OkHttp3-请求器-连接-拦截器
本文为译文,由于译者水平有限,欢迎拍砖,读者也可以阅读原文
【OkHttp3-基本用法,OkHttp3-使用进阶(Recipes),OkHttp3-请求器(Calls),OkHttp3-连接(Connections),OkHttp3-拦截器(Interceptor)】
OkHttp3-请求器(Calls)
OkHttp客户端负责接收应用程序发出的请求,并且从服务器获取响应返回给应用程序。理论听起来十分简单,但是在实践中往往会出现很多意想不到的因素。
请求 (Request)
每一个Http请求都包含一个URL和一个请求方式(比如Get或者Post),以及一些请求头信息。请求也有可能包含一个请求主体:当一个数据流存在指定的content type类型的请求头时。
响应 (Responses)
服务器根据请求向你的应用程序返回响应,此响应包含了一个状态码(比如200表示请求成功,404表示请求失败)、响应头、以及可能包含的响应主体。
重写请求 (Rewriting Requests)
OkHttp所发出去的每个Http请求都是高等级的:`“fetch me this URL with these headers.”。为了请求的正确性和高效性,OkHttp在数据传输之前会自动重写你的请求。
OkHttp可以自动为你的请求添加一些请求所没有的请求头,包括Content-Length、Transfer-Encoding、User-Agent、Host、Connection,以及Content-Type。 如果你的原生请求中没有定义Accept-Encoding类型,那么OkHtpp会自动为请求添加Accept-Encoding类型为Gzip,以此希望服务端能返回压缩过的数据。如果应用程序中存在Cookies,那么OkHttp将会自动将它们添加到你的请求的Cookie头部信息中。
OkHttp会将一些请求的响应缓存起来。当其中的一个缓存过期时,OkHttp将会发送一个带有特定的请求头信息(比如If-Modified-Since或者If-None-Match),并且以Get方式请求去重新从服务器上获取数据,并且如果所获取的新数据与旧的缓存数据不一致,OkHttp将新的数据保存覆盖掉旧的缓存。
重写响应 (Rewriting Responses)
如果响应主体是经过压缩处理,那么OkHttp会自动将响应头部中的Content-Encoding和Content-Length去掉,因为它们并不适用于解压缩响应主体的操作。
如果一个请求方法为Get的网络请求执行成功,那么正常情况下从服务器返回的响应将会和缓存进行合并。
跟踪请求 (Follow-up Requests)
当你所请求的主机的URL发生改变时,服务器将会返回一个为302的响应状态码以及新的URL信息。OkHttp将会根据这个URL进行重定向操作,并且再次向新的URL发送请求获取数据。
当你发送请求时,服务器可能会返回一个响应告诉你需要进行身份基本认证,那么OkHttp此时会自动告诉Authenticator去解决这个认证问题,当然,Authenticator需要你自己进行配置。Authenticator处理身份认证通过时会获取到认证成功凭证,OkHttp会携带着它再次向服务器发送原来的请求。
重试请求 (Retrying Requests)
有的时候会发生连接失败:可能连接池过期而导致连接断开,或者请求的服务器无法找到。OkHttp将会不断尝试不同的可用线路去发送请求。
请求器 (Calls)
通过重写、重定向、跟踪以及重试,你发送的一个简单的请求可能会变成需要发送多个请求以及接收多次响应之后才能获得最后的想要的响应。OkHttp会将这些全部请求以及响应(你的一个请求任务)塑造成一个Call对象,然而请求过程中所发生的多次请求以及响应是必须的。但是通常情况下中间请求及响应工作不会很多!令人欣慰的是,无论发生URL重定向还是因为服务器出现问题而向一个备用IP地址再次发送请求的情况,你的代码都会一直正常运行。
执行Call有两种方式:
- 同步:请求和处理响应发生在同一线程。并且此线程会在响应返回之前会一直被堵塞。
- 异步:请求和处理响应发生在不同线程。将发送请求操作发生在一个线程,并且通过回调的方式在其他线程进行处理响应。(一般在子线程发送请求,主线程处理响应)
Calls可以在任何线程被取消。当这个Call尚未执行结束时,执行取消操作将会直接导致此Call失败!当一个Call被取消时,无论是写入请求主体或者读取响应主体的代码操作,都会抛出一个IOException异常。
