比特币源码分析--PBFT算法
上一篇文章介绍了CFT的经典算法paxos,paxos,raft这类非拜占庭模型的共识算法比较适用于私链,但是对于公链和联盟链,因为必须要考虑集群中存在恶意节点的情况,所以需要不同的容错算法,本文要介绍的就是BFT的经典算法PBFT算法(Practical Byzantine Fault Tolerance,翻译过来就是实用拜占庭容错)
1 PBFT介绍
1.1 拜占庭将军问题
拜占庭将军问题最早是由Lamport(没错,就是上一篇文章中发明paxos算法的那位神仙)在1982年与另外两位作者一起发表的论文《The Byzantine Generals Problem》中提出的,这个问题的描述如下:
拜占庭是古代东罗马帝国的首都,当时东罗马帝国国土辽阔,为了防御外敌入侵,帝国的每块封地都驻扎一支由将军统领的军队,每个军队都相隔很远,将军与将军之间只能靠派出的信使传递消息。 当发生战事的时候,拜占庭军队内所有将军必需就进攻还是防守达成共识,只有有赢的机会时才去攻打敌人的阵营。但是这些将军中可能存在叛徒,另外派出的信使也有可能被敌人俘虏(消息传达不到或者沦为奸细故意向其他将军传递假消息),拜占庭将军问题就是在已知有将军是叛徒的情况下,剩余的忠诚的将军如何达成一致协议。
Lamport在其论文中证明:假设将军总数为N,叛变的将军数为f,则在N >= 3f + 1时,上述的拜占庭将军问题可以解决,将军达成共识的时间复杂度为O(N^(f+1)),即指数级的复杂度。
首先来简单的验证一下这个结论:
假设总共有3个将军A,B,C,其中1个将军叛变,按照上面的结论,因为不满足N >= 3f + 1的条件,因此不可能达成一致:
假设A是叛变者同时也是提案者,他派出两名信使分别告诉B说进攻,告诉C说防守,结果最终C会得到两份矛盾的消息:A的信使告诉他说防守,但是B的信使又告诉他说进攻,无法形成共识;
假设叛变的将军是A,但提案者是B,B派出信使告诉A和C某日某时某刻发起进攻,但是A收到消息后可以篡改,他可以告诉C说收到的是防守的指令,同样无法达成共识;
如果加1名将军,总共A,B,C,D四名将军,同样只有1名将军叛变,此时满足N >= 3f + 1的条件,我们再来验证看是否能达成一致:
假设A是提案者,同时也是叛徒,此时无论他怎么安排,剩余的3名将军中总会有至少2名的将军得到相同的指令,假设B和C得到的是A发出的进攻指令,而D得到的是A发出的防守的指令,根据少数服从多数的原则,最终B,C,D都会达成共识:
D收到A的防守指令,但是收到B和C的进攻指令,少数服从多数,D认为要进攻;
B收到A和C的进攻指令,收到D的防守指令,少数服从多数,B也选择进攻;
C收到A和B的进攻指令,收到D的防守指令,同样C也决定进攻;
最终B,C,D都进攻,A的诡计无法得逞。
通过上面的简单验证,我们已经了解到N >= 3f + 1确实能做到存在拜占庭节点的分布式系统的共识,换句话说PBFT算法最多可以容许不超过(N-1) / 3个问题节点。作者Lamport凭借他在分布式系统共识算法上的杰出成绩,获得了2013年的图灵奖。
1.2 PBFT算法
虽然Lamport的论文中给出了解决拜占庭将军问题的算法,但是由于算法的时间复杂度是指数级,很难落地到实际的项目中。从1982年Lamport提出拜占庭将军问题起,对拜占庭将军的问题的研究一直没有停止,期间也出过很多的学术论文和解决算法,但效率始终没能得到提升,直到1999年,Miguel Castro和Babara Liskov发表了论文《Practical Byzantine Falut Tolerance》,首次提出了PBFT算法,将拜占庭将军问题的时间复杂度从指数及降到了多项式级(O(N^2))。
PBFT算法目前在许多区块链项目中都有运用,例如国内的迅雷,腾讯等公司的区块链使用的就是PBFT算法(应该是对算法进行了优化),超级账本的Farbic v0.6版本也使用了PBFT作为其共识算法。
2 PBFT算法的流程
2.1 pbft三阶段共识
本节我们描述一下PBFT算法的流程,关于PBFT算法,网上有大量的介绍,建议英文和数学比较扎实的学霸可以直接下载原论文学习。
PBFT算法的过程可以分为以下几步:
(1) 客户的请求发送给主节点(primary);
(2) 主节点对请求进行编号,然后将请求发送给从节点;
(3) 从节点开始三阶段的pbft处理流程;
(4) 从节点返回响应给客户端;
(5) 如果客户端收到来自f+1个节点的相同的响应消息,则共识完成,执行请求;
上面最核心的就是第(3)步中节点执行三阶段的处理:pre-prepare阶段,prepare阶段和commit阶段:
(1) pre-prepare阶段:主节点向其他节点广播preprepare消息, 从节点可能接受此消息也可能拒绝,从节点拒绝的原因可能是请求的序号不在高低水位(高低水位的概念稍后说明)之间,也可能是节点已经收到序号和视图编号相同的请求,但是摘要不一致;
(2) prepare阶段:如果从节点接受pre-prepare消息,则向其他节点发送prepare消息,同时自己也接收其他节点广播的prepare消息,在指定的超时时间内,一旦节点收到2f个不同节点的prepare,则进入第三阶段;
(3) commit阶段:如果节点收到了2f个不同节点的prepare消息后,向其他节点发送commit消息,同时接受其他节点广播的commit消息,如果节点收到了包括自己在内的2f+1个commit消息,则三阶段完成。
