mysql联合索引命中率abc
mysql 联合索引 复合索引 (abc) 命中率:在工作中经常会使用到联合索引,在百度查询多很多资料也有说法不一的、给大家实测下100w数据下查询命中率,废话不多说、上干货;
创建测试表:
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
CREATE TABLE `test` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`a` int(11) NOT NULL DEFAULT 1,
`b` int(11) NOT NULL DEFAULT 1,
`c` int(11) NOT NULL DEFAULT 1,
`d` int(11) NOT NULL DEFAULT 1,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 1 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Compact;
SET FOREIGN_KEY_CHECKS = 1;
在插入数据前添加索引,在100w数据添加还可以接受 数量越大越慢 带来的也是io占用 具体原理百度搜索 mysql innoDB索引原理(聚簇索引) 、 b+树。(或后续更新
alter table test add index sindex(a,b,c);
批量插入100w条数据做测试,漫长的等待过程,超时 set_time_limit(0);
$n = 1000000;
for ($i = 0; $i <= $n; $i++) {
//a 范围 0 - 1000 随机整数
//b 范围 0 - 10000 随机整数
//c 范围 0 - 100000 随机整数
//d 范围 0 - 1000 随机整数
$data['a'] = rand(0, 1000);
$data['b'] = rand(0, 10000);
$data['c'] = rand(0, 100000);
$data['d'] = rand(0, 1000);
DB::table('test')->insert($data);
}测试索引命中、为了更清晰直观体现索引命中率、我把结果都截图到每条语句的下方导致篇幅过长;
1.explain select * from test where a = 437 and b = 7800 and c = 33561;

2.explain select * from test where a = 437 and c = 7800 and b = 33561;

3.explain select * from test where a = 437 and b = 33561;

4.explain select * from test where a = 437

5.explain select * from test where c = 7800 and b = 33561;
6.explain select * from test where b = 33561;
![]()
7.explain select * from test where b = 33561 and a = 437;
![]()
8.explain select * from test where b = 33561 and c = 7800 and a = 437;

结论:
1.and and 只要用到了最左侧a都会使用到索引
2.a and b or c 不会使用索引
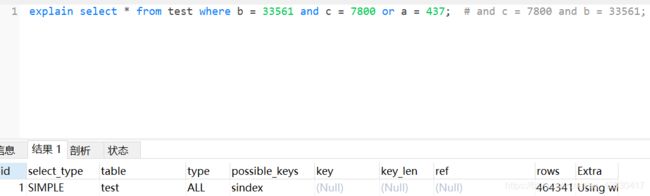
3.最左侧a列被大于、小于、不等于比较的、不使用索引

4.b列 c列使用大于、小于、不等于比较的 会使用索引
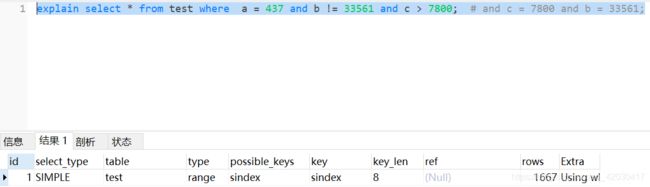
5. order by a desc group by a 只要保持最左侧a原则 都会使用索引;