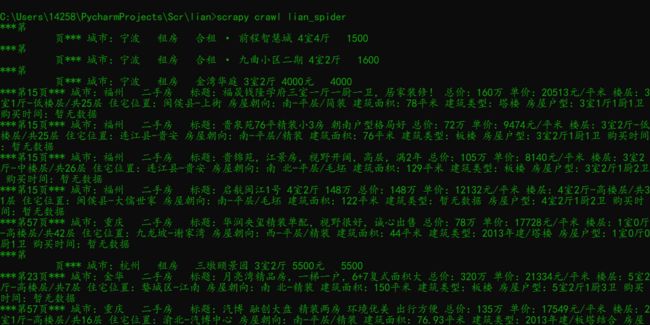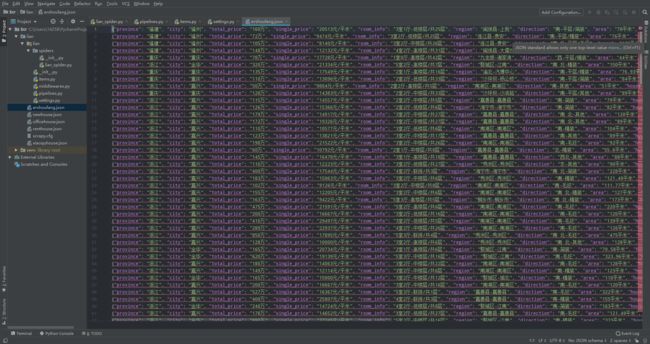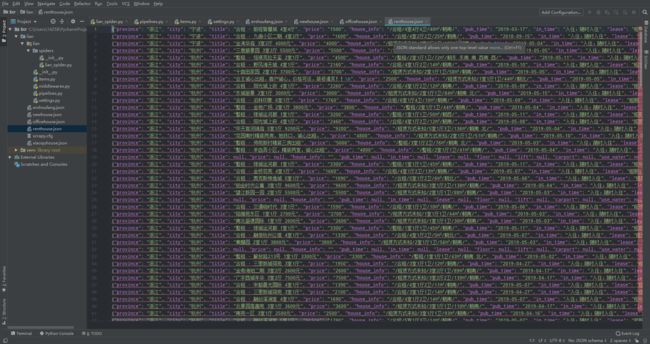
用scrapy爬取链家全国以上房源分类的信息:
路径:
items.py


# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # https://doc.scrapy.org/en/latest/topics/items.html import scrapy class LianItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() pass class ErShouFangItem(scrapy.Item): # 省份 province = scrapy.Field() # 城市 city = scrapy.Field() # 总价 total_price = scrapy.Field() # 单价 single_price = scrapy.Field() # 楼层 room_info = scrapy.Field() # 住宅位置 region = scrapy.Field() # 房屋朝向及装修情况 direction = scrapy.Field() # 建筑面积 area = scrapy.Field() # 建筑类型 house_struct = scrapy.Field() # 房屋户型 huxing = scrapy.Field() # 购买时间 buy_time = scrapy.Field() # url ershou_detail_url = scrapy.Field() class NewHouseItem(scrapy.Item): # 省份 province = scrapy.Field() # 城市 city = scrapy.Field() # 标题 title = scrapy.Field() # 位置 region = scrapy.Field() # 房屋信息 room_info = scrapy.Field() # 建筑面积 area = scrapy.Field() # 价格 price = scrapy.Field() # 详情页 newHouse_detail_url = scrapy.Field() class RentHouseItem(scrapy.Item): # 省份 province = scrapy.Field() # 城市 city = scrapy.Field() # 标题 title = scrapy.Field() # 价格 price = scrapy.Field() # 房间信息(房源户型、朝向、面积、租赁方式) house_info = scrapy.Field() # 发布时间 pub_time = scrapy.Field() # 入住: in_time = scrapy.Field() # 租期 lease = scrapy.Field() # 楼层 floor = scrapy.Field() # 电梯: lift = scrapy.Field() # 车位: carport = scrapy.Field() # 用水: use_water = scrapy.Field() # 用电: use_electricity = scrapy.Field() # 燃气: use_gas = scrapy.Field() # url rent_detail_url = scrapy.Field() class OfficeHouseItem(scrapy.Item): # 省份 province = scrapy.Field() # 城市 city = scrapy.Field() # 标题 title = scrapy.Field() # 价格 price = scrapy.Field() # 数量 num = scrapy.Field() # 面积 area = scrapy.Field() # url office_detail_url = scrapy.Field() class XiaoquHouseItem(scrapy.Item): # 省份 province = scrapy.Field() # 城市 city = scrapy.Field() # 标题 title = scrapy.Field() # 地区 region = scrapy.Field() # 单价 single_price = scrapy.Field() # 建筑年代 build_time = scrapy.Field() # 建筑类型 house_struct = scrapy.Field() # 物业费用 service_fees = scrapy.Field() # 物业公司 service_company = scrapy.Field() # 开发商 build_company = scrapy.Field() # 楼栋数 building_nums = scrapy.Field() # 房屋总数 house_nums = scrapy.Field() # url xiaoqu_detail_url = scrapy.Field()
pipelines.py
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html from scrapy.exporters import JsonLinesItemExporter from lian.items import ErShouFangItem, NewHouseItem,RentHouseItem,OfficeHouseItem,XiaoquHouseItem # 已经导入成功,不用管 class LianPipeline(object): def __init__(self): self.ershoufang_fp = open('ershoufang.json', 'wb') self.ershoufang_exporter = JsonLinesItemExporter(self.ershoufang_fp, ensure_ascii=False) self.newhouse_fp = open('newhouse.json', 'wb') self.newhouse_exporter = JsonLinesItemExporter(self.newhouse_fp, ensure_ascii=False) self.renthouse_fp = open('renthouse.json', 'wb') self.renthouse_exporter = JsonLinesItemExporter(self.renthouse_fp, ensure_ascii=False) self.officehouse_fp = open('officehouse.json', 'wb') self.officehouse_exporter = JsonLinesItemExporter(self.officehouse_fp, ensure_ascii=False) self.xiaoquhouse_fp = open('xiaoquhouse.json', 'wb') self.xiaoquhouse_exporter = JsonLinesItemExporter(self.xiaoquhouse_fp, ensure_ascii=False) def process_item(self, item, spider): if isinstance(item, ErShouFangItem): self.ershoufang_exporter.export_item(item) elif isinstance(item, NewHouseItem): self.newhouse_exporter.export_item(item) elif isinstance(item, RentHouseItem): self.renthouse_exporter.export_item(item) elif isinstance(item ,OfficeHouseItem): self.officehouse_exporter.export_item(item) else: self.xiaoquhouse_exporter.export_item(item) return item def close_spider(self, spider): self.ershoufang_fp.close() self.newhouse_fp.close() self.renthouse_fp.close() # self.officehouse_fp.closed() self.xiaoquhouse_fp.close()
lian_spider.py
# -*- coding: utf-8 -*- import scrapy import re from lian.items import ErShouFangItem,NewHouseItem,RentHouseItem,OfficeHouseItem,XiaoquHouseItem # 已经导入成功,不用管 class LianSpiderSpider(scrapy.Spider): name = 'lian_spider' allowed_domains = ['lianjia.com'] start_urls = ['https://www.lianjia.com/city/'] headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36', 'Cookie': 'select_city=510700; lianjia_uuid=8bd3d017-2c99-49a5-826e-986f56ce99b9; _smt_uid=5cd3cd13.44c49764; UM_distinctid=16a9b59145a158-0442ba7704d667-3b654406-c0000-16a9b59146011e; _jzqckmp=1; _ga=GA1.2.822868133.1557384475; _gid=GA1.2.801531476.1557384475; all-lj=ed5a77c9e9ec3809d0c1321ec78803ae; lianjia_ssid=50fd11a7-d48c-4dde-b281-287224c40487; TY_SESSION_ID=ae45e1a4-b6d9-46bb-81c8-7cff32931953; Hm_lvt_9152f8221cb6243a53c83b956842be8a=1557384618,1557389971,1557392984,1557446598; _jzqc=1; _jzqy=1.1557384468.1557446599.1.jzqsr=baidu|jzqct=%E9%93%BE%E5%AE%B6.-; _qzjc=1; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%2216a9b5916632a6-01ac8dcdbbb8a7-3b654406-786432-16a9b59166452e%22%2C%22%24device_id%22%3A%2216a9b5916632a6-01ac8dcdbbb8a7-3b654406-786432-16a9b59166452e%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22%22%2C%22%24latest_referrer_host%22%3A%22%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%7D%7D; _jzqa=1.1500973956232310800.1557384468.1557451920.1557454945.6; _jzqx=1.1557451920.1557454945.2.jzqsr=mianyang%2Elianjia%2Ecom|jzqct=/ershoufang/pag1/.jzqsr=mianyang%2Elianjia%2Ecom|jzqct=/ershoufang/; CNZZDATA1255604082=609852050-1557381958-https%253A%252F%252Fwww.baidu.com%252F%7C1557455869; CNZZDATA1254525948=1645681089-1557382543-https%253A%252F%252Fwww.baidu.com%252F%7C1557458144; CNZZDATA1255633284=262578687-1557381275-https%253A%252F%252Fwww.baidu.com%252F%7C1557458627; Hm_lpvt_9152f8221cb6243a53c83b956842be8a=1557459240; _qzja=1.677427564.1557384472885.1557451920228.1557454945305.1557459200351.1557459240226.0.0.0.62.6; _qzjb=1.1557454945305.13.0.0.0; _qzjto=33.3.0; _jzqb=1.13.10.1557454945.1' } # 每个城市 def parse(self, response): lis = response.xpath('//div[@class="city_list_section"]/ul/li') city_links = [] for li in lis: province = li.xpath('.//div[@class="city_list_tit c_b"]/text()').extract_first() # print(province) lis2 = li.xpath('.