比价网站的基础-爬取淘宝的商品信息
淘宝网站,页面上有很多动态加载的AJAX请求,并且很多参数做过加密处理,如果直接分析网页,会非常繁琐,难度极大。本文利用selenium驱动chrome浏览器完成关键字输入、搜索、点击等功能,完成页面的信息的获取,并利用pyquery库进行解析,获取商品信息并将信息存入mongodb。
selenium库的安装已经具体使用方法详见博客http://blog.csdn.net/qq_29186489/article/details/78661008,
关于mongodb的安装与配置,详见博客http://blog.csdn.net/qq_29186489/article/details/78546727,本文不再赘述。
抓取思路分析##
1:利用selenium驱动chrome浏览器进入淘宝网站,手工输入账号密码后,获取cookies,并存储到本地;在爬取程序运行时,从本地加载cookies,维持登录;
2:利用selenium驱动chrome浏览器进入淘宝网站,输入关键词“美食”,并点击搜索按钮,得到商品查询后的列表;
 3:加载搜索结果页面完成后,分析页码,得到商品的页码数,模拟翻页,每次翻页,停止10-30秒的休眠时间,得到后续页面的商品列表;
3:加载搜索结果页面完成后,分析页码,得到商品的页码数,模拟翻页,每次翻页,停止10-30秒的休眠时间,得到后续页面的商品列表;
4:利用pyquery解析页面,分析获取商品信息;
5:将获取到的商品信息存储到mongodb中,供后续分析使用。
编码实现
一:获取cookies,并存储到本地
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
import time
import json
browser=webdriver.Chrome()
browser.get("https://www.taobao.com")
input=browser.find_element_by_css_selector("#q")
input.send_keys("ipad")
button=browser.find_element_by_class_name("btn-search")
button.click()
#留下时间,扫描二维码登录
time.sleep(20)
#登录后,保存cookies到本地
dictCookies=browser.get_cookies()
jsonCookies=json.dumps(dictCookies)
with open("cookies.txt","w") as f:
f.write(jsonCookies)
browser.close()
二:加载cookies,运行爬虫程序,获取商品信息
1:引入相关类库
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import re
from pyquery import PyQuery as pq
import pymongo
import random
import time
2:定义MONGO数据库的链接参数
MONGO_URL="LOCALHOST"
MONGO_DB="taobao"
MONGO_TABLE="product"
client=pymongo.MongoClient(MONGO_URL)
db=client[MONGO_DB]
3:加载cookies信息,并维持登录
#加载cookie,维持登录
def load_cookie(browser,file):
browser.get("https://www.taobao.com")
browser.maximize_window()
browser.delete_all_cookies()
# 读取登录时存储到本地的cookie
with open(file, 'r', encoding='utf-8') as f:
listCookies = json.loads(f.read())
for cookie in listCookies:
browser.add_cookie(cookie)
browser.refresh()
return browser
3:搜索商品信息
#搜索商品信息
def search_html(browser):
try:
browser=load_cookie(browser,"cookies.txt")
#等待搜索框加载并获取该元素
input_element=WebDriverWait(browser,10).until(
EC.presence_of_element_located((By.CSS_SELECTOR,"#q"))
)
#等待搜索按钮并获取该元素
search_button=WebDriverWait(browser,10).until(
EC.presence_of_element_located((By.CSS_SELECTOR,"#J_TSearchForm > div.search-button > button"))
)
#输入关键字 美食
input_element.send_keys("美食")
#点击搜索按钮
search_button.click()
page_total_num=WebDriverWait(browser,10).until(
EC.presence_of_element_located((By.CSS_SELECTOR,"#mainsrp-pager > div > div > div > div.total"))
)
num=re.findall('共.*?(\d+).*?页',page_total_num.text,re.S)[0]
#time.sleep(1000)
return num
except TimeoutException:
return None
4:实现翻页功能
#实现翻页功能,由于淘宝的反抓取设置,翻页太快会被屏蔽,翻页时间设置为15秒每次
def next_page(page_num):
try:
#等待页码输入框加载成功,并获取该对象
input_pagenum=WebDriverWait(browser,10).until(
EC.presence_of_element_located((By.CSS_SELECTOR,"#mainsrp-pager > div > div > div > div.form > input"))
)
#等待翻页确定按钮加载成功,并获取该对象
button_confirm=WebDriverWait(browser,10).until(
EC.presence_of_element_located((By.CSS_SELECTOR,"#mainsrp-pager > div > div > div > div.form > span.btn.J_Submit"))
)
#清空页码输入框
input_pagenum.clear()
#输入跳转的页码
input_pagenum.send_keys(page_num)
#点击页码跳转确认按钮
button_confirm.click()
#判断跳转后页面的页面是否和输入的一致
WebDriverWait(browser,10).until(
EC.text_to_be_present_in_element((By.CSS_SELECTOR,"#mainsrp-pager > div > div > div > ul > li.item.active > span"),str(page_num))
)
#每隔10-30秒随机事件翻页
time.sleep(random.randint(10, 30))
except TimeoutException:
next_page(page_num)
5:解析网页代码,获取商品信息
#解析网页代码,获取商品信息
def get_products():
#判断商品信息是否加载完成
WebDriverWait(browser,10).until(EC.presence_of_element_located((By.CSS_SELECTOR,"#mainsrp-itemlist .items .item")))
#获取加载完成的网页代码
html=browser.page_source
#利用pyquery解析网页代码
doc=pq(html)
#获取所有的商品信息的列表
items=doc("#mainsrp-itemlist .items .item").items()
#遍历获取每个商品的信息
for item in items:
product={
'image':item.find(".pic .img").attr("src"),
'price':item.find(".price").text(),
'deal':item.find(".deal-cnt").text()[:-3],
'title':item.find(".title").text(),
'shop':item.find(".shop").text(),
'location':item.find(".location").text()
}
save_to_mongo(product)
6:将结果存储到mongodb中
def save_to_mongo(result):
try:
if db[MONGO_TABLE].insert(result):
print("存储到mongodb成功",result)
except Exception:
print("存储到mongodb失败",result)
7:程序入口
try:
browser = webdriver.Chrome()
total_num=int(search_html(browser))
for page_num in range(2,total_num+1):
get_products(browser)
next_page(page_num)
except:
print("运行出错,请重试!")
finally:
browser.close()
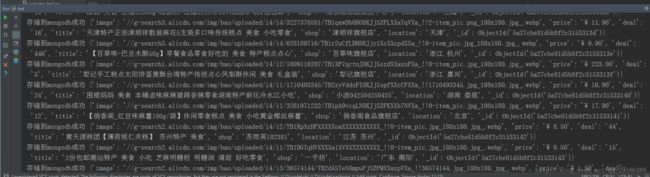
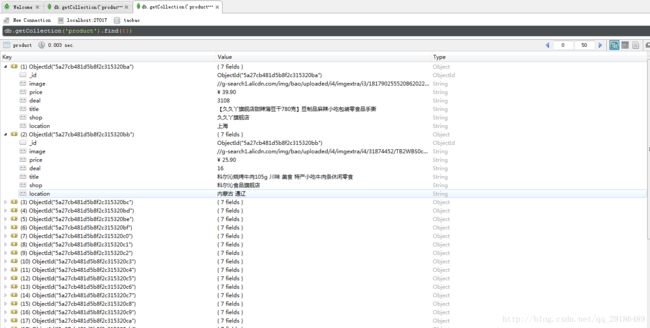
程序运行结果
控制台截图
数据库截图
程序完整代码下载地址
https://code.csdn.net/qq_29186489/taobaoproduct/tree/master/taobaoproduct.py