老年人教程: 数据库版本管理工具 Flyway使用文档

一、什么是Flyway ?
Flyway 是一款开源的数据库版本管理工具, 它更倾向于规约优于配置的方式。
Flyway 可以独立于应用实现管理并且跟踪数据库的变更。 支持数据库版本的自动升级,
自带有一套默认的规约,不需要复杂的配置。Migrations 可以写成SQL脚本,也可以集成到JAVA代码中,同时在分布式环境下能够安全可靠的升级数据库,支持失败恢复操作等。
而且flyway命令简单, 可以很快的上手使用。
Flyway主要基于6种基本命令:Migrate, Clean, Info, Validate, Baseline and Repair
目前支持的数据库主要有:Oracle, SQL Server, SQL Azure, DB2, DB2 z/OS, MySQL(including Amazon RDS), MariaDB, Google Cloud SQL, PostgreSQL(including Amazon RDS and Heroku), Redshift, Vertica, H2, Hsql, Derby, SQLite, SAP HANA, solidDB, Sybase ASE and Phoenix.
关于Flyway 的优势,支持的数据库以及其他数据库版本工具对比,可阅读Flyway官方介绍
二、Flway 可以做什么 ?
当用户遵循规范存放好数据库脚本,程序启动的时候,Flyway会连接数据源对应的数据库,并按照版本号进行版本检查,如果不是最新版本,则自动执行升级脚本。
这意味着,当程序连接的是一个全新的数据库的时候,Flyway 会自动初始化应用所需的表结构和基础数据;或者当程序连接到一个落后几个版本的测试数据库的时候,Flyway 会自动帮用户升级到最新的表结构和基础数据。
三、Flway 的获取
Flyway 的获取可以通过(官方网站:https://flywaydb.org/download/) 找到下载地址.
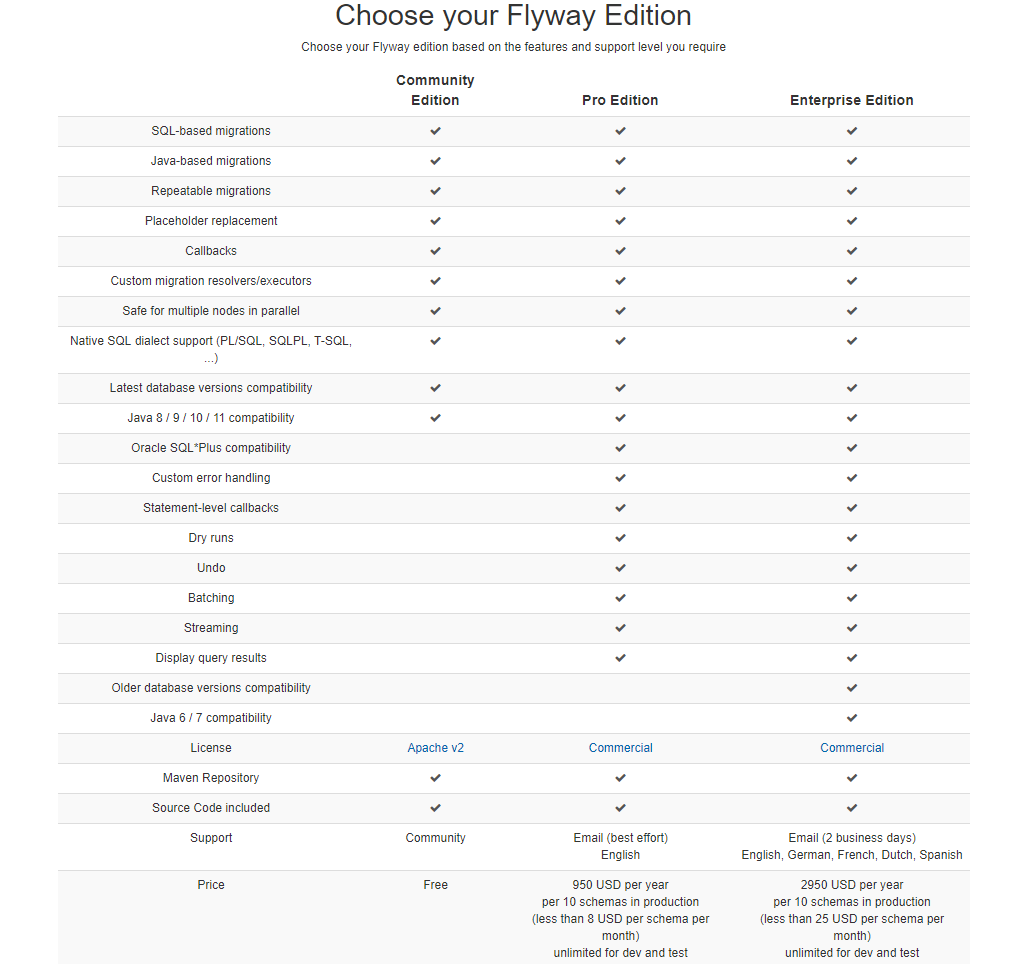
官方网站提供三种不同的版本:
- Community Edition : 社区版,此版本含有Flyway的核心功能
- Pro Edition:专业版本,提供一些高级命令例如回滚等。
- Enterprise Edition:企业版,此版本提供JDK 6的支持。
备注: Flyway 基于jre运行环境, 但无需另外下载,flyway自带运行环境。
四、Flway 的目录结构
1. 概述
如下图所示, Flyway 包含以下

- conf 配置文件存放的地方
- drivers 数据库连接驱动jar包存放的地方
- jars 如果是通过java 进行数据库升级,将升级jar包放在此文件夹下
- jre flyway 自带的jre运行环境
- lib flyway 的代码库
- sql 脚本文件存放的地方
2. sql 升级脚本存放
升级脚本在flyway中被称作 Migration , Migration 里面包含可执行的数据库脚本,用来进行数据库版本变更, 需要注意的是, 放在 sql 文件夹中的脚本, 需要按照 与Flyway约定的方式来命名脚本, Flyway 才能正确识别出你的脚本是用来干什么的, 是什么版本。 Flyway 根据你的脚本来进行分类 , 比如V开头的脚本是升级脚本, R开通的脚本是可重复执行的脚本,然后Flyway 会根据特定规则去对这些脚本进行排序, 然后一个个按顺序去执行它们。
sql 脚本命名类似于 V2__ADD_new_table.sql , 其中
V 是前缀, 位于文件命名的第一个字符,通常用来表示脚本的类型,此处代表是一个升级脚本
**2是版本号,**flyway 会根据此字符换来进行排序
__ 两个下划线是用来区分版本和版本描述的分隔符 , 两个下划线后面就接上这个脚本的描述说明

- 总结
核心的目录 有 sql conf 这两个, 需要记住这两个目录的使用方法。
五、Flway 使用
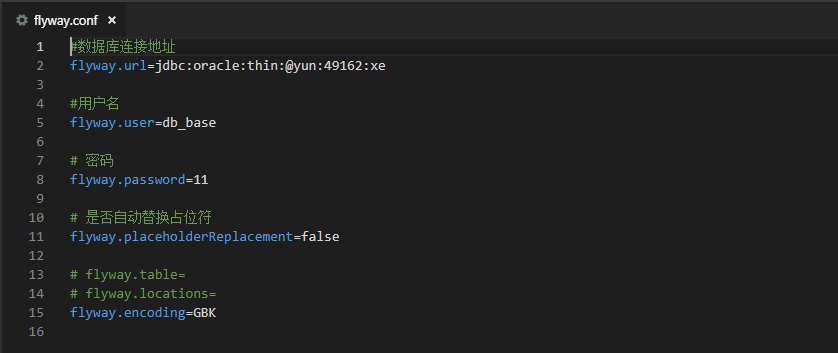
- 配置好数据源
数据源配置可以参考下图 , 需要制定url 和账户密码, 如果不进行配置,会在每次连接的时候提示你进行输入
