HAWQ技术解析(八) —— 大表分区
一、HAWQ中的分区表
与大多数关系数据库一样,HAWQ也支持分区表。这里所说的分区表是指HAWQ的内部分区表,外部分区表在后面“外部数据”篇讨论。在数据仓库应用中,事实表通常有非常多的记录,分区可以将这样的大表在逻辑上分为小的、更易管理的数据片段。HAWQ的优化器支持分区消除以提高查询性能。只要查询条件中可以使用分区键作为过滤条件,那么HAWQ只需要扫描满足查询条件的分区,而不必进行全表扫描。
分区并不改变表数据在segment间的物理分布。表的分布是物理的,无论是分区表还是非分区表,HAWQ都会在segment上物理地分布数据,并且并行处理查询。而表的分区是逻辑上的,HAWQ逻辑分隔大表以提高查询性能和数据仓库应用的可维护性。例如,将老的分区数据从数据仓库转储或移除,并建立新的数据分区等。HAWQ支持以下分区类型:

在CREATE TABLE命令中使用PARTITION BY或可选的SUBPARTITION BY子句建立分区。上级分区可以包含一个或多个下级分区。HAWQ内部创建上下级分区之间的层次关系。分区条件定义一个分区内可以包含的数据。在建立分区表时,HAWQ为每个分区条件创建一个唯一的CHECK约束,限制一个分区所能含有的数据,保证各个分区中数据的互斥性。查询优化器利用该CHECK约束,决定扫描哪些分区以满足查询谓词条件。
HAWQ在系统目录中存储分区的层次信息,因此插入到分区表中的行可以正确传递到子分区中。ALTER TABLE命令的PARTITION子句用于修改分区表结构。
在向分区表插入数据时,可以在INSERT命令中指定表的根分区或叶分区(适用于从主表继承方式创建的分区表)。如果数据对于指定的叶分区无效,将返回错误。INSERT命令不支持向非叶分区的子分区中插入数据。
二、确定分区策略
并不是所有表都适合分区,需要进行实测以保证所期望的性能提升。下面是一些通用的分区指南,如果对以下问题的大部分答案是肯定的,分区表对于提高性能是可行的数据库设计。否则,表不适合分区。
三、创建分区表
如前所述,创建分区表需要定义分区键、分区类型、分区层次。下面是几个创建分区表的例子。
1. 定义日期范围分区表
在定义日期分区表时,可以考虑以可接受的细节粒度做分区。例如,相对于以月份做主分区,日期做子分区的分区策略,每个日期一个分区,一年365个分区的方案可能更好。多级分区可以降低生成查询计划的时间,但平面化的分区设计运行地更快。
2. 定义数字范围分区表
列表分区可以使用任何允许等值比较数据类型的列作为分区键。列表分区表必须显式定义每个分区。注意列表中的字符比较区分大小写。
4. 定义多级分区
可以在分区中定义子分区。使用subpartition template子句保证每个分区都有相同的子分区定义,包括以后添加的分区。
下面的例子显示了一个树形分区设计。sales表按年、月、地区的层级三级分区。SUBPARTITION TEMPLATE子句保证每个分区都有相同的子分区结构。例子中的每一层级都指定了缺省的分区。
5. 对一个已经存在的表进行分区
正如开篇提到的,HAWQ只能使用CREATE TABLE命令创建分区表。如果想对一个已经存在的表进行分区,只能这样做:新建分区表->将数据原表导入分区表->删除原表->分区表改名->分析分区表->对新建的分区表重新授权。例如:
6. 查看分区表定义
查询pg_partitions视图可以获取分区相关信息。
使用EXPLAIN可以检查查询执行计划,验证查询优化器是否只扫描了相关分区的数据。下面以sales表上的年、月、地区三级分区为例进行说明。
1. 插入一条数据,如图2所示。
3. 以年为条件查询,查询计划如图4所示。
3. 以年、月为条件查询,查询计划如图5所示。
4. 以年、月、地区为条件查询,查询计划如图6所示。
5. 以DEFAULT条件查询,查询计划如图7所示。
分区消除有以下限制:
ALTER TABLE命令维护分区表。尽管可以通过引用分区对应的表对象的名子进行查询和装载数据,但修改分区表结构时,只能使用ALTER TABLE...PARTITION引用分区的名字。也可以使用PARTITION FOR (value)或PARTITION FOR(RANK(number))指示分区。注意,HAWQ不支持在多级分区上的如下操作:
为一个分区表增加子分区时,可以指定需要修改的分区。
2. 增加缺省分区
3. 分区改名
每个子分区对应一个表对象,可以用\dt元命令查看到。如果是自动生成的范围分区,在没有指定名称的分区被赋予一个数字。分区对应表对象的命名规则如下:
修改顶级父表的名称,会重命名所有分区子表名,例如:
4. 删除分区
ALTER TABLE命令也可用来删除分区,如果被删除的分区有子分区,则这些子分区及其数据也都被一起删除。
5. 清空分区
使用ALTER TABLE命令清空一个分区及其所有子分区的数据。不能单独清空一个子分区。
6. 分区交换
分区交换指的是用一个表的数据与一个分区的数据交换。HAWQ只支持单级分区表的分区交换。
7. 分裂分区
分裂分区指的是将一个分区分裂成两个分区,HAWQ只能分裂单级分区表。
8. 修改子分区模板
ALTER TABLE SET SUBPARTITION TEMPLATE修改一个分区表的子分区模板。新模板只影响后面添加的数据,不修改现有的分区数据。
9. 分区滚动窗口维护
在对数据表进行范围分区处理的基础上,可以进一步设计滚动数据的策略。通过维护一个数据滚动窗口,删除老分区,添加新分区,将老分区的数据迁移到数据仓库以外的次级存储,以节省系统开销。下面以一个常见的应用场景说明分区自动滚动的实现。假设一个数据仓库保留最近一年的销售记录,按日期每天一个分区。初始建立一年的分区,并装载近一年的数据,然后每天装载前一天的销售数据。
(1)建立分区表
(2)创建动态滚动分区的函数
HAWQ从PostgreSQL继承了过程化编程,并使用多种语言。在我自己使用过的SQL-on-Hadoop产品中,HAWQ是唯一支持过程化编程的。而且,其内建函数、操作符和语法与Oracle极为接近,这对于传统数据库的开发管理人员及广大DBA是非常有吸引力的。在转到大数据平台时,他们可以复用原来积淀的知识与经验。仅凭这一点,HAWQ就可以在众多SQL-on-Hadoop解决方案中体现出独有的优势和价值。下一篇将详细描述HAWQ的过程化语言编程。
(3)在cron中增加作业,例如,从下个月开始的每月一日两点执行分区滚动。
与大多数关系数据库一样,HAWQ也支持分区表。这里所说的分区表是指HAWQ的内部分区表,外部分区表在后面“外部数据”篇讨论。在数据仓库应用中,事实表通常有非常多的记录,分区可以将这样的大表在逻辑上分为小的、更易管理的数据片段。HAWQ的优化器支持分区消除以提高查询性能。只要查询条件中可以使用分区键作为过滤条件,那么HAWQ只需要扫描满足查询条件的分区,而不必进行全表扫描。
分区并不改变表数据在segment间的物理分布。表的分布是物理的,无论是分区表还是非分区表,HAWQ都会在segment上物理地分布数据,并且并行处理查询。而表的分区是逻辑上的,HAWQ逻辑分隔大表以提高查询性能和数据仓库应用的可维护性。例如,将老的分区数据从数据仓库转储或移除,并建立新的数据分区等。HAWQ支持以下分区类型:
- 范围分区:基于数字范围分区,如日期、价格等。
- 列表分区:基于列表值分区,如销售区域、产品分类等。
