应用散列表和外拉链表统计文本中单词个数
应用散列表和外拉链表统计英文单词个数, 其中外拉链表用的是双向链表模板, 散列表是一个大数组, hash 函数有 BKDRHash, APHash, DJBHash, PJWHash, ELFHash等多种Hash函数. 测试性能主要是测试平均外链长度和槽占用率. 这里选择的英文文章是ANSI格式的, 因为英文文章里标点符号后面会加空格, 所以这段代码截取单词时以空格为标志, 然后再去除截取单词中的标点符号.
llgen.h
/*----- hash.h ----------------------------------------------------------------
* Declarations for hash table and external chaining.
* Used in conjunction with hash.c
*---------------------------------------------------------------------------*/
#ifndef LLGEN_H
#define LLGEN_H 1
struct Node {
struct Node * prev;
struct Node * next;
void * data; /* generic pointer to data */
};
typedef struct Node * Link;
/* a linked-list data structure */
struct List {
Link LHead;
Link LTail;
unsigned int LCount;
void * ( *LCreateData ) ( void * data );
int ( *LDeleteData ) ( void * data );
int ( *LDuplicatedNode ) ( Link new_node , Link list_node );
int ( *LNodeDataCmp ) ( void * first , void * second );
};
/*--- generic linked-list primitives ---*/
int AddNodeAtHead( struct List * LList , void * data_add );
int AddNodeAscend( struct List * LList , void * data_add );
struct List * CreateLList(
void * ( *LCreateData ) ( void * data ) ,
int ( *LDeleteData ) ( void * data ) ,
int ( *LDuplicatedNode ) ( Link new_node , Link list_node ) ,
int ( *LNodeDataCmp ) ( void * first , void * second ) );
Link CreateNode( struct List * LList , void * data_create );
int DeleteNode( struct List * LList , Link node_delete );
Link FindNode( struct List * LList , void * data_search );
Link FindNodeAscend( struct List * LList , void * data_search );
#endifllapp.h
#ifndef LLAPP_H
#define LLAPP_H 1
struct WordNode {
char * word;
unsigned int word_count;
};
void * CreateData ( void * data );
int DeleteData ( void * data );
int DuplicatedNode ( Link new_node , Link list_node );
int NodeDataCmp ( void * first , void * second );
#endifhash_table.h
/*--- the hash table portion ---*/
#ifndef HASH_H
#define HASH_H 1
#include "llgen.h"
int CreateHashTable( Link ** table_create );
#endif
#ifndef HASH_FUNCTIONS_H
#define HASH_FUNCTIONS_H 1
unsigned int BKDRHash( char *str );
unsigned int APHash( char *str );
unsigned int SDBMHash( char *str );
unsigned int RSHash( char *str );
unsigned int JSHash( char *str );
unsigned int PJWHash( char *str );
unsigned int ELFHash( char *str );
unsigned int DJBHash( char *str );
#endifllgen.cpp
#include
#include
#include
#include "llgen.h"
/*--- Aliases to make the code more readable ---*/
#define LLHead ( LList->LHead )
#define LLTail ( LList->LTail )
#define NodeCount ( LList->LCount )
#define CreateData ( LList->LCreateData )
#define DeleteData ( LList->LDeleteData )
#define DuplicatedNode ( LList->LDuplicatedNode )
#define NodeDataCmp ( LList->LNodeDataCmp )
/*-----------------------------------------------------------------------------
* Add a node at head: first allocate the space for the data, then allocate
* a node with a pointer to the data, then add the node to the list.
* Return 0 on error, 1 on success.
*---------------------------------------------------------------------------*/
int AddNodeAtHead( struct List * LList , void * data_add )
{
Link pnode;
pnode = CreateNode( LList , data_add );
if ( NULL == pnode ) {
return ( 0 );
}
/* Add the node */
if ( NULL == LLHead ) { /* Is it the first node? */
LLHead = LLTail = pnode; /*--- yes ---*/
}
else { /*--- no ---*/
pnode->next = LLHead;
LLHead->prev = pnode;
LLHead = pnode;
}
NodeCount += 1;
return ( 1 );
}
/*-----------------------------------------------------------------------------
* Add Ascending. Adds a node to an ordered list.
