最新版本的mmdetection2.0 (v2.0.0版本)环境搭建、基于VOC数据来训练自己的数据集、测试
目录
1 数据声明
2 mmdetection环境搭建
2.1 查看Cuda和cudnn的版本
2.2 安装Anaconda
2.3 配置mmdetection
3 准备自己的数据集
3.1 数据标注
3.2 数据划分与存放
3.2.1 VOC2007数据集说明
3.2.2 VOC2007数据集划分与存放
4 训练自己的数据集
4 修改配置文件
4.1.1 修改模型配置文件
4.1.2 修改训练数据的配置文件
4.1.3 修改模型文件中的类别个数
4.1.4 修改测试时的标签类别文件
4.1.5 修改voc.py文件
4.1.6 选择性修改参数
4.2 开始训练模型
4.2.1 快速开始训练
4.2.2 训练命令中的指定参数
4.3 在自己的预训练模型上进行测试
4.3.1 测试命令,使用测试脚本test.py
4.4 用自己训练的模型在图片和视频上做测试
4.4.1 用自己训练的模型在图片上做测试
4.4.2 用自己训练的模型在视频上做测试
4.5 训练结果可视化,以及训练时间计算
4.5.1 可视化训练的loss结果
4.5.2 计算训练的时间
1 数据声明
VOC2007数据集作为训练数据,主要是为了方便快捷的做一个POC的验证,同时节省数据标注的时间,文中会详细阐述如何自定义自己的数据集,以及如何修改数据集。
VOC2007数据官方下载地址:
https://pjreddie.com/projects/pascal-voc-dataset-mirror/

2 mmdetection环境搭建
2.1 查看Cuda和cudnn的版本
参考
在Linux下查看cuda的版本:
cat /usr/local/cuda/version.txt在Linux下查看cudnn的版本:
cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 22.2 安装Anaconda
下载:官方网站
安装:
bash ***.sh2.3 配置mmdetection
参考官方文档进行配置
官方文档链接:https://mmdetection.readthedocs.io/en/latest/install.html
3 准备自己的数据集
3.1 数据标注
数据标注工具使用LabelImg,然后把所有的数据都标注成VOC数据格式,关于如何LabelImg工具如何使用,请参考我的博客:
LabelImg教程详细使用
- 所有的数据图片放在:JPEGImage文件夹
- 所有的数据图片的标签文件放在:Annotation文件夹
3.2 数据划分与存放
3.2.1 VOC2007数据集说明
VOC数据集共包含:训练集(5011幅),测试集(4952幅),共计9963幅图,共包含20个种类。

3.2.2 VOC2007数据集划分与存放
数据集存放在如下机构中:
- 所有的
数据标签存放在:./data/VOCdevkit/VOC2007/Annotations - 所有的
图片数据存放在:./data/VOCdevkit/VOC2007/JPEGImage
./data
└── VOCdevkit
└── VOC2007
├── Annotations # 标注的VOC格式的xml标签文件
├── JPEGImages # 数据集图片
├── ImageSet
│ └── Main
│ ├── test.txt # 划分的测试集
│ ├── train.txt # 划分的训练集
│ ├── trainval.txt
│ └── val.txt # 划分的验证集
├── cal_txt_data_num.py # 用于统计text.txt、train.txt等数据集的个数
└── split_dataset.py # 数据集划分脚本1、数据集的划分,使用:split_dataset.py脚本
脚本内容:
import os
import random
trainval_percent = 0.8
train_percent = 0.8
xmlfilepath = 'Annotations'
txtsavepath = 'ImageSets\Main'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('ImageSets/Main/trainval.txt', 'w')
ftest = open('ImageSets/Main/test.txt', 'w')
ftrain = open('ImageSets/Main/train.txt', 'w')
fval = open('ImageSets/Main/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
执行完该脚本后,会在./data/VOCdevkit/VOC2007/ImageSets/Main目录下,生成四个txt文件:
- train.txt
- trainval.txt
- test.txt
- val.txt
每个txt文件中存储的都是图片的名字(不含图片名字的后缀.jpg),例如:trian.txt中的内容如下:
000005
000007
000016
000019
000020
000021
000024
000046
000052
...