- 两者混合的分区类型。
图1
在CREATE TABLE命令中使用PARTITION BY或可选的SUBPARTITION BY子句建立分区。上级分区可以包含一个或多个下级分区。HAWQ内部创建上下级分区之间的层次关系。分区条件定义一个分区内可以包含的数据。在建立分区表时,HAWQ为每个分区条件创建一个唯一的CHECK约束,限制一个分区所能含有的数据,保证各个分区中数据的互斥性。查询优化器利用该CHECK约束,决定扫描哪些分区以满足查询谓词条件。
HAWQ在系统目录中存储分区的层次信息,因此插入到分区表中的行可以正确传递到子分区中。ALTER TABLE命令的PARTITION子句用于修改分区表结构。
在向分区表插入数据时,可以在INSERT命令中指定表的根分区或叶分区(适用于从主表继承方式创建的分区表)。如果数据对于指定的叶分区无效,将返回错误。INSERT命令不支持向非叶分区的子分区中插入数据。
二、确定分区策略
并不是所有表都适合分区,需要进行实测以保证所期望的性能提升。下面是一些通用的分区指南,如果对以下问题的大部分答案是肯定的,分区表对于提高性能是可行的数据库设计。否则,表不适合分区。
- 表是否足够大?按照一般的经验,至少千万记录以上的表才算大表。数据仓库中的事实表适合作为分区表。对于小于这个数量级的表通常不需要分区。因为系统管理与维护分区的开销会抵消掉分区带来的可见的性能优势。
- 性能是否不可接受?只有当实施了其它优化手段后,响应时间仍然不可接受时,再考虑使用分区。
- 查询谓词条件中是否包含适合的分区键?检查查询的WHERE子句中是否包含适合作为分区的条件。例如,如果大部分查询都通过日期检索数据,那么按照月或周做范围分区可能是有益的。
- 是否需要维护一个数据仓库的历史数据窗口?例如,组织中的数据仓库只需要保持过去12个月的数据,那么按月分区,就可以很容易地删除最老月份的分区,并向最新的月分区中装载当前数据。
- 根据分区定义条件,是否每个分区的数据量比较平均?分区条件应尽可能使数据平均划分。如果每个分区包含基本相同的记录数,性能会有所提升。例如,将一个大表分成10个相等的分区,如果查询条件中带有分区键,那么理论上查询应该比非分区表快将近10倍。
三、创建分区表
如前所述,创建分区表需要定义分区键、分区类型、分区层次。下面是几个创建分区表的例子。
1. 定义日期范围分区表
在定义日期分区表时,可以考虑以可接受的细节粒度做分区。例如,相对于以月份做主分区,日期做子分区的分区策略,每个日期一个分区,一年365个分区的方案可能更好。多级分区可以降低生成查询计划的时间,但平面化的分区设计运行地更快。
create table sales (id int, date date, amt decimal(10,2))
distributed by (id)
partition by range (date)
( start (date '2017-01-01') inclusive
end (date '2017-02-01') exclusive
every (interval '1 day') );db1=# insert into sales values (1, (date '2016-12-31'),100);
ERROR: no partition for partitioning key (seg21 hdp4:40000 pid=60186)
db1=# insert into sales values (1, (date '2017-01-01'),100);
INSERT 0 1
db1=# insert into sales values (1, (date '2017-02-01'),100);
ERROR: no partition for partitioning key (seg23 hdp4:40000 pid=60190)
db1=# insert into sales values (1, (date '2017-01-31'),100);
INSERT 0 1create table sales (id int, date date, amt decimal(10,2))
distributed by (id)
partition by range (date)
( start (date '2017-01-01') exclusive
end (date '2017-02-01') inclusive
every (interval '1 day') );
db1=# insert into sales values (1, (date '2017-01-01'),100);
ERROR: no partition for partitioning key (seg19 hdp4:40000 pid=60182)
db1=# insert into sales values (1, (date '2017-01-02'),100);
INSERT 0 1
db1=# insert into sales values (1, (date '2017-01-31'),100);
INSERT 0 1
db1=# insert into sales values (1, (date '2017-02-01'),100);
INSERT 0 1
db1=# insert into sales values (1, (date '2017-02-02'),100);
ERROR: no partition for partitioning key (seg23 hdp4:40000 pid=60269)create table sales (id int, date date, amt decimal(10,2))
distributed by (id)
partition by range (date)
( partition p201701 start (date '2017-01-01') inclusive ,
partition p201702 start (date '2017-02-01') inclusive ,
partition p201703 start (date '2017-03-01') inclusive ,
partition p201704 start (date '2017-04-01') inclusive ,
partition p201705 start (date '2017-05-01') inclusive ,
partition p201706 start (date '2017-06-01') inclusive ,
partition p201707 start (date '2017-07-01') inclusive ,
partition p201708 start (date '2017-08-01') inclusive ,
partition p201709 start (date '2017-09-01') inclusive ,
partition p201710 start (date '2017-10-01') inclusive ,
partition p201711 start (date '2017-11-01') inclusive ,
partition p201712 start (date '2017-12-01') inclusive