*---------------------------------------------------------------------------*/
int AddNodeAscend( struct List * LList , void * data_add )
{
Link pnode;
struct Node dummy; /* a dummy node */
Link prev , curr; /* our current search */
int compare_status;
int duplicate_status;
pnode = CreateNode( LList , data_add );
if ( NULL == pnode ) {
return ( 0 );
}
/* attach dummy node to head of list */
dummy.next = LLHead;
dummy.prev = NULL;
if ( NULL != dummy.next ) {
dummy.next->prev = &dummy;
}
prev = &dummy;
curr = dummy.next;
/* search position to add node */
for ( ; NULL != curr ; prev = curr , curr = curr->next ) {
compare_status = NodeDataCmp( data_add , curr->data );
if ( compare_status <= 0 ) {
break;
}
}
/* handle duplicated node */
if ( NULL != LLHead && 0 == compare_status ) {
duplicate_status = DuplicatedNode( pnode , curr );
if ( 2 == duplicate_status ) {
/* do nothing -- will get inserted */
}
else {
/* same as 0 == duplicate_status, do nothing to list, function return */
/* first, repair the linked-list */
LLHead = dummy.next;
LLHead->prev = NULL;
if ( 1 == duplicate_status ) {
DeleteData( pnode->data );
free( pnode );
}
return ( 1 );
}
}
/* Add the node */
pnode->next = curr;
pnode->prev = prev;
prev->next = pnode;
if ( NULL != curr ) {
curr->prev = pnode;
}
else {
LLTail = pnode; /* this node is the new tail */
}
NodeCount += 1;
/* now, unhook the dummy head node */
LLHead = dummy.next;
LLHead->prev = NULL;
return ( 1 );
}
/*-----------------------------------------------------------------------------
* Creates a linked-list structure and returns a pointer to it.
* This functions accepts pointers to the four list-specific functions and
* initializes the linked-list structure with them.
* Return NULL on errors, a pointer to linked-list on success.
*---------------------------------------------------------------------------*/
struct List * CreateLList(
void * ( * LCreateData ) ( void * data ),
int ( * LDeleteData ) ( void * data ),
int ( * LDuplicatedNode ) ( Link new_node , Link list_node ),
int ( * LNodeDataCmp ) ( void * first , void * second ) )
{
struct List * plist;
plist = ( struct List * )malloc( sizeof ( struct List ) );
if ( NULL == plist ) {
return ( NULL );
}
plist->LHead = NULL;
plist->LTail = NULL;
plist->LCount = 0;
plist->LCreateData = LCreateData;
plist->LDeleteData = LDeleteData;
plist->LDuplicatedNode = LDuplicatedNode;
plist->LNodeDataCmp = LNodeDataCmp;
return ( plist );
}
/*-----------------------------------------------------------------------------
* Creates a node and then call the application-specific function CreateData()
* to create the node's data structure.
* Return NULL on error, a pointer to new created node on success.
*---------------------------------------------------------------------------*/
Link CreateNode( struct List * LList , void * data_create )
{
Link new_node;
new_node = ( Link )malloc( sizeof( struct Node ) );
if ( NULL == new_node ) {
return ( NULL );
}
new_node->prev = NULL;
new_node->next = NULL;
/* now call the application-specific data allocation */
new_node->data = CreateData( data_create );
if ( NULL == new_node->data ) {
free( new_node );
return ( NULL );
}
return ( new_node );
}
/*-----------------------------------------------------------------------------
* Deletes the node pointed to by node_delete.
* Function calls list-specific function to delete data.
* Return 0 on error, 1 on success.
*---------------------------------------------------------------------------*/
int DeleteNode( struct List * LList , Link node_delete )
{
Link node;
if ( NULL == node_delete ) { /* empty linked-list */
return ( 0 );
}
/* there is only one node in the linked-list? */
if ( NULL == node_delete->prev && NULL == node_delete->next ) {
LLHead = NULL; /*--- yes ---*/
LLTail = NULL;
}
else { /*--- no ---*/
if ( NULL == node_delete ) /* we are at the head */
{
LLHead = node_delete->next;
LLHead->prev = NULL;
}
else if ( NULL == node_delete ) /* we are at the tail */
{
LLTail = node_delete->prev;
LLTail->next = NULL;
}
else { /* we are in the list */
node = node_delete->prev;
node->next = node_delete->next;
node = node_delete->next;
node->prev = node_delete->prev;
}
}
/* now delete the node */
DeleteData( node_delete->data );
free( node_delete );
NodeCount -= 1;
return ( 1 );
}
/*-----------------------------------------------------------------------------
* Finds node by starting at the head of the list, stepping through each node,
* and comparing data items with the search key. The Ascend Version checks that
* the data in the node being examined is not larger than the search key,
* If it is , we know the key is not in the list.
