日期除以范围个数的出来的分区位置没有对应的dataNode的话,还是会插入失败。
仍然用之前按省分的那个表:
INSERT INTO t_order_province(orderId,orderName,createTime,province) values(1111,'aa','2020-08-03','BJ');
INSERT INTO t_order_province(orderId,orderName,createTime,province) values(222,'aa','2020-08-04','BJ');
INSERT INTO t_order_province(orderId,orderName,createTime,province) values(333,'aa','2020-08-06','BJ');
INSERT INTO t_order_province(orderId,orderName,createTime,province) values(4444,'aa','2020-08-08','BJ');
这样4条数据,前两个应该在第一个dataNode中,后两个应该在第二个dataNode中:

按月分区道理一样的:
<function name="sharding-by-month"
class="io.mycat.route.function.PartitionByMonth">
<property name="dateFormat">yyyy-MM-ddproperty>
<property name="sBeginDate">2020-01-01property>
<property name="nPartition">3property>
function>
按需配置即可。相关配置进入PartitionByMonth可以看。
一致性HASH
解决什么问题?
前面在分片枚举的部分说到,对于上海北京这样的会出现大业务量的分区,一定会出现数据倾斜现象,这时我们需要对原本的分区节点进行扩容,而扩容一下不要紧,原本hash到之前节点的数据,扩容后,节点个数加1,再进行hash就肯定无法定位到之前的节点,相当于这些数据通过简单的按节点个数取模的hash方式都找不到了。
假如是Redis的架构,那么相当于原理的某个机器的所有的key都失效了,这样当访问这些key的时候就都会打到数据库,会出现缓存雪崩。
原理

如上,一致性hash算法会对2^32次方进行取模,所有的hash后的值组成了一个hash环。
每个主机和过来的id,都会通过一个hash算法获得其在hash环上的一个位置。
上图中,假设有三个节点 H1、H2和H3,其通过hash会到了环中的某个位置;
现在又id1~id5五个id,分别进行hash后也到了环上的几个位置;
这些id如何对应到某个节点呢?
这里,其一致性hash按照环的顺时针方向,对某个id,将其放在顺时针方向距离其最近的一个节点上。
上图中,分配到某个节点的id和当前节点用了同一个颜色标注。
那么假设以下情况:
增加节点
此时像分片枚举中那样,单个节点不够用了,OK,我们加一个节点:

此时增加了一个H4节点,那么现在,就不会像之前的取模hash一样,所有的id都会失效,现在只会有从H4到H2之间的id,即id1会失效,此时id1交给H4处理。
容错性比原本的方式要好很多。
某个节点宕机
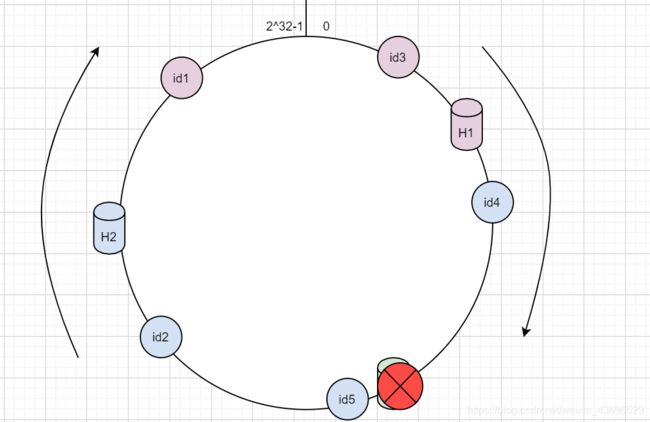
假设此时H3宕机了,那么只有H3和H1之间的id数据会收到影响,即id4,此时id4交给H2处理。
数据倾斜
节点较多时,其hash分布肯定会较均匀,但假如节点比较少,就会出现数据倾斜的情况:

如上,id1、id2、id3和id5都分配给了H1,而H3只分配到了id4,这就会出现数据倾斜。
而一致性hash针对这种情况,会采用一种虚拟节点的方式解决:
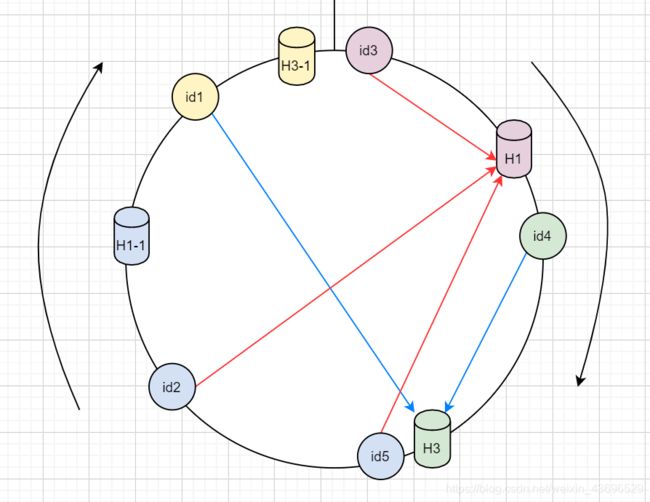
如上,H3映射出一个虚拟的H3-1,H1映射出一个虚拟的H1-1;
这样id2、id5由H1-1处理;
id1由H3-1处理;
但是实际上,id2和id5逗游实际的H1处理(图中箭头所示),id1由实际的H3处理。
因此,其内部需要维护一个虚拟节点到真实节点的映射关系。
在查询时,比如查id1,通过hash找到对应的环的位置,然后找到最近的H3-1。再根据映射关系找到真实的H3,然后从H3中找到id1的数据。
这就是一致性hash的原理。
总结
- 通过虚拟节点解决数据倾斜问题
- 动态扩容或节点宕机时,需要迁移的数据少
Mycat使用一致性Hash
rule.xml
<tableRule name="sharding-by-murmur">
<rule>
<columns>orderIdcolumns>
<algorithm>murmuralgorithm>
rule>
tableRule>
<function name="murmur"
class="io.mycat.route.function.PartitionByMurmurHash">
<property name="seed">0property>
<property name="count">2property>
<property name="virtualBucketTimes">160property>
<property name="bucketMapPath">D:\Documentation\JAVA\mycat\Mycat-Server-Mycat-server-1675-release\src\main\resourcesproperty>
function>
这里还是使用之前的分片枚举用的表,插入1000条数据:
@Test
public void test() {
for (int i = 0; i < 1000; i++) {
Order order = new Order();
order.setOrderId(SnowflakeUtil.nextId());
order.setOrderName("RR");
order.setProvince("XX");
orderMapper.add(order);
}
}
@Insert("insert into t_order_province(orderId,orderName,createTime,province) values(#{orderId},#{orderName},now(),#{province})")
int add(Order order);
两个数据库的数据:

一个449,一个551,较均匀。
跳增一致性哈希分片
mycat源码说明:思想源自Google公开论文,比传统一致性哈希更省资源速度更快数据迁移量更少
rule.xml
<tableRule name="jch">
<rule>
<columns>orderIdcolumns>
<algorithm>jump-consistent-hashalgorithm>
rule>
tableRule>
<function name="jump-consistent-hash" class="io.mycat.route.function.PartitionByJumpConsistentHash">
<property name="totalBuckets">2property>
function>
totalBuckets:指定节点个数。
插入1000条数据:
@Test
public void test() {
for (int i = 0; i < 1000; i++) {
Order order = new Order();
order.setOrderId(SnowflakeUtil.nextId());
order.setOrderName("RR");
order.setProvince("XX");
orderMapper.add(order);
}
}
@Insert("insert into t_order_province(orderId,orderName,createTime,province) values(#{orderId},#{orderName},now(),#{province})")
int add(Order order);

两个master实例的数据均匀了很多。