- 在Flyway 根目录启动终端
windows 下

六、Flyway 相关概念
在正式使用flyway 的命令之前,先对Flyway中会提及的概念做一个介绍,通过了解这些概念,可以帮我们快速掌握Flyway的使用方法
- Migrations
在Flyway 中, 对数据库的所有操作都被称之为 **Migrations **
- migration 可以分为以下几类
- version migrations ( 版本升级 , 在Migrations命名中前缀为 V)
- undo migrations (版本回滚, 在Migrations命名中前缀为 U)
- Repeatable Migrations (可重复执行的操作 , 在Migrations命名中前缀为 R)
下图是基于SQL脚本的migrations的命名

- 执行方式又可以分为两种
- SQL_base Migrations (基于SQL脚本的Migrations)
- Java_base Migrations (基于JAVA代码的Migrations)
- migrations 的状态
| 状态名 | 状态解释 | 备注 |
|:----|:----|:----|
| pending | 准备状态中的Migrations , 还没被执行。 | 正常情况下,新版本未执行的脚本状态为 pending |
| success | 成功被执行的migrations | |
| 空 | 如果数据库支持DDL事务,在操作失败后将不会有任何显示 | |
| failed | 如果数据库不支持DDL事务,那么没有被成功执行的migrations会显示此状态,此时可能需要手动去处理DDL操作带来的变化 | |
| undone | 执行版本回滚后会显示此状态 | 针对 回滚脚本 |
| outdated | 自上次应用校验和更改后,可重复迁移被标记为过期,直到再次执行为止 | 针对 可重复执行脚本 |
| future | 当Flyway发现一个版本高于最高已知版本的应用版本migrations时(这通常发生在软件的新版本已经成功migrations),该migrations被标记为未来。 | |
- Callbacks
Callbacks 是指回调函数,Callbacks 能够使你在整个migrations的生命周期中插入新的操作。
下面这些是Flyway 支持的操作:
| Name | Execution |
|---|---|
| beforeMigrate | Before Migrate runs |
| beforeEachMigrate | Before every single migration during Migrate |
| beforeEachMigrateStatement Flyway Pro | Before every single statement of a migration during Migrate |
| afterEachMigrateStatement Flyway Pro | After every single successful statement of a migration during Migrate |
| afterEachMigrateStatementError Flyway Pro | After every single failed statement of a migration during Migrate |
| afterEachMigrate | After every single successful migration during Migrate |
| afterEachMigrateError | After every single failed migration during Migrate |
| afterMigrate | After successful Migrate runs |
| afterMigrateError | After failed Migrate runs |
| beforeUndo Flyway Pro | Before Undo runs |