当然你也可以把数据放到其他目录,然后使用软连接的形式连接到./mmdetection/data目录下():
ln -s /HDD/VOCdevkit ./data # 就是把实体目录VOCdevkit做一个链接放到 ./data目录下2、统计划分数据集数据的个数,使用:cal_txt_data_num.py脚本
脚本内容:
import sys
import os
# 计算txt中有多少个数据,即有多上行
names_txt = os.listdir('./ImageSets/Main')
#print(names_txt)
for name_txt in names_txt:
with open(os.path.join('./ImageSets/Main', name_txt)) as f:
lines = f.readlines()
print(('文件 %s'%name_txt).ljust(35) + ("共有数据:%d个"%len(lines)).ljust(50))
执行结果,如下(显示了我数据集的划分情况):
文件 test.txt 共有数据:1003个
文件 val.txt 共有数据:802个
文件 train.txt 共有数据:3206个
文件 trainval.txt 共有数据:4008个
当然你也可以用coco格式数据集,但是需要把labelImg标注的xml标签转化一下(参考1, 参考2 格式转换)
至此,数据集的准备工作已经全部完成
4 训练自己的数据集
在数据进行训练前,需要先进行一些配置文件的修改工作
4 修改配置文件
4.1.1 修改模型配置文件
修改:./mmdetection/configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py
faster_rcnn_r50_fpn_1x_coco.py脚本内容的原始内容
_base_ = [
'../_base_/models/faster_rcnn_r50_fpn.py',
'../_base_/datasets/coco_detection.py',
'../_base_/schedules/schedule_1x.py', '../_base_/default_runtime.py'
]
faster_rcnn_r50_fpn_1x_coco.py脚本内容的修改如下(使用VOC数据格式)
_base_ = [
'../_base_/models/faster_rcnn_r50_fpn.py',
'../_base_/datasets/voc0712.py',
'../_base_/schedules/schedule_1x.py', '../_base_/default_runtime.py'
]
之前是把模型的配置文件,和模型结构都是定义到faster_rcnn_r50_fpn_1x_coco.py这种脚本文件中,最近mmdetection项目代码更新,只不过是做了更好的封装,把这文件进行了拆分,放到了mmdetection/configs/_base_ 目录下,所以要有些内容就要到_base_目录下的文件中进行修改,_base_目录结构如下:
_base_/
├── datasets # 定义数据路径等信息
│ ├── cityscapes_detection.py
│ ├── cityscapes_instance.py
│ ├── coco_detection.py
│ ├── coco_instance.py
│ ├── coco_instance_semantic.py
│ ├── voc0712.py
│ └── wider_face.py
├── default_runtime.py
├── models # 定义模型的配置信息
│ ├── cascade_mask_rcnn_r50_fpn.py
│ ├── cascade_rcnn_r50_fpn.py
│ ├── faster_rcnn_r50_caffe_c4.py
│ ├── faster_rcnn_r50_fpn.py
│ ├── fast_rcnn_r50_fpn.py
│ ├── mask_rcnn_r50_caffe_c4.py
│ ├── mask_rcnn_r50_fpn.py
│ ├── retinanet_r50_fpn.py
│ ├── rpn_r50_caffe_c4.py
│ ├── rpn_r50_fpn.py
│ └── ssd300.py
└── schedules # 定义训练策略信息
├── schedule_1x.py
├── schedule_20e.py
└── schedule_2x.py
../_base_/models/faster_rcnn_r50_fpn.py:定义模型文件
如果你想使用../_base_/datasets/coco_detection.py:定义训练数据路径等../_base_/schedules/schedule_1x.py:定义学习策略,例如leaning_rate、epoch等../_base_/default_runtime.py:定义一些日志等其他信息
4.1.2 修改训练数据的配置文件
修改:./mmdetection/configs/_base_/datasets/voc712.py
因为我们使用的是VOC2007数据,因此只要把其中含有VOC2012路径注释即可,修改后的内容如下:
# dataset settings
dataset_type = 'VOCDataset'
data_root = 'data/VOCdevkit/'
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True),
dict(type='Resize', img_scale=(1000, 600), keep_ratio=True),
