flume的使用
文本数据:软件、硬件打印信息。
流媒体:音视频、图片
flume是什么??
flume是一个高效的可靠、可用的、分布式的海量日志数据收集、聚合、传输工具。
Flume is a distributed, reliable, and available service for efficiently
collecting, aggregating, and moving large amounts of log data
flume中组件及作用??
client:客户端(运行agent的地方)
source:数据源,负责接收数据
channel:管道,负责接收source的数据,然后并将数据推送到sink
sink:负责拉去channel中的数据,将其推送到持久化系统。
interceptor:拦截器,flume允许使用拦截器拦截数据,它作用于source、sink阶段,flume还允许拦截器链。
selector:选择器,作用于source阶段,然后决定数据发送的方式。
event:flume的事件,相当于一条数据。
agent:flume的客户端,一个agent运行在一个jvm里面。它是flume的最小运行单元。
source的种类:
avro 、 exec 、 spooling dir 、 syslogtcp 、 httpsource 、 avro sink() 、kafka等。
channel的种类:
file:
memory:
jdbc:
kafka:
sinks的种类:
logger 、 avro 、 hdfs、kafka 等。
数据模型:
单一数据流模型
多数据流模型:
flume的安装:
flume 0.9 和 1.x的版本的区别?
1、0.9以前的叫flume-og,而1.x的flume-ng
2、0.9区分逻辑和物理的节点,而1.x不在区分逻辑的和物理的node节点,每一个agent就是一个服务。
3、0.9需要master和zookeeper的支持,而1.x不在需要其支持。
4、0.9开发并不是很灵活,而1.x较为灵活,可以支持很多功能模块的自定义(source、sink、channel、interceptor、selector等)。
flume案例??
案例1、 avro + memory + logger
vi ./conf/avro
#定义agent必须三个组件
a1.sources=r1
a1.channels=c1
a1.sinks=s1
#配置sources
a1.sources.r1.type=avro
a1.sources.r1.bind=hadoop02
a1.sources.r1.port=6666
#配置channels
a1.channels.c1.type=memory
#配置sinks
a1.sinks.s1.type=logger
#将source和sink通过channel连接上
a1.sources.r1.channels=c1
a1.sinks.s1.channel=c1
启动agent:
flume-ng agent -c ./conf/ -f ./conf/avro1.conf -n a1 -Dflume.root.logger=INFO,console
测试:
flume-ng avro-client -c /usr/local/flume-1.6.0/conf/ -H hadoop02 -p 6666 -F /home/flumedata/avrodata
案例2、 exec + memory + logger
vi ./conf/exec
a1.sources=r1
a1.channels=c1
a1.sinks=s1
a1.sources.r1.type=exec
a1.sources.r1.command= tail -f /home/flumedata/exedata
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
a1.channels.c1.keep-alive=3
a1.channels.c1.byteCapacityBufferPercentage = 20
a1.channels.c1.byteCapacity = 800000
a1.sinks.s1.type = hdfs
a1.sinks.s1.hdfs.path = /flume/events/exec
a1.sinks.s1.hdfs.filePrefix = events-
a1.sinks.s1.hdfs.round = true
a1.sinks.s1.hdfs.roundValue = 10
a1.sinks.s1.hdfs.roundUnit = minute
a1.sources.r1.channels=c1
a1.sinks.s1.channel=c1
启动agent:
flume-ng agent -c ./conf/ -f ./conf/exec -n a1 -Dflume.root.logger=INFO,console
测试:
案例3、 spooldir + memory + logger
vi ./conf/spooldir
a1.sources=r1
a1.channels=c1
a1.sinks=s1
a1.sources.r1.type=spoolDir
a1.sources.r1.spoolDir=/home/flumedata/spool1
a1.sources.r1.fileHeader=true
a1.sources.r1.fileHeaderKey=file
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
a1.channels.c1.keep-alive=3
a1.channels.c1.byteCapacityBufferPercentage = 20
a1.channels.c1.byteCapacity = 800000
a1.sinks.s1.type = logger
a1.sources.r1.channels=c1
a1.sinks.s1.channel=c1
启动agent:
flume-ng agent -c ./conf/ -f ./conf/exec -n a1 -Dflume.root.logger=INFO,console
测试:
案例4、 syslogtcp + memory + logger
vi ./conf/syslogtcp
a1.sources=r1
a1.channels=c1
a1.sinks=s1
a1.sources.r1.type=syslogtcp
a1.sources.r1.port=6666
a1.sources.r1.host=hadoop01
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
a1.channels.c1.keep-alive=3
a1.channels.c1.byteCapacityBufferPercentage = 20
a1.channels.c1.byteCapacity = 800000
a1.sinks.s1.type = logger
a1.sources.r1.channels=c1
a1.sinks.s1.channel=c1
启动agent:
flume-ng agent -c ./conf/ -f ./conf/syslogtcp -n a1 -Dflume.root.logger=INFO,console
测试:
echo "hello qianfeng" | nc hadoop01 6666
案例5、 http + memory + logger
vi ./conf/http
a1.sources=r1
a1.channels=c1
a1.sinks=s1
a1.sources.r1.type=org.apache.flume.source.http.HTTPSource
a1.sources.r1.port=6666
a1.sources.r1.bind=hadoop01
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
a1.channels.c1.keep-alive=3
a1.channels.c1.byteCapacityBufferPercentage = 20
a1.channels.c1.byteCapacity = 800000
a1.sinks.s1.type = logger
a1.sources.r1.channels=c1
a1.sinks.s1.channel=c1
启动agent:
flume-ng agent -c ./conf/ -f ./conf/http -n a1 -Dflume.root.logger=INFO,console
测试:
curl -X POST -d '[{"headers":{"time":"2017-06-13"},"body":"this is http"}]' http://hadoop01:6666
案例6、 exec + memory + hdfs
vi ./conf/hdfs
a1.sources=r1
a1.channels=c1
a1.sinks=s1
a1.sources.r1.type=exec
a1.sources.r1.command= tail -f /home/flumedata/exedata
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
a1.channels.c1.keep-alive=3
a1.channels.c1.byteCapacityBufferPercentage = 20
a1.channels.c1.byteCapacity = 800000
a1.sinks.s1.type = hdfs
a1.sinks.s1.hdfs.path = hdfs://qianfeng/flume/events/%y-%m-%d/%H%M/%S
a1.sinks.s1.hdfs.filePrefix = qianfeng-
a1.sinks.s1.hdfs.fileSuffix=.log
a1.sinks.s1.hdfs.inUseSuffix=.tmp
a1.sinks.s1.hdfs.rollInterval=2
a1.sinks.s1.hdfs.rollSize=1024
a1.sinks.s1.hdfs.fileType=DataStream
a1.sinks.s1.hdfs.writeFormat=Text
a1.sinks.s1.hdfs.round = true
a1.sinks.s1.hdfs.roundValue = 1
a1.sinks.s1.hdfs.roundUnit = second
a1.sinks.s1.hdfs.useLocalTimeStamp=false
a1.sources.r1.channels=c1
a1.sinks.s1.channel=c1
启动agent:
flume-ng agent -c ./conf/ -f ./conf/hdfs -n a1 -Dflume.root.logger=INFO,console
测试:
案例7、 exec + file + hdfs
vi ./conf/file
a1.sources=r1
a1.channels=c1
a1.sinks=s1
a1.sources.r1.type=exec
a1.sources.r1.command= tail -f /home/flumedata/exedata
a1.channels.c1.type=file
a1.channels.c1.checkpointDir=/home/flumedata/checkpoint
a1.channels.c1.dataDirs=/home/flumedata/data
a1.sinks.s1.type = hdfs
a1.sinks.s1.hdfs.path = hdfs://qianfeng/flume/events/%y-%m-%d/%H%M/%S
a1.sinks.s1.hdfs.filePrefix = qianfeng-
a1.sinks.s1.hdfs.fileSuffix=.log
a1.sinks.s1.hdfs.inUseSuffix=.tmp
a1.sinks.s1.hdfs.rollInterval=2
a1.sinks.s1.hdfs.rollSize=1024
a1.sinks.s1.hdfs.fileType=DataStream
a1.sinks.s1.hdfs.writeFormat=Text
a1.sinks.s1.hdfs.round = true
a1.sinks.s1.hdfs.roundValue = 1
a1.sinks.s1.hdfs.roundUnit = second
a1.sinks.s1.hdfs.useLocalTimeStamp=false
a1.sources.r1.channels=c1
a1.sinks.s1.channel=c1
启动agent:
flume-ng agent -c ./conf/ -f ./conf/file -n a1 -Dflume.root.logger=INFO,console
测试:
---------------------#############拦截器--------------------
案例1、
vi ./conf/ts1
a1.sources=r1
a1.channels=c1
a1.sinks=s1
a1.sources.r1.type=exec
a1.sources.r1.command= tail -f /home/flumedata/test.dat
a1.sources.r1.interceptors = i1 i2 i3
a1.sources.r1.interceptors.i1.type = timestamp
a1.sources.r1.interceptors.i1.preserveExisting=true
a1.sources.r1.interceptors.i2.type = host
a1.sources.r1.interceptors.i2.hostHeader = hostname
a1.sources.r1.interceptors.i2.preserveExisting=true
a1.sources.r1.interceptors.i3.type = static
a1.sources.r1.interceptors.i3.key = city
a1.sources.r1.interceptors.i3.value = NEW_YORK
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
a1.channels.c1.keep-alive=3
a1.channels.c1.byteCapacityBufferPercentage = 20
a1.channels.c1.byteCapacity = 800000
a1.sinks.s1.type = hdfs
a1.sinks.s1.hdfs.path = /flume/events/%y-%m-%d/%H%M/%S
a1.sinks.s1.hdfs.filePrefix = %{hostname}-
a1.sinks.s1.hdfs.fileSuffix=.log
a1.sinks.s1.hdfs.inUseSuffix=.tmp
a1.sinks.s1.hdfs.rollInterval=2
a1.sinks.s1.hdfs.rollSize=1024
a1.sinks.s1.hdfs.fileType=DataStream
a1.sinks.s1.hdfs.writeFormat=Text
a1.sinks.s1.hdfs.round = true
a1.sinks.s1.hdfs.roundValue = 1
a1.sinks.s1.hdfs.roundUnit = second
a1.sinks.s1.hdfs.useLocalTimeStamp=false
a1.sources.r1.channels=c1
a1.sinks.s1.channel=c1
启动agent:
flume-ng agent -c ./conf/ -f ./conf/ts -n a1 -Dflume.root.logger=INFO,console
测试:
案例2、
vi ./conf/ts3
a1.sources=r1
a1.channels=c1
a1.sinks=s1
a1.sources.r1.type=exec
a1.sources.r1.command= tail -f /home/flumedata/exedata
a1.sources.r1.interceptors = i1 i2 i3
a1.sources.r1.interceptors.i1.type = timestamp
a1.sources.r1.interceptors.i1.preserveExisting=true
a1.sources.r1.interceptors.i2.type = host
a1.sources.r1.interceptors.i2.hostHeader = hostname
a1.sources.r1.interceptors.i2.preserveExisting=true
a1.sources.r1.interceptors.i3.type = static
a1.sources.r1.interceptors.i3.key = city
a1.sources.r1.interceptors.i3.value = NEW_YORK
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
a1.channels.c1.keep-alive=3
a1.channels.c1.byteCapacityBufferPercentage = 20
a1.channels.c1.byteCapacity = 800000
a1.sinks.s1.type = logger
a1.sources.r1.channels=c1
a1.sinks.s1.channel=c1
启动agent:
flume-ng agent -c ./conf/ -f ./conf/ts -n a1 -Dflume.root.logger=INFO,console
测试:
案例3、正则拦截器
vi ./conf/rex
a1.sources=r1
a1.channels=c1
a1.sinks=s1
a1.sources.r1.type=exec
a1.sources.r1.command= tail -f /home/flumedata/text.log
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = regex_filter
a1.sources.r1.interceptors.i1.regex=^[0-9].*$
a1.sources.r1.interceptors.i1.excludeEvents=false
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
a1.channels.c1.keep-alive=3
a1.channels.c1.byteCapacityBufferPercentage = 20
a1.channels.c1.byteCapacity = 800000
a1.sinks.s1.type = logger
a1.sources.r1.channels=c1
a1.sinks.s1.channel=c1
启动agent:
flume-ng agent -c ./conf/ -f ./conf/rex -n a1 -Dflume.root.logger=INFO,console
测试:
#####案例3、复制选择器
vi ./conf/rep
a1.sources=r1
a1.channels=c1 c2
a1.sinks=s1 s2
a1.sources.r1.type=exec
a1.sources.r1.command= tail -f /home/flumedata/test.dat
a1.sources.r1.selector.type = replicating
a1.sources.r1.selector.optional = c2
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
a1.channels.c1.keep-alive=3
a1.channels.c1.byteCapacityBufferPercentage = 20
a1.channels.c1.byteCapacity = 800000
a1.channels.c2.type=memory
a1.channels.c2.capacity=1000
a1.channels.c2.transactionCapacity=100
a1.channels.c2.keep-alive=3
a1.channels.c2.byteCapacityBufferPercentage = 20
a1.channels.c2.byteCapacity = 800000
a1.sinks.s1.type = logger
a1.sinks.s2.type = hdfs
a1.sinks.s2.hdfs.path = /flume/events/%y-%m-%d/%H%M/%S
a1.sinks.s2.hdfs.filePrefix = event-
a1.sinks.s2.hdfs.fileSuffix=.log
a1.sinks.s2.hdfs.inUseSuffix=.tmp
a1.sinks.s2.hdfs.rollInterval=2
a1.sinks.s2.hdfs.rollSize=1024
a1.sinks.s2.hdfs.fileType=DataStream
a1.sinks.s2.hdfs.writeFormat=Text
a1.sinks.s2.hdfs.round = true
a1.sinks.s2.hdfs.roundValue = 1
a1.sinks.s2.hdfs.roundUnit = second
a1.sinks.s2.hdfs.useLocalTimeStamp=true
a1.sources.r1.channels=c1 c2
a1.sinks.s1.channel=c1
a1.sinks.s2.channel=c2
#####案例4、复分选择器
vi ./conf/mul
a1.sources=r1
a1.channels=c1 c2
a1.sinks=s1 s2
a1.sources.r1.type=org.apache.flume.source.http.HTTPSource
a1.sources.r1.port=6666
a1.sources.r1.bind=hdp01
a1.sources.r1.selector.type = multiplexing
a1.sources.r1.selector.header = status
a1.sources.r1.selector.mapping.CZ = c1
a1.sources.r1.selector.mapping.US = c2
a1.sources.r1.selector.default = c1
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
a1.channels.c1.keep-alive=3
a1.channels.c1.byteCapacityBufferPercentage = 20
a1.channels.c1.byteCapacity = 800000
a1.channels.c2.type=memory
a1.channels.c2.capacity=1000
a1.channels.c2.transactionCapacity=100
a1.channels.c2.keep-alive=3
a1.channels.c2.byteCapacityBufferPercentage = 20
a1.channels.c2.byteCapacity = 800000
a1.sinks.s1.type = logger
a1.sinks.s2.type = hdfs
a1.sinks.s2.hdfs.path = /flume/events/%y-%m-%d/%H%M/%S
a1.sinks.s2.hdfs.filePrefix = event-
a1.sinks.s2.hdfs.fileSuffix=.log
a1.sinks.s2.hdfs.inUseSuffix=.tmp
a1.sinks.s2.hdfs.rollInterval=2
a1.sinks.s2.hdfs.rollSize=1024
a1.sinks.s2.hdfs.fileType=DataStream
a1.sinks.s2.hdfs.writeFormat=Text
a1.sinks.s2.hdfs.round = true
a1.sinks.s2.hdfs.roundValue = 1
a1.sinks.s2.hdfs.roundUnit = second
a1.sinks.s2.hdfs.useLocalTimeStamp=true
a1.sources.r1.channels=c1 c2
a1.sinks.s1.channel=c1
a1.sinks.s2.channel=c2
测试数据:
curl -X POST -d '[{"headers":{"status":"2017-06-13"},"body":"this is default"}]' http://hdp01:6666
curl -X POST -d '[{"headers":{"status":"CZ"},"body":"this is CZ"}]' http://hadoop01:6666
curl -X POST -d '[{"headers":{"status":"US"},"body":"this is US"}]' http://hadoop01:6666
案例5、flume集群搭建:
hadoop01的配置:
a1.sources=r1
a1.channels=c1
a1.sinks=s1
a1.sources.r1.type=syslogtcp
a1.sources.r1.port=6666
a1.sources.r1.host=hadoop01
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
a1.channels.c1.keep-alive=3
a1.channels.c1.byteCapacityBufferPercentage = 20
a1.channels.c1.byteCapacity = 800000
a1.sinks.s1.type =avro
a1.sinks.s1.hostname=hadoop03
a1.sinks.s1.port=6666
a1.sources.r1.channels=c1
a1.sinks.s1.channel=c1
hadoop02的配置:
a1.sources=r1
a1.channels=c1
a1.sinks=s1
a1.sources.r1.type=syslogtcp
a1.sources.r1.port=6666
a1.sources.r1.host=hadoop02
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
a1.channels.c1.keep-alive=3
a1.channels.c1.byteCapacityBufferPercentage = 20
a1.channels.c1.byteCapacity = 800000
a1.sinks.s1.type =avro
a1.sinks.s1.hostname=hadoop03
a1.sinks.s1.port=6666
a1.sources.r1.channels=c1
a1.sinks.s1.channel=c1
hadoop03的配置:
agent.sources=r1
agent.channels=c1
agent.sinks=s1
agent.sources.r1.type=avro
agent.sources.r1.port=6666
agent.sources.r1.bind=hadoop03
agent.channels.c1.type=memory
agent.channels.c1.capacity=1000
agent.channels.c1.transactionCapacity=100
agent.channels.c1.keep-alive=3
agent.channels.c1.byteCapacityBufferPercentage = 20
agent.channels.c1.byteCapacity = 800000
agent.sinks.s1.type =logger
agent.sources.r1.channels=c1
agent.sinks.s1.channel=c1
####然后测试:
先启动master的agent:
flume-ng agent -c ./conf/ -f ./conf/master -n agent -Dflume.root.logger=INFO,console &
然后再启动slave的agent:
flume-ng agent -c ./conf/ -f ./conf/slave1 -n a1 -Dflume.root.logger=INFO,console &
flume-ng agent -c ./conf/ -f ./conf/slave2 -n a1 -Dflume.root.logger=INFO,console &
flume的缺点:??
同步部署较难
tail -f /vat/access.log
cat /vat/---access.log
#####????
将合并的这台flume的sink写成hdfs sink?
将sink写成hive sink?
flume的高可用
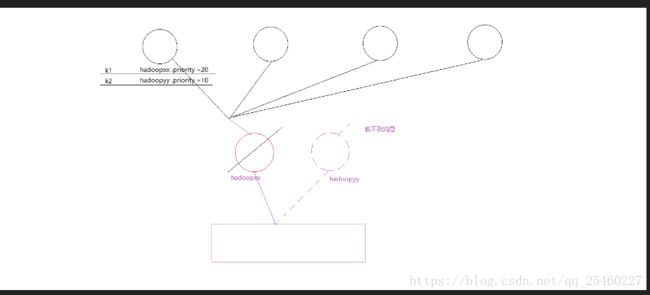
flume框架的设计思想----flume的内部结构
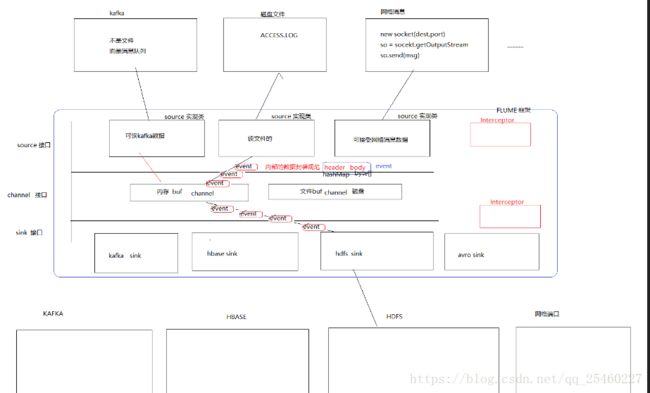
多agent