某工具类 APP 容器化过程的思考与实践
本次CKA培训课程,通过线下授课、考题解读、模拟演练等方式,帮助学员快速掌握Kubernetes的理论知识和专业技能,并针对考试做特别强化训练,让学员能从容面对CKA认证考试,使学员既能掌握Kubernetes相关知识,又能通过CKA认证考试,点击下方图片了解详情。

现在基本没有人会考虑该不该使用 Kubernetes,大家都在考虑如何用好 Kubernetes,本文主要介绍我们公司基于 GitLab,Jenkins,Helm 等开源组件做的Kubernetes部署工具,还有使用 Kubernetes 的过程中遇到的关于应用日志,灰度发布,监控等问题的思考与实践。
我司使用 Kubernetes 容器接入生产流量已经一年多了,目前的容器集群有在阿里云的是托管版,还有的在我们自己机房,Node 数一共不到50,目前所有集群通过 Ingress 接入的每日总流量在 8 亿 PV 以上。
目前我们的 Kubernetes 组件如下:
镜像仓库(Harbor )
网络插件 Flannel host-gw (阿里云托管版是 flannel vpc)
日志收集(Filebeat -> Kafka –> Logstash -> Elasticsearch -> Kibana,Filebeat Sidecar 应用的 Pod)
流量接入(Nginx Ingress)
监控(Prometheus+Grafana)
CD(Jenkins Helm)
CD 介绍

我们就从我们的 CD 工具开始介绍,逐步说下我们从虚拟机的应用部署迁移到 Kubernetes 容器应用部署的一些思考与实践。
我们有一个很重要的前提就是我们线上运维团队不到 5 人,所以我认为适合我们的 CD 解决方案应该符合以下几点:
尽量少的引入复杂度(尽量不自己造轮子)
依赖开源工具
轻量(以后我们想要换别的,可以换的比较轻松)
我们选择的CD方案
我以新上线一个应用,并且部署到 Kubernetes 为例,具体流程如下图:

从笔记本的源码库上添加一个应用,然后运行我们自己编写工具脚本生成 Jenkins 的 Job DSL,然后把这些文件都 push 到 GitLab 上面
到了 GitLab 以后,GitLab 会触发 Jenkins 的 webhook
Jenkins 会根据 Job DSL 生成对应的 Job
我们运维会通过这个 Jenkins Job 调用 Helm 部署到 Kubernetes
下面我就具体介绍一下我们整个流程,我们的技术栈大部分都是 Java,这个例子也是以 Java 为例,这次分享就是为了给大家看看思路,所以会简化很多东西。
应用配置
我们笔记本上的源码库文件树如下:
├── config.yaml
├── generate_dsl.go
├── department1
│ ├── app.groovy
│ └── app2.groovy
├── department2
│ ├── app1.groovy
└── templates
├── helm_dsl
│ └── common.tpl
└── helm_templates
└── common
├── app.yaml
├── filebeat-config.yaml
├── flume_config.yaml
├── ingress.yaml
├── java.yaml
└── python.yaml
test,test1 是部门名,common.tpl 是生成 Jenkins Job DSL 的模板,templates/helm_templates/common 是 Helm 的模板,generate_dsl.go 是按照配置文件生成 Jenkins Job DSL 的脚本。
我们从 config.yaml 中添加一个新的应用配置,一个例子如下:
- department_name: department2
apps:
- app_name: app1
image_tpl: jar
clusters:
- name: shubei
replicaCount: 6
replicaCountMax: 12
- name: aliyun
replicaCount: 8
replicaCountMax: 12
values:
java_opts: "-Xms2550m -Xmx2550m -Duser.timezone=Asia/Shanghai"
service:
port: 8080
ingress:
enabled: true
hosts:
- host: demo.test.com
paths:
- /
我们的应用在不同的集群中目前就副本数不同。添加完这个配置文件后就会生成对应的 Jenkins Job DSL Groovy 脚本。
Jenkins部署
下图是我们部署到 Kubernetes 的 Jenkins 截图:

这个图中就能看到我们部署界面,下面是各个参数的解释:
release 是否灰度
helm_opts 是否加上 --dry-run --debug,只看 Helm 的 manifests
cluster 部署到哪个集群
VERSION 从 gitTag 中选择部署的分支
选择好参数,点击 build 就会自动把这个应用部署到对应的集群中。
下面是上面截图对应的 Jenkins DSL 代码:
choiceParam("app_name", ["${app_name}"], "")
choiceParam("release", ["canary", "normal"], "")
choiceParam("helm_opts", [" ", " --dry-run --debug "], "")
choiceParam("cluster", [{{- range .App.Clusters -}} "{{ .Name }}", {{- end -}}], "")
{{- if eq .App.ImageVersion "gitTag" }}
gitParameter{
name("VERSION")
type("PT_TAG")
sortMode('DESCENDING')
defaultValue('TOP')
selectedValue('TOP')
useRepository(gitUrl)
tagFilter('*')
branch('*')
branchFilter('*')
description('gitTag')
quickFilterEnabled(true)
listSize('5')
}
{{- else }}
stringParam("VERSION", "", "")
{{- end }}
下面是我们 Jenkins 主要的脚本:
department_name=department2
tag=${VERSION#$app_name-}
