scrapy搭建分布式爬虫
一.准备工作
1.Redis数据库及可视化工具
Windows百度网盘链接:https://pan.baidu.com/s/1Wz09FdXN4jWn5I4SRSF5-w
提取码:kxvz
或者https://github.com/microsoftarchive/redis/releases从这里下载自己需要的版本
2.我这里是使用两个linux系统的克隆来做我的Windows系统的Slaver,windows系统做Master,Redis安装到Windows就可以,使用xshell通过ip来连接操控两个虚拟机,通过xftp向虚拟机装python环境和传入我要运行的代码,
3.使用scrapy_redis完成该分布式爬虫,
二、开始
1.通过scrapy框架编写一个正常的爬虫文件,我这里爬的是链家二手房,
lianjia.py
# -*- coding: utf-8 -*-
import scrapy
from scrapy_redis.spiders import RedisSpider
class LianjiaSpider(RedisSpider):
name = 'lianjia'
allowed_domains = ['lianjia.com']
start_urls = ['https://bj.lianjia.com/ershoufang/pg{}/'.format(num) for num in range(1, 10)]
index = 3
base_url = 'https://bj.lianjia.com/ershoufang/pg{}/'
#base_url = 'https://bj.lianjia.com/ershoufang/pg1/'
def parse(self, response):
urls = response.xpath('//div[@class="info clear"]/div[@class="title"]/a/@href').extract()
for url in urls:
yield scrapy.Request(url, callback=self.parse_info)
if self.index < 1000:
yield scrapy.Request(self.base_url.format(self.index), callback=self.parse)
self.index = self.index + 2
def parse_info(self, response):
total = response.xpath(
'concat(//span[@class="total"]/text(),//span[@class="unit"]/span/text())').extract_first()
unitPriceValue = response.xpath('string(//span[@class="unitPriceValue"])').extract_first()
xiao_qu = response.xpath('//div[@class="communityName"]/a[1]/text()').extract_first()
qu_yu = response.xpath('string(//div[@class="areaName"]/span[@class="info"])').extract_first()
base = response.xpath('//div[@class="base"]//ul')
hu_xing = base.xpath('./li[1]/text()').extract_first()
lou_ceng = base.xpath('./li[2]/text()').extract_first()
mian_ji = base.xpath('./li[3]/text()').extract_first()
zhuang_xiu = base.xpath('./li[9]/text()').extract_first()
gong_nuan = base.xpath('./li[last()-2]/text()').extract_first()
chan_quan = base.xpath('./li[last()]/text()').extract_first()
transaction = response.xpath('//div[@class="transaction"]//ul')
yong_tu = transaction.xpath('./li[4]/span[2]/text()').extract_first()
nian_xian = transaction.xpath('./li[last()-3]/span[2]/text()').extract_first()
di_ya = transaction.xpath('./li[last()-1]/span[2]/text()').extract_first()
yield {
"total": total,
"unitPriceValue": unitPriceValue,
"xiao_qu": xiao_qu,
"qu_yu": qu_yu,
"hu_xing": hu_xing,
"lou_ceng": lou_ceng,
"mian_ji": mian_ji,
"zhuang_xiu": zhuang_xiu,
"gong_nuan": gong_nuan,
"chan_quan": chan_quan,
"yong_tu": yong_tu,
"nian_xian": nian_xian,
"di_ya": di_ya
}
直接在pipeline中保存
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import pymongo
from pymysql import connect
class MongoPipeline(object):
def open_spider(self, spider):
self.client = pymongo.MongoClient()
def process_item(self, item, spider):
self.client.room.lianjia.insert(item)
return item
def close_spider(self, spider):
self.client.close()
class MysqlPipeline(object):
def open_spider(self, spider):
self.client = connect(host='localhost', port=3306, user='root', password='123', db='room', charset="utf8")
self.cursor = self.client.cursor()
def process_item(self, item, spider):
args = [item["total"],
item["unitPriceValue"],
item["xiao_qu"],
item["qu_yu"],
item["hu_xing"],
item["lou_ceng"],
item["mian_ji"],
item["zhuang_xiu"],
item["gong_nuan"],
item["chan_quan"],
item["yong_tu"],
item["nian_xian"],
item["di_ya"]]
sql = 'insert into t_lianjia VALUES (0,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)'
self.cursor.execute(sql, args)
self.client.commit()
return item
def close_spider(self, spider):
self.cursor.close()
self.client.close()
在settings.py中配置好Itempipeline,
添加修改
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
然后在当前目录下简历start.py
写入代码
from scrapy.cmdline import execute
execute('scrapy crawl lianjia'.split())
运行start.py,项目运行成功
分布式
接下来开始改写为分布式
settings中设置:
SCHEDULER = “scrapy_redis.scheduler.Scheduler”
DUPEFILTER_CLASS = “scrapy_redis.dupefilter.RFPDupeFilter”
ITEM_PIPELINES = {
‘scrapy_redis.pipelines.RedisPipeline’: 300
}
REDIS_HOST = “192.168.1.101”
REDIS_PORT = 6379
这里是我的IP地址,需要换成Master的IP地址,6379是默认的Redis端口号
lianjia.py里将
start_urls = [‘https://bj.lianjia.com/ershoufang/pg{}/’.format(num) for num in range(1, 10)]
替换成
redis_key = 'lianjia:start_urls'
Slaver中的Redis ip 应该写主机Master的IP地址,主机中的ip写127.0.0.1就可以
可以将完整的项目复制到两个虚拟机中,然后先启动虚拟机中的项目,会发现他俩运行一会就会一直等待,然后运行Master的项目发现redis数据库中出现如下图的界面,
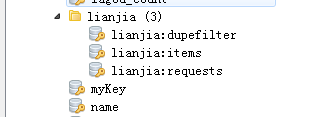
dupefilter – set类型,用于爬虫访问的URL去重
items – list 类型,保存爬虫获取到的数据item
requests --zset类型,用于scheduler调度处理 requests
这样就说明保存到Redis数据库中,也可以自己写存储到MongoDB数据库的代码。
在master服务器上搭建一个redis数据库,并将要抓取的url存放到redis数据库中,所有的slave爬虫服务器在抓取的时候从redis数据库中去链接,由于scrapy_redis自身的队列机制,slave获取的url不会相互冲突,然后抓取的结果最后都存储到数据库中。master的redis数据库中还会将抓取过的url的指纹存储起来,用来去重。
相关代码在dupefilter.py文件中的request_seen()方法中可以找到。
去重问题:
dupefilter.py 里面的源码:
def request_seen(self, request):
fp = request_fingerprint(request)
added = self.server.sadd(self.key, fp)
return not added
去重是把 request 的 fingerprint 存在 redis 上,来实现的。
这是我学习的一点想法,写在这里当做笔记,有不对的地方请多指教。