Flume(10)数据流的复制、分流、负载均衡、故障转移
一、在前面几篇文章中介绍过几种常见的flume pipeline 场景。我们在回顾一下,主要有一下几种:
1、多个 agent 顺序连接:
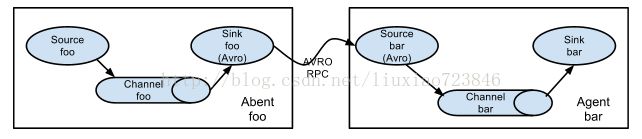
可以将多个Agent顺序连接起来,将最初的数据源经过收集,存储到最终的存储系统中。这是最简单的情况,一般情况下,应该控制这种顺序连接的Agent的数量,因为数据流经的路径变长了,如果不考虑failover的话,出现故障将影响整个Flow上的Agent收集服务。
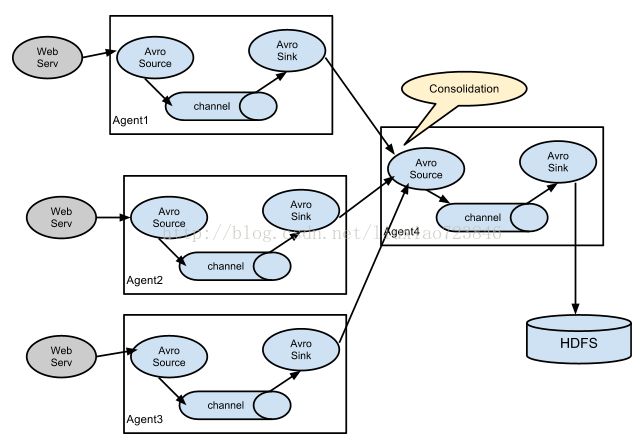
2、多个agent的数据汇聚到一个agent:
3、flume channel selectors功能:
flume channel selectors允许给一个source可以配置多个channel的能力。这种模式有两种方式,一种是用来复制(Replication),另一种是用来分流(Multiplexing)。
Replication方式
可以将最前端的数据源复制多份,分别传递到多个channel中,每个channel接收到的数据都是相同的。
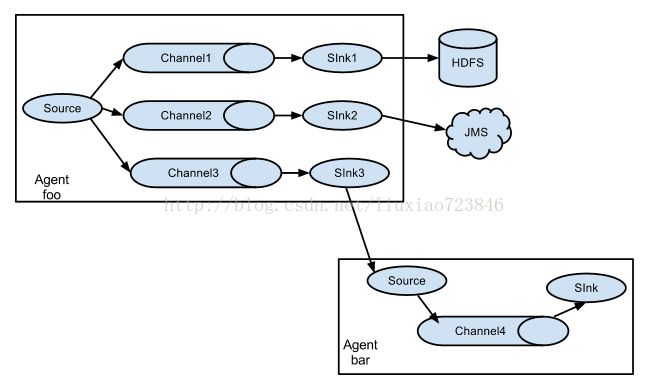
配置格式示例如下:
# List the sources, sinks and channels for the agent
.sources =
.sinks =
.channels =
# set list of channels for source (separated by space)
.sources..channels =
# set channel for sinks
.sinks..channel =
.sinks..channel =
.sources..selector.type = replicating
上面指定了selector的type的值为replication(没有制定时默认的方式),Source1会将数据分别存储到Channel1和Channel2,这两个channel里面存储的数据是相同的,然后数据被传递到Sink1和Sink2。
注:还有个配置 selector.optional,如下配置,表示channel1是optional的channel,如果想channel1写入失败,则会被忽略,channel2没有被比较optional,如果想channel2写入失败则会导致整个事件失败。
# set list of channels for source (separated by space)
.sources..channels =
.sources..selector.optional=
Multiplexing方式
selector可以根据header的值来确定数据传递到哪一个channel,配置格式,如下所示:
# Mapping for multiplexing selector
.sources..selector.type = multiplexing
.sources..selector.header =
.sources..selector.mapping. =
.sources..selector.mapping. =
.sources..selector.mapping. =
#...
