2021 年深度学习哪些方向比较新颖,比较有研究潜力?
主要内容来自微信公众号:计算机视觉联盟
2021年深度学习哪些方向比较新颖,处于上升期或者朝阳阶段,比较有研究潜力?
团队成员为国内各大高校博士,专注于深度学习、机器学习、图像解译、人工智能、无人驾驶等热门领域,分享开源框架学习(如TensorFlow)、项目经历及编程语言(C++、python)等咨讯
【本博客主要原创内容包括:1. 对原文回答内容进行的删减和修改;2. 回答者中提及的重要文献提供了原文链接和部分 GitHub 链接;3. 展示重要文章的摘要。】
下面回答内容来自知乎作者:Zhifeng
来源链接:https://www.zhihu.com/question/460500204/answer/1902459141
---------- Influence Function ----------
可解释性:feature-based 研究的很多了,instance-based 个人感觉在上升期,从研究的角度来说缺乏 benchmark/axiom/sanity check。主流方法是 influence function, 我觉得这里面 self influence的概念非常有趣,应该很值得研究。当然,更意思的方向是跳出 influence function 本身,比如像relatIF 加一些 regularization,也是水文章的一贯套路 (relatIF 是好文章)。
Influence function for generative models 也是很值得做的。Influence function for GAN 已经有人做了,虽然文章直接优化 FID 是有点问题的,但是框架搭好了,换一个 evaluation 换个 setting 就可以直接发 paper。
Influence Estimation for Generative Adversarial Networks [2021 ICLR]
Abstract Identifying harmful instances, whose absence in a training dataset improves model performance, is important for building better machine learning models. Although previous studies have succeeded in estimating harmful instances under supervised settings, they cannot be trivially extended to generative adversarial networks (GANs). This is because previous approaches require that (1) the absence of a training instance directly affects the loss value and that (2) the change in the loss directly measures the harmfulness of the instance for the performance of a model. In GAN training, however, neither of the requirements is satisfied. This is because, (1) the generator’s loss is not directly affected by the training instances as they are not part of the generator’s training steps, and (2) the values of GAN’s losses normally do not capture the generative performance of a model. To this end, (1) we propose an influence estimation method that uses the Jacobian of the gradient of the generator’s loss with respect to the discriminator’s parameters (and vice versa) to trace how the absence of an instance in the discriminator’s training affects the generator’s parameters, and (2) we propose a novel evaluation scheme, in which we assess harmfulness of each training instance on the basis of how GAN evaluation metric (e.g., inception score) is expect to change due to the removal of the instance. We experimentally verified that our influence estimation method correctly inferred the changes in GAN evaluation metrics. Further, we demonstrated that the removal of the identified harmful instances effectively improved the model’s generative performance with respect to various GAN evaluation metrics.
一篇 Influence function for VAE,有不少比较有意思的 observation。 (paper: https://arxiv.org/pdf/2105.14203.pdf; code repo: VAE-TracIn-pytorch)。
Understanding Instance-based Interpretability of Variational Auto-Encoders [2021]
Abstract Instance-based interpretation methods have been widely studied for supervised learning methods as they help explain how black box neural networks predict. However, instance-based interpretations remain ill-understood in the conte6yhb xt of unsupervised learning. In this paper, we investigate influence functions [20], a popular instance-based interpretation method, for a class of deep generative models called variational auto-encoders (VAE). We formally frame the counter-factual question answered by influence functions in this setting, and through theoretical analysis, examine what they reveal about the impact of training samples on classical unsupervised learning methods. We then introduce VAE-TracIn, a computationally efficient and theoretically sound solution based on Pruthi et al. [28], for VAEs. Finally, we evaluate VAE-TracIn on several real world datasets with extensive quantitative and qualitative analysis.6ygb
---------- Diffusion Probabilistic Models ----------
无监督生成学习:最近的 denoising diffusion probabilistic model (DDPM) 绝对是热坑,效果好,但是速度慢没有 meaningful latent space 限制了很多应用,有待发掘。我去年实习写了一篇 DiffWave 是这个方法在语音上的应用,效果很好,最近应该能看到这个模型的 application 井喷,比如 3D point cloud 生成。
Improved Denoising Diffusion Probabilistic Models [PDF 2021]
Abstract Denoising diffusion probabilistic models (DDPM) are a class of generative models which have recently been shown to produce excellent samples. We show that with a few simple modifications, DDPMs can also achieve competitive loglikelihoods while maintaining high sample quality. Additionally, we find that learning variances of the reverse diffusion process allows sampling with an order of magnitude fewer forward passes with a negligible difference in sample quality, which is important for the practical deployment of these models. We additionally use precision and recall to compare how well DDPMs and GANs cover the target distribution. Finally, we show that the sample quality and likelihood of these models scale smoothly with model capacity and training compute, making them easily scalable. We release our code at https://github.com/ openai/improved-diffusion.
