fullnat介绍
相比普通的 nat, 大部分公司都使用 fullnat, 对网段没有任何要求,也不需要配置路由。
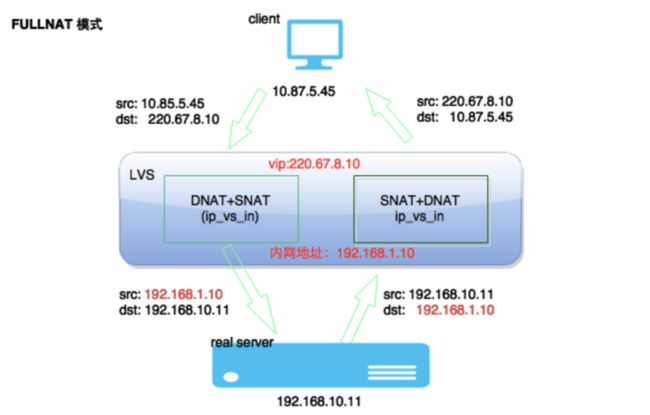
原理是在流量进入和返回时都做 dnat 和 snat. 而且 fullnat 性能扩展性非常好。如图所示,rs 是看不到真正 client ip 的,所有的请求都来自 lb. 这是 fullnat 缺点,通过安装 toa 模块来解决。
synproxy介绍
DDOS 攻击常见的就是 syn flood, 利用三次握手原理,只发送 syn 包,这时内核协义栈就会分配本地内存,当海量攻击流量生成时无法处理正常流量。也就是说如果能在第一次握手时挡住攻击流量就可以。
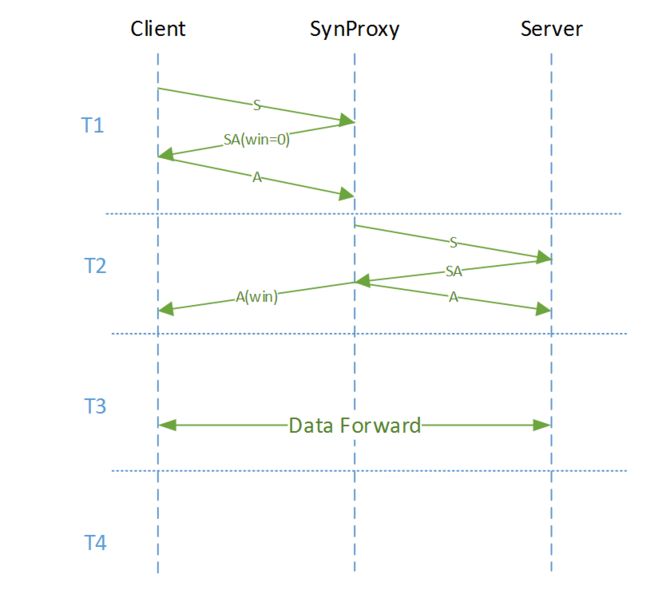
如上图所示,syn proxy 正常请求有四个阶段:
- client 发送 syn, LB 代理了第一次握次,不转发给 rs. LB 返回 ack 包时,seq 由 syn cookie 算法生成,并且将 win 设置为 0,不允许在握手阶段携带数据。由此得知不支持 tcp fast open
- 当 client 返回 ack 时,反解 seq, 如果和 cookie 算法匹配,那么就是正常流量。此时 LB 与后端 rs 开启三次所握手,并透传 win size. 由于经过 LB 代理,还需要记录 seq 差值 delta
- 数据交互通信,lb 除了正常的 full-nat 工作,还要补偿 seq delta
- 连接关闭,正常清理
ipv4_rcv 接收 client syn 请求
前文说到 ipv4_rcv 接收请求,最后调用 hook
INET_HOOK(INET_HOOK_PRE_ROUTING, mbuf, port, NULL, ipv4_rcv_fin)
int INET_HOOK(unsigned int hook, struct rte_mbuf *mbuf,
struct netif_port *in, struct netif_port *out,
int (*okfn)(struct rte_mbuf *mbuf))
{
struct list_head *hook_list;
struct inet_hook_ops *ops;
struct inet_hook_state state;
int verdict = INET_ACCEPT;
state.hook = hook;
hook_list = &inet_hooks[hook];
#ifdef CONFIG_DPVS_IPV4_INET_HOOK
rte_rwlock_read_lock(&inet_hook_lock);
#endif
ops = list_entry(hook_list, struct inet_hook_ops, list);
if (!list_empty(hook_list)) {
verdict = INET_ACCEPT;
list_for_each_entry_continue(ops, hook_list, list) {
repeat:
verdict = ops->hook(ops->priv, mbuf, &state);
if (verdict != INET_ACCEPT) {
if (verdict == INET_REPEAT)
goto repeat;
break;
}
}
}
#ifdef CONFIG_DPVS_IPV4_INET_HOOK
rte_rwlock_read_unlock(&inet_hook_lock);
#endif
if (verdict == INET_ACCEPT || verdict == INET_STOP) {
return okfn(mbuf);
} else if (verdict == INET_DROP) {
rte_pktmbuf_free(mbuf);
return EDPVS_DROP;
} else { /* INET_STOLEN */ // 比如 synproxy 第一步处理
return EDPVS_OK;
}
}
这个 HOOK 会执行 INET_HOOK_PRE_ROUTING 注册的回调函数:dp_vs_pre_routing 和 dp_vs_in, 但不是所有情况都会全部执行。当新连接请求时,dp_vs_pre_routing 会返回 INET_STOLEN,也就是说 dp_vs_in 并不会执行,并且 INET_HOOK 传入的回调函数 ipv4_rcv_fin 也不会执行。
static int dp_vs_pre_routing(void *priv, struct rte_mbuf *mbuf,
const struct inet_hook_state *state)
{
...
