1、java基础
java入门
计算机语言发展史
计算机语言经历了三代:第一代是机器语言,第二代是汇编语言,第三代是高级语言。
Java的核心优势
跨平台是Java语言的核心优势,赶上最初互联网的发展,并随着互联网的发展而发展,建立了强大的生态体系,目前已经覆盖IT各行业的“第一大语言”,是计算机界的“英语”。
虽然,目前也有很多跨平台的语言,但是已经失去先机,无法和Java强大的生态体系抗衡。Java仍将在未来几十年成为编程语言的主流语言。
JAVA虚拟机是JAVA实现跨平台的核心。事实上,基于JAVA虚拟机(JVM)的编程语言还有很多种。
Java各版本的含义
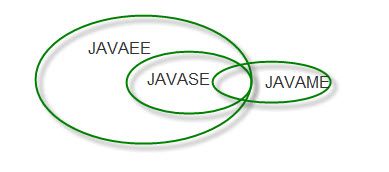
JavaSE(Java Standard Edition):标准版,定位在个人计算机上的应用。这个版本是Java平台的核心,它提供了非常丰富的API来开发一般个人计算机上的应用程序,包括用户界面接口AWT及Swing,网络功能与国际化、图像处理能力以及输入输出支持等。在上世纪90年代末互联网上大放异彩的Applet也属于这个版本。Applet后来为Flash取代,Flash即将被HTML5取代。
JavaEE(Java Enterprise Edition):企业版,定位在服务器端的应用。
JavaEE是JavaSE的扩展,增加了用于服务器开发的类库。如:JDBC是让程序员能直接在Java内使用的SQL的语法来访问数据库内的数据;Servlet能够延伸服务器的功能,通过请求-响应的模式来处理客户端的请求;JSP是一种可以将Java程序代码内嵌在网页内的技术;
JavaME(Java Micro Edition):微型版,定位在消费性电子产品的应用上
JavaME是JavaSE的内伸,包含J2SE的一部分核心类,也有自己的扩展类,增加了适合微小装置的类库:javax.microedition.io.*等。该版本针对资源有限的电子消费产品的需求精简核心类库,并提供了模块化的架构让不同类型产品能够随时增加支持的能力。
很多人开始会误解为安卓开发就是JavaME,这两个是完全不同的内容。
Java的特性和优势
跨平台/可移植性
这是Java的核心优势。Java在设计时就很注重移植和跨平台性。比如:Java的int永远都是32位。不像C++可能是16,32,可能是根据编译器厂商规定的变化。这样的话程序的移植就会非常麻烦。
安全性
Java适合于网络/分布式环境,为了达到这个目标,在安全性方面投入了很大的精力,使Java可以很容易构建防病毒,防篡改的系统。
面向对象
面向对象是一种程序设计技术,非常适合大型软件的设计和开发。由于C++为了照顾大量C语言使用者而兼容了C,使得自身仅仅成为了带类的C语言,多少影响了其面向对象的彻底性!Java则是完全的面向对象语言。
简单性
Java就是C++语法的简化版,我们也可以将Java称之为“C+±”。跟我念“C加加减”,指的就是将C++的一些内容去掉;比如:头文件,指针运算,结构,联合,操作符重载,虚基类等等。同时,由于语法基于C语言,因此学习起来完全不费力。
高性能
Java最初发展阶段,总是被人诟病“性能低”;客观上,高级语言运行效率总是低于低级语言的,这个无法避免。Java语言本身发展中通过虚拟机的优化提升了几十倍运行效率。比如,通过JIT(JUST IN TIME)即时编译技术提高运行效率。 将一些“热点”字节码编译成本地机器码,并将结果缓存起来,在需要的时候重新调用。这样的话,使Java程序的执行效率大大提高,某些代码甚至接待C++的效率。
因此,Java低性能的短腿,已经被完全解决了。业界发展上,我们也看到很多C++应用转到Java开发,很多C++程序员转型为Java程序员。
分布式
Java是为Internet的分布式环境设计的,因为它能够处理TCP/IP协议。事实上,通过URL访问一个网络资源和访问本地文件是一样简单的。Java还支持远程方法调用(RMI,Remote Method Invocation),使程序能够通过网络调用方法。
多线程
多线程的使用可以带来更好的交互响应和实时行为。 Java多线程的简单性是Java成为主流服务器端开发语言的主要原因之一。
健壮性
Java是一种健壮的语言,吸收了C/C++ 语言的优点,但去掉了其影响程序健壮性的部分(如:指针、内存的申请与释放等)。Java程序不可能造成计算机崩溃。即使Java程序也可能有错误。如果出现某种出乎意料之事,程序也不会崩溃,而是把该异常抛出,再通过异常处理机制加以处理。
Java应用程序的运行机制
计算机高级语言的类型主要有编译型和解释型两种,而Java 语言是两种类型的结合。
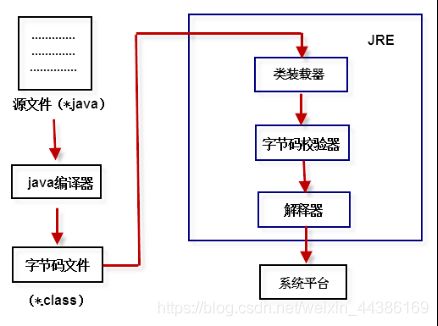
Java首先利用文本编辑器编写 Java源程序,源文件的后缀名为.java;再利用编译器(javac)将源程序编译成字节码文件,字节码文件的后缀名为.class; 最后利用虚拟机(解释器,java)解释执行。
JVM、JRE和JDK
JVM(Java Virtual Machine)就是一个虚拟的用于执行bytecode字节码的”虚拟计算机”。他也定义了指令集、寄存器集、结构栈、垃圾收集堆、内存区域。JVM负责将Java字节码解释运行,边解释边运行,这样,速度就会受到一定的影响。
不同的操作系统有不同的虚拟机。Java 虚拟机机制屏蔽了底层运行平台的差别,实现了“一次编译,随处运行”。 Java虚拟机是实现跨平台的核心机制。如图1-6所示。
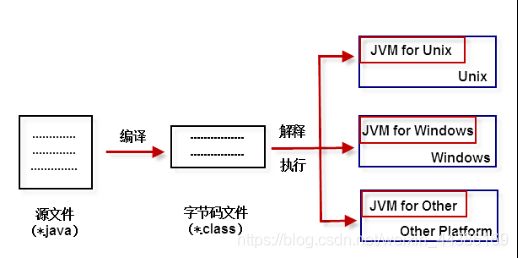
Java Runtime Environment (JRE) 包含:Java虚拟机、库函数、运行Java应用程序所必须的文件。
Java Development Kit (JDK)包含:包含JRE,以及增加编译器和调试器等用于程序开发的文件。
JDK、JRE和JVM的关系如图1-7所示。

Java运行时环境(JRE)。它包括Java虚拟机(JVM)、Java核心类库和支持文件。
Java开发工具包(JDK)是完整的Java软件开发包,包含了JRE,编译器和其他的工具(比如:JavaDoc,Java调试器)
老鸟建议:
**·**如果只是要运行Java程序,只需要JRE就可以。JRE通常非常小,其中包含了JVM。
**·**如果要开发Java程序,就需要安装JDK。
JDK下载和安装
地址:
www.oracle.com/technetwork/java/javase/downloads/index.html
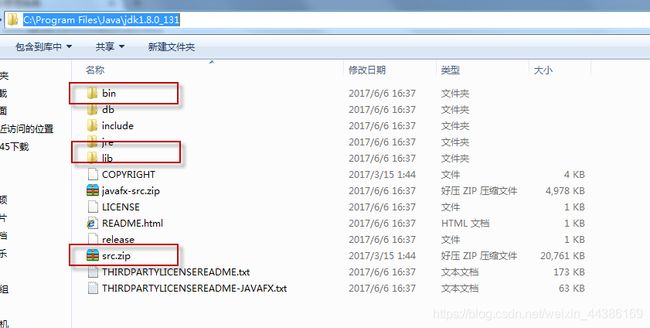
JDK的安装目录C:\Program Files\Java\jdk1.8.0_131,可以看到如下的结构:
其中:
- bin目录是存储一些可执行的二进制文件;
- lib存储相关jar包;
- src.zip是JDK相关JAVA类的源代码。
环境变量Path的配置
环境变量是在操作系统中一个具有特定名字的对象, 它包含了一个或者多个应用程序所将使用到的信息。
Path是一个常见的环境变量,它告诉操作系统,当要求系统运行一个程序而没有告诉它程序所在的完整路径时,系统除了在当前目录下寻找此程序外,还应到哪些目录下寻找。
具体看另一份文档。
开发java程序的一点小总结:
1.Java对大小写敏感,如果出现了大小写拼写错误,程序无法运行。
2.关键字public被称作访问修饰符(access modifier),用于控制程序的其它部分对这段代码的访问级别。
3.关键字class 的意思是类。Java是面向对象的语言,所有代码必须位于类里面。