mkdir -p helm_app
cd helm_app
cp /ops/k8s_config/$cluster ./$cluster
export KUBECONFIG=$PWD/$cluster
kubens default
mkdir -p templates
rsync -avzP /ops/jenkins-helm-dsl/templates/helm_templates/common/ templates --delete
case $cluster in
zhaowei)
replicaCountMax=12
replicaCount=6
;;
aliyun)
replicaCountMax=12
replicaCount=8
;;
esac
cat << EOF > values.yaml
department_name: demo
java_opts: "-Xms2550m -Xmx2550m -Duser.timezone=Asia/Shanghai"
service:
port: 8080
ingress:
enabled: true
hosts:
- host: demo.test.com
paths:
- /
EOF
cat << EOF > Chart.yaml
apiVersion: v2
name: $app_name
description: A Helm chart for Kubernetes
type: application
version: 0.1.0
appVersion: $tag
EOF
helm_app_name=${app_name}
if [ $release == "canary" ]; then
helm_app_name=${app_name}-canary
fi
helm upgrade --install ${helm_app_name} ./ --set release=$release --set replicaCountMax=$replicaCountMax --set replicaCount=$replicaCount $helm_opts
我们运行上面脚本的 Jenkins Node 的 /ops/k8s_config/ 会有以各个集群为文件名的 kubeconfig 文件,/ops/jenkins-helm-dsl/templates/helm_templates/common/ 这个目录是我们 jenkins-helm-dsl 这个源码库 pull 到了Jenkins node 的 /ops 下。
Helm 部署
下面是我们 Helm 部署的一个标准化的模板。
{{- define "java" }}
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: {{ .Chart.Name }}
release: {{ .Values.release }}
name: {{ .Chart.Name }}{{- if eq .Values.release "canary" -}}-canary{{- end }}
spec:
{{- if eq .Values.release "normal" }}
replicas: {{ .Values.replicaCount }}
{{- end }}
{{- if eq .Values.release "canary" }}
replicas: 1
{{- end }}
selector:
matchLabels:
app: {{ .Chart.Name }}
release: {{ .Values.release }}
template:
metadata:
labels:
app: {{ .Chart.Name }}
release: {{ .Values.release }}
spec:
initContainers:
- name: app-jar
image: harbor.test.com/projects/{{ .Values.department_name }}/{{ .Chart.Name }}:{{ .Chart.AppVersion }}
command: ["/bin/sh","-c","cp /opt/*.jar /app"]
volumeMounts:
- mountPath: /app
name: app-volume
- name: logdir-init
image: busybox
command: ["/bin/sh","-c","mkdir -p /docker/logs/$HOSTNAME && ln -s /docker/logs/$HOSTNAME /opt/logs"]
volumeMounts:
- mountPath: /docker/logs
name: logs
- mountPath: /opt/
name: logdir-init
containers:
- name: {{ .Chart.Name }}
image: harbor.test.com/projects/jar-java8u251:v1
command:
- "/bin/sh"
- "-c"
- "java -jar {{ .Values.java_opts }} `ls /app/*jar` -Duser.timezone=Asia/Shanghai --spring.profiles.active=product"
volumeMounts:
- mountPath: /docker/logs
name: logs
- mountPath: /opt/
name: logdir-init
- mountPath: /app
name: app-volume
volumes:
- name: logs
hostPath:
path: /opt/logs
type: DirectoryOrCreate
- name: app-volume
emptyDir: {}
- name: logdir-init
emptyDir: {}
{{- end }}
容器镜像
我们 Java 的镜像都是只存编译好的 jar 包,通过 initContainers copy 到主容器中,下面使我们镜像的 build 过程:
tag=${VERSION#$app_name-}
department_name=department2
docker_tag=harbor.test.com/projects/$department_name/$app_name:$tag
cat << EOF > Dockerfile
FROM busybox
MAINTAINER yw
COPY target/$app_name.jar /opt/
EOF
docker build -t $docker_tag .
