录音知识整理
网上的文章又老又旧,不是从事相关工作的专业人士看了都是一头雾水,自己整理下,希望能帮到一些朋友。话不多说,走你!
1、 音频开发的具体内容有哪些?
(1)音频采集/播放
(2)音频算法处理(去噪、静音检测、回声消除、音效处理、功放/增强、混音/分离,等等)
(3)音频的编解码和格式转换
(4)音频传输协议的开发(SIP,A2DP、AVRCP,等等)
2、声音数字化过程
声源 -> mic-> ADC(模-数转换器) ,采样、量化 -> [可选项] 过滤、音效等特殊化处理 -> 编码 ->
a、首先,音频采集设备(比如Microphone)捕获声音信息,初始数据是模拟信号
b、模拟信号通过模-数转换器(ADC)处理成计算机能接受的二进制数据
c、上一步得到的数据根据需求进行必要的渲染处理,比如音效调整、过滤等等
d、 处理后的音频数据理论上已经可以存储到计算机设备中了,比如硬盘、USB设备等等。不过由于这时的音频数据体积相对庞大,不利于保存和传输,通常还会对其进行压缩处理。比如我们常见的mp3音乐,实际上就是对原始数据采用相应的压缩算法后得到的。压缩过程根据采样率、位深等因素的不同,最终得到的音频文件可能会有一定程度的失真
3、音频采样
前面我们说过,数字音频系统需要将声波波形信号通过ADC转换成计算机支持的二进制,进而保存成音频文件,这一过程叫做音频采样(Audio Sampling)。音频采样是众多数字信号处理的一种,它们的基本原理都是类似的(比如视频的采样和音频采样本质上也没有太大区别)。
可想而知,采样(Sampling)的核心是把连续的模拟信号转换成离散的数字信号。它涉及到如下几点:
l 样本(Sample)
这是我们进行采样的初始资料,比如一段连续的声音波形
l 采样器(Sampler)
采样器是将样本转换成终态信号的关键。它可以是一个子系统,也可以指一个操作过程,甚至是一个算法,取决于不同的信号处理场景。理想的采样器要求尽可能不产生信号失真
l 量化(Quantization)
采样后的值还需要通过量化,也就是将连续值近似为某个范围内有限多个离散值的处理过程。因为原始数据是模拟的连续信号,而数字信号则是离散的,它的表达范围是有限的,所以量化是必不可少的一个步骤
l 编码(Coding)
计算机的世界里,所有数值都是用二进制表示的,因而我们还需要把量化值进行二进制编码。这一步通常与量化同时进行
整个流程如下图所示PCM流程:
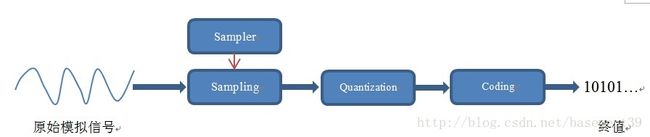
PCM(Pulse-code modulation)俗称脉冲编码调制,是将模拟信号数字化的一种经典方式,得到了非常广泛的应用。比如数字音频在计算机、DVD以及数字电话等系统中的标准格式采用的就是PCM。它的基本原理就是我们上面的几个流程,即对原始模拟信号进行抽样、量化和编码,从而产生PCM流。另外,我们可以调整PCM的以下属性来达到不同的采样需求:
l 采样率(Sampling Rate)
在将连续信号转化成离散信号时,就涉及到采样周期的选择。如果采样周期太长,虽然文件大小得到控制,但采样后得到的信息很可能无法准确表达原始信息;反之,如果采样的频率过快,则最终产生的数据量会大幅增加,这两种情况都是我们不愿意看到的,因而需要根据实际情况来选择合适的采样速率。
由于人耳所能辨识的声音范围是20-20KHZ,所以人们一般都选用44.1KHZ(CD)、48KHZ或者96KHZ来做为采样速率
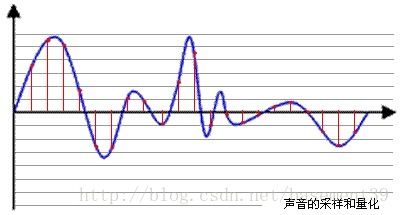
l 采样深度(Bit Depth也叫量化精度)
下图中的每一个红色点,都有一个数值来表示其大小,这个数值的数据类型有:4bit、8bit、16bit、32bit等,位数越多,表示得就越精细,声音质量也就越好。
l 通道数
一般表示声音录制时的音源数量或回放时相应的扬声器数量。单声道(Mono)和双声道(Stereo)比较常见。
l 音频帧(frame)
音频数据是流式的,本身并没有明确的一帧帧的概念,在实际的应用中,为了音频算法处理/传输的方便,一般约定俗成取 2.5 ms ~ 60 ms为单位的数据量为一帧音频。 这个时间被称之为“采样时间”,其长度没有特别的标准。我们可以计算一下一帧音频帧的大小:假设某通道的音频信号是采样率为 8 kHz,位宽为16 bit,20 ms 一帧,双通道,则一帧音频数据的大小为:
int size = 8000 x 16bit x 0.02s x 2 = 5120 bit = 640 byte
3、采样率和比特率
音频中叫采样率,是指把音频信号数字化(AD采样)后一个通道1秒钟有多少个样本,对应而来的就是原始的数据。如44.1kHz的采样率,就是指1个通道1秒钟有44.1k个数据,这数据可以是16位,也可以是24或者其他,这就是采样精度。
码率就是音频文件或者音频流中1秒中的数据量,如1.44Mbps,就是1秒钟内的数据量达1.44Mbits。
原始的音频数据和实际传输的音频流的大小一般不一致,是因为存在压缩算法这东东。压缩后的音频流一般是固定比特率,这样有利于稳定地传输。也可能是可变比特率,同样大小的文件能取得更好的压缩效果。 CD音质,一般2通道,原始音频数据1秒钟的数据量是44.1k*16*2=1411.2kbits, 压缩成128kbps的MP3,1秒钟数据就变成了128kbits了。丢了少许一般人耳或者设备还原不了的细节,节省了大量的磁盘空间或带宽。
比如说:一段音频大小为10MB左右,时长为4分钟,请问它的比特率是多少?