4.一个源文件中至多只能声明一个public的类,其它类的个数不限,如果源文件中包含一个public 类,源文件名必须和其中定义的public的类名相同,且以“.java”为扩展名。
5.一个源文件可以包含多个类class。
6.正确编译后的源文件,会得到相应的字节码文件,编译器为每个类生成独立的字节码文件,且将字节码文件自动命名为类的名字且以“.class”为扩展名。
7.main方法是Java应用程序的入口方法,它有固定的书写格式:
8.public static void main(String[] args) {…}
9.在Java中,用花括号划分程序的各个部分,任何方法的代码都必须以“{”开始,以“}”结束, 由于编译器忽略空格,所以花括号风格不受限制。
10.Java中每个语句必须以分号结束,回车不是语句的结束标志,所以一个语句可以跨多行。
最常用DOS命令
| 1.cd 目录路径 | 进入一个目录 |
|---|---|
| 2.cd … | 进入父目录 |
| 3.dir | 查看本目录下的文件和子目录列表 |
| 4.cls | 清楚屏幕命令 |
| 5.上下键 | 查找敲过的命令 |
| 6.Tab键 | 自动补齐命令 |
数据类型和运算符
注释
注释不会出现在字节码文件中,即Java编译器编译时会跳过注释语句。 在Java中根据注释的功能不同,主要分为单行注释、多行注释和文档注释。
- 单行注释: 使用“//”开头,“//”后面的单行内容均为注释。
- 多行注释: 以“/”开头以“/”结尾,在“/”和“/”之间的内容为注释,我们也可以使用多行注释作为行内注释。但是在使用时要注意,多行注释不能嵌套使用。
- 文档注释: 以“/**”开头以“*/”结尾,注释中包含一些说明性的文字及一些JavaDoc标签(后期写项目时,可以生成项目的API)
每个方法和类最好都加个注释。(好习惯)
多行注释可以用来做行内注释。

标识符
标识符是用来给变量、类、方法以及包进行命名的,如Welcome、main、System、age、name、gender等。
标识符需要遵守一定的规则:
- 标识符必须以字母、下划线_、美元符号$开头。
- 标识符其它部分可以是字母、下划线“_”、美元符“$”和数字的任意组合。
- Java 标识符大小写敏感,且长度无限制。
- 标识符不可以是Java的关键字。
标识符的使用规范
- 表示类名的标识符:每个单词的首字母大写,如Man, GoodMan
- 表示方法和变量的标识符:第一个单词小写,从第二个单词开始首字母大写,我们称之为“驼峰原则”,如eat(), eatFood()
- 【注意】:Java不采用通常语言使用的ASCII字符集,而是采用Unicode这样标准的国际字符集。因此,这里字母的含义不仅仅是英文,还包括汉字等等。但是不建议大家使用汉字来定义标识符!

其实也就是分为了三类:类名,常量,其他所有。
另外数据库的字段多为用下划线连接,这样反向工程生成的属性名才有驼峰。
Java中的关键字/保留字
Java关键字是Java语言保留供内部使用的,如class用于定义类。 关键字也可以称为保留字,它们的意思是一样的,我们不能使用关键字作为变量名或方法名。
| abstract | assert | boolean | break | byte | case |
| catch | char | class | const | continue | default |
| do | double | else | extends | final | finally |
| float | for | goto | if | implements | import |
| instanceof | int | interface | long | native | new |
| null | package | private | protected | public | return |
| short | static | strictfp | super | switch | synchronized |
| this | throw | throws | transient | try | void |
| volatile | while |
变量
变量的本质
变量本质上就是代表一个”可操作的存储空间”,空间位置是确定的,但是里面放置什么值不确定。我们可通过变量名来访问“对应的存储空间”,从而操纵这个“存储空间”存储的值。
Java是一种强类型语言,每个变量都必须声明其数据类型。变量的数据类型决定了变量占据存储空间的大小。 比如,int a=3; 表示a变量的空间大小为4个字节。
变量作为程序中最基本的存储单元,其要素包括变量名,变量类型和作用域。变量在使用前必须对其声明, 只有在变量声明以后,才能为其分配相应长度的存储空间。
变量的声明
格式为:
`type varName [=value][,varName[=value]...]; ``//[]中的内容为可选项,即可有可无``数据类型 变量名 [=初始值] [,变量名 [=初始值]…];`
注意事项
- 每个变量都有类型,类型可以是基本类型,也可以是引用类型。
- 变量名必须是合法的标识符
- 变量声明是一条完整的语句,因此每一个声明都必须以分号结束
不提倡"一行声明多个变量"风格,逐一声明每一个变量可以提高程序可读性。
变量的分类
从整体上可将变量划分为局部变量、成员变量(也称为实例变量)和静态变量。
| 类型 | 声明位置 | 从属于 | 生命周期 |
| 局部变量 | 方法或语句块内部 | 方法/语句块 | 从声明位置开始,直到方法或语句块执行完毕,局部变量消失 |
| 成员变量(实例变量) | 类内部,方法外部 | 对象 | 对象创建,成员变量也跟着创建。对象消失,成员变量也跟着消失; |
| 静态变量(类变量) | 类内部,static修饰 | 类 | 类被加载,静态变量就有效;类被卸载,静态变量消失。 |
局部变量(local variable)
方法或语句块内部定义的变量。生命周期是从声明位置开始到到方法或语句块执行完毕为止。
局部变量在使用前必须先声明、初始化(赋初值)再使用。
【示例】局部变量
public void test() { int i; int j = i+5 ; // 编译出错,变量i还未被初始化 }
public void test() { int i; i=10; int j = i+5 ; // 编译正确}
//易错点:
public class LocalValue {
public static void main(String[] args) {
int a = 10;
int b;
int c;
if (a>50){
b=9;
}
//还没写到这里的时候不会出错,写到下面一行的时候就会提示出错了
//因为 if(...){}其实不一定会为b赋值,所以编译也会检测出来,并报下面的错误
c=b+a; //Variable 'b' might not have been initialized
}
}
成员变量(也叫实例变量 member variable)
方法外部、类的内部定义的变量。从属于对象,生命周期伴随对象始终。
如果不自行初始化,它会自动初始化成该类型的默认初始值。
| 数据类型 | 实始值 |
|---|---|
| int | 0 |
| double | 0.0 |
| char | ‘\u0000’ (空格,\u是Unicode码的意思) |
| boolean | false |
【示例2-8】实例变量的声明
public class Test {
int i;
}
静态变量(类变量 static variable)
使用static定义。 从属于类,生命周期伴随类始终,从类加载到卸载。 (注:讲完内存分析后我们再深入!先放一放这个概念!)
