redis面试知识
redis
1 redis是什么
redis是一种支持Key-Value等多种数据结构的存储系统。可用于缓存,事件发布或订阅,高速队列等场景。该数据库使用ANSI C语言编写,支持网络,提供字符串,哈希,列表,队列,集合结构直接存取,基于内存,可持久化。
简单来说 redis 就是一个数据库,不过与传统数据库不同的是 redis 的数据是存在内存中的,所以读写速度非常快,因此 redis 被广泛应用于缓存方向。另外,redis 也经常用来做分布式锁。redis 提供了多种数据类型来支持不同的业务场景。除此之外,redis 支持事务 、持久化、LUA脚本、LRU驱动事件、多种集群方案。
2 支持的语言

3 redis的应用场景有哪些
1,会话缓存(最常用)
2,消息队列,比如支付
3,活动排行榜或计数
4,发布,订阅消息(消息通知)
5,商品列表,评论列表等
高性能:
假如用户第一次访问数据库中的某些数据。这个过程会比较慢,因为是从硬盘上读取的。将该用户访问的数据存在缓存中,这样下一次再访问这些数据的时候就可以直接从缓存中获取了。操作缓存就是直接操作内存,所以速度相当快。如果数据库中的对应数据改变的之后,同步改变缓存中相应的数据即可!
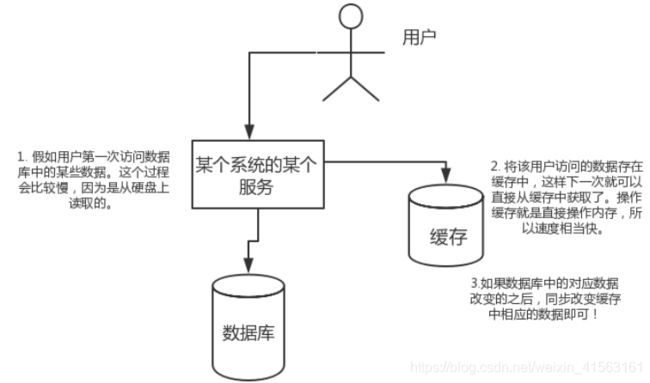
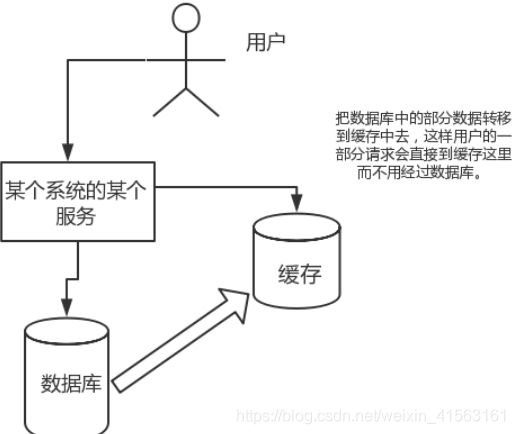
高并发:
直接操作缓存能够承受的请求是远远大于直接访问数据库的,所以我们可以考虑把数据库中的部分数据转移到缓存中去,这样用户的一部分请求会直接到缓存这里而不用经过数据库。
4 redis数据类型
Redis一共支持五种数据类:string(字符串),hash(哈希),list(列表),set(集合)和zset(sorted set有序集合)。
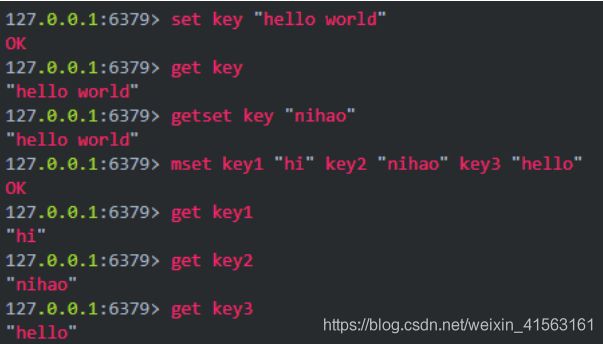
1)字符串(字符串)
它是redis的最基本的数据类型,一个键对应一个值,需要注意是一个键值最大存储512MB。
(2)hash(哈希)
redis hash是一个键值对的集合,是一个string类型的field和value的映射表,适合用于存储对象

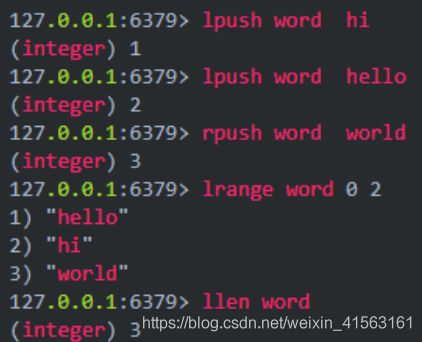
(3)表(列表)
