python高级编程 ---- 多任务编程_多进程编程 & 多线程编程 & 协程
文章目录
- python高级编程 多任务编程
- 一、多任务管理
- 1.多任务定义
- 2.单核CPU如何实现“多任务”?
- 3.多核CPU如何实现“多任务”?
- 二、多进程编程
- 1.程序和进程:
- 2.进程的五状态模型:
- 3.fork()实现创建子进程
- 创建子进程:
- 4.多进程编程
- (1)多进程修改全局变量
- (2)实现多进程编程方式一:实例化对象
- ①多进程编程框架
- 多进程编程join()方法理解
- (3)实现多进程编程方式二:进程池管理
- (4)实现多进程编程方式三:创建子类(继承)
- 5.进程间通信
- (1)消息队列实现通信
- (2)消息队列实现通信代码
- 三、多线程编程
- 1.线程
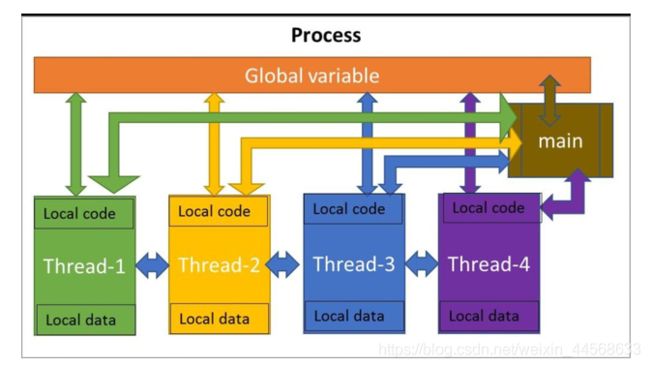
- 2.线程和进程的区别,难点(记忆*)
- 3.线程分类
- 4.多线程编程
- (1)实现多线程方式一:实例化对象
- 项目案例: IP地址归属地批量查询任务
- (1)实现多线程方式二:创建子类
- 项目案例: 创建子线程,执行的任务:判断指定的IP是否存活
- 5.GIL全局解释器锁
- 6.线程同步和线程锁
- 7.死锁
- 四、协程
- 1.什么是协程
- 2、协程的优势
- 3、线程的实现
- 五、总结
python高级编程 多任务编程
一、多任务管理
1.多任务定义
就是操作系统可以同时运⾏多个任务。打个 ⽐⽅,你⼀边在⽤浏览器上⽹,⼀边在听MP3,⼀边在⽤Word赶作业,这就是多任务,⾄少同时有3个任务正在运⾏。还有很多任务悄悄地在后台同时运 ⾏着,只是桌⾯上没有显示⽽已。
2.单核CPU如何实现“多任务”?
操作系统轮流让各个任务交替执⾏,每个任务执⾏0.01秒,这样反复执⾏下去。 表⾯上看,每个任务交替执⾏,但CPU的执⾏速度实在是太快了,感觉就像所有任务都在同时执⾏⼀样。

3.多核CPU如何实现“多任务”?
真正的并⾏执⾏多任务只能在多核CPU上实现,但是,由于任务数量远远多 于CPU的核⼼数量,所以,操作系统也会⾃动把很多任务轮流调度到每个核 ⼼上执⾏。

二、多进程编程
1.程序和进程:
编写完毕的代码,在没有运⾏的时候,称之为程序
正在运⾏着的代码,就成为进程
注意: 进程,除了包含代码以外,还有需要运⾏的环境等,所以和程序是有区别的
linux打开进程:

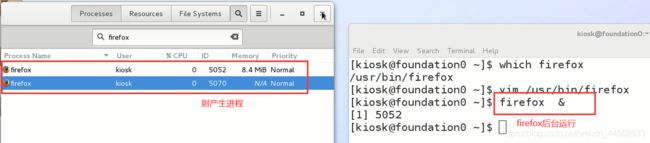
2.进程的五状态模型:
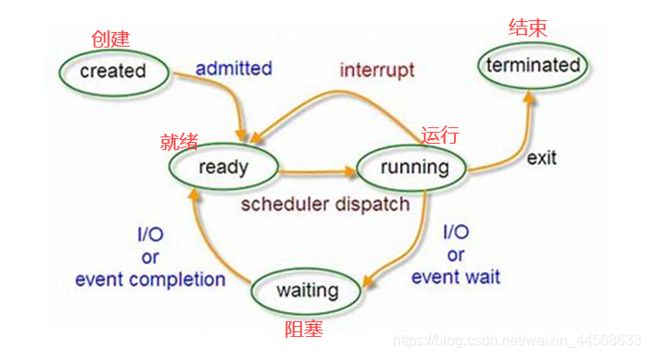
创建–>就绪–>运行–>结束
创建–>就绪–>运行–>就绪–>运行–>结束(cpu跑去执行其他任务,此时处于就绪状态,等待cpu分配时间片段在运行)
创建–>就绪–>运行–>阻塞–>就绪–>运行–>结束(处理从任务时,需要用到其他资料,则处于阻塞状态,等待cpu,然后就绪运行)
3.fork()实现创建子进程
-
Python的os模块封装了常⻅的系统调⽤
fork轻松创建⼦进程。
注意:windows系统中没有fork系统调用,调用os.fork就会报错,该方法在mac,linux,unix中可以使用 -
执⾏到os.fork()时,操作系统会创建⼀个新的进程复制⽗进程的所有信息到⼦进程中
-
普通的函数调⽤,调⽤⼀次,返回⼀次,但是fork()调⽤⼀次,返回两次
-
⽗进程和⼦进程都会从fork()函数中得到⼀个返回值,⼦进程返回是0,⽽⽗进程中返回⼦进程的 id号
创建子进程:

父进程
当前进程 当前进程创建的子进程
linux查看进程:
表示此文件在运行时产生的进程

此程序在pycharm中运行,所以他的父进程为pycharm产生的进程
在命令行运行,则父进程为bash产生的进程
查看命令 ps aux | grep 4206
ps a 显示现行终端机下的所有程序,包括其他用户的程序。
ps u 以用户为主的格式来显示程序状况。
ps x 显示所有程序,不以终端机来区分。

4.多进程编程
(1)多进程修改全局变量
- Windows没有fork调⽤,由于Python是跨平台的,multiprocessing模块就是跨平台版本的多进程模块。multiprocessing模块提供了⼀个Process类来代表⼀个进程对象.
- Process([group [, target [, name [, args [, kwargs]]]]])
target:表示这个进程实例所调⽤对象;执行的任务是什么
args:表示调⽤对象的位置参数元组;
kwargs:表示调⽤对象的关键字参数字典;
name:为当前进程实例的别名;
group:⼤多数情况下⽤不到;
Process类常⽤⽅法:
is_alive(): 判断进程实例是否还在执⾏;
join([timeout]): 是否等待进程实例执⾏结束,或等待多少秒;即:等待进程执行完后在执行的进程
start(): 启动进程实例(创建⼦进程);
run(): 如果没有给定target参数,对这个对象调⽤start()⽅法时,
就将执 ⾏对象中的run()⽅法;
terminate(): 不管任务是否完成,⽴即终⽌;
Process类常⽤属性:
name:当前进程实例别名,默认Process-N,N为从1开始计数;
pid:当前进程实例的PID值;
- 多进程中,每个进程中所有数据(包括全局变量)都各有拥有⼀份,互不影响
import os
import time
# 定义一个全局变量money
money = 100
print("当前进程的pid:", os.getpid())
print("当前进程的父进程pid:", os.getppid())
# time.sleep(115)
p = os.fork() #创建一个子进程,返回两个值
# 子进程返回的是0
if p == 0:
money = 200
print("子进程返回的信息, money=%d" %(money)) #200
# 父进程返回的是子进程的pid
else:
print("创建子进程%s, 父进程是%d" %(p, os.getppid()))
print(money) #100
(2)实现多进程编程方式一:实例化对象
①多进程编程框架