| beforeEachUndo Flyway Pro | Before every single migration during Undo |
| beforeEachUndoStatement Flyway Pro | Before every single statement of a migration during Undo |
| afterEachUndoStatement Flyway Pro | After every single successful statement of a migration during Undo |
| afterEachUndoStatementError Flyway Pro | After every single failed statement of a migration during Undo |
| afterEachUndo Flyway Pro | After every single successful migration during Undo |
| afterEachUndoError Flyway Pro | After every single failed migration during Undo |
| afterUndo Flyway Pro | After successful Undo runs |
| afterUndoError Flyway Pro | After failed Undo runs |
| beforeClean | Before Clean runs |
| afterClean | After successful Clean runs |
| afterCleanError | After failed Clean runs |
| beforeInfo | Before Info runs |
| afterInfo | After successful Info runs |
| afterInfoError | After failed Info runs |
| beforeValidate | Before Validate runs |
| afterValidate | After successful Validate runs |
| afterValidateError | After failed Validate runs |
| beforeBaseline | Before Baseline runs |
| afterBaseline | After successful Baseline runs |
| afterBaselineError | After failed Baseline runs |
| beforeRepair | Before Repair runs |
| afterRepair | After successful Repair runs |
| afterRepairError | After failed Repair runs |
使用方法:
Flyway将会自动扫描 SQL 文件, 比如说 beforeMigrate.sql, beforeEachMigrate.sql, afterEachMigrate.sql, …
文件的命名对应的就是具体的Callbacks
3.Error Overrides
错误覆盖(Flyway Pro 提供的高级功能)
当Flyway 执行 SQL脚本的时候, 它会报告所有由数据库返回的警告或错误信息。
如果数据库返回的信息是一个错误, 那么Flyway 将会停止(快速失败策略),并且告诉你错误信息,并且将此次migrations标记为失败。
你可以根据Flyway提供的信息进行调整修复。
错误信息大概会像下面这个样子
Migration V1__Create_person_table.sql failed
--------------------------------------------
SQL State : 42001
Error Code : 42001
Message : Syntax error in SQL statement "CREATE TABLE1[*] PERSON "; expected "OR, FORCE, VIEW, ...
