一些关于程序内存布局的问题
1.内存布局
首先简单图解一下程序内存布局
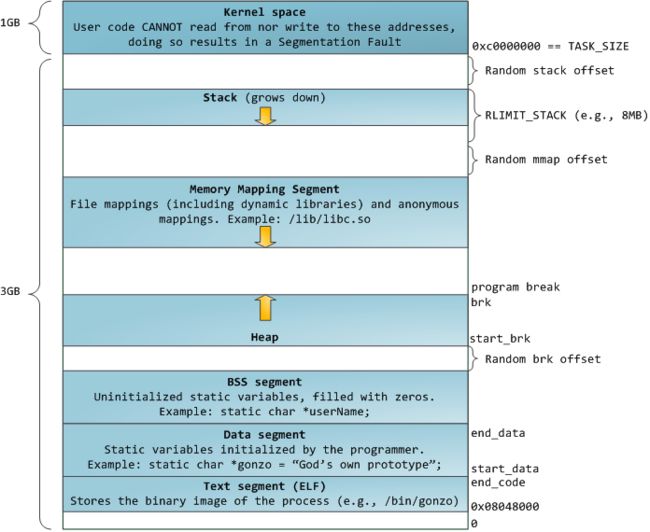
这时32位程序的内存布局,我们可以看到栈是自顶向下的扩展,而且是有界的。而堆是自底向上扩展。mmap映射区域自顶向下扩展。、
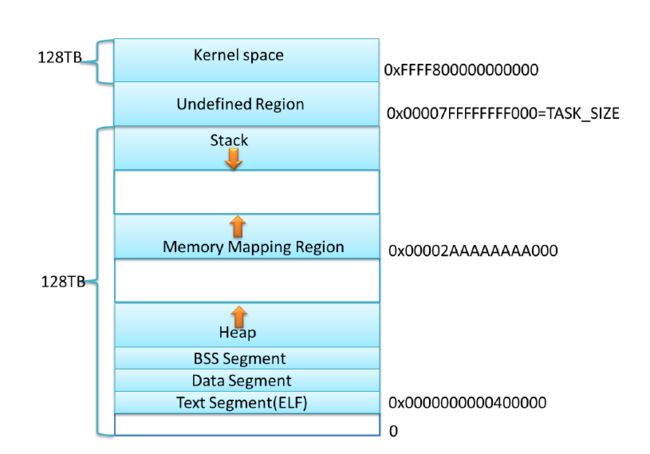
这是64位程序的内存布局,其中stack和map的起始地址是随机的。当然我们也可以通过设置/proc/sys/kernel/randomize_va_space特性来停用该特性,或者sudo sysctl -w kernel.randomize_va_space=0
2.栈
栈大小是有默认值的,当申请的临时变量太大或者函数调用深度过深会导致程序的栈空间不够用。这时我们需要修改栈大小
1.Linux系统:
ulimit -a #显示当前用户的栈大小
ulimit -s 32768 #将当前用户的栈大小设置为32M bytes
2. Windows (在编译过程中的设置):
1). 选择 "Project->Setting".
2). 选择 "Link".
3. 选择 "Category"中的 "Output".
3. 在 "Stack allocations"中的"Reserve:"中输栈的大小,例如: 32768
在 Visual Studio 开发环境中设置此链接器选项
- 打开此项目的“属性页”对话框。有关详细信息,请参见设置 Visual C++ 项目属性。
- 单击“链接器”文件夹。
- 单击“系统”属性页。
- 修改下列任一属性:
- 堆栈提交大小
- 堆栈保留大小
栈中调用函数的时候存在着三种函数调用协议——__stdcall、__cdecl和__fastcall,函数调用协议会影响函数参数的入栈方式、栈内数据的清除方式、编译器函数名的修饰规则等
- 调用协议常用场合
- __stdcall:Windows API默认的函数调用协议。
- __cdecl:C/C++默认的函数调用协议。
- __fastcall:适用于对性能要求较高的场合。
- 函数参数入栈方式
- __stdcall:函数参数由右向左入栈。
- __cdecl:函数参数由右向左入栈。
- __fastcall:从左开始不大于4字节的参数放入CPU的ECX和EDX寄存器,其余参数从右向左入栈。
- 栈内数据清除方式
- __stdcall:函数调用结束后由被调用函数清除栈内数据。
- __cdecl:函数调用结束后由函数调用者清除栈内数据。
- __fastcall:函数调用结束后由被调用函数清除栈内数据。
- c语言编译器函数名称修饰规则
- __stdcall:编译后,函数名被修饰为“_functionname@number”。
- __cdecl:编译后,函数名被修饰为“_functionname”。
- __fastcall:编译后,函数名给修饰为“@functionname@nmuber”。
3.堆
堆结构比较复杂,一般通过malloc和free来获取和释放。在glibc中使用ptmalloc来管理堆,当使用malloc的时候将返回一个chunk
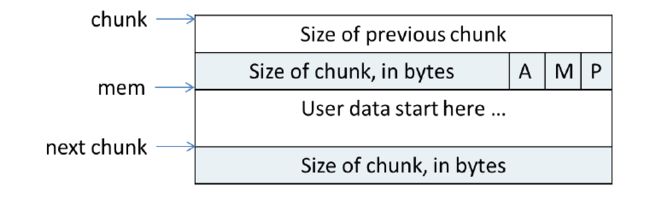
在图中,chunk指针指向一个chunk的开始,一个chunk中包含了用户请求的内存区域和相关的控制信息。图中的mem指针才是真正返回给用户的内存指针。chunk的第二个域的最低一位为P,它表示前一个块是否在使用中,P为0则表示前一个chunk为空闲,这时 chunk的第一个域prev_size才有效,prev_size表示前一个chunk的size,程序可以使用这个值来找到前一个chunk的开始地址。当P为1时,表示前一个chunk正在使用中,prev_size无效,程序也就不可以得到前一个chunk的大小。不能对前一个chunk进行任何操作。ptmalloc分配的第一个块总是将P设为1,以防止程序引用到不存在的区域。
Chunk的第二个域的倒数第二个位为M,他表示当前chunk是从哪个内存区域获得的虚拟内存。M为1表示该chunk是从mmap映射区域分配的,否则是从heap区域分配的。
Chunk的第二个域倒数第三个位为A,表示该chunk属于主分配区或者非主分配区,如果属于非主分配区,将该位置为1,否则置为0。