调度者 (Dispatch)
对于在同步线程中执行Call而言,你最好创建子线程并且手动管理你所发出的并发请求。因为太多并发连接浪费资源,以及可能会导致发生一些不好的小问题。
对于异步线程执行Call而言,Dispactcher实现了一个限制最大并发的接口。你也可以自定义设置对于每台主机的最大并发数(默认为5),以及总的并发数(默认为64)。
OkHttp3-连接(Connections)
虽然通常你只需要提供一个URL给OkHttp,OkHttp就可以帮你完成其他事情。但是实际上OkHttp连接服务器需要三个条件:URL,Address,Route。
URLs(统一资源定位符)
提供一个URL(比如https://github.com/square/okhttp)让Http去连接服务器是最基本的工作。还有一种渐渐普遍的文件定位方式称为URN(同意名称定位符),它是利用一种分散式的命名方案去指定所需要访问的资源文件。
URLs是抽象的:
-
URL可以指定请求的类型是明文(Http)或者是密文(Https),但是无法指定使用的是哪个加密算法,也无法指定怎样去验证证书(HostnameVerifier)或者指定哪种证书可以被验证(SSLSocketFactory)。 -
URL无法指定使用哪些代理服务器,以及指定哪些代理服务器进行身份认证。
URL是具体的:
- 每一个
URL都可以定义一个指定的路径(比如/square/okhttp)以及查询条件(比如?q=sharks&lang=en)。每个主机可以拥有多个URL。
Address(地址)
Address在OKHttp中是一个对象,它为OkHttp提供静态配置!
地址指定了一个服务器(比如github.com)以及连接此服务器所需要的静态配置:端口号,HTTPS设置,以及指定的网络协议(比如HTTP/2或者SPDY)。
相同地址的URL也可以共用相同的底层TCP Socket连接。共用相同的连接对于性能有很大的提升:更低的延迟,更大的吞吐量(复用连接,由于每个TCP启动的都需要较多的准备工作),更少的电能损耗。OkHttp使用一个连接池,来自动复用HTTP/1.x connections、HTTP/2、SPDY连接。
URL为地址提供了一些字段(比如域名、主机名、端口号),其他的字段都来自于OkHttpClient。
Routes(路由)
Routes在OKHttp中是一个对象,它为OkHttp提供动态配置!
路由提供了实际连接到服务器所需要的动态配置。比如所指定用来尝试连接服务器的IP地址(从DNS服务商获得)、连接过程中实际所使用到的代理服务器(如果使用了ProxySelector),以及使用的是哪个版本的
TLS协议(当使用Https协议连接时候需要)。
对于一个地址来说 ,可能存在有很多种路由的方式。比如,当一个服务器被托管在多个数据中心,这时路由从DNS供应商获取的响应中就可以获取到多个IP地址。
Connections(连接)
当你使用OkHttp去请求一个URL时,OkHttp为你做了如下事情:
- OkHttp使用一个
URL以及经过配置的OkHttpClient去创建一个address。这个address表示我们将如何连接服务器。 - OkHttp尝试从连接池中获取一个适用于此
address的Connection。 - 如果OkHttp没有找到对应的
Connection,那么OkHttp就会选择一条路由去尝试创建连接。这通常意味着需要向DNS供应商发送一个请求去获取这个服务器的IP地址,以及可能还需要选择TLS版本和代理服务器。 - 如果此路由是一条新的路由,它将通过构建一个
Socket连接,一个TLS连接(通过Http代理的Https),或者直接通过一个TLS进行连接(它需要TLS握手)。 - OkHttp发送
Http请求并读取响应。
如果在连接的过程中出现问题,那么OkHttp将会选择其他的路由进行重新连接。这意味着当一个服务器的某一个IP地址无法访问时,OkHttp可以尝试别的IP地址进行访问。或者当一个连接池过期或者你尝试连接的所用的TLS版本不受服务器支持时,这种重连机制也是非常有用的。
一旦客户端发来接收到来自服务器的响应,那么这个Connection将会被放置到连接池中以备于将来新的连接进行复用。Connection在长期不使用的情况下,将会从这个连接池中被移除。
··
OkHttp3-OkHttp3-拦截器(Interceptor)