/* Synproxy: defence synflood */
if (IPPROTO_TCP == iph.proto) {
int v = INET_ACCEPT;
if (0 == dp_vs_synproxy_syn_rcv(af, mbuf, &iph, &v))
return v;
}
return INET_ACCEPT;
}
这是 dp_vs_pre_routing 函数体,忽略上半部份,直接看 dp_vs_synproxy_syn_rcv 的实现
int dp_vs_synproxy_syn_rcv(int af, struct rte_mbuf *mbuf,
const struct dp_vs_iphdr *iph, int *verdict)
{
int ret;
struct dp_vs_service *svc = NULL;
struct tcphdr *th, _tcph;
struct dp_vs_synproxy_opt tcp_opt;
struct netif_port *dev;
struct ether_hdr *eth;
struct ether_addr ethaddr;
th = mbuf_header_pointer(mbuf, iph->len, sizeof(_tcph), &_tcph);
if (unlikely(NULL == th))
goto syn_rcv_out;
// 第一次握手只有 syn 包,并有访问的 svc 开启了 syn proxy防护
if (th->syn && !th->ack && !th->rst && !th->fin &&
(svc = dp_vs_service_lookup(af, iph->proto,
&iph->daddr, th->dest, 0, NULL, NULL)) &&
(svc->flags & DP_VS_SVC_F_SYNPROXY)) {
/* if service's weight is zero (non-active realserver),
* do noting and drop the packet */
// 如果后端服务 svc 权重为 0 ,那么也没可用后端
if (svc->weight == 0) {
dp_vs_estats_inc(SYNPROXY_NO_DEST);
dp_vs_service_put(svc);
goto syn_rcv_out;
}
dp_vs_service_put(svc);
/* drop packet from blacklist */ // 如果在黑名单里,那么退出
if (dp_vs_blklst_lookup(iph->proto, &iph->daddr, th->dest, &iph->saddr)) {
goto syn_rcv_out;
}
} else {
if (svc)
dp_vs_service_put(svc);
return 1;
}
/* mbuf will be reused and ether header will be set.
* FIXME: to support non-ether packets. */
if (mbuf->l2_len != sizeof(struct ether_hdr))
goto syn_rcv_out;
/* update statistics */
dp_vs_estats_inc(SYNPROXY_SYN_CNT);
/* set tx offload flags */
assert(mbuf->port <= NETIF_MAX_PORTS);
dev = netif_port_get(mbuf->port);
if (unlikely(!dev)) {
RTE_LOG(ERR, IPVS, "%s: device eth%d not found\n",
__func__, mbuf->port);
goto syn_rcv_out;
}
if (likely(dev && (dev->flag & NETIF_PORT_FLAG_TX_TCP_CSUM_OFFLOAD)))
mbuf->ol_flags |= (PKT_TX_TCP_CKSUM | PKT_TX_IP_CKSUM | PKT_TX_IPV4);
/* reuse mbuf */
syn_proxy_reuse_mbuf(af, mbuf, &tcp_opt);
/* set L2 header and send the packet out
* It is noted that "ipv4_xmit" should not used here,
* because mbuf is reused. */
eth = (struct ether_hdr *)rte_pktmbuf_prepend(mbuf, mbuf->l2_len);
if (unlikely(!eth)) {
RTE_LOG(ERR, IPVS, "%s: no memory\n", __func__);
goto syn_rcv_out;
}
memcpy(ðaddr, ð->s_addr, sizeof(struct ether_addr));
memcpy(ð->s_addr, ð->d_addr, sizeof(struct ether_addr));
memcpy(ð->d_addr, ðaddr, sizeof(struct ether_addr));
if (unlikely(EDPVS_OK != (ret = netif_xmit(mbuf, dev)))) {
RTE_LOG(ERR, IPVS, "%s: netif_xmit failed -- %s\n",
__func__, dpvs_strerror(ret));
/* should not set verdict to INET_DROP since netif_xmit
* always consume the mbuf while INET_DROP means mbuf'll
* be free in INET_HOOK.*/
}
*verdict = INET_STOLEN;
return 0;
syn_rcv_out:
/* drop and destroy the packet */
*verdict = INET_DROP;
return 0;
}
- 判断第一次握手只有 syn 包,并且访问的后端服务 svc 开启了 syn proxy 防护。如果在黑名单那么退出,返回 INET_DROP
-
syn_proxy_reuse_mbuf复用 mbuf, 为什么说是复用呢?因为对 mbuf 修改后,直接当做回包返回给了 client,这个修改是重点 - 三个
memcpy操作是交换原来 mbuf 的目的地址和源地址,然后调用netif_xmit返回给了 client
来看一下 syn_proxy_reuse_mbuf 做了哪些事情?