我们用原论文中的图来看一下,基本上所有关于PBFT算法的文章中都会引用这个图:
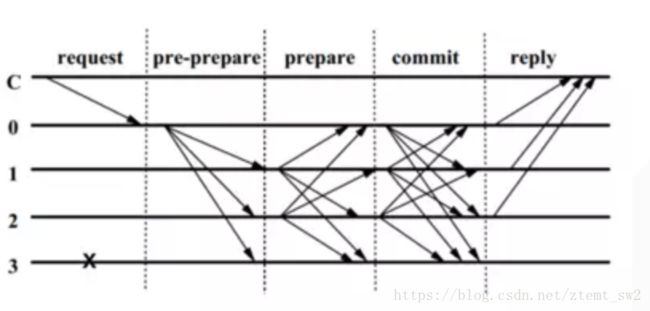
图中的C为客户端,0为主节点,带有X的3为问题节点。
在来解释一下PBFT算法中的高低水位的概念,之前提到,主节点发送的pre-prepare消息,如果请求编号不在高低水位之间,从节点会拒绝,这里的高低水位的概念如下:
(1) Check Point:检查点,是指当前节点处理的最新请求的编号,例如节点当前正在共识的请求的编号是100,那么对于该节点而言,其Check Point就是100;
(2) Stable check point:稳定检查点,是指多数节点(2f + 1)已经共识完成的请求的最大编号。稳定检查点的主要作用就是减少内存占用,因为PBFT要求节点记住之前已经共识过的请求,随着时间推移,这些数据占用的内存会越来越多,因此需要有删除机制,删除的时候就可以把稳定检查点之前的请求全删掉(因为是大部分节点都已经共识过了的)。
(3) 高低水位:假设当前的稳定检查点是100,则低水位h即为100,而高水位H = h + L,L是一个可设定的值。
以上简单介绍了pbft三阶段共识的流程,接下来我们来看看pbft实现的一个例子。超级账本的fabric 0.6版本采用了PBFT作为共识算法,我们结合其源码来看看。源代码可以从github上下载:
fabric源码
fabric的pbft实现位于consensus/pbft目录下,如果抽丝剥茧,其核心的类就是pbftCore,pbft算法的主要内容基本上都在这个类里了:
type pbftCore struct {
// internal data
internalLock sync.Mutex
executing bool // signals that application is executing
idleChan chan struct{} // Used to detect idleness for testing
injectChan chan func() // Used as a hack to inject work onto the PBFT thread, to be removed eventually
consumer innerStack
// PBFT data
activeView bool // view change happening
byzantine bool // whether this node is intentionally acting as Byzantine; useful for debugging on the testnet
f int // max. number of faults we can tolerate
N int // max.number of validators in the network
h uint64 // low watermark
id uint64 // replica ID; PBFT `i`
K uint64 // checkpoint period
logMultiplier uint64 // use this value to calculate log size : k*logMultiplier
L uint64 // log size
lastExec uint64 // last request we executed
replicaCount int // number of replicas; PBFT `|R|`
seqNo uint64 // PBFT "n", strictly monotonic increasing sequence number
view uint64 // current view
chkpts map[uint64]string // state checkpoints; map lastExec to global hash
pset map[uint64]*ViewChange_PQ //已经完成prepare阶段的请求
qset map[qidx]*ViewChange_PQ //已经完成pre-prepare阶段的请求
skipInProgress bool // Set when we have detected a fall behind scenario until we pick a new starting point
stateTransferring bool // Set when state transfer is executing
highStateTarget *stateUpdateTarget // Set to the highest weak checkpoint cert we have observed
hChkpts map[uint64]uint64 // highest checkpoint sequence number observed for each replica
currentExec *uint64 // currently executing request
timerActive bool // is the timer running?