docker push $docker_tag
我们的镜像都是 /projects/部门名/应用名:tag 这个镜像 tag 和源码库的 tag 是一一对应的,上面脚本的 tag。还有我们的应用,源码库,生成的二进制文件(jar 包)都是一一对应的,这个一一对应的关系是我们这边的 Java 规范。如果不符合规范,就需要开发自己 build 镜像,然后发我们 tag 来部署。
灰度
我们灰度是用的一个 service 对应两个 deployment 的方式(https://github.com/ContainerSolutions/k8s-deployment-strategies/tree/master/canary/native ),通过 Helm 部署这两个 deployment(实际上是两个 Helm chart),我们灰度都是一个 Pod,每次部署的时候先部署单个 Pod 的 deployment,开发验证这个 Pod 日志正常的话,我们再部署 normal 的 deployment。这个部署过程和我们之前部署到虚拟机中的方式基本是一致的。具体实现可以看上面的配置和截图。
我们灰度的 chart 只有 deployment,其他如 Service,HPA,Ingress 等等都是在正常的 chart 里面,所以在应用部署到一个新集群的时候,需要先部署正常的 chart。
应用日志问题
我们的应用日志比较大,不适合全部收集到 Elasticsearch,所以我们把日志存在了主机上。我们这有一个场景:
应用A在上午的时候自动扩了一个 Pod,过了几分钟这个 Pod 因为负载低又被删了,这时候开发说有问题要看这个 Pod 的日志。
我们的解决方案也是受了唯品会之前分享的启发,在 Pod 中日志的路径是 /opt/logs/app_name 对应的 host 的路径是 /opt/logs/pod_name/app_name,这样就算 Pod 没了,应用日志还是会在主机上存储。具体的解决方法可以看上面 Helm 的 Java 模板。
管理工具
我们主要用 Rancher,k9s 也安装了。开发看日志是通过 rancher exec 进入 Pod 来看。
监控
我们 Kubernetes 基础设施的监控主要还是用的 Zabbix,Kubernetes 里面的监控用的是 https://github.com/coreos/kube-prometheus,应用的四个黄金指标中延迟,流量,错误,我们都是通过收集 Ingress 的日志监控,负载是通过 Prometheus 来监控的。我们 Kubernetes 里面的 Redis 都是 redis-exporter sidecar redis pod 通过 Prometheus 监控。
目前我们在把原来在 Zabbix 中的,逐步迁移到 Prometheus,现在我们已经把 Redis 的监控放到 Prometheus 中了,架构如图:
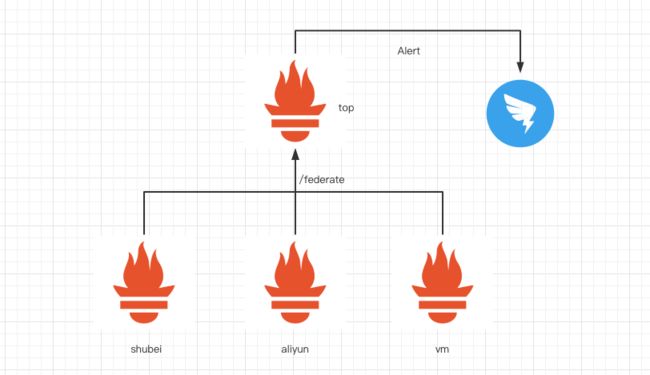
我们有一个 top Prometheus 通过 /federate 收集各个容器集群还有虚拟机上的 Prometheus Metric,每个集群中通过在 Prometheus 这个 CR(custom resource)中添加 externalLabels cluster: shubei,原有虚拟机上的 Prometheus 也是添加了 externalLabels cluster: vm,我们的告警都配置在 top Prometheus 上,告警统一发到钉钉的群。
经验分享
容器内核参数问题
容器里面内核参数一般都是默认的,比如 net.core.somaxconn 是 128,比如我们会有一个 initContainers 容器来修改这些参数。
initContainers:
- name: init-sysctl
command:
- /bin/sh
- -c
- |-