static void syn_proxy_reuse_mbuf(int af, struct rte_mbuf *mbuf,
struct dp_vs_synproxy_opt *opt)
{
uint32_t isn;
uint32_t tmpaddr;
uint16_t tmpport;
struct iphdr *iph;
struct tcphdr *th;
int ip4hlen;
iph = (struct iphdr*)ip4_hdr(mbuf);
ip4hlen = ip4_hdrlen(mbuf);
th = tcp_hdr(mbuf);
if (mbuf_may_pull(mbuf, ip4hlen + (th->doff<< 2)) != 0)
return;
/* deal with tcp options */
syn_proxy_parse_set_opts(mbuf, th, opt);
/* get cookie */
isn = syn_proxy_cookie_v4_init_sequence(mbuf, opt);
/* set syn-ack flag */
((uint8_t *)th)[13] = 0x12;
/* exchage ports */
tmpport = th->dest;
th->dest = th->source;
th->source = tmpport;
/* set seq(cookie) and ack_seq */
th->ack_seq = htonl(ntohl(th->seq) + 1);
th->seq = htonl(isn);
/* exchage addresses */
tmpaddr = iph->saddr;
iph->saddr = iph->daddr;
iph->daddr = tmpaddr;
iph->ttl = dp_vs_synproxy_ctrl_synack_ttl;
iph->tos = 0;
/* compute checksum */
if (likely(mbuf->ol_flags & PKT_TX_TCP_CKSUM)) {
mbuf->l3_len = ip4hlen;
mbuf->l4_len = ntohs(ip4_hdr(mbuf)->total_length) - ip4hlen;
th->check = rte_ipv4_phdr_cksum(ip4_hdr(mbuf), mbuf->ol_flags);
} else {
if (mbuf_may_pull(mbuf, mbuf->pkt_len) != 0)
return;
tcp4_send_csum((struct ipv4_hdr*)iph, th);
}
if (likely(mbuf->ol_flags & PKT_TX_IP_CKSUM))
iph->check = 0;
else
ip4_send_csum((struct ipv4_hdr*)iph);
}
- 调用
syn_proxy_parse_set_opts设置 tcp option, 包括 mss, window size, timestamp - 调用
syn_proxy_cookie_v4_init_sequence计算生成 cookie,函数是secure_tcp_syn_cookie(iph->saddr, iph->daddr, th->source, th->dest, ntohl(th->seq), rte_atomic32_read(&g_minute_count), data); - 交换 dest, source 端口
- 设置 seq, 其中 ack seq 是客户端的序号加一,而返回的 syn seq 就是刚刚计算出来的 cookie
- 交换源和目地 ip 地址
- 如果硬件不支持计算 csum,调用
ip4_send_csum生成
ipv4_rcv 接收 client syn 请求小结:此时可以看到,lb 是不分配任务内存资源的,他将状态生成 cookie,保存到 syn seq 中。如果此时是攻击流量,那么 lb 基本没什么负担。分析到这第一阶段结束,dp_vs_pre_routing 返回 INET_STOLEN,INET_HOOK 直接返回,并不会执行 okfn 回调。
ipv4_rcv 接收 client ack 应答
如前文所述,HOOK 会执行 INET_HOOK_PRE_ROUTING 注册的回调函数:dp_vs_pre_routing 和 dp_vs_in,当 client 返回 ack 应答时,dp_vs_pre_routing 返回 DPVS_ACCEPT, 继续执行 dp_vs_in 逻辑。
首先,此时还没有建立连接,流表里并不存在。dp_vs_proto_lookup 查找协义,当前只看 dp_vs_proto_tcp. 由于 conn_lookup 查找不到流表,所以继续执行 tcp_conn_sched
static int tcp_conn_sched(struct dp_vs_proto *proto,
const struct dp_vs_iphdr *iph,
struct rte_mbuf *mbuf,
struct dp_vs_conn **conn,
int *verdict)
{
struct tcphdr *th, _tcph;
struct dp_vs_service *svc;
assert(proto && iph && mbuf && conn && verdict);
th = mbuf_header_pointer(mbuf, iph->len, sizeof(_tcph), &_tcph);
if (unlikely(!th)) {
*verdict = INET_DROP;
return EDPVS_INVPKT;
}
/* Syn-proxy step 2 logic: receive client's 3-handshacke ack packet */
/* When synproxy disabled, only SYN packets can arrive here.
* So don't judge SYNPROXY flag here! If SYNPROXY flag judged, and syn_proxy
* got disbled and keepalived reloaded, SYN packets for RS may never be sent. */
if (dp_vs_synproxy_ack_rcv(iph->af, mbuf, th, proto, conn, iph, verdict) == 0) {
/* Attention: First ACK packet is also stored in conn->ack_mbuf */
return EDPVS_PKTSTOLEN;
}
/* only TCP-SYN without other flag can be scheduled */
if (!th->syn || th->ack || th->fin || th->rst) {
#ifdef CONFIG_DPVS_IPVS_DEBUG
char dbuf[64], sbuf[64];
const char *daddr, *saddr;
daddr = inet_ntop(iph->af, &iph->daddr, dbuf, sizeof(dbuf)) ? dbuf : "::";
saddr = inet_ntop(iph->af, &iph->saddr, sbuf, sizeof(sbuf)) ? sbuf : "::";
RTE_LOG(DEBUG, IPVS,
"%s: [%d] try sched non-SYN packet: [%c%c%c%c] %s:%d->%s:%d\n",
__func__, rte_lcore_id(),
th->syn ? 'S' : '.', th->fin ? 'F' : '.',
th->ack ? 'A' : '.', th->rst ? 'R' : '.',
saddr, ntohs(th->source), daddr, ntohs(th->dest));
#endif
/* Drop tcp packet which is send to vip and !vport */
if (g_defence_tcp_drop &&
(svc = dp_vs_lookup_vip(iph->af, iph->proto, &iph->daddr))) {
dp_vs_estats_inc(DEFENCE_TCP_DROP);
*verdict = INET_DROP;
return EDPVS_INVPKT;
}
*verdict = INET_ACCEPT;
return EDPVS_INVAL;
}
svc = dp_vs_service_lookup(iph->af, iph->proto,
&iph->daddr, th->dest, 0, mbuf, NULL);