.sources..selector.default =
上面selector的type的值为multiplexing,同时配置selector的header信息,还配置了多个selector的mapping的值,即header的值:如果header的值为Value1、Value2,数据从Source1路由到Channel1;如果header的值为Value2、Value3,数据从Source1路由到Channel2。
注:如果只配置了一个channel,多个sink,那么只有一个固定的sink可以获取到channel的数据。
Custom Channel Selector方式
自定义通道选择器需要实现ChannelSelector接口。 启动Flume代理时,自定义通道选择器的类及其依赖项必须包含在代理程序的类路径中。 自定义通道选择器的类型是其FQCN。
| Property Name | Default | Description |
|---|---|---|
| selector.type | – | The component type name, needs to be your FQCN |
Example for agent named a1 and its source called r1:
a1.sources = r1
a1.channels = c1
a1.sources.r1.selector.type = org.example.MyChannelSelector
4、flume sink processors功能:
Sink Processors,顾名思义,就是沉槽处理器,也就是数据向哪里流,怎么流由处理器控制。以sinkgroup的形式出现。简单的说就是一个source 对应一个Sinkgroups,即多个sink, 其实与selector情况差不多,只是processor考虑更多的是可靠性和性能,即故障转移与负载均衡的设置。 SinkGroup允许组织多个sink到一个实体上。SinkProcessors 能够提供在组内所有sink之间实现负载均衡的能力(配置load_balance)。而且在失败的情况下能够进行故障转移,从一个Sink到另一个Sink(配置failover )。
1)负载均衡
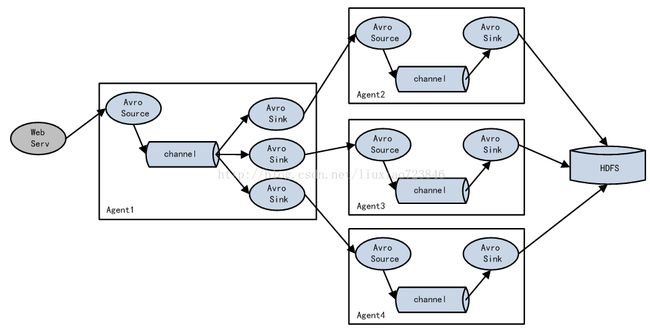
Load balancing Sink Processor
能够实现load balance功能,上图Agent1是一个路由节点,负责将Channel暂存的Event均衡到对应的多个Sink组件上,而每个Sink组件分别连接到一个独立的Agent上,示例配置,如下所示:
a1.sinkgroups = g1
a1.sinkgroups.g1.sinks = k1 k2 k3
a1.sinkgroups.g1.processor.type = load_balance
a1.sinkgroups.g1.processor.backoff = true #健康检查
a1.sinkgroups.g1.processor.selector = round_robin #random两种选择方式
a1.sinkgroups.g1.processor.selector.maxTimeOut=10000
它维护一个可用sink索引,它支持通过round_robin和random两种方法进行负载分配,默认的选择方式是round_type类型的,也可以通过配置文件进行更改。当被选择器被调用的时候,它不会屏蔽故障的sink,继续尝试访问每一个可用的sink,如果所有的sink都故障了,选择器则无法给sink传播数据。如果backoff被开启,则sink processor会屏蔽故障的sink,选择器会在一个给定的超时时间内移除它们,当超时时间完毕后,sink还是无法访问,则超时时间以指数方式增长。
2)实现failover
Failover Sink Processor能够实现failover功能,具体流程类似load balance,但是内部处理机制与load balance完全不同:Failover Sink Processor维护一个优先级Sink组件列表,只要有一个Sink组件可用,Event就被传递到下一个组件。如果一个Sink能够成功处理Event,则会加入到一个Pool中,否则会被移出Pool并计算失败次数,设置一个惩罚因子,示例配置如下所示:
a1.sinkgroups = g1
a1.sinkgroups.g1.sinks = k1 k2 k3
a1.sinkgroups.g1.processor.type = failover
a1.sinkgroups.g1.processor.priority.k1 = 5
a1.sinkgroups.g1.processor.priority.k2 = 7
a1.sinkgroups.g1.processor.priority.k3 = 6
a1.sinkgroups.g1.processor.maxpenalty = 20000 #故障转移时间
二、flume设置多个数据源:
a1.sources = r1 r2 r3
a1.sinks = k1
a1.channels = c1
#source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /application/flume/logs/access.log
a1.sources.r1.channels = c1
a1.sources.r2.type = exec
a1.sources.r2.command = tail -F /application/flume/logs/uqc_head.log
a1.sources.r2.channels = c1
a1.sources.r3.type = exec
a1.sources.r3.command = tail -F /application/flume/logs/uqc_tail.log
a1.sources.r3.channels = c1
# channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# sink
a1.sinks.k1.type = logger
a1.sinks.k1.channel = c1
上面配置,在同一个flume进程中,会有多个source数据会流入到一个channel中。通常,我们不会这么干,会采用上面第二种思路(多个agent汇总到一个agent那种思路)。