* Return NULL on error, a pointer to target node on success.
*---------------------------------------------------------------------------*/
Link FindNode( struct List * LList , void * data_search )
{
Link curr;
int compare_status;
for ( curr = LLHead; NULL != curr; curr = curr->next ) {
compare_status = NodeDataCmp( data_search , curr->data );
if ( 0 == compare_status ) {
return ( curr );
}
}
return ( NULL ); /* could not find node */
}
Link FindNodeAscend( struct List * LList , void * data_search )
{
Link curr;
int compare_status;
for ( curr = LLHead; NULL != curr; curr = curr->next ) {
compare_status = NodeDataCmp( data_search , curr->data );
if ( compare_status < 0 ) {
return ( NULL );
}
if ( 0 == compare_status ) {
return ( curr );
}
}
return ( NULL ); /* could not find node */
} llapp.cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include
#include
#include "llgen.h"
#include "llapp.h"
void * CreateData( void * data )
{
struct WordNode * pword;
pword = ( struct WordNode * )malloc( sizeof( struct WordNode ) );
if ( NULL == pword ) {
return ( NULL );
}
pword->word_count = 1;
pword->word = _strdup( ( (( struct WordNode * )data)->word ) );
if ( NULL == pword->word ) {
free( pword );
return ( NULL );
}
else {
return ( pword );
}
}
/* free heap memory! here, data is a pointer to a structure or any other style */
int DeleteData( void * data )
{
/* In this case, WordNode consists of: a pointer and an int.
* The integer will be returned to memory when the node is freed.
* However, the string must be freed manually.
*/
free( ( ( struct WordNode * )data )->word );
return ( 1 );
}
/* This function determines what to do when inserting a node into a list if an
* existing node with the same data is found in the list. In this case, since we
* are counting words, if a duplicate word is found, we simply increment the counter.
*
* Note this function should return one of the following values:
* 0 an error occurred
* 1 delete the duplicated node
* 2 insert the duplicated node
*/
int DuplicatedNode( Link new_node , Link list_node )
{
struct WordNode * wd = ( struct WordNode * )(list_node->data);
++ wd->word_count;
return ( 1 );
}
int NodeDataCmp( void * first , void * second )
{
int compare_status;
compare_status = strcmp( ( ( struct WordNode * )first )->word ,
( ( struct WordNode * )second )->word );
return ( compare_status );
}
#include
#include "hash_table.h"
#define TABLE_SIZE 1000
/*-----------------------------------------------------------------------------
* The function accepts a multilevel pointer to the Node structure and modify it.
* Return 0 on error, 1 on success.
*---------------------------------------------------------------------------*/
int CreateHashTable( Link ** table_create )
{
*table_create = ( Link * )calloc( TABLE_SIZE , sizeof( Link ) );
return ( NULL == *table_create ? 0 : 1 );
}
hash_functions.cpp
// BKDR Hash Function
unsigned int BKDRHash( char *str )
{
unsigned int seed = 131; // 31 131 1313 13131 131313 etc..