vcResendTimer events.Timer // timer triggering resend of a view change
newViewTimer events.Timer // timeout triggering a view change
requestTimeout time.Duration // progress timeout for requests
vcResendTimeout time.Duration // timeout before resending view change
newViewTimeout time.Duration // progress timeout for new views
newViewTimerReason string // what triggered the timer
lastNewViewTimeout time.Duration // last timeout we used during this view change
broadcastTimeout time.Duration // progress timeout for broadcast
outstandingReqBatches map[string]*RequestBatch // track whether we are waiting for request batches to execute
nullRequestTimer events.Timer // timeout triggering a null request
nullRequestTimeout time.Duration // duration for this timeout
viewChangePeriod uint64 // period between automatic view changes
viewChangeSeqNo uint64 // next seqNo to perform view change
missingReqBatches map[string]bool // for all the assigned, non-checkpointed request batches we might be missing during view-change
// implementation of PBFT `in`
reqBatchStore map[string]*RequestBatch // track request batches
certStore map[msgID]*msgCert // track quorum certificates for requests
checkpointStore map[Checkpoint]bool // track checkpoints as set
viewChangeStore map[vcidx]*ViewChange // track view-change messages
newViewStore map[uint64]*NewView // track last new-view we received or sent
}代码中的注释比较详细。pbftCore可以理解为一个状态机:接受消息,然后进行处理,更改状态,我们只看其关键函数就能一窥一二:
// allow the view-change protocol to kick-off when the timer expires
func (instance *pbftCore) ProcessEvent(e events.Event) events.Event {
var err error
logger.Debugf("Replica %d processing event", instance.id)
switch et := e.(type) {
case viewChangeTimerEvent:
logger.Infof("Replica %d view change timer expired, sending view change: %s", instance.id, instance.newViewTimerReason)
instance.timerActive = false
instance.sendViewChange()
case *pbftMessage:
return pbftMessageEvent(*et)
case pbftMessageEvent:
msg := et
logger.Debugf("Replica %d received incoming message from %v", instance.id, msg.sender)
next, err := instance.recvMsg(msg.msg, msg.sender)
if err != nil {
break
}
return next
case *RequestBatch:
err = instance.recvRequestBatch(et)
case *PrePrepare:
err = instance.recvPrePrepare(et)
case *Prepare:
err = instance.recvPrepare(et)
case *Commit:
err = instance.recvCommit(et)
case *Checkpoint:
return instance.recvCheckpoint(et)
case *ViewChange:
return instance.recvViewChange(et)
case *NewView:
return instance.recvNewView(et)
case *FetchRequestBatch:
err = instance.recvFetchRequestBatch(et)
case returnRequestBatchEvent:
return instance.recvReturnRequestBatch(et)
case stateUpdatedEvent:
update := et.chkpt
instance.stateTransferring = false
// If state transfer did not complete successfully, or if it did not reach our low watermark, do it again
if et.target == nil || update.seqNo < instance.h {
if et.target == nil {
logger.Warningf("Replica %d attempted state transfer target was not reachable (%v)", instance.id, et.chkpt)
} else {
logger.Warningf("Replica %d recovered to seqNo %d but our low watermark has moved to %d", instance.id, update.seqNo, instance.h)
}
if instance.highStateTarget == nil {
logger.Debugf("Replica %d has no state targets, cannot resume state transfer yet", instance.id)
} else if update.seqNo < instance.highStateTarget.seqNo {
logger.Debugf("Replica %d has state target for %d, transferring", instance.id, instance.highStateTarget.seqNo)
instance.retryStateTransfer(nil)
} else {
logger.Debugf("Replica %d has no state target above %d, highest is %d", instance.id, update.seqNo, instance.highStateTarget.seqNo)
}
return nil
}
logger.Infof("Replica %d application caught up via state transfer, lastExec now %d", instance.id, update.seqNo)
instance.lastExec = update.seqNo
instance.moveWatermarks(instance.lastExec) // The watermark movement handles moving this to a checkpoint boundary
instance.skipInProgress = false
instance.consumer.validateState()
instance.Checkpoint(update.seqNo, update.id)
instance.executeOutstanding()
case execDoneEvent:
instance.execDoneSync()
if instance.skipInProgress {
instance.retryStateTransfer(nil)
}
// We will delay new view processing sometimes
return instance.processNewView()
case nullRequestEvent:
instance.nullRequestHandler()
case workEvent:
et() // Used to allow the caller to steal use of the main thread, to be removed
case viewChangeQuorumEvent:
logger.Debugf("Replica %d received view change quorum, processing new view", instance.id)
if instance.primary(instance.view) == instance.id {
return instance.sendNewView()
}
return instance.processNewView()
case viewChangedEvent:
// No-op, processed by plugins if needed
case viewChangeResendTimerEvent:
if instance.activeView {
logger.Warningf("Replica %d had its view change resend timer expire but it's in an active view, this is benign but may indicate a bug", instance.id)