end (date '2018-01-01') exclusive );2. 定义数字范围分区表
db1=# create table rank (id int, rank int, year int, gender
db1(# char(1), count int)
db1-# distributed by (id)
db1-# partition by range (year)
db1-# ( start (2017) end (2018) every (1),
db1(# default partition extra );
NOTICE: CREATE TABLE will create partition "rank_1_prt_extra" for table "rank"
NOTICE: CREATE TABLE will create partition "rank_1_prt_2" for table "rank"
CREATE TABLE
db1=# \dt
List of relations
Schema | Name | Type | Owner | Storage
--------+------------------+-------+---------+-------------
public | rank | table | gpadmin | append only
public | rank_1_prt_2 | table | gpadmin | append only
public | rank_1_prt_extra | table | gpadmin | append only
(3 rows)
db1=# insert into rank values (1,1,2016,'M',100);
INSERT 0 1
db1=# insert into rank values (1,1,2017,'M',100);
INSERT 0 1
db1=# insert into rank values (1,1,2018,'M',100);
INSERT 0 1
db1=# insert into rank values (1,1,2019,'M',100);
INSERT 0 1
db1=# select * from rank;
id | rank | year | gender | count
----+------+------+--------+-------
1 | 1 | 2016 | M | 100
1 | 1 | 2018 | M | 100
1 | 1 | 2019 | M | 100
1 | 1 | 2017 | M | 100
(4 rows)
db1=# select * from rank_1_prt_2;
id | rank | year | gender | count
----+------+------+--------+-------
1 | 1 | 2017 | M | 100
(1 row)
db1=# select * from rank_1_prt_extra;
id | rank | year | gender | count
----+------+------+--------+-------
1 | 1 | 2016 | M | 100
1 | 1 | 2018 | M | 100
1 | 1 | 2019 | M | 100
(3 rows)
db1=# drop table rank;
DROP TABLE
db1=# \dt
No relations found.- HAWQ缺省的分区范围是左闭右开。
- 可以使用default partition子句增加一个缺省分区,当数据不被包含在任何明确定义的分区时,可以被包含在缺省分区中。
- HAWQ在查询时可以将分区当做表看待,但删除主表后,分区被一并删除。
列表分区可以使用任何允许等值比较数据类型的列作为分区键。列表分区表必须显式定义每个分区。注意列表中的字符比较区分大小写。
db1=# create table rank (id int, rank int, year int, gender
db1(# char(1), count int )
db1-# distributed by (id)
db1-# partition by list (gender)
db1-# ( partition girls values ('f'),
db1(# partition boys values ('m'),
db1(# default partition other );
NOTICE: CREATE TABLE will create partition "rank_1_prt_girls" for table "rank"
NOTICE: CREATE TABLE will create partition "rank_1_prt_boys" for table "rank"
NOTICE: CREATE TABLE will create partition "rank_1_prt_other" for table "rank"
CREATE TABLE
db1=# \dt
List of relations
Schema | Name | Type | Owner | Storage
--------+------------------+-------+---------+-------------
public | rank | table | gpadmin | append only
public | rank_1_prt_boys | table | gpadmin | append only
public | rank_1_prt_girls | table | gpadmin | append only
public | rank_1_prt_other | table | gpadmin | append only
(4 rows)
db1=# insert into rank values (1,1,2016,'M',100);
INSERT 0 1
db1=# insert into rank values (1,1,2016,'m',100);
INSERT 0 1
db1=# insert into rank values (1,1,2016,'f',100);
INSERT 0 1
db1=# insert into rank values (1,1,2016,'F',100);
INSERT 0 1
db1=# insert into rank values (1,1,2016,'A',100);
INSERT 0 1
db1=# select * from rank;
id | rank | year | gender | count
----+------+------+--------+-------
1 | 1 | 2016 | f | 100
1 | 1 | 2016 | m | 100
1 | 1 | 2016 | M | 100
1 | 1 | 2016 | F | 100
1 | 1 | 2016 | A | 100
(5 rows)
db1=# select * from rank_1_prt_boys;