是redis的简单的字符串列表,它按插入顺序排序
(4)组(集合)
是字符串类型的无序集合,也不可重复
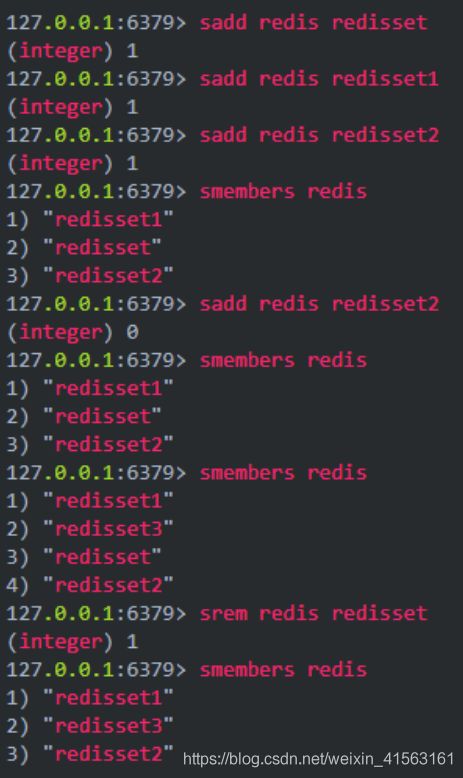
(5)zset(sorted set有序集合)
是string类型的有序集合,也不可重复
有序集合中的每个元素都需要指定一个分数,根据分数对元素进行升序排序,如果多个元素有相同的分数,则以字典序进行升序排序,sorted set因此非常适合实现排名
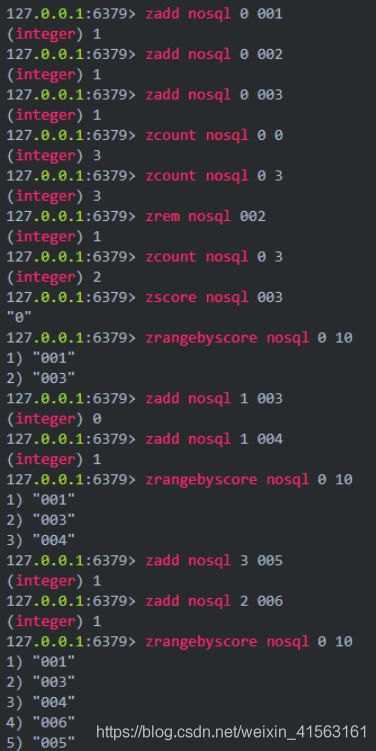
5,redis的服务相关的命令
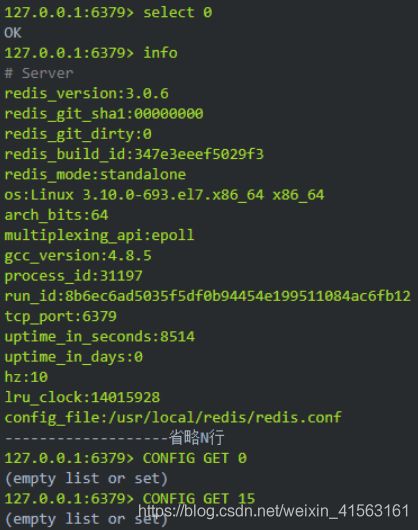
slect#选择数据库(数据库编号0-15)
退出#退出连接
信息#获得服务的信息与统计
monitor#实时监控
config get#获得服务配置
flushdb#删除当前选择的数据库中的key
flushall#删除所有数据库中的键
6,redis的发布与订阅
redis的发布与订阅(发布/订阅)是它的一种消息通信模式,一方发送信息,一方接收信息。
下图是三个客户端同时订阅同一个频道
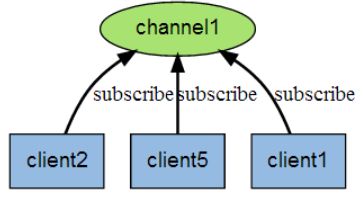
下图是有新信息发送给频道1时,就会将消息发送给订阅它的三个客户端
7,redis的持久化
能,将内存中的数据异步写入硬盘中,两种方式:RDB(默认)和AOF
RDB持久化原理:通过bgsave命令触发,然后父进程执行fork操作创建子进程,子进程创建RDB文件,根据父进程内存生成临时快照文件,完成后对原有文件进行原子替换(定时一次性将所有数据进行快照生成一份副本存储在硬盘中)
优点:是一个紧凑压缩的二进制文件,Redis加载RDB恢复数据远远快于AOF的方式。
缺点:由于每次生成RDB开销较大,非实时持久化,
AOF持久化原理:开启后,Redis每执行一个修改数据的命令,都会把这个命令添加到AOF文件中。
优点:实时持久化。
缺点:所以AOF文件体积逐渐变大,需要定期执行重写操作来降低文件体积,加载慢
8,redis的性能测试
自带相关测试工具
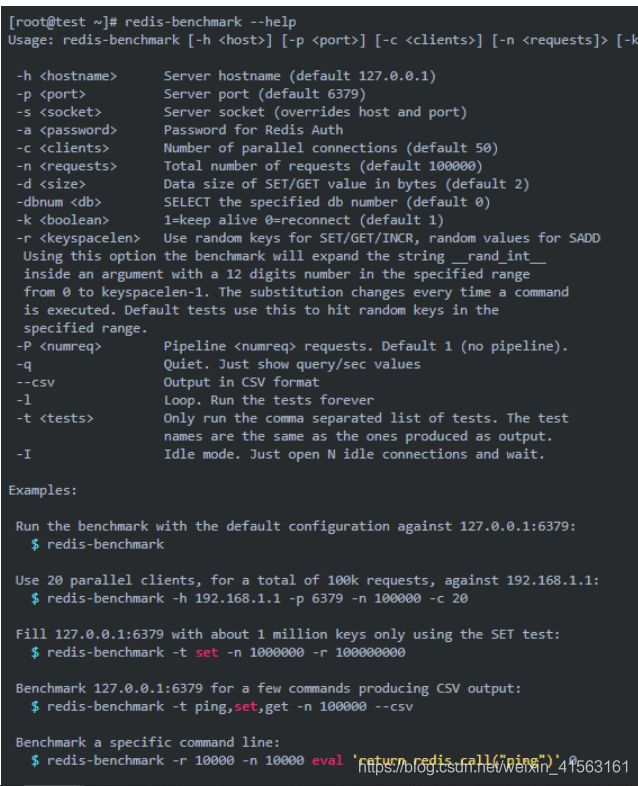
实际测试同时执行100万的请求

5 为什么redis是单线程的都那么快?
