论文:accurate ,large minibatch SGD:Training ImageNet in 1 Hour
Abstract:
这篇论文发现,在 ImageNet dataset 上使用 large minibatch 会导致优化困难,但是当这个问题解决了,模型具有更好的泛化能力,并且没有精度上的损失
为达到这个目的,我们提出了 hyper-parameter-free linear scaling rule,用来调整学习率,学习率是有关于 minibatch size 的一个函数,还提出了一个 warmup scheme 用来克服训练早期的优化问题
1 Introduction:
本文目的是介绍 分布式同步 SGD 完成 large-scale training,我们可以将 ResNet-50 从 minibatch size 256 时间 29 hours 缩短到 minibatch size 8192 in 1 hour,获得的精度一样的,如下图
为了解决 large minibatch size,我们提出了一个简单的 hyper-parameter-free linear scaling rule 来调整学习率,为了成功应用此 rule,我们提出了一个新的 warmup strategy. 这个 strategy 在训练的初期使用低的学习率来克服优化困难
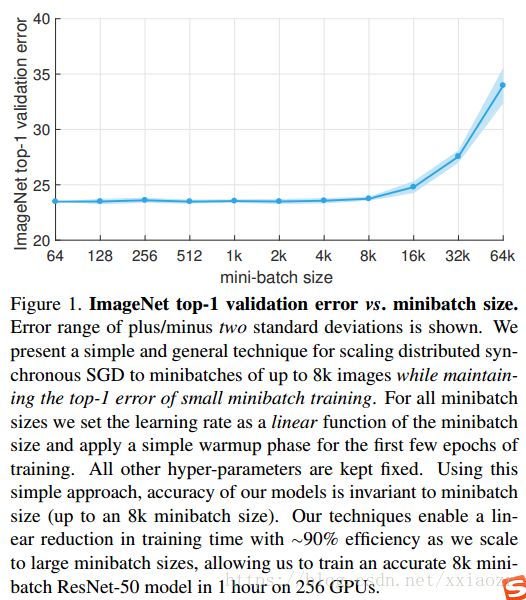
我们之后的实验说明了优化困难最主要的问题是 large minibatch 而不是 poor generalization ( 至少在 ImageNet 上是),而且我们说明了 linear scaling rule 和 warmup strategy 可以推广到更复杂的任务,比如 detection 和 instance segmentation.
虽然这个 strategy 很简单,但是它的应用需要比较好的理解,SGD里面很小的改变有时候会得到很难发现的错误的结果,之后我们会描述这些常见的陷阱和解决的细节,我们的策略还需要非平凡的通信算法
在工业界,我们可以释放模型训练大量数据的潜能,在学术界我们可以简化从单 GPU 到多 GPU 的迁移而不需要超参数搜索
2 Large Minibatch SGD:
首先回顾基本的随机梯度下降方法

w 是 weight , x 是有标签的训练数据 l(x,w)是计算的 loss ,通常 loss 是 classification loss (cross-entropy)和 regularization loss on w 的和
Minibatch SGD 在最近的文献中被简称为 SGD,它的更新函数如下:

其中 B 是一个minibatch 的sample,n 是 minibatch size , η 是学习率,我们使用的是 momentum SGD ,在之后的第3部分进行讨论
2.1 learning rates for large minibatches
large minibatch 在分布式学习中可以利用数据并行性使用多个 work 工作,并且不会减少每一个 work 的工作量也不会牺牲模型的精度
Liner Scaling Rule: When the minibatch size is multiplied by K ,multiply the learning rate by K
这个 rule 在 broad range of minibatch size 里都很有效果,其他的 hyper-parameters(weight decay 等)都保持不变,在第 5 部分,我们将会展示 linear sacling rule 不仅可以在 small 和 large minibath 中 math accuracy ,还可以 match training curves
我们比较了 k minibatch ,每一个batch size 为 n ,学习率为 η 和 一个 minibatch ,size 为 kn, 学习率为 ![]()
第一种的更新函数为 ???
???
第二种的更新函数为 ???
???
在一个很强的假设,即 l(x,wt) 和 l(x,w(t+j)) 的梯度相等的条件的,设置 ![]() ,可以获得
,可以获得![]()
但是这个假设在两种情况下不存在,一种是训练初期,网络变化的很快,第二种是 minibatch size 不可以无限的缩放,虽然结果在很大的 size 时也会保持很高的精度,但是在超过某个点后会迅速的下降
2.2 warmup
上面的第一种情况可以使用 warmup 来解决
Constant warmup:在训练的 first few epochs 使用 low constant learning rate. 这个 strategy 在目标检测和语义分割上fine pre-trained layers together with newly initialized layers 很有效,在 ImageNet kn minibatch size的实验中,先使用小学习率 η 学习 first 5 epoch ,之后使用![]() ,学习。然而当 k 比较大的时候,constant warmup 策略对收敛并不充分,并有可能使训练误差增大,所以提出下面的方法
,学习。然而当 k 比较大的时候,constant warmup 策略对收敛并不充分,并有可能使训练误差增大,所以提出下面的方法
Gradual warmup:逐渐将学习率从小到大增大,可以避免学习率的突然增大,保证训练初期的健康收敛。在 kn 的minibatch size 下,一开始使用 η 学习率,然后在 5 epoch 后逐渐增大至 ![]() ,warmup 后,回到正常的 learning rate schedule.
,warmup 后,回到正常的 learning rate schedule.
2.3 batch normalization with large minibatches
3 Subtleties and Pitfalls of Distributed SGD
在分布式计算中,许多 common implementation errors 会改变超参数的定义,模型虽然可以训练但误差会比较大
- weight decay:
l2 regularization on the weights
如果没有 weight decay , 就会有很多种方法来缩放学习率,例如缩放loss 的梯度项,但是我们发现缩放 loss 和缩放学习率并不等价