id | rank | year | gender | count
----+------+------+--------+-------
1 | 1 | 2016 | m | 100
(1 row)
db1=# select * from rank_1_prt_girls;
id | rank | year | gender | count
----+------+------+--------+-------
1 | 1 | 2016 | f | 100
(1 row)
db1=# select * from rank_1_prt_other;
id | rank | year | gender | count
----+------+------+--------+-------
1 | 1 | 2016 | M | 100
1 | 1 | 2016 | F | 100
1 | 1 | 2016 | A | 100
(3 rows)db1=# create table rank (id int, rank int, year int, gender
db1(# char(1), count int )
db1-# distributed by (id)
db1-# partition by list (gender,year)
db1-# ( partition girls values ('f',2017),
db1(# partition boys values ('m',2018),
db1(# default partition other );
ERROR: Composite partition keys are not allowed4. 定义多级分区
可以在分区中定义子分区。使用subpartition template子句保证每个分区都有相同的子分区定义,包括以后添加的分区。
create table sales (trans_id int, date date, amount
decimal(9,2), region text)
distributed by (trans_id)
partition by range (date)
subpartition by list (region)
subpartition template
( subpartition usa values ('usa'),
subpartition asia values ('asia'),
subpartition europe values ('europe'),
default subpartition other_regions)
(start (date '2017-01-01') inclusive
end (date '2018-01-01') exclusive
every (interval '1 month'),
default partition outlying_dates );下面的例子显示了一个树形分区设计。sales表按年、月、地区的层级三级分区。SUBPARTITION TEMPLATE子句保证每个分区都有相同的子分区结构。例子中的每一层级都指定了缺省的分区。
create table sales (id int, year int, month int, day int,
region text)
distributed by (id)
partition by range (year)
subpartition by range (month)
subpartition template (
start (1) end (13) every (1),
default subpartition other_months )
subpartition by list (region)
subpartition template (
subpartition usa values ('usa'),
subpartition europe values ('europe'),
subpartition asia values ('asia'),
default subpartition other_regions )
( start (2017) end (2018) every (1),
default partition outlying_years );5. 对一个已经存在的表进行分区
正如开篇提到的,HAWQ只能使用CREATE TABLE命令创建分区表。如果想对一个已经存在的表进行分区,只能这样做:新建分区表->将数据原表导入分区表->删除原表->分区表改名->分析分区表->对新建的分区表重新授权。例如:
create table sales2 (like sales)
partition by range (date)
( start (date '2017-01-01') inclusive
end (date '2018-01-01') exclusive
every (interval '1 month') );
insert into sales2 select * from sales;
drop table sales;
alter table sales2 rename to sales;
analyze sales;
grant all privileges on sales to admin;
grant select on sales to guest;6. 查看分区表定义
查询pg_partitions视图可以获取分区相关信息。
select partitionboundary, partitiontablename, partitionname,partitionlevel, partitionrank
from pg_partitions
where tablename='sales';- pg_partition:分区表及其层级关系。
- pg_partition_templates:子分区使用的模板。
- pg_partition_columns:分区键列。
使用EXPLAIN可以检查查询执行计划,验证查询优化器是否只扫描了相关分区的数据。下面以sales表上的年、月、地区三级分区为例进行说明。
create table sales (id int, year int, month int, day int,
region text)
distributed by (id)
partition by range (year)
subpartition by range (month)
subpartition template (
start (1) end (13) every (1),
default subpartition other_months )
subpartition by list (region)
subpartition template (
subpartition usa values ('北京'),
subpartition europe values ('上海'),
subpartition asia values ('广州'),
default subpartition other_regions )
( start (2017) end (2020) every (1),