if (!svc) {
/* Drop tcp packet which is send to vip and !vport */
if (g_defence_tcp_drop &&
(svc = dp_vs_lookup_vip(iph->af, iph->proto, &iph->daddr))) {
dp_vs_estats_inc(DEFENCE_TCP_DROP);
*verdict = INET_DROP;
return EDPVS_INVPKT;
}
*verdict = INET_ACCEPT;
return EDPVS_NOSERV;
}
*conn = dp_vs_schedule(svc, iph, mbuf, false);
if (!*conn) {
dp_vs_service_put(svc);
*verdict = INET_DROP;
return EDPVS_RESOURCE;
}
dp_vs_service_put(svc);
return EDPVS_OK;
}
看注释,如果 dp_vs_synproxy_ack_rcv 执行成功,那么返回 EDPVS_PKTSTOLEN, 最终 dp_vs_in 也会返回 STOLEN. 再细看 dp_vs_synproxy_ack_rcv 源码
/* Syn-proxy step 2 logic: receive client's Ack
* Receive client's 3-handshakes ack packet, do cookie check and then
* send syn to rs after creating a session */
int dp_vs_synproxy_ack_rcv(int af, struct rte_mbuf *mbuf,
struct tcphdr *th, struct dp_vs_proto *pp,
struct dp_vs_conn **cpp,
const struct dp_vs_iphdr *iph, int *verdict)
{
int res;
struct dp_vs_synproxy_opt opt;
struct dp_vs_service *svc;
int res_cookie_check;
/* Do not check svc syn-proxy flag, as it may be changed after syn-proxy step 1. */
if (!th->syn && th->ack && !th->rst && !th->fin &&
(svc = dp_vs_service_lookup(af, iph->proto, &iph->daddr,
th->dest, 0, NULL, NULL))) {
if (dp_vs_synproxy_ctrl_defer &&
!syn_proxy_ack_has_data(mbuf, iph, th)) {
/* Update statistics */
dp_vs_estats_inc(SYNPROXY_NULL_ACK);
/* We get a pure ack when expecting ack packet with payload, so
* have to drop it */
dp_vs_service_put(svc);
*verdict = INET_DROP;
return 0;
}
res_cookie_check = syn_proxy_v4_cookie_check(mbuf, ntohl(th->ack_seq) - 1, &opt);
if (!res_cookie_check) {
/* Update statistics */
dp_vs_estats_inc(SYNPROXY_BAD_ACK);
/* Cookie check failed, drop the packet */
RTE_LOG(DEBUG, IPVS, "%s: syn_cookie check failed seq=%u\n", __func__,
ntohl(th->ack_seq) - 1);
dp_vs_service_put(svc);
*verdict = INET_DROP;
return 0;
}
/* Update statistics */
dp_vs_estats_inc(SYNPROXY_OK_ACK);
/* Let the virtual server select a real server for the incoming connetion,
* and create a connection entry */
*cpp = dp_vs_schedule(svc, iph, mbuf, 1);
if (unlikely(!*cpp)) {
RTE_LOG(WARNING, IPVS, "%s: ip_vs_schedule failed\n", __func__);
/* FIXME: What to do when virtual service is available but no destination
* available for a new connetion: send an icmp UNREACHABLE ? */
dp_vs_service_put(svc);
*verdict = INET_DROP;
return 0;
}
/* Release the service, we do not need it any more */
dp_vs_service_put(svc);
/* Do nothing but print a error msg when fail, because session will be
* correctly freed in dp_vs_conn_expire */
if (EDPVS_OK != (res = syn_proxy_send_rs_syn(af, th, *cpp, mbuf, pp, &opt))) {
RTE_LOG(ERR, IPVS, "%s: syn_proxy_send_rs_syn failed -- %s\n",
__func__, dpvs_strerror(res));
}
/* Count in the ack packet (STOLEN by synproxy) */
dp_vs_stats_in(*cpp, mbuf);
/* Active session timer, and dec refcnt.
* Also steal the mbuf, and let caller return immediately */
dp_vs_conn_put(*cpp);
*verdict = INET_STOLEN;
return 0;
}
return 1;
}
使用 syn_proxy_v4_cookie_check 反解 seq cookie, 如果不匹配,那么就是攻击或是无效流量,将包丢弃。如果成功,执行 syn proxy 第二阶段,lb 调用 dp_vs_schedule 与后端 real server 建立连接,这里也有细节。
/* select an RS by service's scheduler and create a connection */
struct dp_vs_conn *dp_vs_schedule(struct dp_vs_service *svc,
const struct dp_vs_iphdr *iph,
struct rte_mbuf *mbuf,
bool is_synproxy_on)
{
uint16_t _ports[2], *ports; /* sport, dport */
struct dp_vs_dest *dest;
struct dp_vs_conn *conn;
struct dp_vs_conn_param param;
struct sockaddr_in daddr, saddr;
int err;
assert(svc && iph && mbuf);
ports = mbuf_header_pointer(mbuf, iph->len, sizeof(_ports), _ports);
if (!ports)
return NULL;
/* persistent service 长连接请求*/
if (svc->flags & DP_VS_SVC_F_PERSISTENT)
return dp_vs_sched_persist(svc, iph, mbuf, is_synproxy_on);
dest = svc->scheduler->schedule(svc, mbuf); // 特定的调度算法
if (!dest) {
RTE_LOG(WARNING, IPVS, "%s: no dest found.\n", __func__);
#ifdef CONFIG_DPVS_MBUF_DEBUG
dp_vs_mbuf_dump("found dest failed.", iph->af, mbuf);