如果不自行初始化,与成员变量相同会自动初始化成该类型的默认初始值,如上表所示。
生命周期:静态变量>成员变量>局部变量
课堂练习1:变量的声明并赋值
public class LocalVariableTest {
public static void main(String[ ] args) {
boolean flag = true; // 声明boolean型变量并赋值
char c1, c2; // 声明char型变量
c1 = '\u0041'; // 为char型变量赋值
c2 = 'B'; // 为char型变量赋值
int x; // 声明int型变量
x = 9; //为int型变量赋值
int y = x; // 声明并初始化int型变量
float f = 3.15f; // 声明float型变量并赋值
double d = 3.1415926; //声明double型变量并赋值
}
}
课堂代码:
/**
* 测试变量
*/public class TestVariable {
int a;//成员变量, 从属于对象; 成员变量会自动被初始化
static int size;//静态变量,从属于类
public static void main(String[] args) {
{int age; //局部变量,从属于语句块;
age = 18;
}
int salary = 3000; //局部变量,从属于方法
int gao = 13;
System.out.println(gao);
int i;//
int j = i + 5; // 编译出错,变量i还未被初始化
}
}

常量
常量通常指的是一个固定的值,例如:1、2、3、’a’、’b’、true、false、”helloWorld”等。
在Java语言中,主要是利用关键字final来定义一个常量。 常量一旦被初始化后不能再更改其值。
常量名为大写字母和下划线组成。
常量的声明及使用
//声明格式为:
final type varName = value;
public class TestConstants {
public static void main(String[] args) {
final double PI = 3.14;
// PI = 3.15; //编译错误,不能再被赋值!
double r = 4;
double area = PI * r * r;
double circle = 2 * PI * r;
System.out.println("area = " + area);
System.out.println("circle = " + circle);
}
}
一般将1、2、3、’a’、’b’、true、false、”helloWorld”等称为字面常量,
而使用final修饰的PI等称为符号常量。
基本数据类型
Java是一种强类型语言,每个变量都必须声明其数据类型。
Java的数据类型可分为两大类:基本数据类型(primitive data type)和引用数据类型(reference data type)。
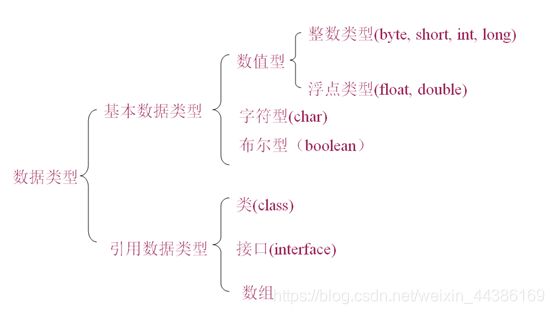
引用数据类型是用来引用对象,为4个字节(32位)
布尔型大小为1位,与c语言不同,不可以使用0或者非0的整数来代替true和flase.
String是引用数据类型中的类。
整型变量/常量
整型数据类型
| 类型 | 占用存储空间 | 表数范围 |
|---|---|---|
| byte | 1字节 | -27 ~ 27-1(-128~127) |
| short | 2字节 | -215 ~ 215-1(-32768~32767) |
| int | 4字节 | -231 ~ 231-1 (-2147483648~2147483647)约21亿 |
| long | 8字节 | -263 ~ 263-1 |
//int型的数据可以直接给byte和short类型的变量赋值
byte a1 = 2, a2 = 4, a3;
short s =16;
//但是如下的语句会报错,因为byte型和short型在计算时会自动转换为int型,结果也是int型。
a3 = a1+a2; 要改为:a3 = (byte)(a1+a2);
s = a1+a2; 要改为:s = (short)(a1+a2);
s = s+a2; 要改为:s = (short)(s+a2);
//但是使用类似 += ,-=的符号,byte型和short型在计算时就不会自动转换为int型
a1 += 1;
s += 1;
Java 语言整型常量的四种表示形式
- 十进制整数,如:99, -500, 0
- 八进制整数,要求以 0 开头,如:015
- 十六进制数,要求 0x 或 0X 开头,如:0x15
- 二进制数,要求0b或0B开头,如:0b01110011
Java语言的整型常数默认为int型,声明long型常量可以后加‘ l ’或‘ L ’ 。
public class Test {
public static void main(String[] args) {
int a = 015;
System.out.println(a); //13
}
}
长整型常数的声明
long a = 55555555; //编译成功,在int表示的范围内(21亿内)。
long b = 55555555555;//不加L编译错误,已经超过int表示的范围。(后面的数值默认是整型的,所以说是超过int表示的范围)
long b = 55555555555L;//修改成long类型的常量即可
浮点型变量/常量
带小数的数据在Java中称为浮点型。浮点型可分为float类型和double类型。
| 类型 | 占用存储空间 | 表数范围 |
|---|---|---|
| float | 4字节 | -3.403E38~3.403E38 |
| double | 8字节 | -1.798E308~1.798E308 |
float类型又被称作单精度类型,尾数可以精确到7位有效数字,在很多情况下,float类型的精度很难满足需求。而double表示这种类型的数值精度约是float类型的两倍,又被称作双精度类型。
绝大部分应用程序都采用double类型。浮点型常量默认类型也是double。
float类型的数值有一个后缀F或者f ,没有后缀F/f的浮点数值默认为double类型。
也可以在浮点数值后添加后缀D或者d, 以明确其为double类型。
Java浮点类型常量有两种表示形式
- 十进制数形式,例如:3.14 314.0 0.314
- 科学记数法形式,如314e-2 314E0 314E-23
使用科学记数法给浮点型变量赋值
double f = 314e2; //314*10^2-->31400.0
double f2 = 314e-2; //314*10^(-2)-->3.14
浮点类型float,double的数据不适合在不容许舍入误差的金融计算领域。如果需要进行不产生舍入误差的精确数字计算,需要使用BigDecimal类。
float f = 0.1f;
double d = 1.0/10;
System.out.println(f==d);//结果为false
float d1 = 423432423f;
float d2 = d1+1;
if(d1==d2){
System.out.println("d1==d2");//输出结果为d1==d2
}else{
System.out.println("d1!=d2");