default partition outlying_years );1. 插入一条数据,如图2所示。

图2
2. 无条件查询,查询计划如图3所示。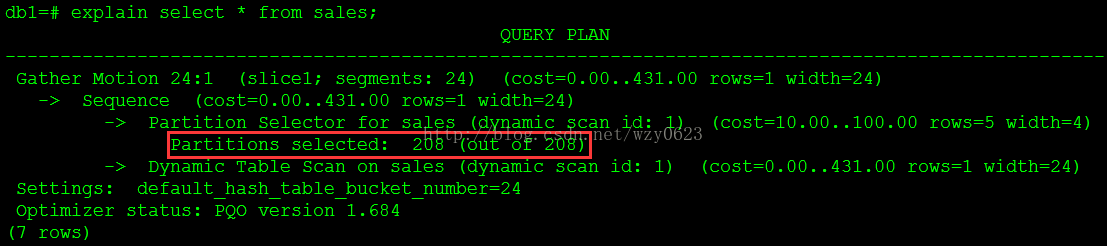
图3
可以看到,该查询扫描了全部208个分区,没有分区消除。3. 以年为条件查询,查询计划如图4所示。
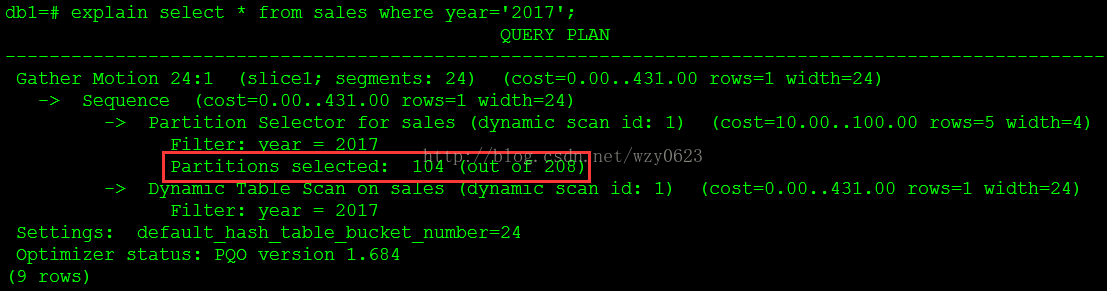
图4
可以看到,该查询扫描了全部208个分区的一半,104个分区。顶级年份分区有四个,为什么where year='2017'要扫描104而不是52个分区呢?在运行时,查询优化器会扫描这个表的层级关系(系统表),并使用CHECK表约束确定扫描哪些满足查询条件的分区。如果存在DEFAULT分区,则它总是被扫描,因此该查询或扫描year=2017和default两个分区,这就是扫描的分区数是104而不是52的原因。可见,包含DEFAULT分区会增加整体扫描时间。按理说DEFAULT与其它所有分区的数据都是互斥的,完全不必在可以确定分区的条件下再去扫描它,这是不是HAWQ查询优化器的一个问题也未可知。3. 以年、月为条件查询,查询计划如图5所示。

图5
可以看到,这次只扫描了16个分区。同样道理本应只扫描4个底层分区,因为DEFAULT的存在,需要扫描16个分区。4. 以年、月、地区为条件查询,查询计划如图6所示。
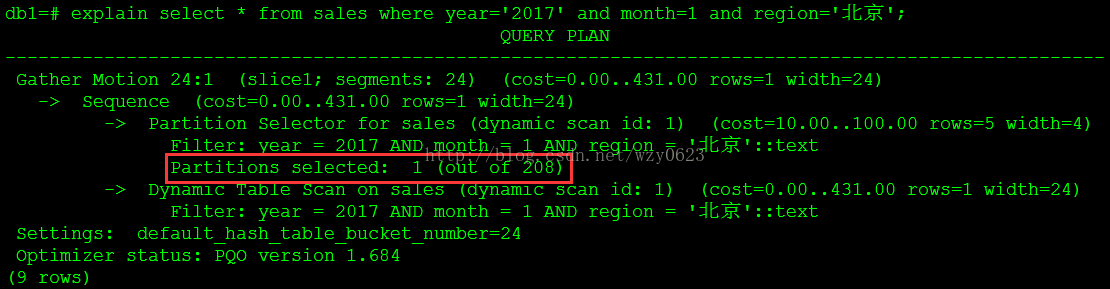
图6
这次只需扫描一个分区。当查询中包含所有层级的谓词条件时,没有扫描DEFAULT,而是唯一确定了一个分区。5. 以DEFAULT条件查询,查询计划如图7所示。

图7
这次只要扫描年份DEFAULT分区下的52个子分区。分区消除有以下限制:
- 查询优化器只有在查询条件中包含=、<、<=、>、>=、<>等比较运算符是才可能应用分区消除。
- 对于稳定的函数会应用分区消除,对于易变函数不会应用分区消除。例如,WHERE date > CURRENT_DATE会应用分区消除,而time > TIMEOFDAY则不会。
ALTER TABLE命令维护分区表。尽管可以通过引用分区对应的表对象的名子进行查询和装载数据,但修改分区表结构时,只能使用ALTER TABLE...PARTITION引用分区的名字。也可以使用PARTITION FOR (value)或PARTITION FOR(RANK(number))指示分区。注意,HAWQ不支持在多级分区上的如下操作:
- 增加缺省分区
- 增加分区
- 删除缺省分区
- 删除分区
- 分割分区
- 所有修改子分区的操作
create table sales (id int, year int, month int, day int,
region text)
distributed by (id)
partition by range (year)
subpartition by range (month)
subpartition template (
start (1) end (13) every (1),
default subpartition other_months )
subpartition by list (region)
subpartition template (
subpartition usa values ('北京'),
subpartition europe values ('上海'),
subpartition asia values ('广州'),
default subpartition other_regions )
( start (2017) end (2020) every (1));
alter table sales add partition
start (2016) inclusive
end (2017) exclusive;ERROR: cannot add RANGE partition to relation "sales" with DEFAULT partition "outlying_years"
HINT: need to SPLIT partition "outlying_years"为一个分区表增加子分区时,可以指定需要修改的分区。
alter table sales alter partition for (rank(12))
add partition africa values ('africa');
alter table sales alter partition for (rank(1))
add partition africa values ('africa');2. 增加缺省分区
alter table sales add default partition other;3. 分区改名
每个子分区对应一个表对象,可以用\dt元命令查看到。如果是自动生成的范围分区,在没有指定名称的分区被赋予一个数字。分区对应表对象的命名规则如下:
__prt_ sales_1_prt_1_2_prt_11_3_prt_other_regions修改顶级父表的名称,会重命名所有分区子表名,例如:
alter table sales rename to globalsales;globalsales_1_prt_1_2_prt_11_3_prt_other_regionsalter table sales rename partition for (2017) to y2017;db1=# alter table globalsales rename partition for (2017) to year2017;
ERROR: relation name "globalsales_1_prt_year2017_2_prt_other_months_3_prt_other_regions" for child partition is too long4. 删除分区
ALTER TABLE命令也可用来删除分区,如果被删除的分区有子分区,则这些子分区及其数据也都被一起删除。
alter table globalsales drop partition for (2017);
alter table globalsales drop partition for (2018);db1=# alter table globalsales drop partition for (2019);
ERROR: cannot drop partition for value (2019) of relation "globalsales" -- only one remains
HINT: Use DROP TABLE "globalsales" to remove the table and the final partition5. 清空分区
使用ALTER TABLE命令清空一个分区及其所有子分区的数据。不能单独清空一个子分区。
alter table globalsales truncate partition for (2018);6. 分区交换
分区交换指的是用一个表的数据与一个分区的数据交换。HAWQ只支持单级分区表的分区交换。
db1=# alter table sales exchange partition for (2017)