#endif
return NULL;
}
if (dest->fwdmode == DPVS_FWD_MODE_SNAT) {
if (unlikely(iph->proto == IPPROTO_ICMP)) {
struct icmphdr *ich, _icmph;
ich = mbuf_header_pointer(mbuf, iph->len, sizeof(_icmph), &_icmph);
if (!ich)
return NULL;
ports = _ports;
_ports[0] = icmp4_id(ich);
_ports[1] = ich->type << 8 | ich->code;
/* ID may confict for diff host,
* need we use ID pool ? */
dp_vs_conn_fill_param(iph->af, iph->proto,
&iph->daddr, &dest->addr,
ports[1], ports[0],
0, ¶m);
} else {
/* we cannot inherit dest (host's src port),
* that may confict for diff hosts,
* and using dest->port is worse choice. */
memset(&daddr, 0, sizeof(daddr));
daddr.sin_family = AF_INET;
daddr.sin_addr = iph->daddr.in;
daddr.sin_port = ports[1];
memset(&saddr, 0, sizeof(saddr));
saddr.sin_family = AF_INET;
saddr.sin_addr = dest->addr.in;
saddr.sin_port = 0;
err = sa_fetch(NULL, &daddr, &saddr);
if (err != 0) {
#ifdef CONFIG_DPVS_MBUF_DEBUG
dp_vs_mbuf_dump("sa_fetch failed.", iph->af, mbuf);
#endif
return NULL;
}
dp_vs_conn_fill_param(iph->af, iph->proto,
&iph->daddr, &dest->addr,
ports[1], saddr.sin_port,
0, ¶m);
}
} else {
if (unlikely(iph->proto == IPPROTO_ICMP)) {
struct icmphdr *ich, _icmph;
ich = mbuf_header_pointer(mbuf, iph->len, sizeof(_icmph), &_icmph);
if (!ich)
return NULL;
ports = _ports;
_ports[0] = icmp4_id(ich);
_ports[1] = ich->type << 8 | ich->code;
dp_vs_conn_fill_param(iph->af, iph->proto,
&iph->saddr, &iph->daddr,
ports[0], ports[1], 0, ¶m);
} else {
dp_vs_conn_fill_param(iph->af, iph->proto,
&iph->saddr, &iph->daddr,
ports[0], ports[1], 0, ¶m);
}
}
conn = dp_vs_conn_new(mbuf, ¶m, dest,
is_synproxy_on ? DPVS_CONN_F_SYNPROXY : 0);
if (!conn) {
if (dest->fwdmode == DPVS_FWD_MODE_SNAT && iph->proto != IPPROTO_ICMP)
sa_release(NULL, &daddr, &saddr);
#ifdef CONFIG_DPVS_MBUF_DEBUG
dp_vs_mbuf_dump("create conn failed.", iph->af, mbuf);
#endif
return NULL;
}
dp_vs_stats_conn(conn);
return conn;
}
根据服务调度算法,选择后端 real server, 就是源码里的 dest. 调用 dp_vs_conn_new 来与 dest 建立连接,这里涉及 syn proxy.
struct dp_vs_conn * dp_vs_conn_new(struct rte_mbuf *mbuf,
struct dp_vs_conn_param *param,
struct dp_vs_dest *dest, uint32_t flags)
{
struct dp_vs_conn *new;
struct conn_tuple_hash *t;
uint16_t rport;
__be16 _ports[2], *ports;
int err;
assert(mbuf && param && dest);
// 内存池,这很重要,malloc 分配内存很慢的,特别是大量的情况下
if (unlikely(rte_mempool_get(this_conn_cache, (void **)&new) != 0)) {
RTE_LOG(WARNING, IPVS, "%s: no memory\n", __func__);
return NULL;
}
memset(new, 0, sizeof(struct dp_vs_conn));
new->connpool = this_conn_cache;
/* set proper RS port */
if ((flags & DPVS_CONN_F_TEMPLATE) || param->ct_dport != 0)
rport = param->ct_dport;
else if (dest->fwdmode == DPVS_FWD_MODE_SNAT) {
if (unlikely(param->proto == IPPROTO_ICMP)) {
rport = param->vport;
} else {
ports = mbuf_header_pointer(mbuf, ip4_hdrlen(mbuf),
sizeof(_ports), _ports);
if (unlikely(!ports)) {
RTE_LOG(WARNING, IPVS, "%s: no memory\n", __func__);
goto errout;
}
rport = ports[0];
}
} else
rport = dest->port;
/* init inbound conn tuple hash */
t = &tuplehash_in(new);
t->direct = DPVS_CONN_DIR_INBOUND; // 入口流量,肯定是外网进来的
t->af = param->af;
t->proto = param->proto;
t->saddr = *param->caddr; // 源地址是 外网 client addr
t->sport = param->cport;
t->daddr = *param->vaddr; // 目地地址是 服务虚IP地址
t->dport = param->vport;
INIT_LIST_HEAD(&t->list);
/* init outbound conn tuple hash */
t = &tuplehash_out(new);
t->direct = DPVS_CONN_DIR_OUTBOUND; // 出口
t->af = param->af;
t->proto = param->proto;
if (dest->fwdmode == DPVS_FWD_MODE_SNAT)
t->saddr.in.s_addr = ip4_hdr(mbuf)->src_addr;
else
t->saddr = dest->addr;
t->sport = rport;
t->daddr = *param->caddr; /* non-FNAT */
t->dport = param->cport; /* non-FNAT */
INIT_LIST_HEAD(&t->list);
/* init connection */
new->af = param->af;
new->proto = param->proto;
new->caddr = *param->caddr;
new->cport = param->cport;
new->vaddr = *param->vaddr;
new->vport = param->vport;
new->laddr = *param->caddr; /* non-FNAT */