DDPM 的加速最近已经有不少 paper 了,目前来看有几类,有的用 conditioned on noise level 去重新训练,有的用 jumping step 缩短 Markov Chain,有的在 DDPM++ 里面研究更快的 solver。最近一篇 FastDPM, 是一种结合 noise level 和 jumping step 的快速生成的框架(无需 retrain, original DDPM checkpoint 拿来直接用),统一并推广了目前的好几种方法,给出了不同任务(图像, 语音) 的 recipe (paper: https//arxiv.org/pdf/2106.00132.pdf; code repo: FastDPM_pytorch)。
On Fast Sampling of Diffusion Probabilistic Models [2021]
Abstract In this work, we propose FastDPM, a unified framework for fast sampling in diffusion probabilistic models. FastDPM generalizes previous methods and gives rise to new algorithms with improved sample quality. We systematically investigate the fast sampling methods under this framework across different domains, on different datasets, and with different amount of conditional information provided for generation. We find the performance of a particular method depends on data domains (e.g., image or audio), the trade-off between sampling speed and sample quality, and the amount of conditional information. We further provide insights and recipes on the choice of methods for practitioners.
---------- Normalizing Flow ----------
生成模型里的 Normalizing Flow 模型,用可逆网络转化数据分布,很 fancy 能提供 likelihood 和比较好的解释性但是效果偏偏做不上去,一方面需要在理论上有补充,因为可逆或者 Lipschitz 网络的 capacity 确实有限。另一方面,实际应用中,training 不稳定可能是效果上不去的原因,其中initialization 和 training landscape 都是有待研究的问题。潜在的突破口:augmented dimension或者类似 surVAE 那种 generalized mapping。除此之外,normalizing flow on discrete domain 也是很重要的问题,潜在突破口是用 OT 里面的 sinkhorn network。
residual flow 这个模型有执念,很喜欢这个框架,虽然它不火。基于 residual flow 的 universal approximation in MMD 的证明,很难做,需要比较特殊的假设 (paper: https://arxiv.org/pdf/2103.05793.pdf)。之后可能继续钻研它的 capacity 和 learnability。
Universal Approximation of Residual Flows in Maximum Mean Discrepancy [2021]
Abstract Normalizing flows are a class of flexible deep generative models that offer easy likelihood computation. Despite their empirical success, there is little theoretical understanding of their expressiveness. In this work, we study residual flows, a class of normalizing flows composed of Lipschitz residual blocks. We prove residual flows are universal approximators in maximum mean discrepancy. We provide upper bounds on the number of residual blocks to achieve approximation under different assumptions.
---------- Data-Copying ----------
生成模型的 overfitting 是一个长久的问题,但是本身很难定义,很大一个原因是 mode collapse 和copy training data 耦合在一起。去年发表了 data-copying test 用于检测相关性质,不过这个 idea 还停留在比较初级的阶段,我觉得这一块需要更多 high level 的框架。
A Non-Parametric Test to Detect Data-Copying in Generative Models [2020 AISTATS]
Abstract Detecting overfitting in generative models is an important challenge in machine learning. In this work, we formalize a form of overfitting that we call data-copying – where the generative model memorizes and outputs training samples or small variations thereof. We provide a three sample non-parametric test for detecting data-copying that uses the training set, a separate sample from the target distribution, and a generated sample from the model, and study the performance of our test on several canonical models and datasets.