}
由于字长有限,浮点数能够精确表示的数是有限的,因而也是离散的。
浮点数一般都存在舍入误差,很多数字无法精确表示(例如0.1),其结果只能是接近, 但不等于。
二进制浮点数不能精确的表示0.1、0.01、0.001这样10的负次幂。
并不是所有的小数都能可以精确的用二进制浮点数表示。
**不要使用浮点数进行比较!**很多新人甚至很多理论不扎实的有工作经验的程序员也会犯这个错误!需要比较请使用BigDecimal类。
java.math包下面的两个有用的类:BigInteger和BigDecimal,这两个类可以处理任意长度的数值。BigInteger实现了任意精度的整数运算。BigDecimal实现了任意精度的浮点运算。
import java.math.BigDecimal;
public class Main {
public static void main(String[] args) {
BigDecimal bd = BigDecimal.valueOf(1.0);
bd = bd.subtract(BigDecimal.valueOf(0.1));
bd = bd.subtract(BigDecimal.valueOf(0.1));
bd = bd.subtract(BigDecimal.valueOf(0.1));
bd = bd.subtract(BigDecimal.valueOf(0.1));
bd = bd.subtract(BigDecimal.valueOf(0.1));
System.out.println(bd);//0.5
System.out.println(1.0 - 0.1 - 0.1 - 0.1 - 0.1 - 0.1);//0.5000000000000001
}
}
在二手商城的项目中也有遇到这个问题。最后使用结果保留两位有效数字草草解决。
字符型变量/常量
字符型在内存中占2个字节,在Java中使用单引号来表示字符常量。
例如’A’是一个字符,”A”表示含有一个字符的字符串。
**char 类型用来表示在Unicode编码表中的字符。**Unicode编码被设计用来处理各种语言的文字,它占2个字节,可允许有65536个字符。
Unicode具有从0到65535之间的编码,他们通常用从’\u0000’到’\uFFFF’之间的十六进制值来表示(前缀为u表示Unicode)
char c = '\u0061';
Java 语言中还允许使用转义字符 ‘\’ 来将其后的字符转变为其它的含义。
| 转义符 | 含义 | Unicode值 |
|---|---|---|
| \b | 退格(backspace) | \u0008 |
| \n | 换行 | \u000a |
| \r | 回车 | \u000d |
| \t | 制表符(tab) | \u0009 |
| \“ | 双引号 | \u0022 |
| \‘ | 单引号 | \u0027 |
| \ | 反斜杠 | \u005c |
char c2 = '\n'; //代表换行符
记忆:“换”是第四声,所以n的前面是“\”
String类,其实是字符序列(char sequence)。
public class TestPrimitiveDataType3 {
public static void main(String[] args) {
char a = 'T';
char b = '尚';
char c = '\u0061';
System.out.println(c); //a
//转义字符
System.out.println(""+'a'+'\n'+'b'); //换行
System.out.println(""+'a'+'\t'+'b'); //制表符(空格)
System.out.println(""+'a'+'\''+'b'); //a'b
//String就是字符序列
String d = "abc";
}
}
boolean类型变量/常量
boolean类型有两个常量值,true和false,在内存中占一位(不是一个字节),
不可以使用 0 或非 0 的整数替代 true 和 false ,这点和C语言不同。
boolean 类型用来判断逻辑条件,一般用于程序流程控制 。
boolean flag ;
flag = true; //或者flag=false;
if(flag) {
// true分支
} else {
// false分支
}
//请不要这样写:if ( flag == true ),只有新手才那么写。
//关键也很容易写错成if(flag=true),这样就变成赋值flag 为true而不是判断!
//正确的写法是if ( flag )或者if ( !flag)
运算符(operator)
算术运算符:一元运算符,二元运算符。
| 二元运算符 | +,-,*,/,% |
|---|---|
| 一元运算符 | ++,– |
| 赋值运算符 | = |
| 扩展运算符 | +=,-=,*=,/= |
| 关系运算符 | >,<,>=,<=,==,!= instanceof |
| 逻辑运算符 | &&,||,!,^ |
| 位运算符 | &,|,^,~ , >>,<<,>>> |
| 条件运算符 | ? : |
| 字符串连接符 | + |
算术运算符
算术运算符中+,-,*,/,%属于二元运算符,二元运算符指的是需要两个操作数才能完成运算的运算符。
其中的%是取模运算符,就是我们常说的求余数操作。
二元运算符的运算规则:
整数运算:
1 . 如果两个操作数有一个为Long, 则结果也为long。
2. 没有long时,结果为int。即使操作数全为short,byte,结果也是int。
浮点运算:
3. 如果两个操作数有一个为double,则结果为double。
4. 只有两个操作数都是float,则结果才为float。
取模运算:
1.其操作数可以为浮点数,一般使用整数,结果是“余数”,“余数”符号和左边操作数相同,如:7%3=1,-7%3=-1,7%-3=1。
算术运算符中++,–属于一元运算符,该类运算符只需要一个操作数。
i++与++i详解
i++有“延迟”,i要先以原来的值进行运算,运算完后才会加一,即要到下一条语句才会生效;
++i没有"延迟",一来就让i的值加一。
int a = 3;
int b = a++; //执行完后,b=3。先给b赋值,再自增。
System.out.println("a="+a+"\nb="+b); // 4 3
a = 3;
b = ++a; //执行完后,b=4。a先自增,再给c赋值
System.out.println("a="+a+"\nb="+b); // 4 4
赋值及其扩展赋值运算符
| 运算符 | 用法举例 | 等效的表达式 |
|---|---|---|
| += | a += b | a = a+b |
| -= | a -= b | a = a-b |
| *= | a *= b | a = a*b |
| /= | a /= b | a = a/b |
| %= | a %= b | a = a%b |
int a=3;
int b=4;
a+=b;//相当于a=a+b;
System.out.println("a="+a+"\nb="+b); // 7 4
a=3;
a*=b+3;//相当于a=a*(b+3)
System.out.println("a="+a+"\nb="+b); //21 4
关系运算符