//div[@class="city_province"]/ul/li') city_info = {} for l in lis2: city_info['city'] = l.xpath('./a/text()').extract_first() city_info['city_link'] = l.xpath('./a/@href').extract_first() city_links.append(city_info) # print(city_info) yield scrapy.Request( url=city_info['city_link'], headers=self.headers, callback=self.parse_rent_type, meta={'city_name': (province,city_info['city'])} ) # 爬取海外房源,所有城市标题上房有海外房源的信息均为一致,所以只爬取一次 # yield scrapy.Request( # url='https://i.lianjia.com/us', # headers=self.headers, # callback=self.parse_haiwai # ) # 类型(二手房,新房,租房,商业办公,小区) def parse_rent_type(self, response): province,city_name = response.meta.get('city_name') lis = response.xpath('//div[@class="nav typeUserInfo"]/ul/li') for li in lis: type = li.xpath('./a/text()').extract_first() if type == '二手房': ershoufang_link = li.xpath('./a/@href').extract_first() # print("city:{}————————{}".format(city_name,ershoufang_link)) next_urls = [ershoufang_link + '/pg{}/'.format(str(i)) for i in range(1, 101)] i = 0 for url in next_urls: i = i+1 yield scrapy.Request( url=url, headers=self.headers, callback=self.parse_ershoufang, meta={'city_name': (province,city_name,i)} ) # 不好找页码 elif type == '新房': xinfang_link = li.xpath('./a/@href').extract_first() xinfang_link = xinfang_link + '/loupan/' yield scrapy.Request( url=xinfang_link, headers=self.headers, callback=self.parse_xinfang, meta={'city_name': (province,city_name)} ) elif type == '租房': zufang_link = li.xpath('./a/@href').extract_first() next_urls = [zufang_link + '/pg{}/'.format(str(i)) for i in range(1, 101)] i = 0 for url in next_urls: i = i + 1 yield scrapy.Request( url=url, headers=self.headers, callback=self.parse_zufang, meta={'city_name': (url,province,city_name,i)} ) # 不好找页码 elif type == '商业办公': #TODO 有一个重定向,只会爬取一页 shangyebangong_link = li.xpath('./a/@href').extract_first() shangyebangong_link = str(shangyebangong_link)+"/xzl/rent/mlist" # print(province, city_name,shangyebangong_link) if shangyebangong_link == None: continue yield scrapy.Request( url=shangyebangong_link, headers=self.headers, callback=self.parse_shangyebangong, meta={'city_name': (province,city_name)} ) # 不好找页码 elif type == '小区': xiaoqu_link = li.xpath('./a/@href').extract_first() yield scrapy.Request( url=xiaoqu_link, headers=self.headers, callback=self.parse_xiaoqu, meta={'city_name': (province,city_name)} ) # 获取二手房主页item+ def parse_ershoufang(self, response): province,city_name,i = response.meta.get('city_name') lis = response.xpath('//ul[@class="sellListContent"]/li') for li in lis: ershou_detail_link = li.xpath('.//div[@class="title"]/a/@href').extract_first() # 注意有的房屋信息为None if ershou_detail_link == None: continue # print("{}——————{}".format(city_name,ershou_detail_link)) yield scrapy.Request( url=ershou_detail_link, headers=self.headers, callback=self.parse_ershoufang_detail, meta={'city_name': (ershou_detail_link,province,city_name,i)} ) # 二手房item详情页 def parse_ershoufang_detail(self, response): ershou_detail_link,province,city_name,i = response.meta.get('city_name') title = response.xpath('//div[@class="sellDetailHeader"]//div[@class="title"]/h1/text()').extract_first() # print("***第{}页*** 城市:{} 二手房 标题:{}".format(i,city_name, title)) total_price = response.xpath('//div[@class="price "]/span[@class="total"]/text()').extract_first() + str(response.xpath('//div[@class="price "]/span[@class="unit"]/span/text()').extract_first()).strip() single_price = response.xpath('//span[@class="unitPriceValue"]/text()').extract_first() + str(response.xpath('//span[@class="unitPriceValue"]/i/text()').extract_first()) room_info = response.xpath('//div[@class="room"]/div[1]/text()').extract_first() + '-' + response.xpath('//div[@class="room"]/div[2]/text()').extract_first() region = response.xpath('//div[@class="areaName"]/span[@class="info"]/a[1]/text()').extract_first() + '-' + response.xpath('//div[@class="areaName"]/span[@class="info"]/a[2]/text()').extract_first() direction = response.xpath('//div[@class="type"]/div[1]/text()').extract_first() + '-' + response.xpath('//div[@class="type"]/div[2]/text()').extract_first() area = response.xpath('//div[@class="area"]/div[1]/text()').extract_first() house_struct = response.xpath('//div[@class="area"]/div[2]/text()').extract_first() huxing = response.xpath('//div[@class="introContent"]/div[1]/div[2]/ul/li[1]/text()').extract_first() buy_time = response.xpath('//div[@class="transaction"]/div[2]/ul/li[3]/span[2]/text()').extract_first() print("***第{}页*** 城市:{} 二手房 标题:{} 总价:{} 单价:{} 楼层:{} 住宅位置:{} 房屋朝向:{} 建筑面积:{} 建筑类型:{} 房屋户型:{} 购买时间:{}".format(i, city_name, title,total_price,single_price,room_info,region,direction,area,house_struct,huxing,buy_time)) item = ErShouFangItem( province = province, city = city_name, total_price = total_price, single_price = single_price, room_info = room_info, region = region, direction = direction, area = area, house_struct = house_struct, huxing = huxing, buy_time = buy_time, ershou_detail_url = ershou_detail_link ) yield item # 新房楼盘主页 def parse_xinfang(self, response): province,city_name = response.meta.get('city_name') lis = response.xpath('//ul[@class="resblock-list-wrapper"]/li') for li in lis: title = li.xpath('./a[@class="resblock-img-wrapper "]/@title').extract_first() region_infos = li.xpath('.//div[@class="resblock-location"]//text()').extract() region = '' for i in region_infos: region = region + i.replace('\n', '').strip(' ') room_infos = li.xpath('.//a[@class="resblock-room"]/span//text()').extract() room_info = '' for i in room_infos: room_info = room_info + i.strip(' ') area_infos = li.xpath('.//div[@class="main-price"]/span//text()').extract() area = '' for i in area_infos: area = area + i.strip(' ') # 加上单位并去除首尾空格 price = li.xpath('.//div[@class="main-price"]/span[1]/text()').extract_first() + str(li.xpath('.//div[@class="main-price"]/span[2]/text()').extract_first()).strip() newhouse_detail_url = 'https://bj.fang.lianjia.com'+str(li.xpath('./a[@class="resblock-img-wrapper "]/@href').extract_first()) print("城市:{} 新房 {} {}".format(city_name,title, newhouse_detail_url)) item = NewHouseItem( province=province, city = city_name, title = title, region = region, room_info = room_info, area = area, price = price, newHouse_detail_url = newhouse_detail_url ) yield item # 租房首页 def parse_zufang(self, response): zufang_link, province, city_name, i = response.meta.get('city_name') # 去掉链接pg页码信息 # print("去掉之前:{}".format(zufang_link)) zufang_link = re.findall('(.*?)