mount -o remount rw /proc/sys
sysctl -w net.core.somaxconn=65535
sysctl -w net.ipv4.ip_local_port_range="1024 65535"
sysctl -w fs.file-max=1048576
sysctl -w fs.inotify.max_user_instances=16384
sysctl -w fs.inotify.max_user_watches=524288
sysctl -w fs.inotify.max_queued_events=16384
image: busybox
imagePullPolicy: IfNotPresent
securityContext:
capabilities:
add:
- SYS_ADMIN
drop:
- ALL
集群之间的高可用
为了防止某个容器集群出现问题,影响应用,我们会在容器集群 Ingress 接入前面的 Nginx 上配置另外一个集群的 Ingress 作为备份。
多集群 Ingress 日志收集到同一个 Elasticsearch index:
我们是通过在 Ingress 的 log-format-upstream 加入 cluster 字段来区分不同的集群。
运维标准化
我觉得在我们这种小于 5 人的运维团队要执行某些标准,有些时候并不容易,但是标准真的很重要,所以这里说一下。我们从虚拟机时代应用,源码库,二进制文件就是一对一的关系,因为这个和开发的小伙伴儿相爱相杀过很多次,不过现在这个标准能覆盖我们 90% 以上的 Java 应用,我们无论是在做虚拟机部署工具的时候还是在做 Kubernetes 部署工具的时候,因为这个标准,我们省了好多事。
为什么没有用 Jenkins Pipeline,而是用的 Jenkins Job DSL
我们也调研过 Jenkins Pipeline,知道 Pipeline 还是大方向,但是我们想用 Jenkins Pipeline 并且还能从 Jenkins 的界面选择 gitTag 发版,那就需要应用的源码库中有 Jenkinsfile,但是我们现阶段没法把 Jenkinsfile 放到应用的源码库中,所以没有使用 Jenkins Pipeline。
开发测试生产三个环境如何保证镜像的一致性
在持续交付中有产出物流过整个流水线这个原则,我们目前还没有在测试环境搞容器化,但是我觉得可以这样做:
首先,开发和测试环境通过分支发版,镜像的 tag 就和源码库哈希值一致,做一镜像库中有没有该应用 tag 的判断即可,没有在构建镜像。
然后,生产环境按照源码库的 tag 发版,在发版构建镜像的时候,先取出该 tag 在源码库中的哈希值,然后把该应用镜像的 tag retag 成源码库的 tag。例如,源码库要发版的 tag 为 20200814-1,源码库的 md5 值为 25c198dbb0,那么我们就把镜像库的 app01:25c198dbb0 retag 成 app01:20200814-1。这样做的好处有:
开发测试环境的发版比较方便
开发测试生产三个环境用的容器镜像实际是一份,只是 tag 不同
生产环境可以根据 tag 很容易定位到对应的源码库版本
我们这个不到 50 台的 Node 为啥能抗住每天 8 亿 PV 的量
我觉得这个和我们公司的业务领域有很大的关系,我们公司 APP 是工具类的,大部分的接口已查询为主,应用和依赖的 RPC 都有本地缓存,应用依赖的中间件(Redis)缓存,数据的预处理等。
结束语
以上就是我们容器化过程的思考与实践,目前正在做的是在更多的场景下使用 Prometheus,容器集群接入更多的应用。我们在容器化的过程中很多时候也是受我们使用团队规模和使用规模影响,可能大家能学到的东西不是很多,但是这都是我们结合我们公司的实际情况总结出来的解决方案,希望能给大家带来一些思考。
Q&A
Q:开源 GitLab 如何做到多副本,高可用的?