拦截器
拦截器是OkHttp中提供一种强大机制,它可以实现网络监听、请求以及响应重写、请求失败重试等功能。下面举一个简单打印日志的栗子,此拦截器可以打印出网络请求以及响应的信息。
class LoggingInterceptor implements Interceptor {
@Override public Response intercept(Interceptor.Chain chain) throws IOException {
Request request = chain.request();
long t1 = System.nanoTime();
logger.info(String.format("Sending request %s on %s%n%s",
request.url(), chain.connection(), request.headers()));
Response response = chain.proceed(request);
long t2 = System.nanoTime();
logger.info(String.format("Received response for %s in %.1fms%n%s",
response.request().url(), (t2 - t1) / 1e6d, response.headers()));
return response;
}
}
在没有本地缓存的情况下,每个拦截器都必须至少调用chain.proceed(request)一次,这个简单的方法实现了Http请求的发起以及从服务端获取响应。
拦截器可以进行链式处理。假如你同时有一个压缩数据和校验数据的拦截器,你可以决定将请求或者响应数据先进行压缩还是先校验大小。OkHttp利用List集合去跟踪并且保存这些拦截器,并且会依次遍历调用。
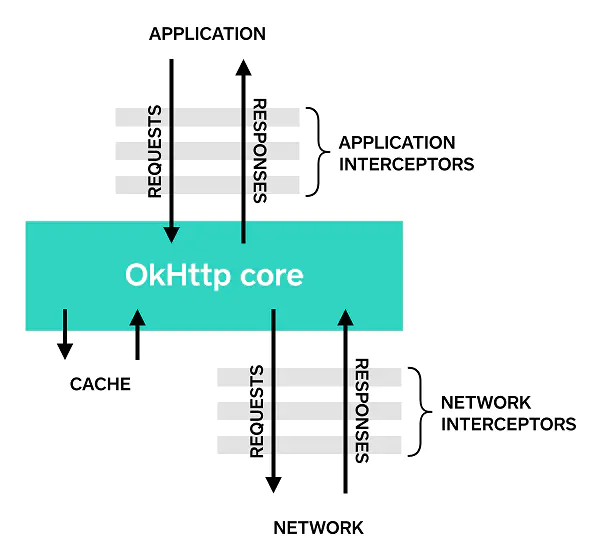
Application interceptors
拦截器可以以application或者network两种方式注册,分别调用addInterceptor()以及addNetworkInterceptor方法进行注册。我们使用上文中日志拦截器的使用来体现出两种注册方式的不同点。
首先通过调用addInterceptor()在OkHttpClient.Builder链式代码中注册一个application拦截器:
OkHttpClient client = new OkHttpClient.Builder()
.addInterceptor(new LoggingInterceptor())
.build();
Request request = new Request.Builder()
.url("http://www.publicobject.com/helloworld.txt")
.header("User-Agent", "OkHttp Example")
.build();
Response response = client.newCall(request).execute();
response.body().close();
请求的URLhttp://www.publicobject.com/helloworld.txt被重定向成https://publicobject.com/helloworld.txt,OkHttp支持自动重定向。注意,我们的application拦截器只会被调用一次,并且调用chain.proceed()之后获得到的是重定向之后的最终的响应信息,并不会获得中间过程的响应信息:
INFO: Sending request http://www.publicobject.com/helloworld.txt on null
User-Agent: OkHttp Example
INFO: Received response for https://publicobject.com/helloworld.txt in 1179.7ms
Server: nginx/1.4.6 (Ubuntu)
Content-Type: text/plain
Content-Length: 1759
Connection: keep-alive