关系运算符用来进行比较运算。关系运算的结果是布尔值:true/false;
| 运算符 | 含义 | 示例 |
|---|---|---|
| == | 等于 | a==b |
| != | 不等于 | a!=b |
| > | 大于 | a>b |
| < | 小于 | a |
| >= | 大于或等于 | a>=b |
| <= | 小于或等于 | a<=b |
- =是赋值运算符,而真正的判断两个操作数是否相等的运算符是==。
- ==、!= 是所有(基本和引用)数据类型都可以使用
- **> 、>=、 <、 <=** 仅针对数值类型(byte/short/int/long, float/double。以及char)
逻辑运算符
逻辑运算的操作数和运算结果都是boolean值。
| 运算符 | 符号 | 说明 |
|---|---|---|
| 逻辑与 | &( 与) | 两个操作数为true,结果才是true,否则是false |
| 逻辑或 | |(或) | 两个操作数有一个是true,结果就是true |
| 短路与 | &&( 与) | 只要有一个为false,则直接返回false |
| 短路或 | ||(或) | 只要有一个为true, 则直接返回true |
| 逻辑非 | !(非) | 取反:!false为true,!true为false |
| 逻辑异或 | ^(异或) | 相同为false,不同为true |
短路与和短路或采用短路的方式。从左到右计算,如果只通过运算符左边的操作数就能够确定该逻辑表达式的值,则不会继续计算运算符右边的操作数,提高效率。
记忆:短路的是两个,没有短路的是一个。
//1>2的结果为false,那么整个表达式的结果即为false,将不再计算2>(3/0)
boolean c = 1>2 && 2>(3/0);
System.out.println(c);
//1>2的结果为false,那么整个表达式的结果即为false,还要计算2>(3/0),0不能做除数,//会输出异常信息
boolean d = 1>2 & 2>(3/0);
System.out.println(d);
这种表示两个限制关系的要用逻辑运算符&&。
if (count>=10&&count<=15) { //错误写法:10<=count<=15
位运算符
位运算指的是进行二进制位的运算。
注意取反符号是有点波浪线的感觉,在键盘的左上角,和表示负数的符号不一样。
| 位运算符 | 说明 |
|---|---|
| ~ | 取反 |
| & | 按位与 |
| | | 按位或 |
| ^ | 按位异或 |
| << | 左移运算符,左移1位相当于乘2 |
| >> | 右移运算符,右移1位相当于除2取商 |
左移运算和右移运算(运算的速度更快)
int a = 3*2*2;
int b = 3<<2; //相当于:3*2*2;
int c = 12/2/2;
int d = 12>>2; //相当于12/2/2;
-
**&和|**既是逻辑运算符,也是位运算符。
如果两侧操作数都是boolean类型,就作为逻辑运算符。如果两侧的操作数是整数类型,就是位运算符。
2. 不要把“^”当做数学运算“乘方”,是“位的异或”操作。
原码反码补码
在二进制编码的中,最高位为符号位,所以通过第一位就可以确定数字的正负。
原码:将最高位作为符号位(0表示正,1表示负),其它数字位代表数值本身的绝对值的数字表示方式。
6:0110 -6:1110
反码:如果是正数,则表示方法和原码一样;
如果是负数,符号位不变,其余各位取反,则得到这个数字的反码表示形式。
6:0110 -6:1001
补码:如果是整数,则表示方法和原码一样;
如果是负数,则将数字的反码加上1(相当于将原码数值位取反然后在最低位加1)
6:0110 -6:1010
0的反码、补码都是0。
取反运算:System.out.println(~8);答案为-9,因为在开发环境中二进制是4位以上的。
四位二进制:8: 0000 1000;用取反的符号“~”每个位置都取反后:1111 0111.
这里注意一个问题:计算机的数据是按照补码的方式进行存储的。
取反后的数字为:1111 0111,是个负数,所以它原来的数值是除去符号后(符号不会变,负数还是负数),减一再取反:1111 0111—>1111 0110—>1000 1001—>-9
如果是4位二进制数的话 ,8取反就是 7。????不会溢出???,至今还不明白
如果是4位以上(任意位)的二进制数的话,那么8取反就是 -9。
字符串连接符
字符串不是基本数据类型,是一个对象。
“+”运算符两侧的操作数中只要有一个是**字符串(String)**类型,系统会自动将另一个操作数转换为字符串然后再进行连接。
字符+数字,会把字符变为对应数字再进行相加;
字符+字符串,字符还是字符。
字符串+数字,相邻的数字变成字符串
int a=12;
System.out.println("a="+a);//输出结果: a=12
char a = '1'; //表示字符时是1,ASCII码是49
int b = 3;
int c = 5;
System.out.println(b+a); // 3+49=52
System.out.println(a); // 1
System.out.println(c);
System.out.println(c+b+a); //5+3+49=57
String d = "1";
System.out.println(c+b+d); //5+3+"1"=81
条件运算符
语法格式:
x ? y : z
其中 x 为 boolean 类型表达式,先计算 x 的值,若为true,则整个运算的结果为表达式 y 的值,否则整个运算结果为表达式 z 的值。
int score = 80;
int x = -100;
String type =score<60?"不及格":"及格";
int flag = x > 0 ? 1 : (x == 0 ? 0 : -1);
System.out.println("type= " + type);
System.out.println("flag= "+ flag);
结果:
type= 及格
flag= -1
运算符优先级的问题
| 优先级 | 运算符 | 类 | 结合性 |
|---|---|---|---|
| 1 | () | 括号运算符 | 由左至右 |
| 2 | !、+(正号)、-(负号) | 一元运算符 | 由左至右 |
| 2 | ~ | 位逻辑运算符 | 由右至左 |
| 2 | ++、– | 递增与递减运算符 | 由右至左 |
| 3 | *、/、% | 算术运算符 | 由左至右 |
| 4 | +、- | 算术运算符 | 由左至右 |
| 5 | <<、>> | 位左移、右移运算符 | 由左至右 |
| 6 | >、>=、<、<= | 关系运算符 | 由左至右 |
| 7 | ==、!= | 关系运算符 | 由左至右 |
| 8 | & | 位运算符、逻辑运算符 | 由左至右 |
| 9 | ^ | 位运算符、逻辑运算符 | 由左至右 |
| 10 | | | 位运算符、逻辑运算符 | 由左至右 |
| 11 | && | 逻辑运算符 | 由左至右 |
| 12 | || | 逻辑运算符 | 由左至右 |
| 13 | ? : | 条件运算符 | 由右至左 |
| 14 | =、+=、-=、*=、/=、%= | 赋值运算符、扩展运算符 | 由右至左 |
- 大家不需要去刻意的记这些优先级,表达式里面优先使用小括号来组织!!