---------- Meta learning + Generative model ----------
Meta learning + generative model 方向个人十分看好,meta learning 框架可以直接套,loss 改成生成模型的 loss 就可以了。Again, GAN 已经被做了,不过 GAN 的 paper 那么多,随便找上一个加上 meta learning 还是很容易的。类似可以做 multitask + GAN。
下面回答内容来自知乎作者:陀飞轮
来源链接:https://www.zhihu.com/question/460500204/answer/1902640999
---------- Transformer ----------
自从去年 DETR 和 ViT 出来之后,计算机视觉领域掀起了 Transformer 狂潮。目前可以做的主要有两个路径,一个是魔改 DETR 和 ViT,另一个是不同task迁移算法。
魔改 DETR 和 ViT 的方法,无非是引入 local 和 hierarchical,或者魔改算子。
不同task迁移算法主要是探究如何针对不同的task做适配设计。
魔改 DETR:
[Deformable DETR] [TSP-FCOS/TSP-RCNN] [UP-DETR] [SMCA] [Meta-DETR] [DA-DETR]
其中魔改ViT的可以参考以下工作:
魔改算子:
[LambdaResNets] [DeiT] [VTs] [So-ViT] [LeViT] [CrossViT] [DeepViT] [TNT] [T2T-ViT]
[BoTNet] [Visformer]
引入 local 或者 hierarchical:
[PVT] [FPT] [PiT] [LocalViT] [SwinT] [MViT] [Twins]
Swin Transformer对CNN的降维打击
引入卷积:
[CPVT] [CvT] [ConViT] [CeiT] [CoaT] [ConTNet]
不同 task 迁移算法:
ViT+Seg [SETR] [TransUNet] [DPT] [U-Transformer]
ViT+Det [ViT-FRCNN] [ACT]
ViT+SOT [TransT] [TMT]
ViT+MOT [TransTrack] [TrackFormer] [TransCenter]
ViT+Video [STTN] [VisTR] [VidTr] [ViViT] [TimeSformer] [VTN]
ViT+GAN [TransGAN] [AOT-GAN] [GANsformer]
ViT+3D [Group-Free] [Pointformer] [PCT] [PointTransformer] [DTNet] [MLMSPT]
---------- Self-Supervised ----------
Self-Supervised 自从何恺明做出 MoCo 以来再度火热,目前仍然是最为火热的方向之一。目前可以做的主要有三个路径,一个是探索退化解的充要条件,一个是 Self-Supervised+Transformer 探索上限,还有一个是探索非对比学习的方法。
探索退化解的充要条件主要是探索无 negative pair 的时候,避免退化解的最优方案是什么。
[SimCLR] [BYOL] [SwAV] [SimSiam] [Twins]
Self-Supervised+Transformer 是 MoCov3 首次提出的,NLP 领域强大的预训练模型 (BERT 和GPT-3) 都是 Transformer 架构的,CV 可以尝试去复制 NLP 的路径,探究 Self-Supervised + Transformer 的上限。
[MoCov1] [MoCov2] [MoCov3] [SiT]
探索非对比学习的方法就是要设计合适的 proxy task。
基于上下文:
[Unsupervised Visual Representation Learning by Context Prediction ICCV2015] [Unsupervised Representation Learning by Predicting Image Rotations ICLR2018]
[Self-supervised Label Augmentation via Input Transformations]
基于时序 [Time-Contrastive Networks: Self-Supervised Learning from Video] [Unsupervised Learning of Visual Representations using Videos]
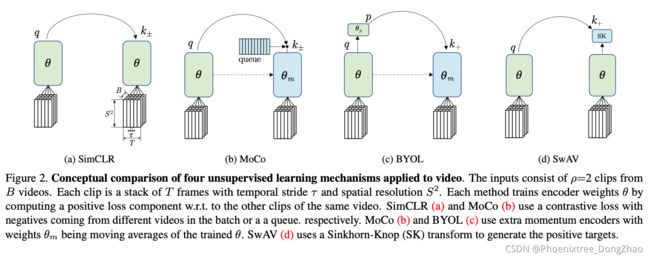
刚写了基于时序,何恺明和 Ross Girshick 就搞了个时序的
A Large-Scale Study on Unsupervised Spatiotemporal Representation Learning
[2021 CVPR]
Abstract We present a large-scale study on unsupervised spatiotemporal representation learning from videos. With a unified perspective on four recent image-based frameworks, we study a simple objective that can easily generalize all these methods to space-time. Our objective encourages temporallypersistent features in the same video, and in spite of its simplicity, it works surprisingly well across: (i) different unsupervised frameworks, (ii) pre-training datasets, (iii) downstream datasets, and (iv) backbone architectures. We draw a series of intriguing observations from this study, e.g., we discover that encouraging long-spanned persistency can be effective even if the timespan is 60 seconds. In addition to state-of-the-art results in multiple benchmarks, we report a few promising cases in which unsupervised pre-training can outperform its supervised counterpart. Code will be made available at https://github.com/ facebookresearch/SlowFast.