当free的时候返回一个空闲chunk,结构如下
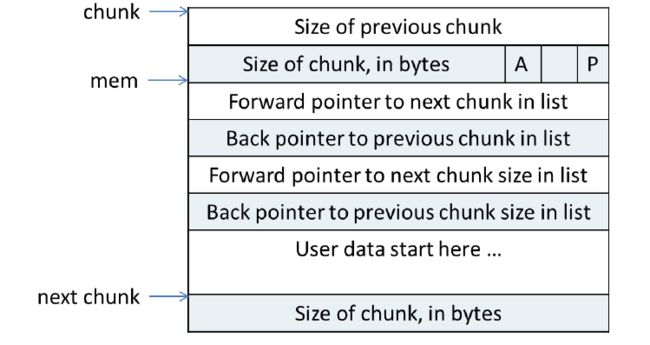
当chunk空闲时,其M状态不存在,只有AP状态,原本是用户数据区的地方存储了四个指针,指针fd指向后一个空闲的chunk,而bk指向前一个空闲的chunk,ptmalloc通过这两个指针将大小m相近的chunk连成一个双向链表。对于large bin中的空闲chunk,还有两个指针,fd_nextsize和bk_nextsize,这两个指针用于加快在large bin中查找最近匹配的空闲chunk。不同的chunk链表又是通过bins或者fastbins来组织的。
空闲的chunk容器并没有直接返回给系统,而是使用一个数组统一管理。并将相似大小的chunk用双向链表连接起来存放在一个数组的位置。数组第一位是unsorted bin,2-64是small bin,一个small bin的chunl有相同大小。后面的是large bins。larger bins中每一个bin有给定范围的chunk,并按大小序排序。在unsorted bin中放了之前释放的chunk——保证速度的同时也保证了局部访问。而fast bins中放了许多小型的bins,且不合并,以便快速的分配一些小型的chunk
ptmalloc分配内存的具体流程如下所示:
- 获取分配区的锁,为了防止多个线程同时访问同一个分配区,在进行分配之前需要取得分配区域的锁。线程先查看线程私有实例中是否已经存在一个分配区,如果存在尝试对该分配区加锁,如果加锁成功,使用该分配区分配内存,否则,该线程搜索分配区循环链表试图获得一个空闲(没有加锁)的分配区。如果所有的分配区都已经加锁,那么ptmalloc会开辟一个新的分配区,把该分配区加入到全局分配区循环链表和线程的私有实例中并加锁,然后使用该分配区进行分配操作。开辟出来的新分配区一定为非主分配区,因为主分配区是从父进程那里继承来的。开辟非主分配区时会调用mmap()创建一个sub-heap,并设置好top chunk。
- 将用户的请求大小转换为实际需要分配的chunk空间大小。
- 判断所需分配chunk的大小是否满足chunk_size <= max_fast (max_fast 默认为 64B),如果是的话,则转下一步,否则跳到第5步。
- 首先尝试在fast bins中取一个所需大小的chunk分配给用户。如果可以找到,则分配结束。否则转到下一步。
- 判断所需大小是否处在small bins中,即判断chunk_size < 512B是否成立。如果chunk大小处在small bins中,则转下一步,否则转到第6步。
- 根据所需分配的chunk的大小,找到具体所在的某个small bin,从该bin的尾部摘取一个恰好满足大小的chunk。若成功,则分配结束,否则,转到下一步。
- 到了这一步,说明需要分配的是一块大的内存,或者small bins中找不到合适的 chunk。于是,ptmalloc首先会遍历fast bins中的chunk,将相邻的chunk进行合并,并链接到unsorted bin中,然后遍历unsorted bin中的chunk,如果unsorted bin只有一个chunk,并且这个chunk在上次分配时被使用过,并且所需分配的chunk大小属于small bins,并且chunk的大小大于等于需要分配的大小,这种情况下就直接将该chunk进行切割,分配结束,否则将根据chunk的空间大小将其放入small bins或是large bins中,遍历完成后,转入下一步。
- 到了这一步,说明需要分配的是一块大的内存,或者small bins和unsorted bin中都找不到合适的 chunk,并且fast bins和unsorted bin中所有的chunk都清除干净了。从large bins中按照“smallest-first,best-fit”原则,找一个合适的 chunk,从中划分一块所需大小的chunk,并将剩下的部分链接回到bins中。若操作成功,则分配结束,否则转到下一步。
- 如果搜索fast bins和bins都没有找到合适的chunk,那么就需要操作top chunk来进行分配了。判断top chunk大小是否满足所需chunk的大小,如果是,则从top chunk中分出一块来。否则转到下一步。