dict(type='RandomFlip', flip_ratio=0.5),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size_divisor=32),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels']),
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(1000, 600),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size_divisor=32),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img']),
])
]
data = dict(
samples_per_gpu=2,
workers_per_gpu=2,
train=dict(
type='RepeatDataset',
times=3,
# dataset=dict(
# type=dataset_type,
# ann_file=[
# data_root + 'VOC2007/ImageSets/Main/trainval.txt',
# data_root + 'VOC2012/ImageSets/Main/trainval.txt'
# ],
# img_prefix=[data_root + 'VOC2007/', data_root + 'VOC2012/'],
# pipeline=train_pipeline)),
# 把含有VOC2012的路径去掉
dataset=dict(
type=dataset_type,
ann_file=[
data_root + 'VOC2007/ImageSets/Main/trainval.txt',
],
img_prefix=[data_root + 'VOC2007/'],
pipeline=train_pipeline)),
val=dict(
type=dataset_type,
ann_file=data_root + 'VOC2007/ImageSets/Main/test.txt',
img_prefix=data_root + 'VOC2007/',
pipeline=test_pipeline),
test=dict(
type=dataset_type,
ann_file=data_root + 'VOC2007/ImageSets/Main/test.txt',
img_prefix=data_root + 'VOC2007/',
pipeline=test_pipeline))
evaluation = dict(interval=1, metric='mAP')
4.1.3 修改模型文件中的类别个数
修改:./mmdetection/configs/_base_/models/faster_rcnn_r50_fpn.py
因为这里使用的是VOC2007数据集,一共有20个类别,因此这里把``faster_rcnn_r50_fpn.py第46行的num_classes`的值改为20,根据自己的分类的个数,有多少类就改成多少,修改完如下所示:
model = dict(
type='FasterRCNN',
pretrained='torchvision://resnet50',
backbone=dict(
type='ResNet',
depth=50,
num_stages=4,
out_indices=(0, 1, 2, 3),
frozen_stages=1,
norm_cfg=dict(type='BN', requires_grad=True),
norm_eval=True,
style='pytorch'),
neck=dict(
type='FPN',
in_channels=[256, 512, 1024, 2048],
out_channels=256,
num_outs=5),
rpn_head=dict(
type='RPNHead',
in_channels=256,
feat_channels=256,
anchor_generator=dict(
type='AnchorGenerator',
scales=[8],
ratios=[0.5, 1.0, 2.0],
strides=[4, 8, 16, 32, 64]),
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[.0, .0, .0, .0],
target_stds=[1.0, 1.0, 1.0, 1.0]),
loss_cls=dict(
type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),
loss_bbox=dict(type='L1Loss', loss_weight=1.0)),
roi_head=dict(
type='StandardRoIHead',
bbox_roi_extractor=dict(
type='SingleRoIExtractor',
roi_layer=dict(type='RoIAlign', out_size=7, sample_num=0),
out_channels=256,
featmap_strides=[4, 8, 16, 32]),
bbox_head=dict(
type='Shared2FCBBoxHead',
in_channels=256,
fc_out_channels=1024,
roi_feat_size=7,
num_classes=20, # 把类别个数改成自己数据集的类别,如果是voc2007数据集就改成20
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[0., 0., 0., 0.],