/zufang//pg\d+/',zufang_link)[0] items = response.xpath('//div[@class="content__list"]/div') for zu in items: zufang_detail_link = zufang_link + str(zu.xpath('./a[@class="content__list--item--aside"]/@href').extract_first()) # 注意有的房屋信息为None if zufang_detail_link == None: continue # print("{}——————{}".format(city_name,zufang_detail_link)) yield scrapy.Request( url=zufang_detail_link, headers=self.headers, callback=self.parse_zufang_detail, meta={'city_name': (zufang_detail_link,province,city_name,i)} ) # 租房信息详情 def parse_zufang_detail(self, response): zufang_detail_link, province, city_name, i = response.meta.get('city_name') title = response.xpath('//div[@class="content clear w1150"]/p/text()').extract_first() price = response.xpath('//div[@class="content__aside fr"]/p/span/text()').extract_first() house_infos = response.xpath('//ul[@class="content__aside__list"]/p//text()').extract() house_info = '' for i in house_infos: house_info = house_info + i.replace('\n','/').strip(' ') # 发布时间 pub_time = str(response.xpath('string(//div[@class="content__subtitle"])').extract_first()) pub_time = re.findall('\d{4}-\d{1,2}-\d{1,2}',pub_time) if pub_time: pub_time = pub_time[0] else: pub_time = None # 入住时间 in_time = response.xpath('//div[@class="content__article__info"]/ul/li[3]/text()').extract_first() # 租期 lease = response.xpath('//div[@class="content__article__info"]/ul/li[5]/text()').extract_first() # 楼层 floor = response.xpath('//div[@class="content__article__info"]/ul/li[8]/text()').extract_first() # 是否有电梯 lift = response.xpath('//div[@class="content__article__info"]/ul/li[9]/text()').extract_first() # 是否有停车位 carport = response.xpath('//div[@class="content__article__info"]/ul/li[11]/text()').extract_first() use_water = response.xpath('//div[@class="content__article__info"]/ul/li[12]/text()').extract_first() use_electricity = response.xpath('//div[@class="content__article__info"]/ul/li[14]/text()').extract_first() use_gas = response.xpath('//div[@class="content__article__info"]/ul/li[15]/text()').extract_first() # print(" 城市:{} 租房 {} {} {} {} {} {} {}".format(city_name, lease,floor,lift,carport,use_water,use_electricity,use_gas)) item = RentHouseItem( province = province, city = city_name, title = title, price = price, house_info = house_info, pub_time = pub_time, in_time = in_time, lease = lease, floor = floor, lift = lift, carport = carport, use_water = use_water, use_electricity = use_electricity, use_gas = use_gas, rent_detail_url = zufang_detail_link ) yield item print("***第{}页*** 城市:{} 租房 {} {}".format(i, city_name, title, price)) # 海外房源信息 # def parse_haiwai(self,response): # items = response.xpath('//*[@id="env"]/div[4]/div/div[2]') # for i in items: # title = i.xpath('.//div[class="titles"]/a/div/text()').extract_first() # price = i.xpath('.