- 到了这一步,说明top chunk也不能满足分配要求,所以,于是就有了两个选择: 如果是主分配区,调用sbrk(),增加top chunk大小;如果是非主分配区,调用mmap来分配一个新的sub-heap,增加top chunk大小;或者使用mmap()来直接分配。在这里,需要依靠chunk的大小来决定到底使用哪种方法。判断所需分配的chunk大小是否大于等于 mmap分配阈值,如果是的话,则转下一步,调用mmap分配,否则跳到第12步,增加top chunk 的大小。
- 使用mmap系统调用为程序的内存空间映射一块chunk_size align 4kB大小的空间。 然后将内存指针返回给用户。
- 判断是否为第一次调用malloc,若是主分配区,则需要进行一次初始化工作,分配一块大小为(chunk_size + 128KB) align 4KB大小的空间作为初始的heap。若已经初始化过了,主分配区则调用sbrk()增加heap空间,分主分配区则在top chunk中切割出一个chunk,使之满足分配需求,并将内存指针返回给用户
ptmalloc使用free回收内存的大致流程如下
- free()函数同样首先需要获取分配区的锁,来保证线程安全。
- 判断传入的指针是否为0,如果为0,则什么都不做,直接return。否则转下一步。
- 判断所需释放的chunk是否为mmaped chunk,如果是,则调用munmap()释放mmaped chunk,解除内存空间映射,该该空间不再有效。如果开启了mmap分配阈值的动态调整机制,并且当前回收的chunk大小大于mmap分配阈值,将mmap分配阈值设置为该chunk的大小,将mmap收缩阈值设定为mmap分配阈值的2倍,释放完成,否则跳到下一步。
- 判断chunk的大小和所处的位置,若chunk_size <= max_fast,并且chunk并不位于heap的顶部,也就是说并不与top chunk相邻,则转到下一步,否则跳到第6步。(因为与top chunk相邻的小chunk也和 top chunk进行合并,所以这里不仅需要判断大小,还需要判断相邻情况)
- 将chunk放到fast bins中,chunk放入到fast bins中时,并不修改该chunk使用状态位P。也不与相邻的chunk进行合并。只是放进去,如此而已。这一步做完之后释放便结束了,程序从free()函数中返回。
- 判断前一个chunk是否处在使用中,如果前一个块也是空闲块,则合并。并转下一步。
- 判断当前释放chunk的下一个块是否为top chunk,如果是,则转第9步,否则转下一步。
- 判断下一个chunk是否处在使用中,如果下一个chunk也是空闲的,则合并,并将合并后的chunk放到unsorted bin中。注意,这里在合并的过程中,要更新chunk的大小,以反映合并后的chunk的大小。并转到第10步。
- 如果执行到这一步,说明释放了一个与top chunk相邻的chunk。则无论它有多大,都将它与top chunk合并,并更新top chunk的大小等信息。转下一步。
- 判断合并后的chunk 的大小是否大于FASTBIN_CONSOLIDATION_THRESHOLD(默认64KB),如果是的话,则会触发进行fast bins的合并操作,fast bins中的chunk将被遍历,并与相邻的空闲chunk进行合并,合并后的chunk会被放到unsorted bin中。fast bins将变为空,操作完成之后转下一步。
- 判断top chunk的大小是否大于mmap收缩阈值(默认为128KB),如果是的话,对于主分配区,则会试图归还top chunk中的一部分给操作系统。但是最先分配的128KB空间是不会归还的,ptmalloc 会一直管理这部分内存,用于响应用户的分配请求;如果为非主分配区,会进行sub-heap收缩,将top chunk的一部分返回给操作系统,如果top chunk为整个sub-heap,会把整个sub-heap还回给操作系统。做完这一步之后,释放结束,从 free() 函数退出。可以看出,收缩堆的条件是当前free的chunk大小加上前后能合并chunk的大小大于64k,并且要top chunk的大小要达到mmap收缩阈值,才有可能收缩堆。
4.data
data段里一般存放着静态全局变量和显示初始化为非零的全局变量
5.bss
一般存放着显示初始化为0的全局变量和未显式初始化的全局变量