target_stds=[0.1, 0.1, 0.2, 0.2]),
reg_class_agnostic=False,
loss_cls=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0),
loss_bbox=dict(type='L1Loss', loss_weight=1.0))))
# model training and testing settings
train_cfg = dict(
rpn=dict(
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.7,
neg_iou_thr=0.3,
min_pos_iou=0.3,
match_low_quality=True,
ignore_iof_thr=-1),
sampler=dict(
type='RandomSampler',
num=256,
pos_fraction=0.5,
neg_pos_ub=-1,
add_gt_as_proposals=False),
allowed_border=-1,
pos_weight=-1,
debug=False),
rpn_proposal=dict(
nms_across_levels=False,
nms_pre=2000,
nms_post=1000,
max_num=1000,
nms_thr=0.7,
min_bbox_size=0),
rcnn=dict(
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.5,
neg_iou_thr=0.5,
min_pos_iou=0.5,
match_low_quality=False,
ignore_iof_thr=-1),
sampler=dict(
type='RandomSampler',
num=512,
pos_fraction=0.25,
neg_pos_ub=-1,
add_gt_as_proposals=True),
pos_weight=-1,
debug=False))
test_cfg = dict(
rpn=dict(
nms_across_levels=False,
nms_pre=1000,
nms_post=1000,
max_num=1000,
nms_thr=0.7,
min_bbox_size=0),
rcnn=dict(
score_thr=0.05, nms=dict(type='nms', iou_thr=0.5), max_per_img=100)
# soft-nms is also supported for rcnn testing
# e.g., nms=dict(type='soft_nms', iou_thr=0.5, min_score=0.05)
)
注意:
之前的代码版本是,num_classes改成类别+1,也就把背景也算作一类,在mmdetection V2.0.0版本,背景不在作为一类,因此不用再加1,有多少个类别就写多少
4.1.4 修改测试时的标签类别文件
修改:./mmdetection/mmdet/core/evaluation/class_names.py
修改mmdetection/mmdet/core/evaluation/class_names.py下的class_names.py中的voc_classes,将 其改为要训练的数据集的类别名称。如果不改的话,最后测试的结果的名称还会是’aeroplane’, ‘bicycle’, ‘bird’, ‘boat’,…这些。因为我使用的是voc2007因此可以不做改动,你可以根据自己的类别进行修改:
def voc_classes():
return [
'aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat',
'chair', 'cow', 'diningtable', 'dog', 'horse', 'motorbike', 'person',
'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor'
]
注意:
如果只有一个类别,需要加上一个逗号,否则将会报错,例如只有一个类别,如下:
def voc_classes():
return ['aeroplane', ]
4.1.5 修改voc.py文件
修改:mmdetection/mmdet/datasets/voc.py
修改mmdetection/mmdet/datasets/voc.py下的voc.py中的CLASSES,将 其改为要训练的数据集的类别名称。如果不改的话,最后测试的结果的名称还会是’aeroplane’, ‘bicycle’, ‘bird’, ‘boat’,…这些。因为我使用的是voc2007因此可以不做改动,你可以根据自己的类别进行修改:
class VOCDataset(XMLDataset):
CLASSES = ('aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car',
'cat', 'chair', 'cow', 'diningtable', 'dog', 'horse',
'motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train',
'tvmonitor')
注意:
如果只有一个类别,需要加上一个逗号,否则将会报错,例如只有一个类别,如下:
class VOCDataset(XMLDataset):
CLASSES = ('aeroplane', )
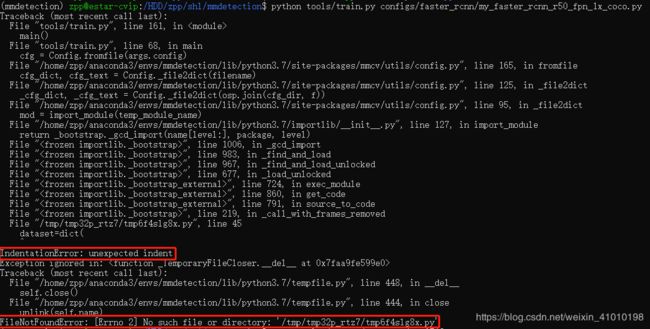
提示错误:
1、IndentationError: unexpected indent