return nil
}
logger.Debugf("Replica %d view change resend timer expired before view change quorum was reached, resending", instance.id)
instance.view-- // sending the view change increments this
return instance.sendViewChange()
default:
logger.Warningf("Replica %d received an unknown message type %T", instance.id, et)
}
if err != nil {
logger.Warning(err.Error())
}
return nil
}ProcessEvent这个函数决定了pbftCore能处理哪些事件,以及具体是如何处理的,所以只要以此函数为主线,跟踪下去基本上就能了解pbft的实现。
首先,客户发送一条批量操作的请求,此时pbftCore将收到RequestBatch事件,于是进入下面的分支:
case *RequestBatch:
err = instance.recvRequestBatch(et)pbftCore对新请求的处理如下,看注释即可:
func (instance *pbftCore) recvRequestBatch(reqBatch *RequestBatch) error {
//对请求进行hash,生成签名
digest := hash(reqBatch)
logger.Debugf("Replica %d received request batch %s", instance.id, digest)
//将请求存起来,以签名作为键
instance.reqBatchStore[digest] = reqBatch
instance.outstandingReqBatches[digest] = reqBatch
instance.persistRequestBatch(digest)
//如果当前节点的视图是活跃状态,启动一个请求超时定时器,一旦超时则怀疑当前主节点有问题,请求view chage更换主节点
if instance.activeView {
instance.softStartTimer(instance.requestTimeout, fmt.Sprintf("new request batch %s", digest))
}
//如果当前节点是主节点,则发送pre-prepare消息,进入第一阶段
if instance.primary(instance.view) == instance.id && instance.activeView {
instance.nullRequestTimer.Stop()
instance.sendPrePrepare(reqBatch, digest)
} else {
logger.Debugf("Replica %d is backup, not sending pre-prepare for request batch %s", instance.id, digest)
}
return nil
}再来看看pre-prepare是怎么发出去的:
func (instance *pbftCore) sendPrePrepare(reqBatch *RequestBatch, digest string) {
logger.Debugf("Replica %d is primary, issuing pre-prepare for request batch %s", instance.id, digest)
//检查本节点是否已经收到过相同编号,但是摘要不同的pre-prepare请求,如果是则拒绝处理
n := instance.seqNo + 1
for _, cert := range instance.certStore { // check for other PRE-PREPARE for same digest, but different seqNo
if p := cert.prePrepare; p != nil {
if p.View == instance.view && p.SequenceNumber != n && p.BatchDigest == digest && digest != "" {
logger.Infof("Other pre-prepare found with same digest but different seqNo: %d instead of %d", p.SequenceNumber, n)
return
}
}
}
//请求的编号不在高低水位之间,拒绝
if !instance.inWV(instance.view, n) || n > instance.h+instance.L/2 {
// We don't have the necessary stable certificates to advance our watermarks
logger.Warningf("Primary %d not sending pre-prepare for batch %s - out of sequence numbers", instance.id, digest)
return
}
//即将要切换到其他主节点,拒绝
if n > instance.viewChangeSeqNo {
logger.Info("Primary %d about to switch to next primary, not sending pre-prepare with seqno=%d", instance.id, n)
return
}
logger.Debugf("Primary %d broadcasting pre-prepare for view=%d/seqNo=%d and digest %s", instance.id, instance.view, n, digest)
//更新序号
instance.seqNo = n
preprep := &PrePrepare{
View: instance.view,
SequenceNumber: n,
BatchDigest: digest,
RequestBatch: reqBatch,
ReplicaId: instance.id,
}
cert := instance.getCert(instance.view, n)
cert.prePrepare = preprep
cert.digest = digest
instance.persistQSet()
//向其他节点广播pre-prepare消息
instance.innerBroadcast(&Message{Payload: &Message_PrePrepare{PrePrepare: preprep}})
instance.maybeSendCommit(digest, instance.view, n)
}不久后,其他的节点收到pre-prepare消息:
case *PrePrepare:
err = instance.recvPrePrepare(et)看一下节点收到pre-prepare消息后是如何处理的:
func (instance *pbftCore) recvPrePrepare(preprep *PrePrepare) error {
logger.Debugf("Replica %d received pre-prepare from replica %d for view=%d/seqNo=%d",
instance.id, preprep.ReplicaId, preprep.View, preprep.SequenceNumber)
//当前正在进行view change,不处理
if !instance.activeView {
logger.Debugf("Replica %d ignoring pre-prepare as we are in a view change", instance.id)
return nil
}
//pre-prepare消息不是主节点发送的,不处理
if instance.primary(instance.view) != preprep.ReplicaId {
logger.Warningf("Pre-prepare from other than primary: got %d, should be %d", preprep.ReplicaId, instance.primary(instance.view))
return nil
}
if !instance.inWV(preprep.View, preprep.SequenceNumber) {
if preprep.SequenceNumber != instance.h && !instance.skipInProgress {
logger.Warningf("Replica %d pre-prepare view different, or sequence number outside watermarks: preprep.View %d, expected.View %d, seqNo %d, low-mark %d", instance.id, preprep.View, instance.primary(instance.view), preprep.SequenceNumber, instance.h)
} else {
// This is perfectly normal
logger.Debugf("Replica %d pre-prepare view different, or sequence number outside watermarks: preprep.View %d, expected.View %d, seqNo %d, low-mark %d", instance.id, preprep.View, instance.primary(instance.view), preprep.SequenceNumber, instance.h)
}
return nil
}
if preprep.SequenceNumber > instance.viewChangeSeqNo {
logger.Info("Replica %d received pre-prepare for %d, which should be from the next primary", instance.id, preprep.SequenceNumber)
instance.sendViewChange()
return nil
}
//收到了请求编号相同但是签名不同,拒绝处理
