linux-awk练习
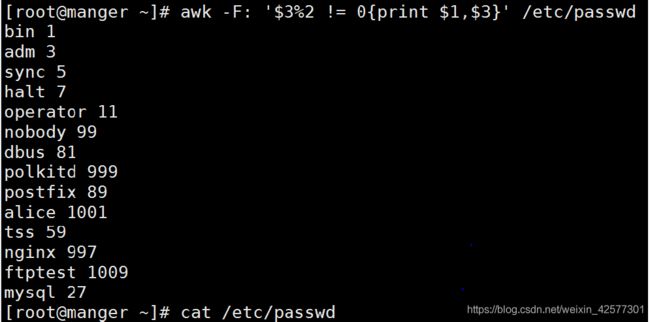
1.只处理用户ID为奇数的行,并打印用户名和uid号
代码:
awk -F: '$3%2 != 0{print $1,$3}' /etc/passwd
运行结果:
2.显示系统的普通用户,并打印用户名和ID
代码:
awk -F: '$1! = "root" {print $1,$3}' /etc/passwd
运行结果:

3.显示用户shell是’/bin/bash’的用户,并打印用户名
代码:
awk -F: '$7 == "/bin/bash"{print $1}' /etc/passwd
运行结果:

4.统计普通用户的个数
代码:
awk -F: '$1!="root" {print $1,$3}' /etc/passwd | wc -l
运行结果:
![]()
5.统计文本的总行数
代码:
awk -F: '{print}' /etc/passwd | wc -l
运行结果:

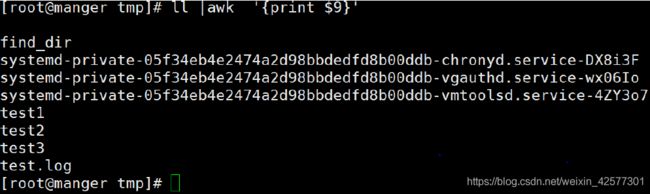
6.显示文件名
代码:
ll |awk '{print $9}'
运行结果:
7.显示UID为1001用户的相关信息
代码:
awk -F: '$3 == 1001{print $0}' /etc/passwd
运行结果:

8.利用awk模拟tail -1的效果
代码:
awk 'END{print $0}' /etc/passwd
运行结果:

9.看懂数组两个练习(统计tcp链接数)
代码:
1.统计tcp的链接数
netstat -ant | awk '/^tcp/ {++state[$NF]} END {for(key in state) print key,"\t",state[key]}'
统计tcp两个状态(LISTEN\ESTABLISHED)的链接个数,用数组state计数
2.分别统计不同ip的tcp连接
netstat -ant | awk '/^tcp/ {n=split($(NF-1),array,":");if(n<=2)++S[array[(1)]];else++S[array[(4)]];++s[$NF];++N} END {for(a in S){printf("%-20s %s\n", a, S[a]);++I}printf("%-20s %s\n","TOTAL_IP",I);for(a in s) printf("%-20s %s\n",a, s[a]);printf("%-20s %s\n","TOTAL_LINK",N);}'
split( ( N F − 1 ) , a r r a y , " : " ) 将 倒 数 第 二 个 字 段 按 照 " : " 分 割 成 a r r a y 数 组 , S [ ] 数 组 下 标 是 i p 地 址 , 元 素 是 每 个 i p 地 址 的 链 接 个 数 , , s [ (NF-1),array,":")将倒数第二个字段按照":"分割成array数组,S[]数组下标是ip地址,元素是每个ip地址的链接个数,,s[ (NF−1),array,":")将倒数第二个字段按照":"分割成array数组,S[]数组下标是ip地址,元素是每个ip地址的链接个数,,s[NF]下标是状态(LISTEN\ESTABLISHED),元素是每个状态链接个数;N是总链接数。
10.将test2文件中的行追加到test1的同一行后,并保存到文件test3
test1文本内容:
haha
hehe
alice
bobtest2文本内容:
20
25
18
30test3文本内容:
haha:20
hehe:25
alice:18
bob:30
代码:
awk '{printf "%s: ",$1; getline t < "test2" ; printf " %s\n",t}' test1 > test3
运行结果:

11.某产品的CDN带宽运营成本迅猛增涨,其带宽主要由各种类型的图片组成,为了对某产品的图片流量带宽进行优化,现需要对该产品的图片和号码特性做一些分析,已有的日志文件test.log供分析使用,格式:
号码|请求大小|请求id,内容如下:
001|100|abc.gif
002|80|abd.jpg
003|150|abe.gif
001|60|abf.gif003|30|abg.jpg
其中带有gif表示是gif图片的请求,带有jpg表示是jpg图片的请求,请使用(python/shell/awk/sort)编写程序实现如下分析思路(1,2为中间步骤,可以只输出3,4结果):
1.找出所有gif图片请求的所有号码
2.找出所有gif图片请求的号码和其对应的请求大小总和及请求数总和.
3.找出所有gif图片请求的号码,并按照其请求大小总和从大到小排序.
4.找出所有gif图片请求的号码,并按其请求平均图片大小从大到小排序.
代码:
awk -F '|' '/gif$/{print$1}' test.log |sort -n | uniq
awk -F '|' '/gif$/{arg[$1] += $2}END{for(i in arg){print i,arg[i]}}' test.log
awk -F '|' '/gif$/{arg[$1] += $2}END{for(i in arg){print i,arg[i]}}' test.log |sort -k2nr

4.
awk -F '|' '/gif$/{++sum[$1];arg[$1] += $2}END{for(i in arg){print i,arg[i]/sum[i]}}' test.log |sort -k2nr

参考改进:awk脚本作业