我们可以看到请求的URL被重定向了,因为response.request().url()和request.url()是不一样的。日志打印出来的信息显示两个不同的URL。客户端第一次请求执行的url为http://www.publicobject.com/helloworld.txt,而响应数据的url为https://publicobject.com/helloworld.txt。
Network interceptors
注册一个Network拦截器和注册Application拦截器方法是非常相似的。注册Application拦截器调用的是addInterceptor(),而注册Network拦截器调用的是addNetworkInterceptor()。
OkHttpClient client = new OkHttpClient.Builder()
.addNetworkInterceptor(new LoggingInterceptor())
.build();
Request request = new Request.Builder()
.url("http://www.publicobject.com/helloworld.txt")
.header("User-Agent", "OkHttp Example")
.build();
Response response = client.newCall(request).execute();
response.body().close();
我们运行这段代码,发现这个拦截被执行了两次。一次是初始化也就是客户端第一次向URL为http://www.publicobject.com/helloworld.txt发出请求,另外一次则是URL被重定向之后客户端再次向https://publicobject.com/helloworld.txt发出请求。
INFO: Sending request http://www.publicobject.com/helloworld.txt on Connection{www.publicobject.com:80, proxy=DIRECT hostAddress=54.187.32.157 cipherSuite=none protocol=http/1.1}
User-Agent: OkHttp Example
Host: www.publicobject.com
Connection: Keep-Alive
Accept-Encoding: gzip
INFO: Received response for http://www.publicobject.com/helloworld.txt in 115.6ms
Server: nginx/1.4.6 (Ubuntu)
Content-Type: text/html
Content-Length: 193
Connection: keep-alive
Location: https://publicobject.com/helloworld.txt
INFO: Sending request https://publicobject.com/helloworld.txt on Connection{publicobject.com:443, proxy=DIRECT hostAddress=54.187.32.157 cipherSuite=TLS_ECDHE_RSA_WITH_AES_256_CBC_SHA protocol=http/1.1}
User-Agent: OkHttp Example
Host: publicobject.com
Connection: Keep-Alive
Accept-Encoding: gzip
INFO: Received response for https://publicobject.com/helloworld.txt in 80.9ms
Server: nginx/1.4.6 (Ubuntu)
Content-Type: text/plain
Content-Length: 1759
Connection: keep-alive
NetWork请求包含了更多信息,比如OkHttp为了减少数据的传输时间以及传输流量而自动添加的请求头Accept-Encoding: gzip希望服务器能返回经过压缩过的响应数据。Network 拦截器调用Chain方法后会返回一个非空的Connection对象,它可以用来查询客户端所连接的服务器的IP地址以及TLS配置信息。
选择使用Application或Network拦截器?
