R语言基础(三)-数据处理常用操作
目录
- 判断
- 循环
- 定义函数
- 常用操作
4.1 列联表
4.2 合并数据集
4.3 取数据的子集
1.判断
括号不要搞混了
x = 2
if(x<2) {
print("Hello")
} else if(x<5) {
print("Hi")
} else {
print("Bye")
}2.循环
#计算10以内所有偶数的和
sum = 0
for(i in 1:10) {
if(i%%2==0) {
sum = sum +i
print(sum)
}
}
输出:
[1] 2
[1] 6
[1] 12
[1] 20
[1] 30计算30以内的所有正树的积,但积不许超过300
y=1
i=1
while (i<30) {
if(y*i>300) {
break
} else {
y = y*i
i=i+1
print(y)
}
}
输出:
[1] 1
[1] 2
[1] 6
[1] 24
[1] 1203.定义函数
#定义函数
calcu = function(x,dire, method = mean) {
y = apply(x, dire, method)
return(y)
}
calcu(mat,1)
calcu(mat,1,method = sum)
报错了
Error in get(as.character(FUN), mode = "function", envir = envir) :
没有状态为"function"的"method"目标对象 因为之前的方法中有了一个变量的名字叫做sum,所以再用的时候,sum表示的是一个之前得到的数值。
有两种方法解决:
calcu(mat,1,method = 'sum') #加上引号
rm(sum) #或者先把这个值线去掉
calcu(mat,1,method = sum) #然后再使用这个sum4.常用操作
使用泰坦尼克号的训练数据来练一下手,数据请到kaggle的比赛页面下载。
> info = read.csv('/Users/huanghuaixian/code/ML/kaggle/code/lecture01/Feature_engineering_and_model_tuning/Kaggle_Titanic/train.csv',sep=',',header = T)
> View(info)
4.1 列联表
> table(info$Survived) #查看一下数据样本的类型分布
0 1
549 342 > s_p = table(info[,c(2,3)])
> View(s_p)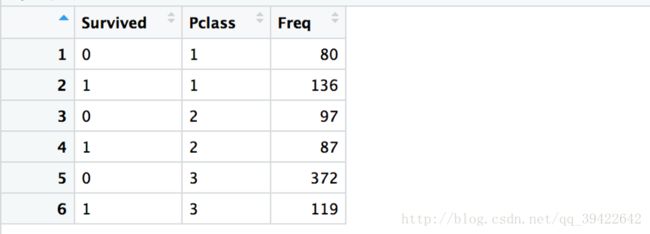
貌似这样子看不太好看
> s_p
Pclass
Survived 1 2 3
0 80 97 372
1 136 87 119这样子看更加明显,看他们同时出现的频率是多少。
如果我们想知道在Pclass的三个仓位中,获得生存的占比,可以输出它们的百分号。
#输出百分号
percent_get = function(x) {
sum = sum(x)
x = round(x/sum,digits = 3)
x = paste(x*100,"%",sep = "") #在小数后面加上%
return(x)
}
apply(s_p,2,percent_get)
Pclass
1 2 3
[1,] "37%" "52.7%" "75.8%"
[2,] "63%" "47.3%" "24.2%"但是这样的到的数值都是字符串了,如果想要再进行运算就不行了。所以这种操作只适合用于观看,而且不能做成图。
4.2 合并数据集
> info_test = read.csv('/Users/huanghuaixian/code/ML/kaggle/code/lecture01/Feature_engineering_and_model_tuning/Kaggle_Titanic/test.csv',sep=',',header = T) #把测试集也读取进来
> dim(info) #训练数据维数
[1] 891 12
> dim(info_test) #测试数据维数
[1] 418 11
> all_data = merge(info_test,info,all.y = T) #通过列名来合并
> dim(all_data)
[1] 891 12
> all_data1 = merge(info_test,info,all.x = T) #通过行索引合并,因为测试数据只有418,故合并之后也只有418
> dim(all_data1)
[1] 418 124.3 取数据的子集
> cla1 = subset(all_data,all_data$Survived==1)[-12] #取生存的人的样本,同时去掉Survived这一列,因为它都是1
> cal0 = subset(all_data,all_data$Survived==0)[-12]
> View(cla1)
> dim(cla1)
[1] 342 11未完待续