cert := instance.getCert(preprep.View, preprep.SequenceNumber)
if cert.digest != "" && cert.digest != preprep.BatchDigest {
logger.Warningf("Pre-prepare found for same view/seqNo but different digest: received %s, stored %s", preprep.BatchDigest, cert.digest)
instance.sendViewChange()
return nil
}
//更新数据
cert.prePrepare = preprep
cert.digest = preprep.BatchDigest
// Store the request batch if, for whatever reason, we haven't received it from an earlier broadcast
//如果当前节点还没有这条请求,则将请求保存起来
if _, ok := instance.reqBatchStore[preprep.BatchDigest]; !ok && preprep.BatchDigest != "" {
digest := hash(preprep.GetRequestBatch())
if digest != preprep.BatchDigest {
logger.Warningf("Pre-prepare and request digest do not match: request %s, digest %s", digest, preprep.BatchDigest)
return nil
}
instance.reqBatchStore[digest] = preprep.GetRequestBatch()
logger.Debugf("Replica %d storing request batch %s in outstanding request batch store", instance.id, digest)
instance.outstandingReqBatches[digest] = preprep.GetRequestBatch()
instance.persistRequestBatch(digest)
}
//启动一个定时器
instance.softStartTimer(instance.requestTimeout, fmt.Sprintf("new pre-prepare for request batch %s", preprep.BatchDigest))
instance.nullRequestTimer.Stop()
//如果当前节点非主节点,并且请求已经完成了pre-prepare阶段,如果尚未发送prepare消息,则向其他节点广播prepare消息
if instance.primary(instance.view) != instance.id && instance.prePrepared(preprep.BatchDigest, preprep.View, preprep.SequenceNumber) && !cert.sentPrepare {
logger.Debugf("Backup %d broadcasting prepare for view=%d/seqNo=%d", instance.id, preprep.View, preprep.SequenceNumber)
prep := &Prepare{
View: preprep.View,
SequenceNumber: preprep.SequenceNumber,
BatchDigest: preprep.BatchDigest,
ReplicaId: instance.id,
}
cert.sentPrepare = true
instance.persistQSet()
instance.recvPrepare(prep)
return instance.innerBroadcast(&Message{Payload: &Message_Prepare{Prepare: prep}})
}
return nil
}注意上面代码中prepare消息的发送条件:
(1) 必须是非主节点,换言之主节点不会发送prepare消息;
(2) 请求必须已经完成了pre-prepare阶段,同时prepare消息尚未发送;
如何判断请求是否已经完成了pre-prepare阶段呢?且看代码:
func (instance *pbftCore) prePrepared(digest string, v uint64, n uint64) bool {
_, mInLog := instance.reqBatchStore[digest]
if digest != "" && !mInLog {
return false
}
//视图相同,并且位于qset中,则请求一定完成了pre-prepare阶段
if q, ok := instance.qset[qidx{digest, n}]; ok && q.View == v {
return true
}
//certStore中找到了请求对应的记录,并且记录中有prePrepare,视图、签名和编号都一致,则该请求已经完成pre-prepare阶段
cert := instance.certStore[msgID{v, n}]
if cert != nil {
p := cert.prePrepare
if p != nil && p.View == v && p.SequenceNumber == n && p.BatchDigest == digest {
return true
}
}
logger.Debugf("Replica %d does not have view=%d/seqNo=%d pre-prepared",
instance.id, v, n)
return false
}如果一切正常,就向其他节点广播prepare消息,进入prepare阶段,消息中会带上请求的编号,视图编号,节点的id,请求的签名。
看看其他节点收到prepare消息后是如何处理的:
func (instance *pbftCore) recvPrepare(prep *Prepare) error {
logger.Debugf("Replica %d received prepare from replica %d for view=%d/seqNo=%d",
instance.id, prep.ReplicaId, prep.View, prep.SequenceNumber)
//忽略主节点发送的prepare消息
if instance.primary(prep.View) == prep.ReplicaId {
logger.Warningf("Replica %d received prepare from primary, ignoring", instance.id)
return nil
}
//检查请求的编号是否在高低水位间
if !instance.inWV(prep.View, prep.SequenceNumber) {
if prep.SequenceNumber != instance.h && !instance.skipInProgress {
logger.Warningf("Replica %d ignoring prepare for view=%d/seqNo=%d: not in-wv, in view %d, low water mark %d", instance.id, prep.View, prep.SequenceNumber, instance.view, instance.h)
} else {
// This is perfectly normal
logger.Debugf("Replica %d ignoring prepare for view=%d/seqNo=%d: not in-wv, in view %d, low water mark %d", instance.id, prep.View, prep.SequenceNumber, instance.view, instance.h)
}
return nil
}
cert := instance.getCert(prep.View, prep.SequenceNumber)
//检查此前是否已经收到过来自同一节点的prepare消息,如果收到过则忽略掉
for _, prevPrep := range cert.prepare {
if prevPrep.ReplicaId == prep.ReplicaId {
logger.Warningf("Ignoring duplicate prepare from %d", prep.ReplicaId)
return nil
}
}
//把收到的prepare消息保存到集合中
cert.prepare = append(cert.prepare, prep)
instance.persistPSet()
//尝试发送commit消息
return instance.maybeSendCommit(prep.BatchDigest, prep.View, prep.SequenceNumber)
}确定是否发送commit消息在代码最后的maybeSendCommit函数中:
func (instance *pbftCore) maybeSendCommit(digest string, v uint64, n uint64) error {
cert := instance.getCert(v, n)
//如果请求已经完成了prepare阶段,并且尚未发送commit消息
if instance.prepared(digest, v, n) && !cert.sentCommit {
logger.Debugf("Replica %d broadcasting commit for view=%d/seqNo=%d",
instance.id, v, n)
commit := &Commit{
View: v,
SequenceNumber: n,
BatchDigest: digest,
ReplicaId: instance.id,
}
cert.sentCommit = true
//节点自己也要处理自己发送的commit消息
instance.recvCommit(commit)
//向其他节点广播commit消息
return instance.innerBroadcast(&Message{&Message_Commit{commit}})
}
return nil
}从代码中看到发送commit消息进入commit阶段的条件是:请求已经完成了prepare阶段,并且还未发送commit消息(防止重复),如何判断请求是否完成了prepare阶段呢?