每一个拦截器都有它的优点。
Application interceptors
- 无法操作中间的响应结果,比如当URL重定向发生以及请求重试等,只能操作客户端主动第一次请求以及最终的响应结果。
- 在任何情况下只会调用一次,即使这个响应来自于缓存。
- 可以监听观察这个请求的最原始未经改变的意图(请求头,请求体等),无法操作OkHttp为我们自动添加的额外的请求头,比如
If-None-Match。 - 允许
short-circuit (短路)并且允许不去调用Chain.proceed()。(编者注:这句话的意思是Chain.proceed()不需要一定要调用去服务器请求,但是必须还是需要返回Respond实例。那么实例从哪里来?答案是缓存。如果本地有缓存,可以从本地缓存中获取响应实例返回给客户端。这就是short-circuit (短路)的意思。。囧) - 允许请求失败重试以及多次调用
Chain.proceed()。
Network Interceptors
- 允许操作中间响应,比如当请求操作发生重定向或者重试等。
- 不允许调用缓存来
short-circuit (短路)这个请求。(编者注:意思就是说不能从缓存池中获取缓存对象返回给客户端,必须通过请求服务的方式获取响应,也就是Chain.proceed()) - 可以监听数据的传输
- 允许
Connection对象装载这个请求对象。(编者注:Connection是通过Chain.proceed()获取的非空对象)
重写请求
拦截器可以添加、移除或者替换请求头。甚至在有请求主体时候,可以改变请求主体。举个栗子,你可以使用application interceptor添加经过压缩之后的请求主体,当然,这需要你将要连接的服务端支持处理压缩数据。
/** This interceptor compresses the HTTP request body. Many webservers can't handle this! */
final class GzipRequestInterceptor implements Interceptor {
@Override public Response intercept(Interceptor.Chain chain) throws IOException {
Request originalRequest = chain.request();
if (originalRequest.body() == null || originalRequest.header("Content-Encoding") != null) {
return chain.proceed(originalRequest);
}
Request compressedRequest = originalRequest.newBuilder()
.header("Content-Encoding", "gzip")
.method(originalRequest.method(), gzip(originalRequest.body()))
.build();
return chain.proceed(compressedRequest);
}
private RequestBody gzip(final RequestBody body) {
return new RequestBody() {
@Override public MediaType contentType() {
return body.contentType();
}
@Override public long contentLength() {
return -1; // We don't know the compressed length in advance!
}
@Override public void writeTo(BufferedSink sink) throws IOException {
BufferedSink gzipSink = Okio.buffer(new GzipSink(sink));
body.writeTo(gzipSink);
gzipSink.close();
}
};
}
}
重写响应
和重写请求相似,拦截器可以重写响应头并且可以改变它的响应主体。相对于重写请求而言,重写响应通常是比较危险的一种做法,因为这种操作可能会改变服务端所要传递的响应内容的意图。
当然,如果你 比较奸诈 在不得已的情况下,比如不处理的话的客户端程序接受到此响应的话会Crash等,以及你还可以保证解决重写响应后可能出现的问题时,重新响应头是一种非常有效的方式去解决这些导致项目Crash的问题。举个栗子,你可以修改服务器返回的错误的响应头Cache-Control信息,去更好地自定义配置响应缓存保存时间。
/** Dangerous interceptor that rewrites the server's cache-control header. */
private static final Interceptor REWRITE_CACHE_CONTROL_INTERCEPTOR = new Interceptor() {
@Override public Response intercept(Interceptor.Chain chain) throws IOException {
Response originalResponse = chain.proceed(chain.request());
return originalResponse.newBuilder()
.header("Cache-Control", "max-age=60")
.build();
}
};
不过通常最好的做法是在服务端修复这个问题。
private static final Interceptor cacheControlInterceptor = chain -> {
Request request = chain.request();
if (!NetWorkUtil.isNetworkConnected(InitApp.AppContext)) {//如果没有网咯
request = request.newBuilder().cacheControl(CacheControl.FORCE_CACHE).build(); //重写请求,强制从缓存中获取数据CacheControl.FORCE_CACHE
}
Response originalResponse = chain.proceed(request);
if (NetWorkUtil.isNetworkConnected(InitApp.AppContext)) {
// 有网络时 设置缓存为默认值
String cacheControl = request.cacheControl().toString();
return originalResponse.newBuilder()
.header("Cache-Control", cacheControl)
.removeHeader("Pragma") // 清除头信息,因为服务器如果不支持,会返回一些干扰信息,不清除下面无法生效
.build();
} else {
// 无网络时 设置超时为1周
int maxStale = 60 * 60 * 24 * 7;
return originalResponse.newBuilder()
.header("Cache-Control", "public, only-if-cached, max-stale=" + maxStale)
.removeHeader("Pragma")
.build();
}
};