Location : V1__Create_person_table.sql (/flyway-tutorial/V1__Create_person_table.sql)
Line : 1
Statement : create table1 PERSON
这种处理方式在默认情况下是很好的, 但在实际使用中可能你需要别的处理方法
- 将错误视为警告,在迁移成功后再修复
- 将警告视为错误, 因为你希望进行快速失败,能够尽快调整好
- 预先为特定的警告或者错误安排一个处理方案。
Flyway Pro 能够为这种场景提供支持。
比如,升级脚本中包含添加字段的语句,但是如果此时数据库已经存在要添加的字段,SQL的执行将会报错。
我们可以在flyway.conf 配置文件中添加
flyway.errorOverrides=72000:1430:W
其中
SQL STATE : 72000
ERROR CODE : 1430
w 是警告的意思, E 是错误。
此时,再次执行mirgations的时候,Flyway 会把这个“表中已存在要添加的列”当作警告,而不会停止下来。
4.Dry Runs
在使用Flyway 的时候,默认情况它会扫描所有的migrations, 然后直接应用于数据库中。
但是,某些情况下,你可能希望:
- 预览 migrations 所作的更改。
- 在应用前,整理出SQL文件 交给DBA去评审
- 使用Flyway确定哪些需要更新,但使用不同的工具来应用实际的数据库更改。
实施:
当使用DryRuns模式的时候, Flyway 于数据库建立只读连接,它将会评估运行迁移所需要的SQL文件,最后生成报告。然后检查报告,如果报告可以满足,这指示Flyway执行,如果不想让Flyway去执行, 可以将整理的SQL文件交由其他数据库工具去运行。
当然这个SQL包含对历史表的记录和变更, 因此你无需担心在其他工具执行会影响flyway的跟踪。
使用:
- 配置 flyway.dryRunOutput 使flyway 进入dryRun模式
七、Flyway 的基本命令
- flyway info 查看当前数据库的版本信息
flyway info 会显示出当前数据库脚本的执行情况,这里列出的脚本列表,是我们放在sql文件下的脚本文件。
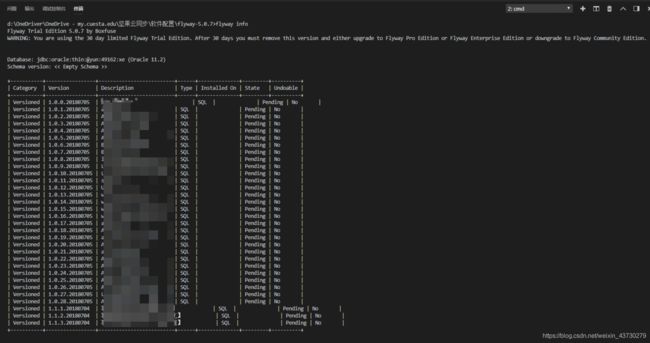
图中各个字段的意思如下
# schema_version 版本记录表
# column name | column type | desc
installed_rank | integer | 序号
version | varchar(50) | 版本号
description | varchar(200) | 版本描述
type | varchar(20) | 类型(可以是SQL或JAVA代码)
script | varchar(1000) | 脚本
checksum | integer | 信息摘要,文件被修改后值会变
installed_by | varchar(100) | 应用位置
installed_on | timestamp | 应用时间
execution_time | integer | 执行耗费时间
state | boolean | 执行结果
根据 state 可以知道, 当前的脚本都是未执行状态。
2.flyway baseline 建立版本基线
在新库使用第一次使用flyway 的时候,需要执行一次flyway baseline ,来建立版本历史表,并且初始化当前所在的版本。

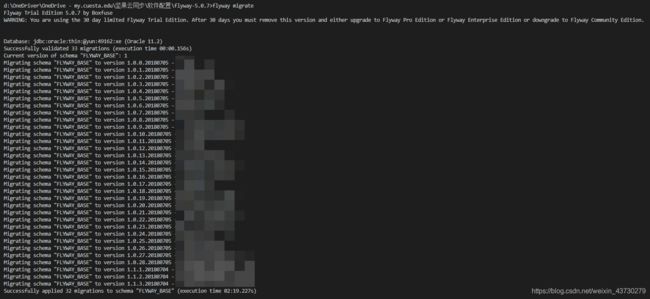