2、FileNotFoundError: [Errno 2] No such file or directory: '/tmp/tmp32p_rtz7/tmp6f4slg8x.py'
从上面看提示了两个错误,我一开始关注的是第二个错误,然后就没有找到错误的原因,后面看到上面还有一个错误:IndentationError: unexpected indent,这种错误一般是由于空格和Tab空格混用导致的,看错误上面的dataset=dict(可以定位到这个错误的位置,然后进行修改。
因此建议,在vi编辑器中全部使用空格键进行缩进,最好是在编辑器中,例如Pycharm中改好在再替换,一般不会出现这种错误。
到此为止,环境的搭建、数据的准备、配置文件的修改已经全部准备完毕,下面就让我们开始训练吧
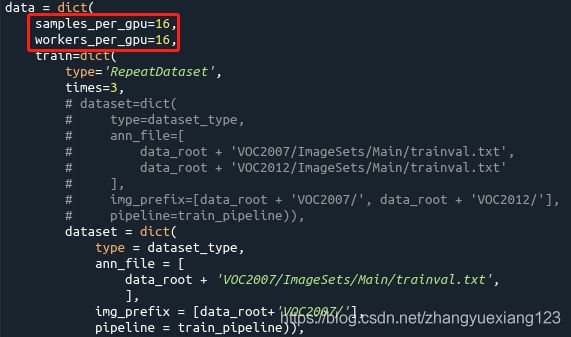
4.1.6 选择性修改参数
修改batch size:mmdetection/configs/_base_/datasets/voc0712.py
mmdetection里的batch size修改为了samples_per_gpu,所以,直接修改这个字段的值即可
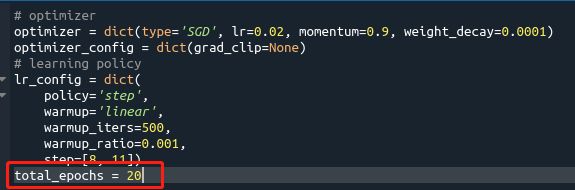
修改total_epochs:configs/_base_/schedules/schedule_1x.py
4.2 开始训练模型
4.2.1 快速开始训练
关于多GPU训练,请参考:这篇博客
1、训练命令:
python tools/train.py ./configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py我是在VOC2007数据集上,2080Ti(11G显存,实际使用显存大概4G)的显卡上训练12epoch,训练时间3个小时

结果信息:
+-------------+-----+------+--------+-------+
| class | gts | dets | recall | ap |
+-------------+-----+------+--------+-------+
| aeroplane | 48 | 113 | 0.708 | 0.646 |
| bicycle | 74 | 145 | 0.824 | 0.773 |
| bird | 89 | 205 | 0.640 | 0.524 |
| boat | 75 | 175 | 0.587 | 0.464 |
| bottle | 99 | 171 | 0.545 | 0.418 |
| bus | 41 | 111 | 0.732 | 0.573 |
| car | 247 | 370 | 0.854 | 0.799 |
| cat | 84 | 198 | 0.869 | 0.735 |
| chair | 181 | 355 | 0.470 | 0.359 |
| cow | 53 | 174 | 0.849 | 0.577 |
| diningtable | 33 | 158 | 0.818 | 0.547 |
| dog | 99 | 352 | 0.919 | 0.739 |
| horse | 76 | 213 | 0.868 | 0.762 |
| motorbike | 74 | 182 | 0.905 | 0.813 |
| person | 881 | 1477 | 0.829 | 0.757 |
| pottedplant | 127 | 187 | 0.425 | 0.323 |
| sheep | 76 | 153 | 0.579 | 0.491 |
| sofa | 48 | 214 | 0.833 | 0.547 |
| train | 54 | 140 | 0.759 | 0.673 |
| tvmonitor | 58 | 117 | 0.690 | 0.582 |
+-------------+-----+------+--------+-------+
| mAP | | | | 0.605 |
+-------------+-----+------+--------+-------+
2020-05-27 14:09:53,057 - mmdet - INFO - Epoch [12][6013/6013] lr: 0.00020, mAP: 0.6050
2、训练完成在工作目录下生成模型文件和日志文件
训练完成之后,训练的模型文件和日志文件等会被保存在./mmdetection/work_dir目录下(work_dir目录不指定会自动创建,也可以用参数--work-dir自己指定):
work_dirs/
└── faster_rcnn_r50_fpn_1x_coco
├── 20200527_105051.log
├── 20200527_105051.log.json
├── epoch_10.pth
├── epoch_11.pth
├── epoch_12.pth
├── epoch_1.pth
├── epoch_2.pth
├── epoch_3.pth
├── epoch_4.pth
├── epoch_5.pth
├── epoch_6.pth
├── epoch_7.pth
├── epoch_8.pth
├── epoch_9.pth
├── latest.pth -> epoch_12.pth
└── faster_rcnn_r50_fpn_1x_coco.py # 把之前的列表中的三个文件的代码都写到这个文件中
从上面生成的文件可以看出:每训练完一轮都会保存一个epoch_x.pth模型,最新的也是最终的模型会被保存为latest.pth,同时会生成两个日志文件:
- 20200527_105051.log 日志内容就是训练时输出的信息:

- 20200527_105051.log.json 日志内容是训练过程中的损失、学习率、精度等信息,主要是为了数据可视化展示,方便调试:

注意1:
在训练的过程中程序终止,报错:IndexError: list index out of range
,这个错误是由于类别(num_classes)没有修改导致的,同时类别的修改也发生变化,现在的类别已经不包括背景(background)

注意2:
这次我使用的是自己的数据集进行训练,一共两类:
- hard_hat
- other
训练的时候没有报错,但是出现异常,所有的训练损失都变成了0,每一轮的label也不是自己设置的label,而变成了VOC的label,这个问题是因为少了一个逗号,我也不知道为什么会因为一个逗号而引发一场血案:在/mmdetection/configs/_base_/datasets/voc0712.py中的'VOC2007/ImageSets/Main/trainval.txt'后的逗号一定要加上,否则会报同样的错误。
异常信息:
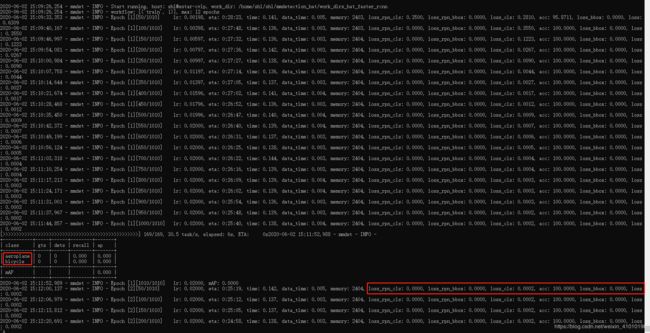
问题解决: 把后面的逗号补上
dataset=dict(
type=dataset_type,
ann_file=[
data_root + 'VOC2007/ImageSets/Main/trainval.txt', ],
img_prefix=[data_root + 'VOC2007/'],
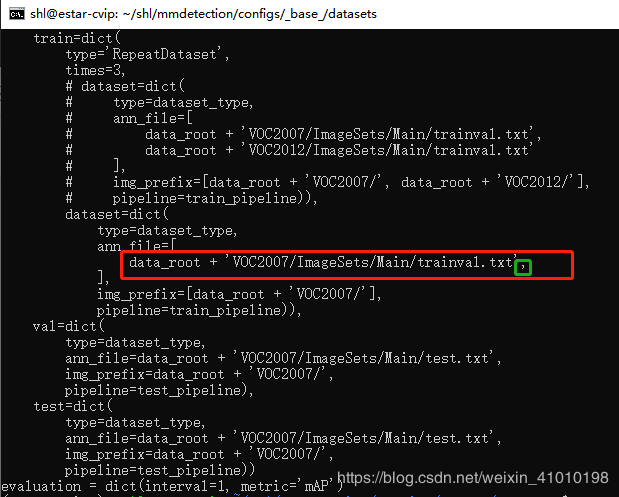
4.2.2 训练命令中的指定参数
训练命令:
python python tools/train.py ./configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py--work-dir:指定训练保存模型和日志的路径--resume-from:从预训练模型chenkpoint中恢复训练--no-validate:训练期间不评估checkpoint--gpus:指定训练使用GPU的数量(仅适用非分布式训练)--gpu-ids: 指定使用哪一块GPU(仅适用非分布式训练)--seed:随机种子--deterministic:是否为CUDNN后端设置确定性选项--options: arguments in dict--launcher: {none,pytorch,slurm,mpi} job launcher--local_rank: LOCAL_RANK--autoscale-lr: automatically scale lr with the number of gpus
加其他参数的训练命令:
1、自己指定模型保存路径
python tools/train.py ./configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py --work-dir my_faster
2、指定GPU数量
python tools/train.py ./configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py --gpus 1 --no-validate --work-dir my_faster
4.3 在自己的预训练模型上进行测试
4.3.1 测试命令,使用测试脚本test.py
运行下面的测试命令前,先安装imagecorruptions包:
pip install imagecorruptions -i http://mirrors.aliyun.com/pypi/simple --trusted-host mirrors.aliyun.com
测试命令参照官网:https://mmdetection.readthedocs.io/en/latest/getting_started.html#inference-with-pretrained-models
python tools/test.py configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py work_dirs/faster_rcnn_r50_fpn_1x_coco/latest.pth --eval mAP
configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py:是模型文件./work_dirs/my_faster_rcnn_r50_fpn_1x_coco/latest.pth:是我们自己训练保存的模型
如下是我测试的结果显示(test.txt 测试集图片有347张):
[>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] 347/347, 29.3 task/s, elapsed: 12s, ETA: 0s
+--------------------+-----+------+--------+-------+
| class | gts | dets | recall | ap |
+--------------------+-----+------+--------+-------+
| transverse_defect | 268 | 323 | 0.888 | 0.787 |
| vertical_defect | 4 | 4 | 0.750 | 0.682 |
| joint | 89 | 101 | 0.910 | 0.876 |
| normal_weld_seam | 87 | 115 | 0.920 | 0.815 |
| abnormal_weld_seam | 0 | 0 | 0.000 | 0.000 |
| head_noise | 12 | 17 | 0.167 | 0.182 |
| web_crack | 70 | 91 | 0.800 | 0.667 |