func (instance *pbftCore) prepared(digest string, v uint64, n uint64) bool {
//没完成pre-prepare阶段的不算
if !instance.prePrepared(digest, v, n) {
return false
}
//pset中找到了请求的记录,并且视图、签名都OK,则请求已经完成prepare阶段
if p, ok := instance.pset[n]; ok && p.View == v && p.BatchDigest == digest {
return true
}
//certStore中没找到请求的记录,不算
quorum := 0
cert := instance.certStore[msgID{v, n}]
if cert == nil {
return false
}
//数一数当前节点总共收到了多少条关于此请求的prepare消息
for _, p := range cert.prepare {
if p.View == v && p.SequenceNumber == n && p.BatchDigest == digest {
quorum++
}
}
logger.Debugf("Replica %d prepare count for view=%d/seqNo=%d: %d",
instance.id, v, n, quorum)
//如果当前节点收到的请求的prepare消息超过规定值,则此请求完成了prepare阶段
return quorum >= instance.intersectionQuorum()-1
}一个节点到底收到多少条prepare消息才算prepare阶段结束呢?代码告诉你真相:
// intersectionQuorum returns the number of replicas that have to
// agree to guarantee that at least one correct replica is shared by
// two intersection quora
func (instance *pbftCore) intersectionQuorum() int {
return (instance.N + instance.f + 2) / 2
}N是集群中总的节点数,f是集群中可以容忍的问题节点数,所以节点收到的prepare消息的数量超过:
(N + f + 2) / 2 - 1 = (f + N) / 2,根据拜占庭问题的结论:N >= 3f + 1,则至少收到2f条prepare消息才算prepare阶段完成了。
继续看代码,假设有节点已经收到了2f条prepare消息,于是节点开始执行第三阶段也就是commit阶段,它向相邻节点发送commit消息,消息中带有请求的签名、编号,视图编号和节点的id,我们看下节点收到commit消息后是如何处理的:
func (instance *pbftCore) recvCommit(commit *Commit) error {
logger.Debugf("Replica %d received commit from replica %d for view=%d/seqNo=%d",
instance.id, commit.ReplicaId, commit.View, commit.SequenceNumber)
//检查请求的编号是否在高低水位之间
if !instance.inWV(commit.View, commit.SequenceNumber) {
if commit.SequenceNumber != instance.h && !instance.skipInProgress {
logger.Warningf("Replica %d ignoring commit for view=%d/seqNo=%d: not in-wv, in view %d, low water mark %d", instance.id, commit.View, commit.SequenceNumber, instance.view, instance.h)
} else {
// This is perfectly normal
logger.Debugf("Replica %d ignoring commit for view=%d/seqNo=%d: not in-wv, in view %d, low water mark %d", instance.id, commit.View, commit.SequenceNumber, instance.view, instance.h)
}
return nil
}
//如果节点此前已经收到过同一节点发送的同一请求的commit消息,忽略掉
cert := instance.getCert(commit.View, commit.SequenceNumber)
for _, prevCommit := range cert.commit {
if prevCommit.ReplicaId == commit.ReplicaId {
logger.Warningf("Ignoring duplicate commit from %d", commit.ReplicaId)
return nil
}
}
//记录收到的commit消息
cert.commit = append(cert.commit, commit)
//如果请求已经完成了commit阶段,则执行请求
if instance.committed(commit.BatchDigest, commit.View, commit.SequenceNumber) {
//终止定时器
instance.stopTimer()
instance.lastNewViewTimeout = instance.newViewTimeout
delete(instance.outstandingReqBatches, commit.BatchDigest)
//执行请求
instance.executeOutstanding()
if commit.SequenceNumber == instance.viewChangeSeqNo {
logger.Infof("Replica %d cycling view for seqNo=%d", instance.id, commit.SequenceNumber)
instance.sendViewChange()
}
}
return nil
}同样来看看,如何判断一个请求是否完成了commit阶段:
func (instance *pbftCore) committed(digest string, v uint64, n uint64) bool {
//prepare阶段没完成的不算
if !instance.prepared(digest, v, n) {
return false
}
quorum := 0
cert := instance.certStore[msgID{v, n}]
if cert == nil {
return false
}
//数一数收到的commit消息
for _, p := range cert.commit {
if p.View == v && p.SequenceNumber == n {
quorum++
}
}
logger.Debugf("Replica %d commit count for view=%d/seqNo=%d: %d",
instance.id, v, n, quorum)
return quorum >= instance.intersectionQuorum()
}可以看到代码中规定的数量:>= (N + f + 2) / 2,即 >= 2f + 1.5,也就是当节点收到2f + 1条commit消息后,commit阶段就算完成了,可以执行请求了。
2.2 视图切换
前面的说明中多次提到了视图(View),PBFT算法中的视图是个什么东西呢?