from multiprocessing import Process
import time
def task1():
print("正在听音乐")
time.sleep(1)
def task2():
print("正在编程......")
time.sleep(0.5)
def no_multi(): #没有使用进程时,按照顺序执行
for i in range(2):
task1()
for i in range(5):
task2()
def use_multi(): # 使用进程时,多进程执行,用时少
processes=[]
for i in range(2):
p=Process(target=task1) #实例化prosess类
p.start() #启动进程执行
processes.append(p)
for i in range(5):
p=Process(target=task2) #实例化prosess类
p.start()
processes.append(p)
[process.join() for process in processes] #阻塞当前进程,process执行完在执行主进程(main函数的主程序)
# p.join() 阻塞当前进程, 当p1.start()之后, p1就提示主进程, 需要等待p1进程执行结束才能向下执行, 那
# 么主进程就乖乖等着, 自然不会执行p2.start()
if __name__ == '__main__':
start_time=time.time()
# no_multi()
use_multi()
end_time=time.time()
print(end_time-start_time)
##no_multi() 运行结果:
#正在听音乐
# 正在听音乐
# 正在编程......
# 正在编程......
# 正在编程......
# 正在编程......
# 正在编程......
# 4.503330707550049
##use_multi() 运行结果:
# 正在编程......
# 正在听音乐
# 正在编程......
# 正在编程......
# 正在听音乐
# 正在编程......
# 正在编程......
# 1.3657500743865967
多进程编程join()方法理解
def use_multi():
p1 = Process(target=task1)
p2 = Process(target=task2)
p1.start() #p1启动执行
p1.join() #join()用到这里,相当于没使用多进程,还是顺序执行,因为p2还没启动执行
pu2.start() #p2启动执行
p2.join()
def use_multi():
p1 = Process(target=task1)
p2 = Process(target=task2)
p1.start() #p1启动执行
p2.start() #p2启动执行
p1.join() # join()用到这里,是使用多进程,p1,p2启动开始执行,在使用join()阻塞执行完p1,p2在执行主函数main()
p2.join()
join()作用:
现在有3个进程,task1(),task2(),main()主进程,当运行程序时,这三个进程都被看作时子进程同时运行,哪个先执行完那个先打印,这样的话,main()函数计算时间的任务运行的快,他只计算了前面的时间。所以需要join()来阻塞,使得main()最后执行
(3)实现多进程编程方式二:进程池管理
- 当被操作对象数目不大时(十几个),可以直接利用multiprocessing中的Process动态成生多个进程,十几个还好,但如果是上百个,上千个目标,手动的去限制进程数量却又太过繁琐,此时可以发挥进程池的功效。
Pool可以提供指定数量的进程供用户调用,当有新的请求提交到pool中时,如果池还没有满,那么就会创建一个新的进程用来执行该请求;但如果池中的进程数已经达到规定最大值,那么该请求就会等待,直到池中有进程结束,才会创建新的进程来它。
进程池编程框架
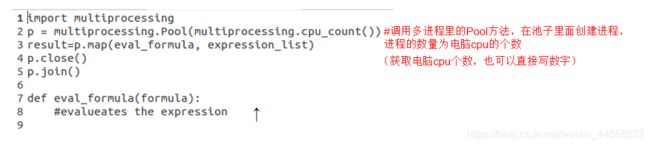
查看cpu个数:

不使用多进程,使用多进程,使用进程池 三种方式实现判断素数 对比
##不使用多进程,使用多进程,使用进程池 三种方式实现判断素数 对比
def is_prime(num):
"""判断素数"""
if num == 1:
return False
for i in range(2, num):
if num % i == 0:
return False
else:
return True
def task(num):
if is_prime(num):
print("%d是素数" % (num))
from multiprocessing import Process
# 判断1,10000之间所有的素数
def use_mutli():
ps = []
# 不要开启太多进程, 创建子进程会耗费时间和空间(内存);电脑会卡死
for num in range(1, 10000):
# 实例化子进程对象
p = Process(target=task, args=(num,))
# 开启子进程
p.start()
# 存储所有的子进程对象
ps.append(p)
# 阻塞子进程, 等待所有的子进程执行结束, 再执行主进程;
[p.join() for p in ps]
# 判断1000-1200之间所有的素数
def no_mutli():
for num in range(1, 100000):
task(num)
#使用进程池
def use_pool():
"""使用进程池"""
from multiprocessing import Pool
from multiprocessing import cpu_count # 4个
p = Pool(cpu_count()) #池子里面产生进程
p.map(task, list(range(1, 100000))) #给进程分配任务
p.close() # 关闭进程池
p.join() # 阻塞, 等待所有的子进程执行结束, 再执行主进程;
if __name__ == '__main__':
import time
start_time = time.time()
# 数据量大小 # 1000-1200 # 1-10000 # 1-100000
# no_mutli() # 0.0077722072601 # 1.7887046337127686 # 90.75180315971375
# use_mutli() # 1.806459665298462 # >100
use_pool() # 0.15455389022827148 # 1.2682361602783203 # 35.63375639915466
end_time = time.time()
print(end_time - start_time)
(4)实现多进程编程方式三:创建子类(继承)
"""
创建子类, 继承的方式
"""
from multiprocessing import Process
import time
class MyProcess(Process):
"""
创建自己的进程, 父类是Process
"""
def __init__(self, music_name):
super(MyProcess, self).__init__()
self.music_name = music_name
def run(self):
"""重写run方法, 内容是你要执行的任务"""
print("听音乐%s" %(self.music_name))
time.sleep(1)
# 开启进程: p.start() ====== p.run()
if __name__ == '__main__':
for i in range(10):
p = MyProcess("音乐%d" %(i))
p.start()
5.进程间通信

(1)消息队列实现通信
可以使⽤multiprocessing模块的Queue实现多进程之间的数据传递,Queue 本身是⼀个消息列队程序。
Queue.qsize(): 返回当前队列包含的消息数量;
Queue.empty(): 如果队列为空,返回True,反之False ;
Queue.full(): 如果队列满了,返回True,反之False;
Queue.get([block[, timeout]]):
获取队列中的⼀条消息,然后将其从列队中移除,block默认值为True;
Queue.get_nowait():
相当Queue.get(False);
Queue.put(item,[block[, timeout]]):
将item消息写⼊队列,block默认值 为True;
Queue.put_nowait(item):
相当Queue.put(item, False)
(2)消息队列实现通信代码


三、多线程编程
1.线程
线程(英语:thread)是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。

- 每个进程至少有一个线程,即进程本身。进程可以启动多个线程。操作系统像并行“进程”一样执行这些线程。
线程的几种状态

2.线程和进程的区别,难点(记忆*)
区别
- 进程是资源分配的最小单位,线程是程序执行的最小单位。
- 进程有自己的独立地址空间。线程是共享进程中的数据的,使用相同的地址空间.
- 进程之间的通信需要以通信的方式(IPC)进行。线程之间的通信更方便,同一进程下的线程共享全局变量、静态变量等数据。
难点
- 处理好同步与互斥。
3.线程分类
有两种不同的线程:
- 内核线程
- 用户空间线程或用户线程(我们多线程创建的线程)
内核线程是操作系统的一部分,而内核中没有实现用户空间线程。
4.多线程编程
与多进程类似
python的thread模块是⽐较底层的模块(一般不用),python的threading 模块是对thread做了⼀些包装的,可以更加⽅便的被使⽤