- 逻辑与、逻辑或、逻辑非的优先级一定要熟悉!(逻辑非>逻辑与>逻辑或)。如:
- a||b&&c的运算结果是:a||(b&&c),而不是(a||b)&&c
所以说,在开发的时候还是尽量用小括号括起来
数据类型转换
自动类型转换
自动类型转换指的是容量小的数据类型可以自动转换为容量大的数据类型。如图2-6所示,黑色的实线表示无数据丢失的自动类型转换,而虚线表示在转换时可能会有精度的损失。
注意:(容量不同于字节数)
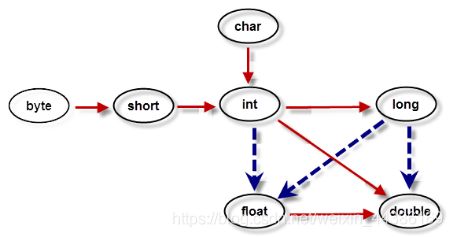
可以将整型常量直接赋值给byte、 short、 char等类型变量,而不需要进行强制类型转换,只要不超出其表数范围即可。
short b = 12; //合法
short b = 1234567;//非法,1234567超出了short的表数范围
强制类型转换
强制类型转换,又被称为造型,用于显式的转换一个数值的类型。在有可能丢失信息的情况下进行的转换是通过造型来完成的,但可能造成精度降低(精度丢失是直接将小数点后面的丢弃,非四舍五入)或溢出。
为防止数字太大溢出,应该将要计算的值进行转换成范围更大的类型,得到的结果也会转换为更大的类型;
如果是对结果进行类型转换,则只是将溢出的结果进行了类型转换。详情见下面:基本类型转化时常见错误和问题的代码。
语法格式:
(type)var //运算符“()”中的type表示将值var想要转换成的目标数据类型。
double x = 3.14;
int nx = (int)x; //值为3
char c = 'a'; //ASCII码是97
int d = c+1;
System.out.println(nx);
System.out.println(d);
System.out.println((char)d);
当将一种类型强制转换成另一种类型,而又超出了目标类型的表数范围,就会被截断成为一个完全不同的值。
int x = 300;
byte bx = (byte)x;
System.out.println(bx); //44 数值溢出后会从最小值重新开始计数
另外:不能在布尔类型和任何数值类型之间做强制类型转换。
基本类型转化时常见错误和问题
操作比较大的数时,要留意是否溢出,尤其是整数操作时。
int money = 1000000000; //10亿
int years = 20;
//返回的total是负数,超过了int的范围
int total = money*years; //-1474836480
System.out.println("total="+total);
//返回的total仍然是负数。默认是int,因此结果会转成int值,再转成long。但是已经发生了数据丢失
long total1 = money*years; //-1474836480
System.out.println("total1="+total1);
//返回的total2正确:先将一个因子变成long,整个表达式发生提升。全部用long来计算。
long total2 = money*((long)years);
System.out.println("total2="+total2); //total2=20000000000
陷阱:不要命名名字为l的变量,l容易和1混淆。long类型使用大写L不要用小写。
简单的键盘输入和输出
//先导入scanner包
import java.util.Scanner;
//system.in 是一个IO流对象,用于扫描系统的输入
//先new一个scanner对象,再用对象名.nextxxx()来获取输入的值。
//输入单个字符是next.charAt(0)
Scanner scanner = new Scanner(System.in);
System.out.println("请输入名字:");
String name = scanner.nextLine();
System.out.println("请输入你的爱好:");
String favor = scanner.nextLine();
System.out.println("请输入你的年龄:");
int age = scanner.nextInt();
System.out.println("###############");
System.out.println(name);
System.out.println(favor);
System.out.println("来到地球的天数:"+age*365);
System.out.println("离开地球的天数:"+(72-age)*365);

控制语句
控制语句
控制语句分为三类:顺序、选择和循环。
“顺序结构”代表“先执行a,再执行b”的逻辑。比如,先找个女朋友,再给女朋友打电话;先订婚,再结婚;
“选择结构”代表“如果…,则…”的逻辑。比如,如果女朋友来电,则迅速接电话;如果看到红灯,则停车;
“循环结构”代表“如果…,则再继续…”的逻辑。比如,如果没打通女朋友电话,则再继续打一次; 如果没找到喜欢的人,则再继续找。
这三种基本逻辑结构是相互支撑的,它们共同构成了算法的基本结构,无论怎样复杂的逻辑结构,都可以通过它们来表达。上述两种结构组成的程序可以解决全部的问题,所以任何一种高级语言都具备上述两种结构。
控制语句加上变量构成了软件程序。
选择结构
选择结构用于判断给定的条件,然后根据判断的结果来控制程序的流程。
主要的选择结构有:if选择结构和switch多选择结构。有如下结构:
- if单选择结构
- if-else双选择结构
- if-else if-else多选择结构
- switch结构
if单选择结构
语法结构
if(布尔表达式){
语句块
}
if语句对布尔表达式进行一次判定,若判定为真,则执行{}中的语句块,否则跳过该语句块。
1.如果if语句不写{},则只能作用于后面的第一条语句。
2.强烈建议,任何时候都写上{},即使里面只有一句话!
Math类的使用
1.java.lang包中的Math类提供了一些用于数学计算的方法。
2.Math.random()该方法用于产生一个0到1区间的double类型的随机数,但是不包括1。
int i = (int) (6 * Math.random()); //产生:[0,5]之间的随机整数
范围:[0,1)含0不含1,所以(int)Math.random()的结果会是0,
因此要将Math.random()乘以一个数字之后才可以转换为int类型来取整。
我们初中高中学到的数学相关知识都可以用Math来实现,
常用的圆周率:Math.PI;
求x的y次方:Math.pow(x,y);
Math.round()加0.5,进行下取整(四舍五入)。
if-else双选择结构
语法结构
if(布尔表达式){
语句块1
}else{
语句块2
}
当布尔表达式为真时,执行语句块1,否则,执行语句块2。也就是else部分。
条件运算符有时候可用于代替if-else
if-else if-else多选择结构
语法结构
if(布尔表达式1) {
语句块1;
} else if(布尔表达式2) {
语句块2;
}……
else if(布尔表达式n){
语句块n;
} else {
语句块n+1;
}
当布尔表达式1为真时,执行语句块1;否则,判断布尔表达式2,当布尔表达式2为真时,执行语句块2;否则,继续判断布尔表达式3······;如果1~n个布尔表达式均判定为假时,则执行语句块n+1,也就是else部分。
public class Test5 {
public static void main(String[] args) {
int age = (int) (100 * Math.random());
System.out.print("年龄是" + age + ", 属于");
if (age < 15) {
System.out.println("儿童, 喜欢玩!");
} else if (age < 25) {
System.out.println("青年, 要学习!");
} else if (age < 45) {
System.out.println("中年, 要工作!");
} else if (age < 65) {
System.out.println("中老年, 要补钙!");
} else if (age < 85) {
System.out.println("老年, 多运动!");
} else {
System.out.println("老寿星, 古来稀!");
}
}
}
switch多选择结构
语法:
switch (表达式) {
case 值1:
语句序列1;
[break];
case 值2:
语句序列2;
[break];
… … … … …
[default:
默认语句;]
}
switch语句会根据表达式的值从相匹配的case标签处开始执行,
一直执行到break语句处或者是switch语句的末尾。
如果表达式的值与任一case值不匹配,则进入default语句(如果存在default语句的情况)。