- mometum correction:

m 是 momentum 的 decay factor , u 是 update tensor.
还有一种流行的将学习率加到 update tensor 项中

对于 fixed 的学习率,这两个是等价的,但是我们可以发现,u 和学习率是无关的,v 和学习率是有关的,如果学习率改变了,为了使第二个式子和第一个等价 ,v 应该变为![]() 我们将 factor
我们将 factor ![]() 当做 momentum correction,这一项对训练 stabilize 很重要,尤其是在 t+1 的学习率远大于 t 的学习率时,否则的话,history term 就会变得很小使得训练不稳定
当做 momentum correction,这一项对训练 stabilize 很重要,尤其是在 t+1 的学习率远大于 t 的学习率时,否则的话,history term 就会变得很小使得训练不稳定

- gradient aggregation
对于 k 个 worker,每一个 worker 的 minibatch size 为 n,梯度更新的时候除以 kn ,而 loss layer 通常会将每一个 worker 的平均梯度加起来

- data shuffling
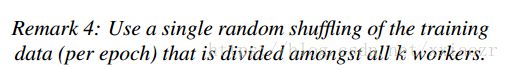
4 Communication
5 Main Results and Analysis
我们的主要结果是使用256 workers 一小时内在 ImageNet 上训练 ResNet-50 网络,获得了和 small minibatch size 同样的精度。使用 linear scaling rule 和 warmup 策略允许我们不用调整超参数和影响精度的情况下缩放 batch size
- minibath size vs error
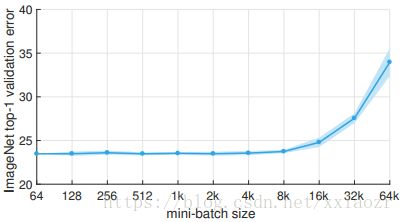
minibath sizes 从64 到 65536(64k),所有的模型都使用 linear scaling rule ,在 kn > 256 时,使用 gradual warmup 策略,从上图可以发现,在 8k 之后验证误差就会变大
- warmup

- Training curves for various minibatch size

比较了不同 minibatch size 的 training curves 和 256 minibatch baseline
- Alternative learning rate rules

对于小批次 256 ,学习率取 0.1 获得最小的 error,但是大的或者小的学习率也可以获得比较好的结果,当在 8k images 上使用 linear scaling rule 时,学习率在 0.1*32 获得最好的结果

当改变学习率时,会改变整个 trianing curves,即使最后的误差是相同的。而线性缩放规则可以在误差和training curves 都相同。
5.4 generalization to detection and segmentation
为了确定 large minibatch 和 small 学到的特征是否一样好,在 COCO detection 和 instance segmentation 上使用 ImageNet pre-training
为了验证 large minibatch pre-training 对 Mask R-CNN 的影响,使用 ResNet-50 训练 ImageNet-1k,minibatch 从 256到 16k,之后使用这个model 初始化 Mask R-CNN

只要 ImageNet validation error 很低,直到 up 8k,detection 的 AP 与之匹配,当数据集切换和任务切换时,用 large minibatch 并不没有什么问题
同样,linear scaling rule 在 Mask R-CNN 上也适用