db1-# with table stage_sales;
ERROR: cannot EXCHANGE PARTITION for relation "sales" -- partition has children
图8
向分区表装载数据的推荐方法创建一个中间过渡表,装载过渡表,然后用过渡表与分区做交换。db1=# create table sales (id int, year int, month int, day int, region varchar(10))
db1-# distributed by (id)
db1-# partition by range (year)
db1-# ( start (2017) end (2020) every (1));
NOTICE: CREATE TABLE will create partition "sales_1_prt_1" for table "sales"
NOTICE: CREATE TABLE will create partition "sales_1_prt_2" for table "sales"
NOTICE: CREATE TABLE will create partition "sales_1_prt_3" for table "sales"
CREATE TABLE
Time: 497.864 ms
db1=# insert into sales values (1,2017,1,1,'北京');
INSERT 0 1
Time: 463.546 ms
db1=# insert into sales values (2,2018,2,2,'上海');
INSERT 0 1
Time: 133.454 ms
db1=# insert into sales values (3,2019,3,3,'广州');
INSERT 0 1
Time: 109.118 ms
db1=# create table stage_sales (like sales);
NOTICE: Table doesn't have 'distributed by' clause, defaulting to distribution columns from LIKE table
CREATE TABLE
Time: 130.794 ms
db1=# \dt;
List of relations
Schema | Name | Type | Owner | Storage
--------+---------------+-------+---------+-------------
public | sales | table | gpadmin | append only
public | sales_1_prt_1 | table | gpadmin | append only
public | sales_1_prt_2 | table | gpadmin | append only
public | sales_1_prt_3 | table | gpadmin | append only
public | stage_sales | table | gpadmin | append only
(5 rows)
db1=# insert into stage_sales values (4,2017,4,4,'深圳');
INSERT 0 1
Time: 1559.465 ms
db1=# alter table sales exchange partition for (2017) with table stage_sales;
ALTER TABLE
Time: 61.744 ms
db1=# select * from sales;
id | year | month | day | region
----+------+-------+-----+--------
2 | 2018 | 2 | 2 | 上海
3 | 2019 | 3 | 3 | 广州
4 | 2017 | 4 | 4 | 深圳
(3 rows)
Time: 91.150 ms
db1=# select * from stage_sales;
id | year | month | day | region
----+------+-------+-----+--------
1 | 2017 | 1 | 1 | 北京
(1 row)
Time: 82.853 ms7. 分裂分区
分裂分区指的是将一个分区分裂成两个分区,HAWQ只能分裂单级分区表。
db1=# alter table sales split partition for (2017)
db1-# at (2016)
db1-# into (partition y016, partition y2017);
ERROR: cannot split partition with child partitions
HINT: Try splitting the child partitions.db1=# create table sales (id int, date date, amt decimal(10,2))
db1-# distributed by (id)
db1-# partition by range (date)
db1-# ( partition p201701 start (date '2017-01-01') inclusive ,
db1(# partition p201702 start (date '2017-02-01') inclusive
db1(# end (date '2017-03-01') exclusive );
NOTICE: CREATE TABLE will create partition "sales_1_prt_p201701" for table "sales"
NOTICE: CREATE TABLE will create partition "sales_1_prt_p201702" for table "sales"
CREATE TABLE
Time: 274.237 ms
db1=# insert into sales values (1, date '2017-01-15', 100);
INSERT 0 1
Time: 386.221 ms
db1=# insert into sales values (1, date '2017-01-16', 100);
INSERT 0 1
Time: 146.437 ms
db1=# select * from sales_1_prt_p201701;
id | date | amt
----+------------+--------
1 | 2017-01-15 | 100.00
1 | 2017-01-16 | 100.00
(2 rows)
Time: 117.187 ms
db1=# alter table sales split partition for ('2017-01-01') at ('2017-01-16')
db1-# into (partition p20170101to0115, partition p20170116to0131);