- flyway migrate 执行数据库升级脚本
我们根据flyway info 查询到当前数据库所在的版本, 假设是新库, 则会执行所有flyway info 列表中列举出来的脚本。如果已经是最新版本,flyway将不会执行任何更新脚本。
- flyway repair 修复错误的升级任务
如果flyway 在执行升级脚本过程中发生错误,会停止执行,并且通过flyway info 查看是能看到执行失败的脚本版本。 此时如果不进行任何处理,是不能继续flyway migrate 的。因此我们需要修正脚本内容,修改脚本内容后 执行 flyway repair 来修复执行情况记录,告诉flyway 我们已经调整好错误,可以再次尝试去执行升级脚本。
- flyway clean 删库命令
**需要特别注意的地方!生产环境下应当禁止此命令!**flyway clean 会将当前数据库的所有表结构,视图,函数等所有东西清空,让其变成一个全新的空库。用于测试或者开发快速进行数据库测试的命令, 生产环境下需要在flyway.conf 中禁用此命令!
- flyway undo 回滚功能(Flyway Pro)
flyway undo 命令能够方便我们管理回滚脚本,但是此功能只在flyway pro中提供。
flyway undo 与 flyway mirgate 命令相反, flyway undo 会把当前的版本回滚到上一个版本,实现原理是通过执行用户事先安排的回滚脚本 。
比如说 在版本1上执行了 升级脚本 V1__update.sql。
alter table APPR_TABLE add test_column varchar2(100);
那么你需要弄一个 U1_undo.sql 来回滚V1 的操作
alter table APPR_TABLE drop column test_column;
版本号需要对应, 如果当前数据库版本处于1.4.1 , 那么flyway 将会执行1.4.1的回滚脚本。
重要的提醒:
尽管Flyway undo 的概念很不错,但它实际上还是依赖用户编写的脚本,如果在数据库实际使用过程中进行的一些破坏性的操作(比如 drop, delete, truncate, …),那么undo命令实际上很难去实现用户实际的操作目标,undo 最主要的目的是作用于一些可控的情况, 所以不要以为有了回滚功能你就能够安全的执行任意操作。
【附录】:常见问题
- flyway 会自动记录我们对数据库的修改吗?
答: flyway并不是类似于git之类的版本管理工具,能够自动跟踪数据库的变更,这是一项异常复杂的工程。 flyway能做的就是记录你通过flyway migrate 执行的脚本,所以仍需要开发去整理数据库脚本的升级补丁,关于数据库结构之间的变化可以使用navicat进行新旧数据结构对比生成对应脚本,最后将脚本整理到flyway 即可
- 有了回滚功能我是否能够安全的对数据库进行一些危险操作?
答:flyway 的 undo 功能是由用户编写脚本来实现的,如果你要删库,请编写好相应的恢复脚本。
- flyway 是如何管理同一个schema不同应用的历史版本表?
答: flyway 的默认历史版本表表名是 “flyway_schema_history” , 这个表名可以通过配置文件来配置, 不同的应用配置不同的历史版本表名即可。 例如: ApprOne 的历史表可以命名为“approne_schema_history”, ApprTwo 的历史表命名为 ‘apprtwo_schema_history’
- plsql也可以批量执行sql脚本,为什么使用flyway?