一般在用的时候都要加上break语句才会符合设计这个结构的思路。
另外书写时switch最好和case对齐。
根据表达式值的不同可以执行许多不同的操作。
switch语句中case标签在JDK1.5之前必须是整数(long类型除外)或者枚举,不能是字符串,在JDK1.7之后允许使用字符串(String)。
大家要注意,当布尔表达式是等值判断的情况,可以使用if-else if-else多选择结构或者switch结构,
如果布尔表达式区间判断的情况,则只能使用if-else if-else多选择结构。
public class Test {
public static void main(String[] args) {
char c = 'a';
int rand = (int) (26 * Math.random());
char c2 = (char) (c + rand);
System.out.print(c2 + ": ");
switch (c2) {
case 'a':
case 'e':
case 'i':
case 'o':
case 'u':
System.out.println("元音");
break;
case 'y':
case 'w':
System.out.println("半元音");
break;
default:
System.out.println("辅音");
}
}
}
循环结构
循环结构分两大类,一类是当型,一类是直到型。
当型:
当布尔表达式条件为true时,反复执行某语句,当布尔表达式的值为false时才停止循环,比如:while与for循环。
直到型:
先执行某语句, 再判断布尔表达式,如果为true,再执行某语句,如此反复,直到布尔表达式条件为false时才停止循环,比如do-while循环。
do-while总是保证循环体至少会被执行一次。
while循环
语法结构:
while (布尔表达式) {
循环体;
}
在循环刚开始时,会计算一次“布尔表达式”的值,若条件为真,执行循环体。而对于后来每一次额外的循环,都会在开始前重新计算一次。
语句中应有使循环趋向于结束的语句,否则会出现无限循环–––"死"循环。
do-while循环
语法结构
do {
循环体;
} while(布尔表达式) ;
for循环
语法结构
for (初始表达式; 布尔表达式; 迭代因子) {
循环体;
}
for循环语句是支持迭代的一种通用结构,是最有效、最灵活的循环结构。
for循环在第一次反复之前要进行初始化,即执行初始表达式;随后,对布尔表达式进行判定,若判定结果为true,则执行循环体,否则,终止循环;最后在每一次反复的时候,进行某种形式的“步进”,即执行迭代因子。
逗号运算符
Java里能用到逗号运算符的地方屈指可数,其中一处就是for循环的控制表达式。
在控制表达式的初始化和步进控制部分,我们可以使用一系列由逗号分隔的表达式,而且那些表达式均会独立执行。
public class Test {
public static void main(String[] args) {
for(int i = 1, j = i + 10; i < 5; i++, j = i * 2) {
System.out.println("i= " + i + " j= " + j);
}
}
}
结果:
i= 1 j= 11
i= 2 j= 4
i= 3 j= 6
i= 4 j= 8
尽管初始化部分可设置任意数量的定义,但都属于同一类型。 ?????指的是i和j是同一个类型?
约定:只在for语句的控制表达式中写入与循环变量初始化,条件判断和迭代因子相关的表达式。
初始化部分、条件判断部分和迭代因子可以为空语句,但必须以“;”分开
public class Test {
public static void main(String[] args) {
for ( ; ; ) { // 无限循环: 相当于 while(true)
System.out.println("北京尚学堂");
}
}
}
在for语句的初始化部分声明的变量,其作用域为整个for循环体,不能在循环外部使用该变量。

嵌套循环
在一个循环语句内部再嵌套一个或多个循环,称为嵌套循环。while、do-while与for循环可以任意嵌套多层。
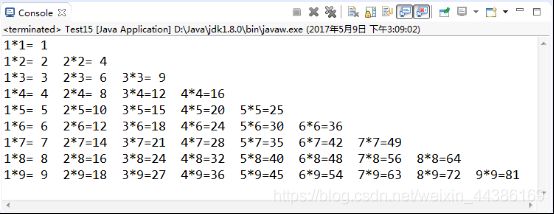
public class Test {
public static void main(String[] args) {
for (int i = 1; i < 10; i++) { // i是一个乘数
for (int j = 1; j <= i; j++) { // j是另一个乘数
System.out.print(j + "*" + i + "=" + (i * j < 10 ? (" " + i * j) : i * j) + " ");
}
System.out.println();
}
}
}
break语句和continue语句
break语句
在任何循环语句的主体部分,均可用break控制循环的流程。
break用于强行退出循环,不执行循环中剩余的语句。
public class Test {
public static void main(String[] args) {
int total = 0;//定义计数器
System.out.println("Begin");
while (true) {
total++;//每循环一次计数器加1
int i = (int) Math.round(100 * Math.random());
//当i等于88时,退出循环
if (i == 88) {
break;
}
}
//输出循环的次数
System.out.println("Game over, used " + total + " times.");
}
}
continue语句
continue 语句用在循环语句体中,用于终止某次循环过程,即跳过循环体中尚未执行的语句,接着进行下一次是否执行循环的判定。
-
continue用在while,do-while中,continue 语句立刻跳到循环首部,越过了当前循环的其余部分。
-
continue用在for循环中,跳到for循环的迭代因子部分(就是最右边的:i++)。
public class Test {
public static void main(String[] args) {
int count = 0;//定义计数器
for (int i = 100; i < 150; i++) {
//如果是3的倍数,则跳过本次循环,继续进行下一次循环
if (i % 3 == 0){
continue; //如果是break,结果就是:100、101、
}
//否则(不是3的倍数),输出该数
System.out.print(i + "、");
count++;//没输出一个数,计数器加1
//根据计数器判断每行是否已经输出了5个数
if (count % 5 == 0) {
System.out.println(); //5个数换一次行
}
}
}
}
结果:
100、101、103、104、106、
107、109、110、112、113、
115、116、118、119、121、
122、124、125、127、128、
130、131、133、134、136、
137、139、140、142、143、
145、146、148、149、
带标签的break和continue
goto关键字很早就在程序设计语言中出现。尽管goto仍是Java的一个保留字,但并未在Java语言中得到正式使用;Java没有goto语句。然而,在break和continue这两个关键字的身上,我们仍然能看出一些goto的影子—带标签的break和continue。
“标签”是指后面跟一个冒号的标识符,例如:“label:”。对Java来说唯一用到标签的地方是在循环语句之前。而在循环之前设置标签的唯一理由是:我们希望在其中嵌套另一个循环,由于break和continue关键字通常只中断当前循环,但若随同标签使用,它们就会中断到存在标签的地方。
在 “goto有害”论中,最有问题的就是标签,而非goto, 随着标签在一个程序里数量的增多,产生错误的机会也越来越多。 但Java标签不会造成这方面的问题,因为它们的活动场所已被限死,不可通过特别的方式到处传递程序的控制权。由此也引出了一个有趣的问题:通过限制语句的能力,反而能使一项语言特性更加有用。
public class Test {
public static void main(String[] args) {
outer: for (int i = 101; i < 150; i++) {
for (int j = 2; j < i / 2; j++) {
if (i % j == 0){
continue outer;
}
}
System.out.print(i + " ");
