关于hadoop-2.6.0-cdh5.7.0 、 hbase-1.2.0-cdh5.7.0开启snappy压缩,直接导入lib库,免编译版
大家好,我是Linux运维工程师 Linke 。技术过硬,从不挖坑~
hbase开启snappy压缩功能,必须要先开启hdfs的snappy压缩功能,因为什么就不用我说了。网上文档都是说要编译库文件后才能使用,于是我大费周折的编译好 hadoop-2.6.0-cdh5.7.0 版本的,测试没问题后,又直接将lib库放到 hadoop-2.6.0-cdh5.9.3 版本上,配置好后也可以用。 下面是支持hadoop-2.6.0-cdh* 版本的snappy压缩功能的 lib 库配置方法。
此文档只介绍如何给 hadoop 、 hbase 集群加 snappy 压缩功能
搭建 hadoop-2.6.0-cdh5.7.0 分布式高可用集群请查看文档
https://blog.csdn.net/qq_31547771/article/details/100579545
搭建 hbase-1.2.0-cdh5.7.0 分布式高可用集群请查看文档
https://blog.csdn.net/qq_31547771/article/details/100769808
CDH hadoop 版本下载地址 http://archive.cloudera.com/cdh5/cdh/5/
注意:下载 hadoop 和 hbase 时,一定要下载 cdh 一样的版本。
本工程师下载的是 hadoop-2.6.0-cdh5.7.0.tar.gz (这个包里面也包含了源码包,在 src 目录下,不过我们直接用编译好的lib库就用不着源码包) 和 hbase-1.2.0-cdh5.7.0.tar.gz
第一步:下载我编译好的lib库文件
链接:点击下载库文件
提取码:m2uw
此文件名为 hadoop2.6.0-cdh5.x-native.tgz
解压文件:
tar xvf hadoop2.6.0-cdh5.x-native.tgz
解压后得到目录 native , 目录内文件如图

第二步:配置hadoop集群支持 snappy 压缩功能
1、将解压的目录复制到 hadoop 主目录的 lib 目录下,原hadoop lib 目录下也有 native 这个目录,是空的。直接覆盖过去就行。
2、补一下环境变量HADOOP_COMMON_LIB_NATIVE_DIR和HADOOP_OPTS ,下面的这个是完整的环境变量,看自己缺了哪个
vim /etc/profile
export HBASE_HOME="/data/hbase-1.2.0-cdh5.7.0"
export HADOOP_HOME="/data/hadoop-2.6.0-cdh5.7.0"
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export PATH=$PATH:$HADOOP_HOME/bin:$HBASE_HOME/bin
3、在将 native 目录下的 lib 文件复制到 lib 目录下,这个本工程师测试了, 只有 native 目录下有 lib 文件不行,lib 目录下也要有这些 lib 文件,如果只给 native 目录下放文件,需要另外再加环境变量,然后老夫是个懒人,直接将文件复制出来。如图,hadoop-2.6.0-cdh5.7.0 目录是我的hadoop主目录。圆圈圈住的那个目录在 hbase 中有用,hadoop中不需要。删了也行,留的也不碍事。
cp native/* /data/hadoop-2.6.0-cdh5.7.0/lib/native/
cp native/lib* /data/hadoop-2.6.0-cdh5.7.0/lib/

3、在 core-site.xml 配置文件加可开放的 lib 压缩功能(配置文件中最后一行的逗号可有可无,本工程师测了,不会有影响)
vim etc/hadoop/core-site.xml
io.compression.codecs
org.apache.hadoop.io.compress.GzipCodec,
org.apache.hadoop.io.compress.DefaultCodec,
org.apache.hadoop.io.compress.BZip2Codec,
org.apache.hadoop.io.compress.Lz4Codec,
org.apache.hadoop.io.compress.SnappyCodec,
4、在 mapred-site.xml 配置文件指定开放哪种压缩功能
vim etc/hadoop/mapred-site.xml
mapreduce.map.output.compress
true
mapreduce.map.output.compress.codec
org.apache.hadoop.io.compress.SnappyCodec
5、将配置好的hadoop分发到各个hadoop节点。
6、到此 hadoop 配置完毕,不用再另外修改添加任何配置和环境变量,直接重启 hdfs 和 yarn 集群。
stop-yarn.sh
stop-dfs.sh
start-dfs.sh
start-yarn.sh
7、验证hadoop集群是否开启 snappy 功能。如图,箭头红线的 openssl 那行如果报错的话,安装了openssl 就可以了,不用重启集群。
yum install -y openssl openssl-devel
hadoop checknative

8、如上步图中显示了,hdfs 已经可以支持 snappy 功能了。让本工程师来搞个300M左右的文件测试一下
hdfs dfs -mkdir /test
hdfs dfs -put /root/hadoop-snappy-2.6.0-cdh5.7.0.tar.gz /test/
hdfs dfs -ls /test
hdfs dfs -du -s -h /test/hadoop-snappy-2.6.0-cdh5.7.0.tar.gz

上传了一个文件,可以看到在 hdfs 中的大小是 318M,让本工程师来调用 MapReduce 任务提交一下作业,如图提交后文件的大小已经是压缩后的大小了
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0-cdh5.7.0.jar wordcount /test/hadoop-snappy-2.6.0-cdh5.7.0.tar.gz /tmp/compression-out/
hdfs dfs -du -s -h /test/hadoop-snappy-2.6.0-cdh5.7.0.tar.gz
hdfs dfs -ls /tmp/compression-out
hdfs dfs -du -s -h /tmp/compression-out/part-r-00000
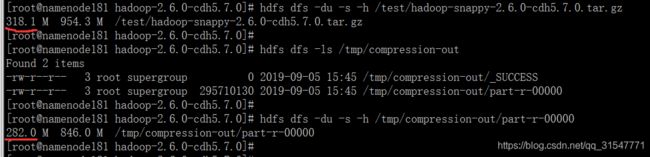
至此,hdfs 的压缩已成功开启。下面就可以开启 hbase 的 snappy 功能了。
第二步:开启hbase的 snappy 压缩功能
1、将刚刚下载下来的文件直接解压覆盖到 hbase 主目录的 lib 目录下。如图
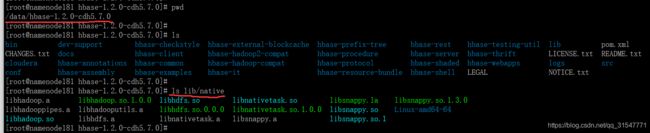
2、在hbase-site.xml配置文件中指定压缩格式
vim conf/hbase-site.xml
hbase.regionserver.codecs
snappy
3、将hbase主目录分发到各个节点,或者将 lib 文件 和 配置文件 …… 你懂得
4、重启hbase
./bin/stop-hbase.sh
./bin/start-hbase.sh
5、登录hbase,创建一个指定压缩格式的表看是否报错。
hbase shell
create 'linke', { NAME => 'c', COMPRESSION => 'SNAPPY' }
describe 'linke'

6、测试hbase压缩。这里我没做测试,因为 Linke 非常自信。技术过硬,从不挖坑。
测试思路: 创建一个普通的表,然后灌入差不多大的数据;修改表支持 SNAPPY ,压缩完毕后查看 hdfs 中 hbase 文件是否变大。