比特率的单位kbps即每秒多少千位的二进制码.10MB中的B是byte即字节.1byte=8bit(比特),1M=1024K所以有:10*1204*8/4*60=341kbps
4、数据格式和文件格式
数据格式(也叫音频编码)
模拟的音频信号转换为数字信号需要经过采样和量化,量化的过程被称之为编码,根据不同的量化策略,产生了许多不同的编码方式,常见的编码方式有:PCM 和 ADPCM,这些数据代表着无损的原始数字音频信号,添加一些文件头信息,就可以存储为WAV文件了,它是一种由微软和IBM联合开发的用于音频数字存储的标准,可以很容易地被解析和播放。
文件格式(也叫音频容器)
l 不压缩的格式(UnCompressed Audio Format)
比如前面所提到的PCM数据,就是采样后得到的未经压缩的数据。PCM数据在Windows和Mac系统上通常分别以wav和aiff后缀进行存储。可想而知,这样的文件大小是比较可观的
l 无损压缩格式(Lossless Compressed Audio Format)
这种压缩的前提是不破坏音频信息,也就是说后期可以完整还原出原始数据。同时它在一定程度上可以减小文件体积。比如FLAC、APE(Monkey’sAudio)、WV(WavPack)、m4a(Apple Lossless)等等
l 有损压缩格式(Lossy Compressed Audio Format)
无损压缩技术能减小的文件体积相对有限,因而在满足一定音质要求的情况下,我们还可以进行有损压缩。其中最为人熟知的当然是mp3格式,另外还有iTunes上使用的AAC,这些格式通常可以指定压缩的比率——比率越大,文件体积越小,但效果也越差。
可能还比较蒙,简单来说,PCM和MP3都是数据格式,只是PCM比较特殊,他是没有经过压缩处理的编码方式,而wav这些是文件格式,PCM编码可以是wav,MP3也可以是wav,他只是个容器。
5、Android提供了哪些音频开发相关的API?
音频采集:MediaRecoder,AudioRecord
音频播放:SoundPool,MediaPlayer,AudioTrack
音频编解码:MediaCodec
NDK API: OpenSL ES
在 Android 开发中,官方 SDK 提供了两套音频录制的 API,一个是 MediaRecorder ,另一个是 AudioRecord。前者会对录入的音频数据进行编码压缩(如 AMR,3GP等), 而后者是更加偏向底层的 API,录入的是一帧帧 的 PCM 音频数据,是无损没有经过压缩的。如果你对音频格式没有特殊的要求,只是简单的想做一个录音功能,那推荐你使用 MediaRecorder 。MediaRecorder 支持的输出方式有:amr_nb,amr_wb, default, mpeg_4, raw_amr, three_gpp。如果需要对音频数据进行额外的算法处理,则建议使用更加灵活的 AudioRecord API。比如,我想要录制一个 MP3 格式的音频文件, Android SDK 本身是不支持直接录制 MP3 格式的文件,我们就可以通过 AudioRecord 来采集音频数据,并通过第三方库来进行编码。
2、音频算法处理的开源库有哪些 ?
对每个音频文件有两部分:1是文件格式(也叫音频容器),2是数据格式(也叫音频编码)。
https://yq.aliyun.com/articles/8637
http://blog.csdn.net/luogaoyun521/article/details/18311047
http://blog.csdn.net/xjbclz/article/details/51884329
http://blog.csdn.net/houqi1993/article/details/50504045