new->lport = param->cport; /* non-FNAT */
if (dest->fwdmode == DPVS_FWD_MODE_SNAT)
new->daddr.in.s_addr = ip4_hdr(mbuf)->src_addr;
else
new->daddr = dest->addr;
new->dport = rport;
/* neighbour confirm cache 邻居子系统*/
new->in_nexthop.in.s_addr = htonl(INADDR_ANY);
new->out_nexthop.in.s_addr = htonl(INADDR_ANY);
new->in_dev = NULL;
new->out_dev = NULL;
/* Controll member */
new->control = NULL;
rte_atomic32_clear(&new->n_control);
/* caller will use it right after created,
* just like dp_vs_conn_get(). */
rte_atomic32_set(&new->refcnt, 1);
new->flags = flags;
new->state = 0;
#ifdef CONFIG_DPVS_IPVS_STATS_DEBUG
new->ctime = rte_rdtsc();
#endif
/* bind destination and corresponding trasmitter */
// 在这里设置 转发模式相关的几个发包收包操作
err = conn_bind_dest(new, dest);
if (err != EDPVS_OK) {
RTE_LOG(WARNING, IPVS, "%s: fail to bind dest: %s\n",
__func__, dpvs_strerror(err));
goto errout;
}
/* FNAT only: select and bind local address/port */
if (dest->fwdmode == DPVS_FWD_MODE_FNAT) {
if ((err = dp_vs_laddr_bind(new, dest->svc)) != EDPVS_OK)
goto unbind_dest;
}
/* add to hash table (dual dir for each bucket) */
if ((err = conn_hash(new)) != EDPVS_OK)
goto unbind_laddr;
/* timer */
new->timeout.tv_sec = conn_init_timeout;
new->timeout.tv_usec = 0;
/* synproxy 用于 syn proxy 使用*/
INIT_LIST_HEAD(&new->ack_mbuf);
rte_atomic32_set(&new->syn_retry_max, 0);
rte_atomic32_set(&new->dup_ack_cnt, 0);
if ((flags & DPVS_CONN_F_SYNPROXY) && !(flags & DPVS_CONN_F_TEMPLATE)) {
struct tcphdr _tcph, *th;
struct dp_vs_synproxy_ack_pakcet *ack_mbuf;
struct dp_vs_proto *pp;
th = mbuf_header_pointer(mbuf, ip4_hdrlen(mbuf), sizeof(_tcph), &_tcph);
if (!th) {
RTE_LOG(ERR, IPVS, "%s: get tcphdr failed\n", __func__);
goto unbind_laddr;
}
/* save ack packet */
if (unlikely(rte_mempool_get(this_ack_mbufpool, (void **)&ack_mbuf) != 0)) {
RTE_LOG(ERR, IPVS, "%s: no memory\n", __func__);
goto unbind_laddr;
}
ack_mbuf->mbuf = mbuf;
list_add_tail(&ack_mbuf->list, &new->ack_mbuf);
new->ack_num++;
sp_dbg_stats32_inc(sp_ack_saved);
/* save ack_seq - 1 */
new->syn_proxy_seq.isn =
htonl((uint32_t) ((ntohl(th->ack_seq) - 1)));
/* save ack_seq */
new->fnat_seq.fdata_seq = htonl(th->ack_seq);
/* FIXME: use DP_VS_TCP_S_SYN_SENT for syn */
pp = dp_vs_proto_lookup(param->proto);
new->timeout.tv_sec = pp->timeout_table[new->state = DPVS_TCP_S_SYN_SENT];
}
this_conn_count++;
/* schedule conn timer */
dpvs_time_rand_delay(&new->timeout, 1000000);
if (new->flags & DPVS_CONN_F_TEMPLATE)
dpvs_timer_sched(&new->timer, &new->timeout, conn_expire, new, true);
else
dpvs_timer_sched(&new->timer, &new->timeout, conn_expire, new, false);
#ifdef CONFIG_DPVS_IPVS_DEBUG
conn_dump("new conn: ", new);
#endif
return new;
unbind_laddr:
dp_vs_laddr_unbind(new);
unbind_dest:
conn_unbind_dest(new);
errout:
rte_mempool_put(this_conn_cache, new);
return NULL;
}
- 调用
tuplehash_in生成两个方向的 tuplehash 用于检索 -
conn_bind_dest根据各个转发模式绑定回调
case DPVS_FWD_MODE_FNAT:
conn->packet_xmit = dp_vs_xmit_fnat;
conn->packet_out_xmit = dp_vs_out_xmit_fnat;
-
dp_vs_laddr_bind绑定 LB 本地 socket, 这个很好理解,fullnat 做了双向 nat -
conn_hash将连接加到流表 this_conn_tab 中 - 处理 synproxy, 将 mbuf 加到 ack_mbuf 列表。将 client 发来的 fnat_seq 保存到 fnat_seq,将 fnat_seq - 1 保存到 syn_proxy_seq
- 将连接加到 dpvs_timer_sched 超时控制。
再回到函数 dp_vs_synproxy_ack_rcv, 当 dp_vs_schedule 创建连接后,调用 syn_proxy_send_rs_syn 完成 lb 与 real server 建连。
static int syn_proxy_send_rs_syn(int af, const struct tcphdr *th,
struct dp_vs_conn *cp, struct rte_mbuf *mbuf,
struct dp_vs_proto *pp, struct dp_vs_synproxy_opt *opt)
{
int tcp_hdr_size;
struct rte_mbuf *syn_mbuf, *syn_mbuf_cloned;
struct rte_mempool *pool;
struct iphdr *ack_iph;
struct iphdr *syn_iph;
struct tcphdr *syn_th;
if (!cp->packet_xmit) {
RTE_LOG(WARNING, IPVS, "%s: packet_xmit is null\n", __func__);
return EDPVS_INVAL;
}
/* Allocate mbuf from device mempool */
pool = get_mbuf_pool(cp, DPVS_CONN_DIR_INBOUND);
if (unlikely(!pool)) {
//RTE_LOG(WARNING, IPVS, "%s: %s\n", __func__, dpvs_strerror(EDPVS_NOROUTE));