}
}
}
结果:101 103 107 109 113 127 131 137 139 149
语句块
语句块(有时叫做复合语句),是用花括号扩起的任意数量的简单Java语句。
块确定了局部变量的作用域。
块中的程序代码,作为一个整体,是要被一起执行的。
块可以被嵌套在另一个块中,但是不能在两个嵌套的块内声明同名的变量。
语句块可以使用外部的变量,而外部不能使用语句块中定义的变量,因为语句块中定义的变量作用域只限于语句块。
public class Test19 {
public static void main(String[] args) {
int n;
int a;
{
int k;
int n; //编译错误:不能重复定义变量n
} //变量k的作用域到此为止
}
}
方法
方法就是一段用来完成特定功能的代码片段,类似于其它语言的函数。
方法用于定义该类或该类的实例的行为特征和功能实现。 方法是类和对象行为特征的抽象。方法很类似于面向过程中的函数。
面向过程中,函数是最基本单位,整个程序由一个个函数调用组成。
面向对象中,整个程序的基本单位是类,方法是从属于类和对象的。
方法声明格式:
[修饰符1 修饰符2 …] 返回值类型 方法名(形式参数列表){
Java语句;… … …
}
方法的调用方式:
对象名.方法名(实参列表)
//方法要通过对象调用,不可以直接用。(除非在方法前用static修饰,调用静态方法)
方法的详细说明
-
形式参数:在方法声明时用于接收外界传入的数据。
-
实参:调用方法时实际传给方法的数据。
-
返回值:方法在执行完毕后返还给调用它的环境的数据。
return的两个作用:结束方法的运行;返回值。
-
返回值类型(必不可少):事先约定的返回值的数据类型,如无返回值,必须显示指定为为void。
public class Test {
/** main方法:程序的入口 */
public static void main(String[] args) {
int num1 = 10;
int num2 = 20;
//调用求和的方法:将num1与num2的值传给add方法中的n1与n2
// 求完和后将结果返回,用sum接收结果
int sum = add(num1, num2);
System.out.println("sum = " + sum);//输出:sum = 30
//调用打印的方法:该方法没有返回值
print();
}
/** 求和的方法 */
public static int add(int n1, int n2) {
int sum = n1 + n2;
return sum;//使用return返回计算的结果
}
/** 打印的方法 */
public static void print() {
System.out.println("北京尚学堂...");
}
}
-
实参的数目、数据类型和次序必须和所调用的方法声明的形式参数列表匹配。
如果不匹配会进行自动转换,转换失败(值溢出、字符型与数字不可转换)则会出错。
-
return 语句终止方法的运行并指定要返回的数据。
-
Java中进行方法调用中传递参数时,遵循值传递的原则(传递的都是数据的副本):
-
基本类型传递的是该数据值的copy值。
-
引用类型传递的是该对象引用的copy值,但指向的是同一个对象。
后面的三点极为重要!!!尤其是引用类型那一点。
方法的重载(overload)
方法的重载是指一个类中可以定义多个方法名相同,但参数不同的方法。
重载的方法,实际是完全不同的方法,只是名称相同而已!
调用时,会根据不同的参数自动匹配对应的方法。
构成方法重载的条件:
1.不同的含义:形参类型、形参个数、形参顺序不同(注意,参数顺序不同,也构成重载)
2.只有返回值不同 不构成方法的重载
int a(String str){}与 void a(String str){} //不构成方法重载
3.只有形参的名称不同,不构成方法的重载
int a(String str){}与int a(String s){} //不构成方法重载
不构成重载=编译器无法区分两个方法的不同。
public class Test21 {
public static void main(String[] args) {
System.out.println(add(3, 5));// 8
System.out.println(add(3, 5, 10));// 18
System.out.println(add(3.0, 5));// 8.0
System.out.println(add(3, 5.0));// 8.0
// 我们已经见过的方法的重载
System.out.println();// 0个参数
System.out.println(1);// 参数是1个int
System.out.println(3.0);// 参数是1个double
}
/** 求和的方法 */
public static int add(int n1, int n2) {
int sum = n1 + n2;
return sum;
}
// 方法名相同,参数个数不同,构成重载
public static int add(int n1, int n2, int n3) {
int sum = n1 + n2 + n3;
return sum;
}
// 方法名相同,参数类型不同,构成重载
public static double add(double n1, int n2) {
double sum = n1 + n2;
return sum;
}
// 方法名相同,参数顺序不同,构成重载
public static double add(int n1, double n2) {
double sum = n1 + n2;
return sum;
}
//编译错误:只有返回值不同,不构成方法的重载
public static double add(int n1, int n2) {
double sum = n1 + n2;
return sum;
}
//编译错误:只有参数名称不同,不构成方法的重载
public static int add(int n2, int n1) {
double sum = n1 + n2;
return sum;
}
}
递归结构
递归是一种常见的解决问题的方法,即把问题逐渐简单化。递归的基本思想就是“自己调用自己”,一个使用递归技术的方法将会直接或者间接的调用自己。
利用递归可以用简单的程序来解决一些复杂的问题。比如:斐波那契数列的计算、汉诺塔、快排等问题。
递归结构包括两个部分:
1.定义递归头。(记忆:到头了,结束了)
解答:什么时候不调用自身方法。如果没有头,将陷入死循环,也就是递归的结束条件。
2.递归体。
解答:什么时候需要调用自身方法。
public class Test {
public static void main(String[] args) {
long d1 = System.currentTimeMillis(); //返回当前时刻的毫秒表示。
System.out.printf("%d阶乘的结果:%s%n", 10, factorial(10)); //%n用于换行,这个输出的方法不常用
long d2 = System.currentTimeMillis();
System.out.printf("递归费时:%s%n", d2-d1);
}
/** 求阶乘的方法*/
static long factorial(int n){
if(n==1){//递归头
return 1;
}else{//递归体
return n*factorial(n-1);//n! = n * (n-1)!
}
}
}
结果:
10阶乘的结果:3628800
递归费时:27
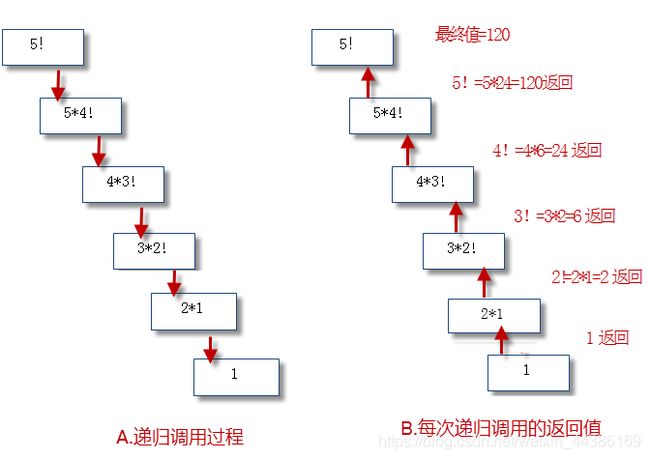
递归的缺陷
简单的程序是递归的优点之一。但是递归调用会占用大量的系统堆栈,内存耗用多,在递归调用层次多时速度要比循环慢的多,所以在使用递归时要慎重。
public class Test {
public static void main(String[] args) {
long d3 = System.currentTimeMillis();
int a = 10;
int result = 1;
while (a > 1) {
result *= a * (a - 1);
a -= 2;
}
long d4 = System.currentTimeMillis();
System.out.println(result);
System.out.printf("普通循环费时:%s%n", d4 - d3);
}
}
结果:
3628800
普通循环费时:0
注意事项
任何能用递归解决的问题也能使用迭代解决。当递归方法可以更加自然地反映问题,并且易于理解和调试,并且不强调效率问题时,可以采用递归;
在要求高性能的情况下尽量避免使用递归,递归调用既花时间又耗内存。