| bolt_hole | 662 | 785 | 0.977 | 0.895 |
| bolt_hole_crack | 111 | 131 | 0.973 | 0.906 |
| hole | 375 | 467 | 0.915 | 0.824 |
| web_noise | 21 | 26 | 0.667 | 0.624 |
| base_defect | 75 | 87 | 0.907 | 0.865 |
| base_noise | 0 | 0 | 0.000 | 0.000 |
| other_head_defect | 23 | 47 | 0.739 | 0.550 |
| fish_scale_pattern | 0 | 0 | 0.000 | 0.000 |
| LER | 79 | 252 | 0.684 | 0.317 |
+--------------------+-----+------+--------+-------+
| mAP | | | | 0.692 |
+--------------------+-----+------+--------+-------+
使用--show-dir 参数,可以把测试的检测图片检测结果保存到指定文件夹中,如下命令:
python tools/test.py ./configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py ./work_dirs_hat_faster_rcnn/latest.pth --out ./result.pkl --show-dir test_hat_result
生成的测试结果图片会被保存到test_hat_result/JPEGImages文件夹下,部分测试结果如下:

4.4 用自己训练的模型在图片和视频上做测试
4.4.1 用自己训练的模型在图片上做测试
测试的脚本为:./mmdetection/demo/image_demo.py
from argparse import ArgumentParser
from mmdet.apis import inference_detector, init_detector, show_result_pyplot
def main():
parser = ArgumentParser()
parser.add_argument('img', help='Image file')
parser.add_argument('config', help='Config file')
parser.add_argument('checkpoint', help='Checkpoint file')
parser.add_argument(
'--device', default='cuda:0', help='Device used for inference')
parser.add_argument(
'--score-thr', type=float, default=0.3, help='bbox score threshold')
args = parser.parse_args()
# build the model from a config file and a checkpoint file
model = init_detector(args.config, args.checkpoint, device=args.device)
# test a single image
result = inference_detector(model, args.img)
# show the results
show_result_pyplot(model, args.img, result, score_thr=args.score_thr)
if __name__ == '__main__':
main()
然后在命令行中输入命令进行测试:
python image_demo.py ../test.jpg ../configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py ../work_dirs/faster_rcnn_r50_fpn_1x_coco/latest.pth
原图:

下面是我做的其他检测任务的一些检测效果:
4.4.2 用自己训练的模型在视频上做测试
4.5 训练结果可视化,以及训练时间计算
4.5.1 可视化训练的loss结果
1、可视化命令:
python tools/analyze_logs.py plot_curve ./1_work_dir_gfl_hat_hair_beard/20200805_154359.log.json --keys loss_cls loss_ bbox loss_dfl --out ./plot_result/1_gfl_hat_hair_beard

2、可视化命令参数介绍:
plot_curve:该参数后跟的是训练保存的json文件--keys:后面跟的是要绘制的损失关键字,可以跟多个值--out:后面跟的是绘制保存的结果,可以保存成png图片,也可以保存成pdf
3、绘图的结果:
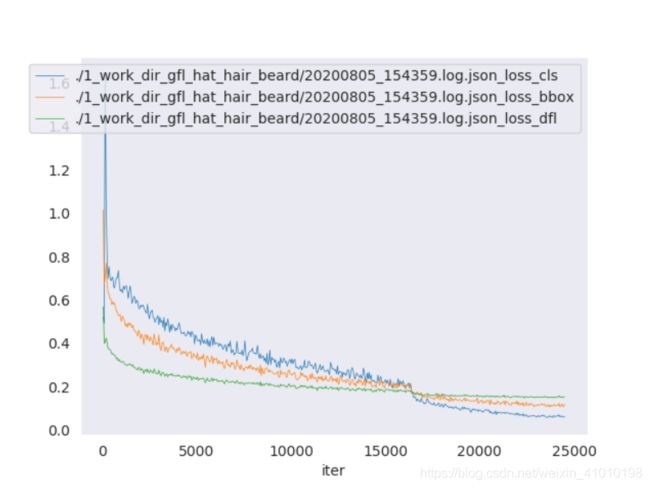
4.5.2 计算训练的时间
计算训练时间的命令:
python tools/analyze_logs.py cal_train_time ./1_work_dir_gfl_hat_hair_beard/20200805_154359.log.json

参考1: # 内容比较详细
参考2:https://blog.csdn.net/syysyf99/article/details/96574325
参考3:https://blog.csdn.net/weicao1990/article/details/93484603
参考4