unsigned int hash = 0;
while ( *str ) {
hash = hash * seed + ( *str++ );
}
return ( hash & 0x7FFFFFFF );
}
// AP Hash Function
unsigned int APHash( char *str )
{
unsigned int hash = 0;
int i;
for ( i=0; *str; i++ ) {
if ( ( i & 1 ) == 0 ) {
hash ^= ( ( hash << 7 ) ^ ( *str++ ) ^ ( hash >> 3 ) );
}
else {
hash ^= ( ~( ( hash << 11 ) ^ ( *str++ ) ^ ( hash >> 5 ) ) );
}
}
return ( hash & 0x7FFFFFFF );
}
// SDB Hash Function
unsigned int SDBMHash( char *str )
{
unsigned int hash = 0;
while ( *str ) {
// equivalent to: hash = 65599*hash + (*str++);
hash = ( *str++ ) + ( hash << 6 ) + ( hash << 16 ) - hash;
}
return ( hash & 0x7FFFFFFF );
}
// RS Hash Function
unsigned int RSHash( char *str )
{
unsigned int b = 378551;
unsigned int a = 63689;
unsigned int hash = 0;
while ( *str ) {
hash = hash * a + ( *str++ );
a *= b;
}
return ( hash & 0x7FFFFFFF );
}
// JS Hash Function
unsigned int JSHash( char *str )
{
unsigned int hash = 1315423911;
while ( *str ) {
hash ^= ( ( hash << 5 ) + ( *str++ ) + ( hash >> 2 ) );
}
return ( hash & 0x7FFFFFFF );
}
// PJW Hash Function
unsigned int PJWHash( char *str )
{
unsigned int BitsInUnignedInt = ( unsigned int )( sizeof( unsigned int )* 8 );
unsigned int ThreeQuarters = ( unsigned int )( ( BitsInUnignedInt * 3 ) / 4 );
unsigned int OneEighth = ( unsigned int )( BitsInUnignedInt / 8 );
unsigned int HighBits = ( unsigned int )( 0xFFFFFFFF ) << ( BitsInUnignedInt - OneEighth );
unsigned int hash = 0;
unsigned int test = 0;
while ( *str ) {
hash = ( hash << OneEighth ) + ( *str++ );
if ( ( test = hash & HighBits ) != 0 ) {
hash = ( ( hash ^ ( test >> ThreeQuarters ) ) & ( ~HighBits ) );
}
}
return ( hash & 0x7FFFFFFF );
}
// ELF Hash Function
unsigned int ELFHash( char *str )
{
unsigned int hash = 0;
unsigned int x = 0;
while ( *str ) {
hash = ( hash << 4 ) + ( *str++ );
if ( ( x = hash & 0xF0000000L ) != 0 ) {
hash ^= ( x >> 24 );
hash &= ~x;
}
}
return ( hash & 0x7FFFFFFF );
}
// DJB Hash Function
unsigned int DJBHash( char *str )
{
unsigned int hash = 5381;
while ( *str ) {
hash += ( hash << 5 ) + ( *str++ );
}
return ( hash & 0x7FFFFFFF );
}
Main.cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include
#include
#include
#include /* include isspace ispunct */
#include "hash_functions.h"
#include "llgen.h"
#include "llapp.h"
#include "hash_table.h"
#define TABLE_SIZE 1000
void PrintHashTable( Link * HashTable );
void PrintHashTableStates( Link * HashTable , struct List * chain_list );
int main( int argc , char * argv[] )
{
char word[64] = "";
char *low_word;
int c , i;
int add_status;
unsigned int hash_key;
struct List * chain_list;
struct WordNode tmp_word_node;
Link * HashTable; /* Our table is an array of Links */
FILE *fileRead;
/* open the file for read */
fileRead = fopen( "English.txt" , "rt" );
if ( NULL == fileRead ) {
fprintf( stderr , "Failed Open English.txt!\n" );
return ( EXIT_FAILURE );
}
/* create the hash table */