从前面的说明中,我们知道了客户发送的请求都是先交给主节点,但是如果主节点出了问题呢(比如宕机了,或者叛变了)?为了解决主节点出问题的情况,PBFT引入了视图的概念。
视图可以理解成主节点的任期,其他的从节点在一个视图内发出的请求,如果超过规定时间还没有响应,则从节点将怀疑现任主节点可能出现了问题,他将向其他节点发起view change请求来尝试更换主节点,然后当前编号最小的节点成为新的主节点。当新的主节点收到2f个其他节点的view change消息时,则表明有大量的节点认为需要更换主节点了,于是新的主节点广播New View消息,并从pre-prepare阶段开始重新执行上一个视图未执行完的请求,其他节点收到new view消息处理主节点发送来的pre-prepare消息,于是新的主节点的任期正式开始。
除了从节点主动触发视图切换,PBFT还会定时的更新主节点,以防止主节点出问题。
下图是论文中描述的视图切换的示意图:

上一节介绍pbft共识过程的源码时看到,当收到新请求的时候,会为新请求启动一个定时器:
func (instance *pbftCore) recvRequestBatch(reqBatch *RequestBatch) error {
digest := hash(reqBatch)
logger.Debugf("Replica %d received request batch %s", instance.id, digest)
instance.reqBatchStore[digest] = reqBatch
instance.outstandingReqBatches[digest] = reqBatch
instance.persistRequestBatch(digest)
//这里启动了一个定时器
if instance.activeView {
instance.softStartTimer(instance.requestTimeout, fmt.Sprintf("new request batch %s", digest))
}
if instance.primary(instance.view) == instance.id && instance.activeView {
instance.nullRequestTimer.Stop()
instance.sendPrePrepare(reqBatch, digest)
} else {
logger.Debugf("Replica %d is backup, not sending pre-prepare for request batch %s", instance.id, digest)
}
return nil
}如果在定时器规定的时间内请求还没执行完(请求执行完定时器是会被终止的),节点就会发送viewChangeTimerEvent事件,触发view chage事件请求:
func (instance *pbftCore) softStartTimer(timeout time.Duration, reason string) {
logger.Debugf("Replica %d soft starting new view timer for %s: %s", instance.id, timeout, reason)
instance.newViewTimerReason = reason
instance.timerActive = true
instance.newViewTimer.SoftReset(timeout, viewChangeTimerEvent{})
}超时处理如下:
case viewChangeTimerEvent:
logger.Infof("Replica %d view change timer expired, sending view change: %s", instance.id, instance.newViewTimerReason)
instance.timerActive = false
instance.sendViewChange()节点会调用sendViewChage来处理:
func (instance *pbftCore) sendViewChange() events.Event {
instance.stopTimer()
//从集合中删除当前视图
delete(instance.newViewStore, instance.view)
//当前节点的视图编号自增
instance.view++
//标记当前节点正在切换视图
instance.activeView = false
instance.pset = instance.calcPSet()
instance.qset = instance.calcQSet()
// clear old messages
//从记录中删除所有属于旧视图的请求
for idx := range instance.certStore {
if idx.v < instance.view {
delete(instance.certStore, idx)
}
}
//从所有收到的view change消息集合中,删除旧的,比如当前节点请求更新视图到100,则把所有收到的小于100的view change消息清掉
for idx := range instance.viewChangeStore {
if idx.v < instance.view {
delete(instance.viewChangeStore, idx)
}
}
//构造view change消息
vc := &ViewChange{
View: instance.view,
H: instance.h,
ReplicaId: instance.id,
}
//将当前节点的所有的检查点带入到view change消息中
for n, id := range instance.chkpts {
vc.Cset = append(vc.Cset, &ViewChange_C{
SequenceNumber: n,
Id: id,
})
}
//将当前节点所有完成prepare阶段的请求带入到view change消息中
for _, p := range instance.pset {
if p.SequenceNumber < instance.h {
logger.Errorf("BUG! Replica %d should not have anything in our pset less than h, found %+v", instance.id, p)
}
vc.Pset = append(vc.Pset, p)
}
//将当前节点所有完成pre-prepare阶段的请求带入到view change消息中
for _, q := range instance.qset {
if q.SequenceNumber < instance.h {
logger.Errorf("BUG! Replica %d should not have anything in our qset less than h, found %+v", instance.id, q)
}
vc.Qset = append(vc.Qset, q)
}
//对view change消息进行签名
instance.sign(vc)
logger.Infof("Replica %d sending view-change, v:%d, h:%d, |C|:%d, |P|:%d, |Q|:%d",
instance.id, vc.View, vc.H, len(vc.Cset), len(vc.Pset), len(vc.Qset))
//广播view change消息
instance.innerBroadcast(&Message{Payload: &Message_ViewChange{ViewChange: vc}})
instance.vcResendTimer.Reset(instance.vcResendTimeout, viewChangeResendTimerEvent{})
return instance.recvViewChange(vc)
}当一个节点收到view change事件以后,分两种情况:
(1) 节点收到超过f + 1条view change消息,这些消息的视图编号都比节点当前视图的编号大,说明当前节点的视图确实需要更新了,当前节点将向其他节点广播view change消息并且切换视图;
(2) 节点当前的view失效,同时收到超过N - f条view change消息,消息中的视图编号和当前视图编号相等,说明当前的view应该是最新的,如果是主节点,则向其他节点广播new view消息,如果是从节点则直接切换视图;
看看代码:
func (instance *pbftCore) recvViewChange(vc *ViewChange) events.Event {
logger.Infof("Replica %d received view-change from replica %d, v:%d, h:%d, |C|:%d, |P|:%d, |Q|:%d",
instance.id, vc.ReplicaId, vc.View, vc.H, len(vc.Cset), len(vc.Pset), len(vc.Qset))
//校验消息签名
if err := instance.verify(vc); err != nil {
logger.Warningf("Replica %d found incorrect signature in view-change message: %s", instance.id, err)
return nil
}
//如果当前节点的view编号比view change消息中的更大,没必要切换
if vc.View < instance.view {
logger.Warningf("Replica %d found view-change message for old view", instance.id)
return nil
}
if !instance.correctViewChange(vc) {
logger.Warningf("Replica %d found view-change message incorrect", instance.id)
return nil
}
//忽略此前收到的相同的view change消息
if _, ok := instance.viewChangeStore[vcidx{vc.View, vc.ReplicaId}]; ok {
logger.Warningf("Replica %d already has a view change message for view %d from replica %d", instance.id, vc.View, vc.ReplicaId)
return nil
}
//将收到的view change消息保存下来
instance.viewChangeStore[vcidx{vc.View, vc.ReplicaId}] = vc
// PBFT TOCS 4.5.1 Liveness: "if a replica receives a set of
// f+1 valid VIEW-CHANGE messages from other replicas for
// views greater than its current view, it sends a VIEW-CHANGE
// message for the smallest view in the set, even if its timer
// has not expired"
//计算收到的所有比当前节点的view编号更大的view change消息中,视图编号最小的view
replicas := make(map[uint64]bool)
minView := uint64(0)
for idx := range instance.viewChangeStore {
if idx.v <= instance.view {
continue
}
replicas[idx.id] = true
if minView == 0 || idx.v < minView {
minView = idx.v
}
}
// We only enter this if there are enough view change messages _greater_ than our current view
//如果收到f + 1条比当前节点视图编号大的view change消息,则向其他节点广播view change,同时节点切换视图
if len(replicas) >= instance.f+1 {
logger.Infof("Replica %d received f+1 view-change messages, triggering view-change to view %d",
instance.id, minView)
// subtract one, because sendViewChange() increments
instance.view = minView - 1
return instance.sendViewChange()
}
//统计收到的视图编号等于当前节点视图编号的view change消息数量
quorum := 0
for idx := range instance.viewChangeStore {
if idx.v == instance.view {
quorum++
}
}
logger.Debugf("Replica %d now has %d view change requests for view %d", instance.id, quorum, instance.view)
//如果当前节点的视图失效,并且收到N - f条视图编号等于当前节点视图编号的view change消息
if !instance.activeView && vc.View == instance.view && quorum >= instance.allCorrectReplicasQuorum() {
instance.vcResendTimer.Stop()
instance.startTimer(instance.lastNewViewTimeout, "new view change")
instance.lastNewViewTimeout = 2 * instance.lastNewViewTimeout
return viewChangeQuorumEvent{}
}
return nil
}代码最下边,节点收到N-f(即 >= 2f + 1)条视图编号与当前视图编号相等的view change消息,就会发送viewChangeQuorumEvent消息,这条消息的处理如下:
case viewChangeQuorumEvent:
logger.Debugf("Replica %d received view change quorum, processing new view", instance.id)
//如果节点是主节点,广播new view消息,同时切换视图
if instance.primary(instance.view) == instance.id {
return instance.sendNewView()
}
//从节点直接切换视图
return instance.processNewView()具体视图切换的实现,可以参考processNewView的处理,本文不在详细展开了。
3 总结
本文介绍了拜占庭将军问题,以及解决拜占庭将军问题的经典算法PBFT,同时结合超级账本的fabric项目的源码分析了pbft算法在商业级项目中的具体实现。
(1) pbft算法可以容忍不超过(N - 1) / 3个问题节点,共识算法的时间复杂度为O(n^2);
(2) pbft算法完成共识需要经过三个阶段:pre-prepare、prepare和commit阶段;
(3) pbft算法需要一个主节点,每个主节点的任期就是一个view。当从节点发现主节点有问题(比如请求在规定时间内没有相应)时通过view change来请求更换主节点。
PBFT算法非常重要,很多大厂的区块链项目中都有运用,例如国内的迅雷、腾讯等公司的区块链项目,超级账本的fabric等,都使用了pbft或者优化后的pbft作为共识算法,理解pbft算法是区块链学习过程中非常重要的一环。