---------- Zero-Shot ----------
最近因为 CLIP 的出现,Zero-Shot 可能会引起一波热潮,ViLD 将 CLIP 成功应用于目标检测领域,相信未来会有越来越多的基于 CLIP 的 Zero-Shot 方法。
Learning Transferable Visual Models From Natural Language Supervision [2021]
[project]
Abstract State-of-the-art computer vision systems are trained to predict a fixed set of predetermined object categories. This restricted form of supervision limits their generality and usability since additional labeled data is needed to specify any other visual concept. Learning directly from raw text about images is a promising alternative which leverages a much broader source of supervision. We demonstrate that the simple pre-training task of predicting which caption goes with which image is an efficient and scalable way to learn SOTA image representations from scratch on a dataset of 400 million (image, text) pairs collected from the internet. After pre-training, natural language is used to reference learned visual concepts (or describe new ones) enabling zero-shot transfer of the model to downstream tasks. We study the performance of this approach by benchmarking on over 30 different existing computer vision datasets, spanning tasks such as OCR, action recognition in videos, geo-localization, and many types of fine-grained object classification. The model transfers non-trivially to most tasks and is often competitive with a fully supervised baseline without the need for any dataset specific training. For instance, we match the accuracy of the original ResNet-50 on ImageNet zero-shot without needing to use any of the 1.28 million training examples it was trained on. We release our code and pre-trained model weights at GitHub - openai/CLIP: Contrastive Language-Image Pretraining.

Zero-Shot Detection via Vision and Language Knowledge Distillation [2021]
Abstract Zero-shot image classification has made promising progress by training the aligned image and text encoders. The goal of this work is to advance zero-shot object detection, which aims to detect novel objects without bounding box nor mask annotations. We propose ViLD, a training method via Vision and Language knowledge Distillation. We distill the knowledge from a pre-trained zero-shot image classification model (e.g., CLIP [33]) into a two-stage detector (e.g., Mask R-CNN [17]). Our method aligns the region embeddings in the detector to the text and image embeddings inferred by the pre-trained model. We use the text embeddings as the detection classifier, obtained by feeding category names into the pre-trained text encoder. We then minimize the distance between the region embeddings and image embeddings, obtained by feeding region proposals into the pre-trained image encoder. During inference, we include text embeddings of novel categories into the detection classifier for zero-shot detection. We benchmark the performance on LVIS dataset [15] by holding out all rare categories as novel categories. ViLD obtains 16.1 mask APr with a Mask R-CNN (ResNet-50 FPN) for zero-shot detection, outperforming the supervised counterpart by 3.8. The model can directly transfer to other datasets, achieving 72.2 AP50, 36.6 AP and 11.8 AP on PASCAL VOC, COCO and Objects365, respectively.