//span[@class="fr"]/text()').extract_first() # print("城市:美国 标题:{} 价格:{}".format(title,price)) # 商业办公主页item详情 def parse_shangyebangong(self, response): province, city_name = response.meta.get('city_name') items = response.xpath('//div[@class="result__ul"]/a') for i in items: office_detail_url = response.xpath('./@href') title = i.xpath('./div/p[@class="result__li-title"]/text()').extract_first() area = i.xpath('./div/p[@class="result__li-features"]/text()').extract_first() nums = i.xpath('./div/p[@class="result__li-other"]/text()').extract_first() price = i.xpath('./div/p[@class="result__li-price"]/span/text()').extract_first() item = OfficeHouseItem( province = province, city = city_name, title = title, price = price, num = nums, area = area, office_detail_url = office_detail_url ) yield item print("城市:{} 商业办公 标题:{} 面积:{} 数量:{} 价格:{} url:{}".format(city_name, title, area, nums, price, office_detail_url)) # 小区主页item def parse_xiaoqu(self, response): province,city_name = response.meta.get('city_name') ul = response.xpath('//ul[@class="listContent"]/li') for li in ul: xiaoqu_detail_link = li.xpath('.//a[@class="img"]/@href').extract_first() if xiaoqu_detail_link == None: continue yield scrapy.Request( url=xiaoqu_detail_link, headers=self.headers, callback=self.parse_xiaoqu_detail, meta={'city_name': (xiaoqu_detail_link,province,city_name)} ) # 小区item详情 def parse_xiaoqu_detail(self, response): xiaoqu_detail_link,province,city_name = response.meta.get('city_name') title = response.xpath('//h1[@class="detailTitle"]/text()').extract_first() region = response.xpath('//div[@class="detailDesc"]/text()').extract_first() single_price = response.xpath('//span[@class="xiaoquUnitPrice"]/text()').extract_first() # 注意有的房屋没有建成时间信息,影响后面值得获取,需要进行判断后准确取值 build_time = str(response.xpath('//div[@class="xiaoquInfo"]/div[1]/span[2]/text()').extract_first()).strip() house_struct = None service_fees = None pattern = re.compile('[0-9]+') if pattern.findall(build_time): build_time = build_time house_struct = response.xpath('//div[@class="xiaoquInfo"]/div[2]/span[2]/text()').extract_first() service_fees = response.xpath('//div[@class="xiaoquInfo"]/div[3]/span[2]/text()').extract_first() service_company = response.xpath('//div[@class="xiaoquInfo"]/div[4]/span[2]/text()').extract_first() build_company = response.xpath('//div[@class="xiaoquInfo"]/div[5]/span[2]/text()').extract_first() building_nums = response.xpath('//div[@class="xiaoquInfo"]/div[6]/span[2]/text()').extract_first() house_nums = response.xpath('//div[@class="xiaoquInfo"]/div[7]/span[2]/text()').extract_first() else: build_time = None house_struct = response.xpath('//div[@class="xiaoquInfo"]/div[1]/span[2]/text()').extract_first() service_fees = response.xpath('//div[@class="xiaoquInfo"]/div[2]/span[2]/text()').extract_first() service_company = response.xpath('//div[@class="xiaoquInfo"]/div[3]/span[2]/text()').extract_first() build_company = response.xpath('//div[@class="xiaoquInfo"]/div[4]/span[2]/text()').extract_first() building_nums = response.xpath('//div[@class="xiaoquInfo"]/div[5]/span[2]/text()').extract_first() house_nums = response.xpath('//div[@class="xiaoquInfo"]/div[6]/span[2]/text()').extract_first() item = XiaoquHouseItem( province=province, city = city_name, title=title, region=region, single_price=single_price, build_time=build_time, house_struct=house_struct, service_fees=service_fees, service_company=service_company, build_company=build_company, building_nums=building_nums, house_nums=house_nums, xiaoqu_detail_url=xiaoqu_detail_link ) yield item print("省份:{} 城市:{} 小区 {} {} {} {} {} {} {}".format(province, city_name, build_time,house_struct,service_fees,service_company,build_company,building_nums,house_nums))
settings.py