if ( 0 == CreateHashTable( &HashTable ) ) {
fprintf( stderr , "Failed CreateHashTable!\n" );
return ( EXIT_FAILURE );
}
/* set up linked-list data structure */
chain_list = CreateLList( CreateData , DeleteData , DuplicatedNode , NodeDataCmp );
if ( NULL == chain_list ) {
fprintf( stderr , "Failed CreateLList!\n" );
return ( EXIT_FAILURE );
}
c = ' ';
/*--- Begin processing file ---*/
while ( !feof( fileRead ) ) {
/* skip white space */
while ( EOF != c && isspace( c ) ) {
c = fgetc( fileRead );
}
/* pick up the word */
i = 0;
while ( EOF != c && !isspace( c ) ) {
word[i++] = ( char )c;
c = fgetc( fileRead );
}
word[i] = '\0';
/* strip off trailing punctuation */
while ( i >= 0 && ispunct( word[--i] ) ) {
word[i] = '\0';
}
low_word = _strlwr( word );
/* get the hash value */
hash_key = ( unsigned int )DJBHash( low_word );
hash_key = hash_key % TABLE_SIZE;
/* insert into table */
chain_list->LHead = HashTable[hash_key];
tmp_word_node.word = _strdup( low_word );
tmp_word_node.word_count = 1;
add_status = AddNodeAscend( chain_list , &tmp_word_node );
if ( 0 == add_status ) {
fprintf( stderr , "Failed AddNodeAscend!\n" );
return ( EXIT_FAILURE );
}
HashTable[hash_key] = chain_list->LHead;
free( tmp_word_node.word );
}
// PrintHashTable( HashTable );
PrintHashTableStates( HashTable , chain_list);
fclose( fileRead );
}
/* printf the words in hash table */
void PrintHashTable( Link * HashTable )
{
int i;
Link curr;
for ( i = 0; i < TABLE_SIZE; i ++ ) {
if ( NULL != HashTable[i] ) { /* print the word in the chain list */
for ( curr = HashTable[i]; NULL != curr; curr = curr->next ) {
printf( "%s -- %d\n" , ( (struct WordNode *)(curr->data) )->word ,
( ( struct WordNode * )(curr->data) )->word_count );
}
printf( "\n\n" );
}
}
}
void PrintHashTableStates( Link * HashTable , struct List * chain_list )
{
int i = 0;
int chain_len , chains_total;
int chain_table[33];
Link pcurr;
memset( chain_table , 0 , sizeof( int )* 33 );
/* preprocessing the hash table */
for ( i = 0; i < TABLE_SIZE; i ++ ) {
pcurr = HashTable[i];
if ( NULL != pcurr ) { /* skip empty slots */
for ( chain_len = 0 ; NULL != pcurr ; pcurr = pcurr->next ) {
chain_len ++;
}
if ( chain_len > 32 ) {
chain_len = 32;
}
chain_table[chain_len] += 1;
}
}
/* list hash table states */
chains_total = 0;
for ( i = 32; i > 0; i -- ) {
if ( 0 != chain_table[i] ) {
printf( "%3d chains of length %2d\n" , chain_table[i] , i );
chains_total += chain_table[i];
}
}
if ( 0 != chains_total ) {
printf( "\n%d nodes in %d chains \n\n" ,
chain_list->LCount , chains_total );
printf( "Size of hash table = %d \n" , TABLE_SIZE );
printf( "Average chain length = %f\n" ,
chain_list->LCount / (( double )chains_total) );
printf( "Slot occupancy = %f\n" ,
(( double )chains_total) / TABLE_SIZE );
}
} 我这里选择的英文文章不是很大,但可以看得出各种 Hash 算法的优劣. 我这里贴两个算法的比较 ELFHash 和 DJBHash
ELFHash:
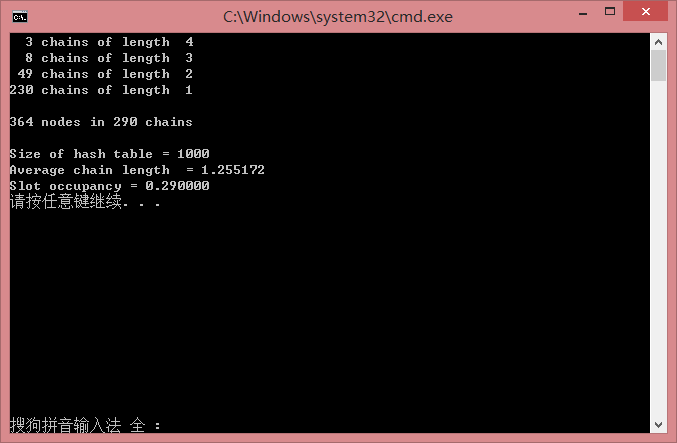
DJBHash:
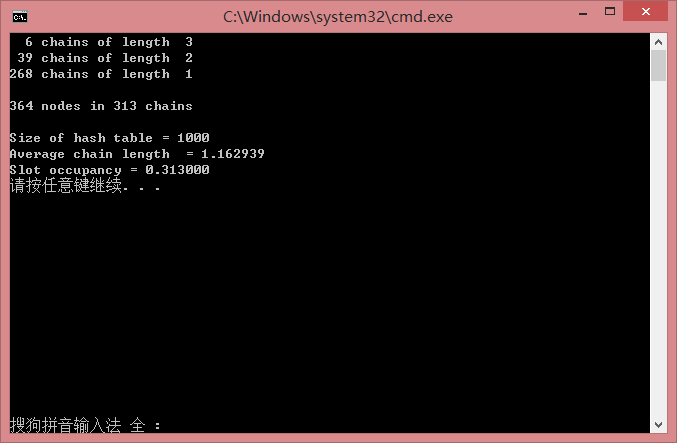
虽然实验不是很标准, 但可以看出两种散列算法的效果了