return EDPVS_NOROUTE;
}
syn_mbuf = rte_pktmbuf_alloc(pool);
if (unlikely(!syn_mbuf)) {
//RTE_LOG(WARNING, IPVS, "%s: %s\n", __func__, dpvs_strerror(EDPVS_NOMEM));
return EDPVS_NOMEM;
}
syn_mbuf->userdata = NULL; /* make sure "no route info" */
/* Reserve space for tcp header */
tcp_hdr_size = (sizeof(struct tcphdr) + TCPOLEN_MAXSEG
+ (opt->tstamp_ok ? TCPOLEN_TSTAMP_APPA : 0)
+ (opt->wscale_ok ? TCP_OLEN_WSCALE_ALIGNED : 0)
/* SACK_PERM is in the palce of NOP NOP of TS */
+ ((opt->sack_ok && !opt->tstamp_ok) ? TCP_OLEN_SACKPERMITTED_ALIGNED : 0));
syn_th = (struct tcphdr *)rte_pktmbuf_prepend(syn_mbuf, tcp_hdr_size);
if (!syn_th) {
rte_pktmbuf_free(syn_mbuf);
//RTE_LOG(WARNING, IPVS, "%s:%s\n", __func__, dpvs_strerror(EDPVS_NOROOM));
return EDPVS_NOROOM;
}
/* Set up tcp header */
memset(syn_th, 0, tcp_hdr_size);
syn_th->source = th->source;
syn_th->dest = th->dest;
syn_th->seq = htonl(ntohl(th->seq) - 1);
syn_th->ack_seq = 0;
*(((uint16_t *) syn_th) + 6) = htons(((tcp_hdr_size >> 2) << 12) | /*TH_SYN*/ 0x02);
/* FIXME: what window should we use */
syn_th->window = htons(5000);
syn_th->check = 0;
syn_th->urg_ptr = 0;
syn_th->urg = 0;
syn_proxy_syn_build_options((uint32_t *)(syn_th + 1), opt);
/* Reserve space for ipv4 header */
syn_iph = (struct iphdr *)rte_pktmbuf_prepend(syn_mbuf, sizeof(struct ipv4_hdr));
if (!syn_iph) {
rte_pktmbuf_free(syn_mbuf);
//RTE_LOG(WARNING, IPVS, "%s:%s\n", __func__, dpvs_strerror(EDPVS_NOROOM));
return EDPVS_NOROOM;
}
ack_iph = (struct iphdr *)ip4_hdr(mbuf);
*((uint16_t *) syn_iph) = htons((4 << 12) | (5 << 8) | (ack_iph->tos & 0x1E));
syn_iph->tot_len = htons(syn_mbuf->pkt_len);
syn_iph->frag_off = htons(IPV4_HDR_DF_FLAG);
syn_iph->ttl = 64;
syn_iph->protocol = IPPROTO_TCP;
syn_iph->saddr = ack_iph->saddr;
syn_iph->daddr = ack_iph->daddr;
/* checksum is done by fnat_in_handler */
syn_iph->check = 0;
/* Save syn_mbuf if syn retransmission is on */
if (dp_vs_synproxy_ctrl_syn_retry > 0) {
syn_mbuf_cloned = rte_pktmbuf_clone(syn_mbuf, pool);
if (unlikely(!syn_mbuf_cloned)) {
rte_pktmbuf_free(syn_mbuf);
//RTE_LOG(WARNING, IPVS, "%s:%s\n", __func__, dpvs_strerror(EDPVS_NOMEM));
return EDPVS_NOMEM;
}
syn_mbuf_cloned->userdata = NULL;
cp->syn_mbuf = syn_mbuf_cloned;
sp_dbg_stats32_inc(sp_syn_saved);
rte_atomic32_set(&cp->syn_retry_max, dp_vs_synproxy_ctrl_syn_retry);
}
/* Count in the syn packet */
dp_vs_stats_in(cp, mbuf);
/* If xmit failed, syn_mbuf will be freed correctly */
cp->packet_xmit(pp, cp, syn_mbuf);
return EDPVS_OK;
}
- 从内存池中分配 syn_mbuf,用于发送到后端 real server
- 借助 syn_th 填充 syn_mbuf 四层头: 源,目的端口,seq,window 等等
- 借助 syn_iph 填充 syn_mbuf 三层头: 源地址,目的地址等等
- 调用
packet_xmit发送 syn_mbuf 给 rs, 由前文conn_bind_dest可知最终调用dp_vs_xmit_fnat,其中最关键的就是调用tcp_fnat_in_handler
/*
* for SYN packet
* 1. remove tcp timestamp option
* laddress for different client have diff timestamp.
* 2. save original TCP sequence for seq-adjust later.
* since TCP option will be change.
* 3. add TOA option
* so that RS with TOA module can get real client IP.
*/
if (th->syn && !th->ack) {
tcp_in_remove_ts(th);
tcp_in_init_seq(conn, mbuf, th);
tcp_in_add_toa(conn, mbuf, th);
}
/* add toa to first data packet */
if (ntohl(th->ack_seq) == conn->fnat_seq.fdata_seq
&& !th->syn && !th->rst && !th->fin)
tcp_in_add_toa(conn, mbuf, th);
tcp_in_adjust_seq(conn, th);
/* L4 translation */
th->source = conn->lport;
th->dest = conn->dport;
- 如果是 syn 包,第一次和 rs 握手,要移除 tcp header 中的 ts, 初始化 seq,并且要记录 seq delta.
- 增加 toa 模块,这样后端 rs 就能拿到真正的 client ip port
- 对于正常己建立连接的数据包,
tcp_in_adjust_seq调整 seq 差值。
最后由将 syn 包发送给 rs
ipv4_rcv 接收 rs ack 应答
当 rs 返回 ack 应答时,数据包经过 dp_vs_in 处理,此时在流表里己经有 conn 了,会走入 syn proxy 逻辑
/* Syn-proxy 3 logic: receive syn-ack from rs */
if (dp_vs_synproxy_synack_rcv(mbuf, conn, prot,
ip4_hdrlen(mbuf), &verdict) == 0) {
dp_vs_stats_out(conn, mbuf);
dp_vs_conn_put(conn);
return verdict;
}
那么看下 dp_vs_synproxy_synack_rcv 具体实现
/* Syn-proxy step 3 logic: receive rs's Syn/Ack.
* Update syn_proxy_seq.delta and send stored ack mbufs to rs. */
int dp_vs_synproxy_synack_rcv(struct rte_mbuf *mbuf, struct dp_vs_conn *cp,
struct dp_vs_proto *pp, int ihl, int *verdict)
{
struct tcphdr _tcph, *th;
struct dp_vs_synproxy_ack_pakcet *tmbuf, *tmbuf2;
struct list_head save_mbuf;
struct dp_vs_dest *dest = cp->dest;
unsigned conn_timeout = 0;
th = mbuf_header_pointer(mbuf, ihl, sizeof(_tcph), &_tcph);
if (unlikely(!th)) {
*verdict = INET_DROP;
return 0;
}
INIT_LIST_HEAD(&save_mbuf);
if ((th->syn) && (th->ack) && (!th->rst) &&
(cp->flags & DPVS_CONN_F_SYNPROXY) &&
(cp->state == DPVS_TCP_S_SYN_SENT)) {
cp->syn_proxy_seq.delta = htonl(cp->syn_proxy_seq.isn) - htonl(th->seq);
cp->state = DPVS_TCP_S_ESTABLISHED;
conn_timeout = dp_vs_get_conn_timeout(cp);
if (unlikely((conn_timeout != 0) && (cp->proto == IPPROTO_TCP)))
cp->timeout.tv_sec = conn_timeout;
else
cp->timeout.tv_sec = pp->timeout_table[cp->state];
dpvs_time_rand_delay(&cp->timeout, 1000000);
if (dest) {
rte_atomic32_inc(&dest->actconns);
rte_atomic32_dec(&dest->inactconns);
cp->flags &= ~DPVS_CONN_F_INACTIVE;
}
/* Save tcp sequence for fullnat/nat, inside to outside */
if (DPVS_FWD_MODE_NAT == cp->dest->fwdmode ||
DPVS_FWD_MODE_FNAT == cp->dest->fwdmode) {
cp->rs_end_seq = htonl(ntohl(th->seq) + 1);
cp->rs_end_ack = th->ack_seq;
// ip_vs_synproxy_save_fast_xmit_info ?
/* Free stored syn mbuf, no need for retransmition any more */
if (cp->syn_mbuf) {
rte_pktmbuf_free(cp->syn_mbuf);
cp->syn_mbuf = NULL;
sp_dbg_stats32_dec(sp_syn_saved);
}
if (list_empty(&cp->ack_mbuf)) {
/*
* FIXME: Maybe a bug here, print err msg and go.
* Attention: cp->state has been changed and we
* should still DROP the syn/ack mbuf.
*/
RTE_LOG(ERR, IPVS, "%s: got ack_mbuf NULL pointer: ack-saved = %u\n",
__func__, cp->ack_num);
*verdict = INET_DROP;
return 0;
}
list_for_each_entry_safe(tmbuf, tmbuf2, &cp->ack_mbuf, list) {
list_del_init(&tmbuf->list);
cp->ack_num--;
list_add_tail(&tmbuf->list, &save_mbuf);
}
assert(cp->ack_num == 0);
list_for_each_entry_safe(tmbuf, tmbuf2, &save_mbuf, list) {
list_del_init(&tmbuf->list);
/* syn_mbuf will be freed correctly if xmit failed */
cp->packet_xmit(pp, cp, tmbuf->mbuf);
/* free dp_vs_synproxy_ack_pakcet */
rte_mempool_put(this_ack_mbufpool, tmbuf);
sp_dbg_stats32_dec(sp_ack_saved);
}
*verdict = INET_DROP;
return 0;
} else if ((th->rst) &&
(cp->flags & DPVS_CONN_F_SYNPROXY) &&
(cp->state == DPVS_TCP_S_SYN_SENT)) {
RTE_LOG(DEBUG, IPVS, "%s: get rst from rs, seq = %u ack_seq = %u\n",
__func__, ntohl(th->seq), ntohl(th->ack_seq));
/* Count the delta of seq */
cp->syn_proxy_seq.delta =
ntohl(cp->syn_proxy_seq.isn) - ntohl(th->seq);
cp->state = DPVS_TCP_S_CLOSE;
cp->timeout.tv_sec = pp->timeout_table[cp->state];
dpvs_time_rand_delay(&cp->timeout, 1000000);
th->seq = htonl(ntohl(th->seq) + 1);
//syn_proxy_seq_csum_update ?
return 1;
}
return 1;
}
- 首先判断应答包状态,必须是 syn 和 ack 包, 并且开启了 synproxy, 当前 conn 连接处于 DPVS_TCP_S_SYN_SENT 状态
- 更新 syn_proxy_seq.delta 序列号差值
- 设置 conn 状态是 DPVS_TCP_S_ESTABLISHED
- 保存序号 rs_end_seq 和 rs_end_ack
- 释放 syn_mbuf,己经不需要了
- 在全局 ack_mbuf 链表中删除自己的 ack_mbuf 引用
- 调用
dp_vs_xmit_fnat将 ack_mbuf 发送出去,从哪发送到哪呢?这个 ack_mbuf 是 client 发过来的,此时要发送到后端 real server. 函数内部修改源目的地址和端口,并修改 seq 等等。此时真正的完成了三次握手。
ipv4_rcv 正常发送数据
这块逻辑就不贴代码了,dp_vs_in 查找流表,根据数据方向,来选择 xmit_inbound 发送到后端 rs,还是由 xmit_outbound 发送到 client,相应的回调分别是 packet_xmit 和 packet_out_xmit
总结
fullnat 流程还是很复杂的,特别是结合 syn proxy. 下一篇再分析流表超时管理。