NOTICE: exchanged partition "p201701" of relation "sales" with relation "pg_temp_68011"
NOTICE: dropped partition "p201701" for relation "sales"
NOTICE: CREATE TABLE will create partition "sales_1_prt_p20170101to0115" for table "sales"
NOTICE: CREATE TABLE will create partition "sales_1_prt_p20170116to0131" for table "sales"
ALTER TABLE
Time: 446.998 ms
db1=# select * from sales_1_prt_p20170101to0115;
id | date | amt
----+------------+--------
1 | 2017-01-15 | 100.00
(1 row)
Time: 132.169 ms
db1=# select * from sales_1_prt_p20170116to0131;
id | date | amt
----+------------+--------
1 | 2017-01-16 | 100.00
(1 row)
Time: 86.589 msdb1=# alter table sales add default partition other;
NOTICE: CREATE TABLE will create partition "sales_1_prt_other" for table "sales"
ALTER TABLE
Time: 134.470 ms
db1=# insert into sales values (3, date '2017-03-01', 100);
INSERT 0 1
Time: 242.053 ms
db1=# insert into sales values (4, date '2017-04-01', 100);
INSERT 0 1
Time: 147.235 ms
db1=# select * from sales_1_prt_other;
id | date | amt
----+------------+--------
4 | 2017-04-01 | 100.00
3 | 2017-03-01 | 100.00
(2 rows)
Time: 79.584 ms
db1=# alter table sales split default partition
db1-# start ('2017-03-01') inclusive
db1-# end ('2017-04-01') exclusive
db1-# into (partition p201703, default partition);
NOTICE: exchanged partition "other" of relation "sales" with relation "pg_temp_68051"
NOTICE: dropped partition "other" for relation "sales"
NOTICE: CREATE TABLE will create partition "sales_1_prt_p201703" for table "sales"
NOTICE: CREATE TABLE will create partition "sales_1_prt_other" for table "sales"
ALTER TABLE
Time: 756.526 ms
db1=# select * from sales_1_prt_p201703;
id | date | amt
----+------------+--------
3 | 2017-03-01 | 100.00
(1 row)
Time: 89.353 ms
db1=# select * from sales_1_prt_other;
id | date | amt
----+------------+--------
4 | 2017-04-01 | 100.00
(1 row)
Time: 69.030 ms8. 修改子分区模板
ALTER TABLE SET SUBPARTITION TEMPLATE修改一个分区表的子分区模板。新模板只影响后面添加的数据,不修改现有的分区数据。
db1=# create table sales (trans_id int, date date, amount decimal(9,2), region text)
db1-# distributed by (trans_id)
db1-# partition by range (date)
db1-# subpartition by list (region)
db1-# subpartition template
db1-# ( subpartition usa values ('usa'),
db1(# subpartition asia values ('asia'),
db1(# subpartition europe values ('europe'),
db1(# default subpartition other_regions )
db1-# ( start (date '2017-01-01') inclusive
db1(# end (date '2017-04-01') exclusive
db1(# every (interval '1 month') );
NOTICE: CREATE TABLE will create partition "sales_1_prt_1" for table "sales"
...
CREATE TABLE
Time: 623.565 ms
db1=# alter table sales set subpartition template
db1-# ( subpartition usa values ('usa'),
db1(# subpartition asia values ('asia'),
db1(# subpartition europe values ('europe'),
db1(# subpartition africa values ('africa'),
db1(# default subpartition regions );
NOTICE: replacing level 1 subpartition template specification for relation "sales"
ALTER TABLE
Time: 49.767 ms
db1=# alter table sales add partition "4"
db1-# start ('2017-04-01') inclusive
db1-# end ('2017-05-01') exclusive ;
NOTICE: CREATE TABLE will create partition "sales_1_prt_4" for table "sales"
...