答:一两个脚本确实,plsql也可以很好的去批量执行,可是plsql的执行并没有记录,有时候可能会由于认为疏忽漏掉或者忘记是否执行过,而且没有规范明确的升级流程。flyway 是一个很强大的数据库版本管理软件,可以进行逻辑编程,进行复杂的数据库升级业务。
- Flyway 的软件生态如何?
答:官方宣称2017年 flyway的下载量达到 4300000 次,项目在github上有源代码,Spring Boot内置对Flyway 的支持。总的来说是一款稳定成熟的产品。
- 如果在当前版本之前加入新的脚本,flyway是否会执行?
答: 不会, flyway 只关注新的数据库脚本,对于旧版本的脚本增减将会被flyway忽略掉。
【附录】:配置文件
#----------------------------------------------------------------
# Jdbc url 用于连接数据库
# 例子
# --------
# 数据库驱动必须放到 /drivers 目录下,大多数驱动是开箱即用
# oracle 下 TNS_ADMIN环境变量必须指向tnsnames.ora所在的目录
# CockroachDB : jdbc:postgresql://:/?=&=...
# DB2* : jdbc:db2://:/
# Derby : jdbc:derby::<;attribute=value>
# H2 : jdbc:h2:
# HSQLDB : jdbc:hsqldb:file:
# MariaDB : jdbc:mariadb://:/?=&=...
# MySQL : jdbc:mysql://:/?=&=...
# Oracle* : jdbc:oracle:thin:@//:/
# Oracle* (TNS)** : jdbc:oracle:thin:@
# PostgreSQL : jdbc:postgresql://:/?=&=...
# SAP HANA* : jdbc:sap://:/?databaseName=
# SQL Server : jdbc:sqlserver::;databaseName=
# SQLite : jdbc:sqlite:
# Sybase ASE : jdbc:jtds:sybase://:/
#----------------------------------------------------------------
flyway.url=jdbc:oracle:thin:@127.0.0.1:1521:oanet
#----------------------------------------------------------------
# JDBC 驱动类的完全限定类名 (默认情况下是基于对 flyway.url 自动检测)
# flyway.driver=
#----------------------------------------------------------------
#----------------------------------------------------------------
#用于连接数据库的用户名,如果没有指定,flyway会提示您输入它
#----------------------------------------------------------------
flyway.user=db
#----------------------------------------------------------------
#用于连接数据库的密码,如果没有指定,flyway会提示您输入它
#----------------------------------------------------------------
flyway.password=a
#----------------------------------------------------------------
# 由Flyway管理的以逗号分隔的模式列表。 这些模式名称区分大小写。
# (默认值:数据源连接的默认schemas), 登陆的账户必要有权限可以管理这些schemas
# 作用:
# - 列表中的第一个schemas将会在迁移期间自动设置为默认schemas
# - 列表中的第一个schemas也将是包含schemas历史表的schemas。
# - 将按此列表的顺序清除schemas。
# flyway.schemas=
#----------------------------------------------------------------
#----------------------------------------------------------------
# Flyway版本信息表的表名 (缺省值: flyway_schema_history)
# 默认情况下(单schemas模式) ,版本信息表将会存放在默认数据源提供的连接的默认schemas中
# When the flyway.schemas property is set (multi-schema mode), the schema history table is placed in the first schema of the list.