import threading
if __name__ == '__main__':
# 一个进程里面一定有一个线程, 叫主线程.用来管理其他线程
print("当前线程个数:", threading.active_count()) # 1
print("当前线程信息:", threading.current_thread())
(1)实现多线程方式一:实例化对象
多线程程序的执⾏顺序是不确定的。
当执⾏到sleep语句时,线程将被阻塞(Blocked),到sleep结束后,线程进⼊就绪(Runnable)状态,等待调度。⽽线程调度将⾃⾏选择⼀个线程执⾏。
代码中只能保证每个线程都运⾏完整个run函数,但是线程的启动顺序、 run函数中每次循环的执⾏顺序都不能确定。
"""
通过实例化对象的方式实现多线程
"""
import time
import threading
def task():
"""当前要执行的任务"""
print("听音乐........")
time.sleep(1)
if __name__ == '__main__':
start_time = time.time()
threads = []
for count in range(5):
t = threading.Thread(target=task)
# 让线程开始执行任务
t.start()
threads.append(t)
# 等待所有的子线程执行结束, 再执行主线程;
[thread.join() for thread in threads]
end_time = time.time()
print(end_time-start_time)
项目案例: IP地址归属地批量查询任务
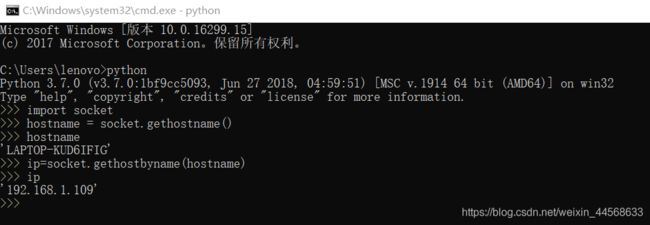
windows获取主机名和IP地址方法
此网址可获取到 IP地址归属地信息:

代码如下:
## IP地址归属地批量查询任务
import requests
import json
from sqlalchemy import create_engine, Column, Integer, String
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
from threading import Thread
import pymysql
pymysql.install_as_MySQLdb()
def task(ip):
"""获取指定IP的所在城市和国家并存储到数据库中"""
# 获取网址的返回内容
url = 'http://ip-api.com/json/%s' % (ip)
try:
response = requests.get(url)
except Exception as e:
print("网页获取错误:", e)
else:
# 默认返回的是字符串
"""
{"as":"AS174 Cogent Communications","city":"Beijing","country":"China","countryCode":"CN","isp":"China Unicom Shandong Province network","lat":39.9042,"lon":116.407,"org":"NanJing XinFeng Information Technologies, Inc.","query":"114.114.114.114","region":"BJ","regionName":"Beijing","status":"success","timezone":"Asia/Shanghai","zip":""}
"""
contentPage = response.text
# 将页面的json字符串转换成便于处理的字典;
data_dict = json.loads(contentPage)
# 获取对应的城市和国家
city = data_dict.get('city', 'null') # None,未获取到city值的话返回null
country = data_dict.get('country', 'null')
print(ip, city, country)
# 存储到数据库表中ips
ipObj = IP(ip=ip, city=city, country=country)
session.add(ipObj)
session.commit()
if __name__ == '__main__':
engine = create_engine("mysql://root:[email protected]/daliu",
encoding='utf8',echo=True
)
# 创建缓存对象
Session = sessionmaker(bind=engine)
session = Session()
# 声明基类
Base = declarative_base()
class IP(Base):
__tablename__ = 'ips'
id = Column(Integer, primary_key=True, autoincrement=True)
ip = Column(String(20), nullable=False)
city = Column(String(30))
country = Column(String(30))
def __repr__(self):
return self.ip
# 创建数据表
Base.metadata.create_all(engine)
# 1.1.1.1 -- 1.1.1.10
threads = []
for item in range(10):
ip = '1.1.1.' + str(item + 1) # 1.1.1.1 -1.1.1.10
# task(ip)
# 多线程执行任务
thread = Thread(target=task, args=(ip,))
# 启动线程并执行任务
thread.start()
# 存储创建的所有线程对象;
threads.append(thread)
[thread.join() for thread in threads]
print("任务执行结束.........")
print(session.query(IP).all())
(1)实现多线程方式二:创建子类
项目案例: 创建子线程,执行的任务:判断指定的IP是否存活
基于多线程的批量主机存活探测
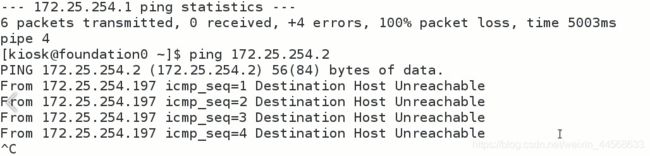
如果要在本地网络中确定哪些地址处于活动状态或哪些计算机处于活动状态, 则可以使用此脚本。我们将依次ping地址, 每次都要等几秒钟才能返回值。
是否使用了这个ip地址,看能不能ping通
没有线程的解决方案效率非常低,因为脚本必须等待每次ping
没ping通说明没人使用此ip
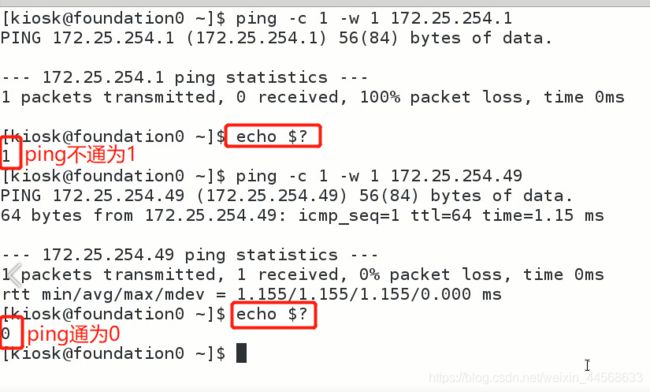

代码如下:
import os
from threading import Thread
class GetHostAliveThread(Thread):
"""
创建子线程,执行的任务:判断指定的IP是否存活
"""
def __init__(self,ip):
super(GetHostAliveThread, self).__init__()
self.ip = ip
def run(self):
"""
重写run()方法:判断指定的IP是否存活
#执行shell命令行语句
os.system() 返回值为0:命令正确执行,不报错 返回值不为0:执行报错
os.system('ping -c1 -w1 172.25.254.49 &> /dev/null') # &> /dev/null 不显示信息
0
os.system('ping -c1 -w1 172.25.254.1 &> /dev/null')
256
"""
# 执行的shell命令
cmd = 'ping -c1 -w1 %s ' %(self.ip)
result = os.system(cmd)
if result != 0:
print('%s主机没有ping通' %(self.ip))
if __name__ == '__main__':
print('打印172.25.254.0网段没有使用的IP地址'.center(10,'*'))
for i in range(1,255):
ip = '172.25.254.' + str(i)
thread = GetHostAliveThread(ip)
thread.start()
5.GIL全局解释器锁
共享全局变量
优点: 在⼀个进程内的所有线程共享全局变量,能够在不使⽤其他⽅式的前提下完成多线程之间的数据共享(这点要⽐多进程要好)
缺点: 线程是对全局变量随意遂改可能造成多线程之间对全局变量的混乱(即线程⾮安全)
如何解决线程不安全问题?
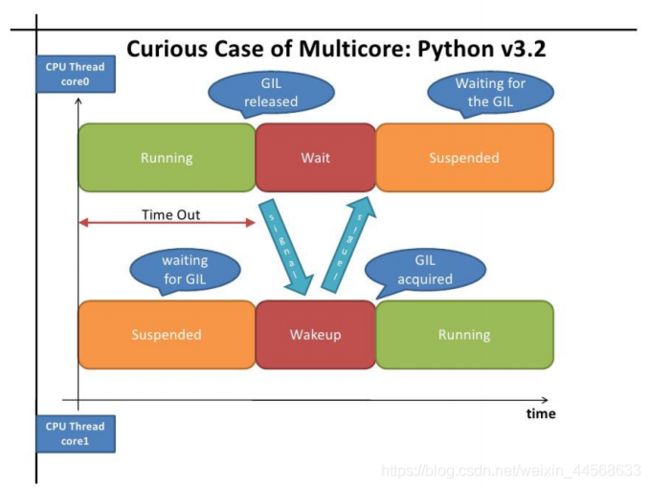
GIL(global interpreter lock): python解释器(CPython)中任意时刻都只有一个线程在执行;
Python代码的执行由Python 虚拟机(也叫解释器主循环,CPython版本)来控 制,Python 在设计之初就考虑到要在解释器的主循环中,同时只有一个线程 在执行,即在任意时刻,只有一个线程在解释器中运行。对Python 虚拟机的 访问由全局解释器锁(GIL)来控制,正是这个锁能保证同一时刻只有一个 线程在运行。
那么使用多线程的时候怎么办?
(1)还有一个python解释器:JPython,他没有全局解释器锁
(2)使用多进程
I/O密集型,输入输出,不会占用CPU(比如爬虫),就可以用多线程去做,效率高
CPU密集型,计算量较大,使用多进程
后面会写到
6.线程同步和线程锁
来看这样一个现象
from threading import Thread
money = 0
def add():
for i in range(1000000):
global money
money += 1
def reduce():
for i in range(1000000):
global money
money -= 1
if __name__ == '__main__':
t1 = Thread(target=add)
t2 = Thread(target=reduce)
t1.start()
t2.start()
t1.join()
t2.join()
print(money)
# 113841
理解:money在+1000000,-1000000后,结果并不是我们想要的0
这是因为在数据量非常大的时候,在运算的过程中,多个线程可能会出现不同步的现象
一开始money=0
当第一个线程add来的时候
money += 1 ,money只是加了1,这个时候还没有将1赋给money,money仍然是0,
这时候第二个线程reduce来了,他直接在money还是0的基础上就去减1,因此结果并不是我们想要的
这是因为多线程共享全局变量
线程对全局变量随意遂改可能造成多线程之间对全局变量的混乱
线程同步:
即当有一个线程在对内存进行操作时,其他线程都不可以对这个内 存地址进行操作,直到该线程完成操作, 其他线程才能对该内存地址进行操作.
同步就是协同步调,按预定的先后次序进⾏运⾏。如:你说完,我再说。
"同"字从字⾯上容易理解为⼀起动作 其实不是,
"同"字应是指协同、协助、互相配合
在对数据进行更改时怎么实现线程同步?
需要用到线程锁:
#实例化一个锁对象,主函数中
lock = threading.Lock()
#操作变量之前进行加锁
lock.acquire()
#操作变量之后进行解锁
lock.release()
from threading import Thread
from threading import Lock
money = 0
def add():
for i in range(1000000):
global money
#操作变量之前进行加锁
lock.acquire()
money += 1
#操作变量之后进行解锁
lock.release()
def reduce():
for i in range(1000000):
global money
# 操作变量之前进行加锁
lock.acquire()
money -= 1
# 操作变量之后进行解锁
lock.release()
if __name__ == '__main__':
t1 = Thread(target=add)
t2 = Thread(target=reduce)
#实例化一个线程锁
lock = Lock()
t1.start()
t2.start()
t1.join()
t2.join()
print(money)
# 0
7.死锁
在线程间共享多个资源的时候,如果两个线程分别占有⼀部分资源并且同时等待对⽅的资源,就会造成死锁。
比如:A有1个苹果1个手机,B有1个梨1个电脑
A说:你先把你的梨给我,我就把我的苹果给你
但是B说:你得先把你的手机给我,我就把我的电脑给你
他俩都在等待对方给资源,僵持住了
"""转账操作"""
import time
import threading
class Account(object):
def __init__(self, id, money, lock):
self.id = id
self.money = money
self.lock = lock
def reduce(self, money):
self.money -= money
def add(self, money):
self.money += money
def transfer(_from, to, money):
if _from.lock.acquire(): # 加锁
_from.reduce(money)
#让线程之间有一个争夺资源的过程,有一点时间的浪费
time.sleep(1)
if to.lock.acquire(): # 加锁
to.add(money)
to.lock.release()
_from.lock.release()
if __name__ == '__main__':
a = Account('a',1000,threading.Lock())
b = Account('b',1000,threading.Lock())
t1 = threading.Thread(target=transfer, args=(a, b, 200))
t2 = threading.Thread(target=transfer, args=(b, a, 100))
t1.start()
t2.start()
print(a.money)
print(b.money)
程序就一直结束不了,一直僵持不动了
怎么解决死锁?
(1)不要用多个锁
(2)对每个锁进行优先级排序
四、协程
1.什么是协程
协程,又称微线程,纤程。英文名Coroutine。
协程看上去也是子程序,但执行过程中, 在子程序内部可中断,然后转而执行别的子程序,在适当的时候再返回来接着执行
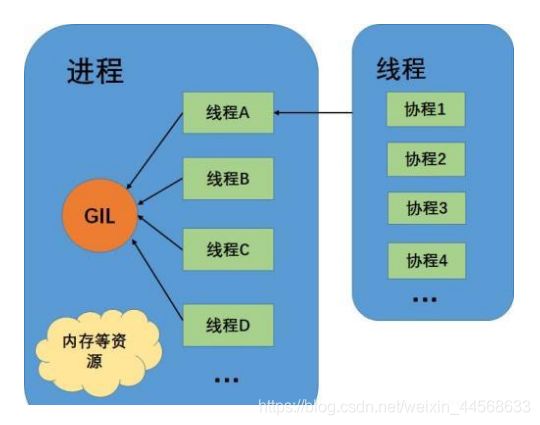
进程 — 线程 — 协程
可以对应理解为:
程序 — 函数 — 函数片段
在执行到一个函数的某个语句时,跳到另外一个函数的某个语句去执行,执行一会儿后又跳回到原来停止的地方执行
和yield类似
可以通过yield去实现协程
2、协程的优势
(1)执行效率极高,因为子程序切换(函数),不是线程切换,由程序自身控制,
(2)没有切换线程的开销。所以与多线程相比,线程的数量越多,协程性能的优势越明显。
(3)不需要多线程的锁机制,因为只有一个线程,也不存在同时写变量冲突,在控制共享资源时也不需要加锁,因此执行效率高很多
3、线程的实现
方法一:yield实现
import time
def consumer():
r = ''
while True:
n = yield r # 停止
if not n :
return
print('[consumer] Consuming %s...' %(n))
time.sleep(1)
r = '200 ok'
def produce(c):
c.next() # 执行consumer生成器内容
n = 0
while n < 5:
n = n + 1
print('[producer] Produceing %s...' %(n))
r = c.send(n) # 把n=1发送给consumer 15行
print('[producer] Consumer rerurn: %s' %(r))
c.close()
if __name__ == '__main__':
c = consumer() # consumer()函数里有yield ,所以返回的c是一个生成器
produce(c)
需自己分析在哪里跳转
方法二:gevent模块实现
基本思想: 当一个greenlet遇到IO操作时,比如访问网络,就自动切换到其他的greenlet,等到 IO操作完成,再在适当的时候切换回来继续执行。由于IO操作非常耗时,经常使程序处于等待状态,有了gevent为我们自动切换协程,就保证总有greenlet在运行,而不是等待IO
gevents = [gevent.spawn()
gevent.joinall(gevents)
在前面的案例:IP地址归属地批量查询任务中
使用协程改写
import gevent
#对io操作进行监视,要打一个补丁
from gevent import monkey
monkey.patch_all()
gevents = [gevent.spawn(task,'1.1.1.'+str(ip+1)) for ip in range(10)]
gevent.joinall(gevents)
五、总结

多任务分类:
(1)IO密集型的任务
有阻塞状态,需要等待,不会一直占用CPU
建议使用多线程编程
(2)计算密集型的任务
没有阻塞状态,一直占用CPU
建议使用多进程编程