ALTER TABLE
Time: 414.251 ms
db1=# \dt sales*
List of relations
Schema | Name | Type | Owner | Storage
--------+-----------------------------------+-------+---------+-------------
public | sales | table | gpadmin | append only
public | sales_1_prt_1 | table | gpadmin | append only
public | sales_1_prt_1_2_prt_asia | table | gpadmin | append only
public | sales_1_prt_1_2_prt_europe | table | gpadmin | append only
public | sales_1_prt_1_2_prt_other_regions | table | gpadmin | append only
public | sales_1_prt_1_2_prt_usa | table | gpadmin | append only
public | sales_1_prt_2 | table | gpadmin | append only
public | sales_1_prt_2_2_prt_asia | table | gpadmin | append only
public | sales_1_prt_2_2_prt_europe | table | gpadmin | append only
public | sales_1_prt_2_2_prt_other_regions | table | gpadmin | append only
public | sales_1_prt_2_2_prt_usa | table | gpadmin | append only
public | sales_1_prt_3 | table | gpadmin | append only
public | sales_1_prt_3_2_prt_asia | table | gpadmin | append only
public | sales_1_prt_3_2_prt_europe | table | gpadmin | append only
public | sales_1_prt_3_2_prt_other_regions | table | gpadmin | append only
public | sales_1_prt_3_2_prt_usa | table | gpadmin | append only
public | sales_1_prt_4 | table | gpadmin | append only
public | sales_1_prt_4_2_prt_africa | table | gpadmin | append only
public | sales_1_prt_4_2_prt_asia | table | gpadmin | append only
public | sales_1_prt_4_2_prt_europe | table | gpadmin | append only
public | sales_1_prt_4_2_prt_regions | table | gpadmin | append only
public | sales_1_prt_4_2_prt_usa | table | gpadmin | append only
(22 rows)alter table sales set subpartition template ();9. 分区滚动窗口维护
在对数据表进行范围分区处理的基础上,可以进一步设计滚动数据的策略。通过维护一个数据滚动窗口,删除老分区,添加新分区,将老分区的数据迁移到数据仓库以外的次级存储,以节省系统开销。下面以一个常见的应用场景说明分区自动滚动的实现。假设一个数据仓库保留最近一年的销售记录,按日期每天一个分区。初始建立一年的分区,并装载近一年的数据,然后每天装载前一天的销售数据。
(1)建立分区表
create table sales (id int, date date, amt decimal(10,2))
distributed by (id)
partition by range (date)
( start (date '2016-03-01') inclusive
end (date '2017-05-01') exclusive
every (interval '1 day') );(2)创建动态滚动分区的函数
HAWQ从PostgreSQL继承了过程化编程,并使用多种语言。在我自己使用过的SQL-on-Hadoop产品中,HAWQ是唯一支持过程化编程的。而且,其内建函数、操作符和语法与Oracle极为接近,这对于传统数据库的开发管理人员及广大DBA是非常有吸引力的。在转到大数据平台时,他们可以复用原来积淀的知识与经验。仅凭这一点,HAWQ就可以在众多SQL-on-Hadoop解决方案中体现出独有的优势和价值。下一篇将详细描述HAWQ的过程化语言编程。
create or replace function fn_rolling_partition() returns int
as $body$
declare
oldest_month_first_day date := date(date_trunc('month',current_date) + interval '-13 month');
oldest_month_last_day date := date(date_trunc('month',current_date) + interval '-12 month - 1 day');
newest_month_first_day date := date(date_trunc('month',current_date) + interval '1 month');
newest_month_last_day date := date(date_trunc('month',current_date) + interval '2 month - 1 day');
i int;
j int;
sqlstring varchar(1000);
begin
-- 转储最早一个月的数据,
sqlstring = 'copy (select * from sales where date >= date(''' || oldest_month_first_day || ''') and date <= date(''' || oldest_month_last_day || ''')) to ''/home/gpadmin/sales_' || to_char(oldest_month_first_day,'YYYYMM') || '.txt'' with delimiter ''|'';';
execute sqlstring;
-- raise notice '%', sqlstring;
-- 删除最早月份对应的分区
i := 1;
j := oldest_month_last_day - oldest_month_first_day + 1;
for i in 1 .. j loop
sqlstring := 'alter table sales drop partition for (rank('|| i ||'));';
execute sqlstring;
end loop;
-- 增加下一个月份的新分区
while newest_month_first_day <= newest_month_last_day loop
sqlstring := 'alter table sales add partition start (date '''|| newest_month_first_day ||''') inclusive end (date '''|| (newest_month_first_day + 1) ||''') exclusive;';
execute sqlstring;
-- raise notice '%', sqlstring;
newest_month_first_day = newest_month_first_day + 1;
end loop;
-- 正常返回1
return 1;
-- 异常返回0
exception when others then
raise exception '%: %', sqlstate, sqlerrm;
return 0;
end
$body$ language plpgsql;(3)在cron中增加作业,例如,从下个月开始的每月一日两点执行分区滚动。
0 2 1 * * psql -d db1 -c "select fn_rolling_partition();" > rolling_partition.log 2>&1