# 多schemas模式下,历史表将会存放在列表中的第一个schemas
# flyway.table=
#----------------------------------------------------------------
#----------------------------------------------------------------
# 逗号分隔的存放SQL或程序的文件位置,用于递归扫描文件. (缺省值: filesystem:<>/sql)
# 位置类型由前缀决定.
# 没有前缀或者以classpath:开头的文件 指向类路径上的包并且可能包含基于sql和java的迁移.
# #以filesystem开头的位置:指向文件系统上的目录,可能只包含sql迁移。
# flyway.locations=
#----------------------------------------------------------------
#----------------------------------------------------------------
# 用逗号分隔的自定义MigrationResolver完全限定类名列表,用于解析迁移任务
# flyway.resolvers=
#----------------------------------------------------------------
#----------------------------------------------------------------
# 如果设置为true,则跳过默认的内置解析器(jdbc,spring-jdbc和sql),并仅用自定义的解析器
# 通过 'flyway.resolvers' 定义解析器. (缺省值: false)
# flyway.skipDefaultResolvers=
#----------------------------------------------------------------
#----------------------------------------------------------------
# 逗号分隔的基于JAVA代码迁移的目录列表,此目录用于存放含有迁移代码的jar包 (缺省值: /jars)
# flyway.jarDirs=
#----------------------------------------------------------------
#----------------------------------------------------------------
# 版本迁移SQL文件的前缀 (缺省值: V)
# 文件结构示例 : V1_1__My_description.sql
# flyway.sqlMigrationPrefix=
#----------------------------------------------------------------
#----------------------------------------------------------------
# 版本回滚SQL文件的前缀. (缺省值: U)
# 版本回滚SQL迁移负责撤消使用相同版本的版本化迁移的影响。
# 文件结构示例 : U1_1__My_description.sql
# Flyway Pro 和 Flyway Enterprise 的功能
# flyway.undoSqlMigrationPrefix=
#----------------------------------------------------------------
#----------------------------------------------------------------
# 可重复执行的SQL文件的前缀 (缺省值: R)
# 每当由新版本可以迁移,就会执行此类文件 ,
# 文件结构示例 : R__My_description.sql
# flyway.repeatableSqlMigrationPrefix=
#----------------------------------------------------------------
#----------------------------------------------------------------
# 文件名分隔符 (缺省值: __),
# 使用默认的分隔符 : V1_1__My_description.sql
# flyway.sqlMigrationSeparator=
#----------------------------------------------------------------
#----------------------------------------------------------------
# 以逗号分隔的迁移文件的后缀名列表 (缺省值: .sql)
# 使用实例 V1_1__My_description.sql
# 多后缀名模式 (比如 .sql,.pkg,.pkb) 可以指定以便与其他工具(例如具有特定文件关联的编辑器)更容易兼容。
# flyway.sqlMigrationSuffixes=
#----------------------------------------------------------------
#----------------------------------------------------------------
# 文件编码 (缺省值: UTF-8)
# flyway.encoding=
#----------------------------------------------------------------
#----------------------------------------------------------------
# 是否自动替换占位符 (缺省值: true)
#----------------------------------------------------------------
flyway.placeholderReplacement=false
#----------------------------------------------------------------
# 要替换的占位符
# flyway.placeholders.user=
# flyway.placeholders.my_other_placeholder=
#----------------------------------------------------------------
#----------------------------------------------------------------
# 占位符前缀(缺省值: ${ )
# flyway.placeholderPrefix=
# 占位符后缀 (缺省值: } )
# flyway.placeholderSuffix=
#----------------------------------------------------------------
#----------------------------------------------------------------
# 指定schems 要执行的版本
# 特殊值'current' 指定schems的当前版本. (缺省值: <>)
# flyway.target=
#----------------------------------------------------------------
#----------------------------------------------------------------
# 是否在运行迁移时自动调用validate (缺省值: true)
# flyway.validateOnMigrate=
#----------------------------------------------------------------
#----------------------------------------------------------------
# 在发生验证错误时是否自动调用clean. (缺省值: false)
# 警告:仅能用于开发环境,生产环境禁止使用自动clean!!!
# flyway.cleanOnValidationError=
#----------------------------------------------------------------
#----------------------------------------------------------------
# 是否开启clean功能. (缺省值: false)
# 适用于生产环境,防止误操作导致删库的风险
# flyway.cleanDisabled=
#----------------------------------------------------------------
#----------------------------------------------------------------
# 版本标志,在执行baseline时候的起始版本. (缺省值: 1)
# flyway.baselineVersion=
#----------------------------------------------------------------
#----------------------------------------------------------------
# baseline的描述,在执行baseline时候添加的描述. (缺省值: << Flyway Baseline >>)
# flyway.baselineDescription=
#----------------------------------------------------------------