# -*- coding: utf-8 -*- # Scrapy settings for lian project # # For simplicity, this file contains only settings considered important or # commonly used. You can find more settings consulting the documentation: # # https://doc.scrapy.org/en/latest/topics/settings.html # https://doc.scrapy.org/en/latest/topics/downloader-middleware.html # https://doc.scrapy.org/en/latest/topics/spider-middleware.html BOT_NAME = 'lian' SPIDER_MODULES = ['lian.spiders'] NEWSPIDER_MODULE = 'lian.spiders' LOG_LEVEL = "WARNING" # Crawl responsibly by identifying yourself (and your website) on the user-agent USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.157 Safari/537.36' # Obey robots.txt rules ROBOTSTXT_OBEY = True DOWNLOAD_FAIL_ON_DATALOSS = False # Configure maximum concurrent requests performed by Scrapy (default: 16) #CONCURRENT_REQUESTS = 32 # Configure a delay for requests for the same website (default: 0) # See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay # See also autothrottle settings and docs #DOWNLOAD_DELAY = 3 # The download delay setting will honor only one of: #CONCURRENT_REQUESTS_PER_DOMAIN = 16 #CONCURRENT_REQUESTS_PER_IP = 16 # Disable cookies (enabled by default) #COOKIES_ENABLED = False # Disable Telnet Console (enabled by default) #TELNETCONSOLE_ENABLED = False # Override the default request headers: #DEFAULT_REQUEST_HEADERS = { # 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', # 'Accept-Language': 'en', #} # Enable or disable spider middlewares # See https://doc.scrapy.org/en/latest/topics/spider-middleware.html #SPIDER_MIDDLEWARES = { # 'lian.middlewares.LianSpiderMiddleware': 543, #} # Enable or disable downloader middlewares # See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html #DOWNLOADER_MIDDLEWARES = { # 'lian.middlewares.LianDownloaderMiddleware': 543, #} # Enable or disable extensions # See https://doc.scrapy.org/en/latest/topics/extensions.html #EXTENSIONS = { # 'scrapy.extensions.telnet.TelnetConsole': None, #} # Configure item pipelines # See https://doc.scrapy.org/en/latest/topics/item-pipeline.html ITEM_PIPELINES = { 'lian.pipelines.LianPipeline': 300, } # Enable and configure the AutoThrottle extension (disabled by default) # See https://doc.scrapy.org/en/latest/topics/autothrottle.html #AUTOTHROTTLE_ENABLED = True # The initial download delay #AUTOTHROTTLE_START_DELAY = 5 # The maximum download delay to be set in case of high latencies #AUTOTHROTTLE_MAX_DELAY = 60 # The average number of requests Scrapy should be sending in parallel to # each remote server #AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0 # Enable showing throttling stats for every response received: #AUTOTHROTTLE_DEBUG = False # Enable and configure HTTP caching (disabled by default) # See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings #HTTPCACHE_ENABLED = True #HTTPCACHE_EXPIRATION_SECS = 0 #HTTPCACHE_DIR = 'httpcache' #HTTPCACHE_IGNORE_HTTP_CODES = [] #HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
结果: