深入浅出解析mssql在高频,高并发访问时键查找死锁问题
SQL Server死锁使我们经常遇到的问题,数据库操作的死锁是不可避免的,本文并不打算讨论死锁如何产生,重点在于解决死锁。希望对您学习SQL Server死锁方面能有所帮助。
死锁对于DBA或是数据库开发人员而言并不陌生,它的引发多种多样,一般而言,数据库应用的开发者在设计时都会有一定的考量进而尽量避免死锁的产生.但有时因为一些特殊应用场景如高频查询,高并发查询下由于数据库设计的潜在问题,一些不易捕捉的死锁可能出现从而影响业务.这里为大家介绍由于设计问题引起的键查找死锁及相关的解决办法.
这里我们在测试的同时开启trace profiler跟踪死锁视图(locks:deadlock graph).(当然也可以开启跟踪标记,或者应用扩展事件(xevents)等捕捉死锁)
创建测试对象code:
create table testklup
(
clskey int not null,
nlskey int not null,
cont1 int not null,
cont2 char(3000)
)
create unique clustered index inx_cls on testklup(clskey)
create unique nonclustered index inx_nlcs on testklup(nlskey) include(cont1)
insert into testklup select 1,1,100,'aaa'
insert into testklup select 2,2,200,'bbb'
insert into testklup select 3,3,300,'ccc'
开启会话1 模拟高频update操作
----模拟高频update操作
declare @i int
set @i=100
while 1=1
begin
update testklup set cont1=@i
where clskey=1
set @i=@i+1
end
开启会话2 模拟高频select操作
----模拟高频select操作
declare @cont2 char(3000)
while 1=1
begin
select @cont2=cont2 from testklup where nlskey=1
end
此时开启会话2执行一小段时间时我们就可以看到类似错误信息:图1-1
图1-1

而在我们开启的跟踪中捕捉到了如下的死锁图.图1-2
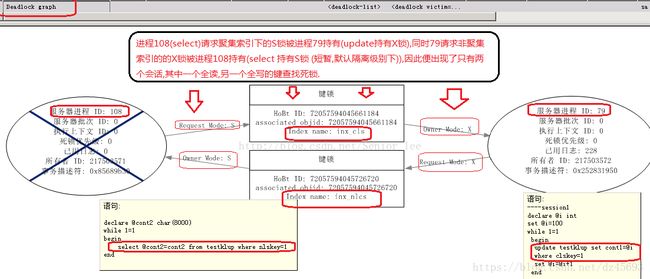
图1-2
死锁分析:可以看出由于读进程(108)请求写进程(79)持有的X锁被阻塞的同时,写进程(79)又申请读进程(108)锁持有的S锁.读执行计划图1-3,写执行计划图1-4
(由于在默认隔离级别下(读提交)读申请S锁只是瞬间过程,读完立即释放,不会等待事务完成),所以在并发,执行频率不高的情形下不易出现.但我们模拟的高频情况使得S锁获得频率非常高,此时就出现了仅仅两个会话,一个读,一个写就造成了死锁现象.

图1-3

图1-4
死锁原因:读操作中的键查找造成的额外锁(聚集索引)需求
解决方案:在了解了死锁产生的原因后,解决起来就比较简单了.
我们可以从以下几个方面入手.
a 消除额外的键查找锁需的锁
b 读操作时取消获取锁
a.1我们可以创建覆盖索引使select语句中的查询列包含在指定索引中
CREATE NONCLUSTERED INDEX [inx_nlskey_incont2] ON [dbo].[testklup]
([nlskey] ASC) INCLUDE ( [cont2])
a.2 根据查询需求,分步执行,通过聚集索引获取查询列,避免键查找.
declare @cont2 char(3000)
declare @clskey int
while 1=1
begin
select @clskey=clskey from testklup where nlskey=1
select @cont2=cont2 from testklup where clskey=@clskey
end
b 通过改变隔离级别,使用乐观并发模式,读操作时源行无需锁
declare @cont2 char(3000)
while 1=1
begin
select @cont2=cont2 from testklup with(nolock) where nlskey=1
end
结束语.我们在解决问题时,最好弄清问题的本质原因,通过问题点寻找出适合自己的环境的解决方案再实施.
在sqlserver标准的已提交读(read committed)隔离级别下,读写操作相互阻塞。未提交读(read uncommitted)虽然不会有这种阻塞,但是读操作可能会读到脏数据,这是大部分用户不能接受的。
ORACLE使用的是另一种处理方式:在任何一个修改之前,先对修改前的版本做一个复制,后续的一切读操作都会去读这个复制的版本,修改将创建一个新的版本。在这种处理方式下,读写操作不会互相阻塞。使用这种行版本控制机制的好处,是系统的并发性比较高,但是缺点是用户读到的虽然不是一个脏数据,但是可能是个正在被修改马上就要过期的数据。如果根据这个过期的值做数据修改,可能会产生逻辑错误。
有些用户为了更高的并发性而不在乎这种缺点,所以更喜欢ORACLE的那种处理方法。
为了满足这部分用户的需求,SQL2005也引入了这种机制,来实现类似的功能。所以选取行版本控制隔离级别也可以成为消除阻塞和死锁的一种手段。
--查询数据库状态
select name,user_access,user_access_desc,
snapshot_isolation_state,snapshot_isolation_state_desc,
is_read_committed_snapshot_on
from sys.databases
GO
---启用指定数据库的快照隔离
ALTER DATABASE [dbName] SET SINGLE_USER WITH ROLLBACK IMMEDIATE
GO
ALTER DATABASE [dbName] SET ALLOW_SNAPSHOT_ISOLATION ON
GO
ALTER DATABASE [dbName] SET READ_COMMITTED_SNAPSHOT ON
GO
ALTER DATABASE [dbName] SET MULTI_USER
GO
开启了行版本控制之后,sqlserver会把行版本存放在tempdb里。修改的数据越多,需要存储的信息越多,对sqlserver额外的负载就越大。所以如果一个应用要从其他隔离级别转向使用行版本控制,需要做特别的测试,以确保现有的软硬件配置能支持额外的负荷,应用程序能够达到相似的响应速度。