1.数据存于内存
2.用了多路复用I/O
3.单线程 避免了不必要的上下文切换和竞争条件
6 redis的内部实现
内部实现采用epoll,采用了epoll+自己实现的简单的事件框架。epoll中的读、写、关闭、连接都转化成了事件,然后利用epoll的多路复用特性,绝不在io上浪费一点时间 这3个条件不是相互独立的,特别是第一条,如果请求都是耗时的,采用单线程吞吐量及性能可想而知了。应该说redis为特殊的场景选择了合适的技术方案。
7 IO多路复用
原因:
由于进程的执行过程是线性的(也就是顺序执行),当我们调用低速系统I/O(read,write,accept等等),进程可能阻塞,此时进程就阻塞在这个调用上,不能执行其他操作.阻塞很正常.
接下来考虑这么一个问题:一个服务器进程和一个客户端进程通信,服务器端read(sockfd1,bud,bufsize),此时客户端进程没有发送数据,那么read(阻塞调用)将阻塞,直到客户端调用write(sockfd,but,size)发来数据.在一个客户和服务器通信时这没什么问题;
当多个客户与服务器通信时当多个客户与服务器通信时,若服务器阻塞于其中一个客户sockfd1,当另一个客户的数据到达套接字sockfd2时,服务器不能处理,仍然阻塞在read(sockfd1,...)上;此时问题就出现了,不能及时处理另一个客户的服务,咋么办?
I/O多路复用:
继续上面的问题,有多个客户连接,sockfd1,sockfd2,sockfd3..sockfdn同时监听这n个客户,当其中有一个发来消息时就从select的阻塞中返回,然后就调用read读取收到消息的sockfd,然后又循环回select阻塞;这样就不会因为阻塞在其中一个上而不能处理另一个客户的消息

那这样子,在读取socket1的数据时,如果其它socket有数据来,那么也要等到socket1读取完了才能继续读取其它socket的数据吧。那不是也阻塞住了吗?而且读取到的数据也要开启线程处理吧,那这和多线程IO有什么区别呢?
1.CPU本来就是线性的不论什么都需要顺序处理并行只能是多核CPU
2.io多路复用本来就是用来解决对多个I/O监听时,一个I/O阻塞影响其他I/O的问题,跟多线程没关系.
3.跟多线程相比较,线程切换需要切换到内核进行线程切换,需要消耗时间和资源.而I/O多路复用不需要切换线/进程,效率相对较高,特别是对高并发的应用nginx就是用I/O多路复用,故而性能极佳.但多线程编程逻辑和处理上比I/O多路复用简单.而I/O多路复用处理起来较为复杂.
Redis常见性能问题和解决方案:
(1) Master最好不要做任何持久化工作,如RDB内存快照和AOF日志文件;(Master写内存快照,save命令调度rdbSave函数,会阻塞主线程的工作,当快照比较大时对性能影响是非常大的,会间断性暂停服务,所以Master最好不要写内存快照;AOF文件过大会影响Master重启的恢复速度)
(2) 如果数据比较重要,某个Slave开启AOF备份数据,策略设置为每秒同步一次
(3) 为了主从复制的速度和连接的稳定性,Master和Slave最好在同一个局域网内
(4) 尽量避免在压力很大的主库上增加从库
(5) 主从复制不要用图状结构,用单向链表结构更为稳定,即:Master <- Slave1 <- Slave2 <- Slave3...;这样的结构方便解决单点故障问题,实现Slave对Master的替换。如果Master挂了,可以立刻启用Slave1做Master,其他不变。