A:是说 GitLab Server 吗?我们这就是定期备份一下 GitLab 的数据库,一般时候就是单节点跑着,有问题再通过备份恢复。
Q:CD 过程中,贵司用的什么组件或插件的方式实现 Kubernetes 的集群 API 调用的?除了Helm。
A:我们除了 Helm 以外比如 Ingress,Prometheus 都是把对应的 yaml 文件放到 Git 中,从一个中控机上用 kubectl apply。
Q:场景是四个环境,分别是 dev、test、uat、prd 。假如你是用的 Jenkins Pipeline 来定义这四个环境阶段的发布。理想情况下,dev -> test -> uat -prd 一次性跑完整个 Pipeline 流程,这样的话下一个阶段很容易可以根据 Jenkins 的 bluidId 参数来获取到上一个节点的镜像 id,可以保证每个环境的镜像都是一样的。但是实际场景中,在 dev 到 test 这两个阶段,dev 可能要经过多轮的发布才会到 test 环境,这样的话镜像 id 怎么获取到 dev 最后一次发布后的 id。或者情况也会存在 test-uat 的阶段。总结来说就是,如果最后发布到生产环境,为了让生产的镜像与非生产环境是一致的话,是不是要重新走一遍 dev-test-uat-prd 的 Pipeline 流程。
A:我们现在没有遇到过这个问题,但是我觉得你这个问题可以通过给 Docker 镜像打 label(不知道这个 label 是不是 Harbor 独有的概念)来解决,比如过了 dev 就打 dev 的 label,test 环境部署的时候筛选有 dev label 的镜像就行了吧。(https://goharbor.io/docs/1.10/working-with-projects/working-with-images/create-labels/)
Q:Kubernetes 中 Pod 修改内核参数是否有必要,介绍中修改了 maxconn 个人认为应该作用不大呀,有测试过吗?我们没有修改内核参数 Traefik 压测数据与官网提供的数据相差不超过百分之五。
A:测试过没有我还真是忘了,我们这些参数是参照阿里云的 ingress deployment 改的。
Q:应用发布是通过 init 容器把业务 jar 包 copy 到主容器里的?为什么不一起打包到一个镜像里,这个是基于什么考虑的,会不会出现一些异常问题?
A:没什么异常问题,我觉得这样清晰简单明了,如果我们要统一替换 Java 版本也好换,最主要的原因是这样做我们可以少定制一个 Java 镜像构建标准。
Q:你们环境用的 Docker 用的什么版本最稳定,再生产环境下,你们平台流量那么大,优化是怎么做的,架构是怎么做的呢?
A:Docker 19.3.5,优化大部分都是应用侧的,平台这块我们没做啥特别的优化。
Q:你们平台 Prometheus 是如何做的高可用,采用的什么方式?
A:我觉得高可用对于监控系统来说不太重要,挂了能起来就好,目前我们没有做高可用
Q:为啥不用 GitLab 自带的 CI 和 CD 呢?
A:我们一直用的 Jenkins,没有调研过 GitLab CI/CD。
Q:对于服务治理方面,是否有必要上线 Istio?
A:Istio 太重了,而且我们服务治理不是痛点,很多应用对性能要求比较高,所以没有上。
Q:请问贵公司为什么没用 Istio 做灰度发布或蓝绿部署呢?
A:同上,还有就是我们现在用的灰度发布的套路和我们在虚拟机的时候是基本一致的。
Q:Kubernetes 有自带的服务发现是 Service,传统 Java 微服务常用的一个 Consul 来做服务发现负载均衡, 当 Kubernetes 管理容器的时候 还有必要使用 Consul 吗?
A:我觉得这个看情况吧,原有的是 Consul 就还用呗,如果有痛点可以考虑替换其他方案。
CKA认证培训
本次CKA培训课程,通过线下授课、考题解读、模拟演练等方式,帮助学员快速掌握Kubernetes的理论知识和专业技能,并针对考试做特别强化训练,让学员能从容面对CKA认证考试,使学员既能掌握Kubernetes相关知识,又能通过CKA认证考试,学员可多次参加培训,直到通过认证。点击下方图片或者阅读原文链接查看详情。