#----------------------------------------------------------------
# 当前schema的版本记录表为空的时候是否自动执行baseline操作
# 当前schema 在执行迁移操作前将会初始化 baselineVersion.
# 只会应用高于baselineVersion的迁移。.
# 这对于具有现有数据库的项目的初始Flyway生产部署非常有用。
# 如果配置错误,Flyway不会迁移错误的数据库!! (缺省值: false)
flyway.baselineOnMigrate=true
#----------------------------------------------------------------
#----------------------------------------------------------------
# 允许迁移时候程序执行 "out of order" (缺省值: false).
# 如果你已经应用了版本1和版本3,现在有了版本2,
# 那么这个版本将会被应用,而不是被忽略
# flyway.outOfOrder=
#----------------------------------------------------------------
#----------------------------------------------------------------
# 这允许您将自定义代码和逻辑与Flyway生命周期通知联系起来 (缺省值: empty).
# 设置用逗号分隔的完全限定类名,这些类需要实现 FlywayCallback
# flyway.callbacks=
#----------------------------------------------------------------
#----------------------------------------------------------------
# 如果此项设置为true ,将会跳过flyway内置的回调方法
# 转而使用 flyway.callbacks 所定义的方法 (缺省值: false)
# flyway.skipDefaultCallbacks=
#----------------------------------------------------------------
#----------------------------------------------------------------
# 在获取版本列表的时候忽略缺失的迁移SQL/程序. 这些缺失的迁移SQL/程序一般是当前版本不再提供旧程序部署执行的.
# 例子: we have migrations
# available on the classpath with versions 1.0 and 3.0. The schema history table indicates that a migration with version 2.0
# (unknown to us) has also been applied. Instead of bombing out (fail fast) with an exception, a
# warning is logged and Flyway continues normally. This is useful for situations where one must be able to deploy
# a newer version of the application even though it doesn't contain migrations included with an older one anymore.
# Note that if the most recently applied migration is removed, Flyway has no way to know it is missing and will
# mark it as future instead.
# true to continue normally and log a warning, false to fail fast with an exception. (缺省值: false)
# flyway.ignoreMissingMigrations=
#----------------------------------------------------------------
# Ignore future migrations when reading the schema history table. These are migrations that were performed by a
# newer deployment of the application that are not yet available in this version. For example: we have migrations
# available on the classpath up to version 3.0. The schema history table indicates that a migration to version 4.0
# (unknown to us) has already been applied. Instead of bombing out (fail fast) with an exception, a
# warning is logged and Flyway continues normally. This is useful for situations where one must be able to redeploy
# an older version of the application after the database has been migrated by a newer one.
# true to continue normally and log a warning, false to fail fast with an exception. (缺省值: true)
# flyway.ignoreFutureMigrations=
# Whether to allow mixing transactional and non-transactional statements within the same migration.
# true if mixed migrations should be allowed. false if an error should be thrown instead. (缺省值: false)
# flyway.mixed=
# Whether to group all pending migrations together in the same transaction when applying them (only recommended for databases with support for DDL transactions).
# true if migrations should be grouped. false if they should be applied individually instead. (缺省值: false)
# flyway.group=
# The username that will be recorded in the schema history table as having applied the migration.
# <> for the current database user of the connection. (缺省值: <>).
# flyway.installedBy=
# Comma-separated list of the fully qualified class names of handlers for errors and warnings that occur during a
# migration. This can be used to customize Flyway's behavior by for example
# throwing another runtime exception, outputting a warning or suppressing the error instead of throwing a FlywayException.
# ErrorHandlers are invoked in order until one reports to have successfully handled the errors or warnings.
# If none do, or if none are present, Flyway falls back to its 缺省值 handling of errors and warnings.
# <> to use the 缺省值 internal handler (缺省值: <>)
# Flyway Pro and Flyway Enterprise only
# flyway.errorHandlers=
# The file where to output the SQL statements of a migration dry run. If the file specified is in a non-existent
# directory, Flyway will create all directories and parent directories as needed.
# <> to execute the SQL statements directly against the database. (缺省值: <>)
# Flyway Pro and Flyway Enterprise only
# flyway.dryRunOutput=